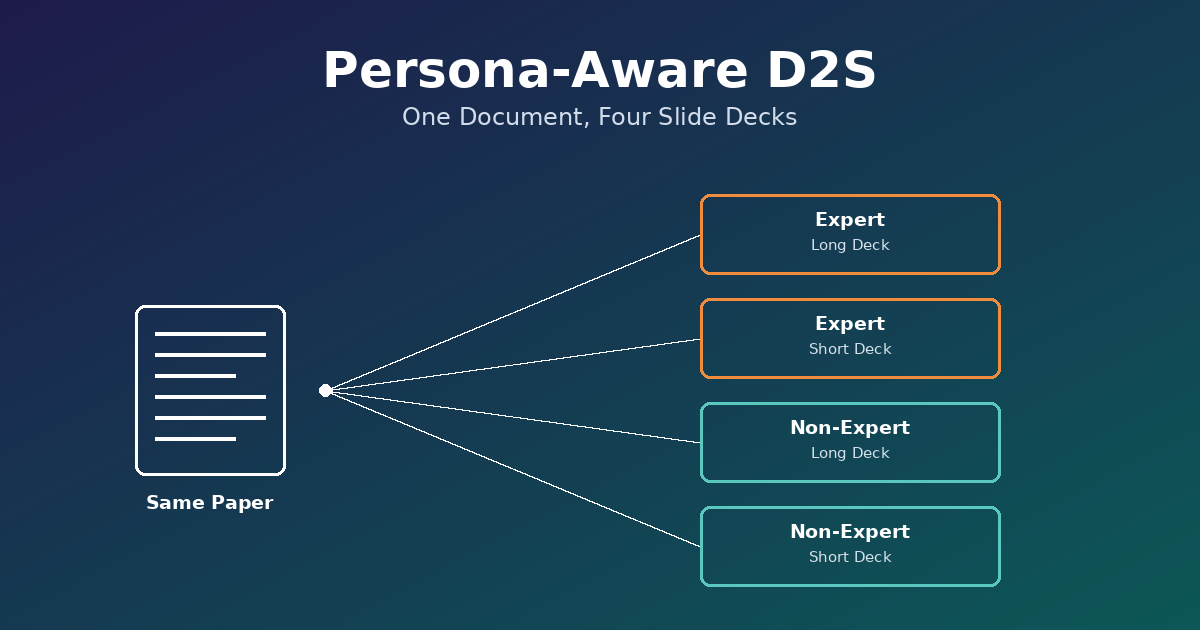
同一份文件換個受眾、換個長度,投影片內容就該完全不同。拆解 EACL 2024 論文 Persona-Aware-D2S 的三階段 pipeline 與 RLHF-lite 訓練法,並老實檢視它在資料規模與架構設計上站不住腳的地方。
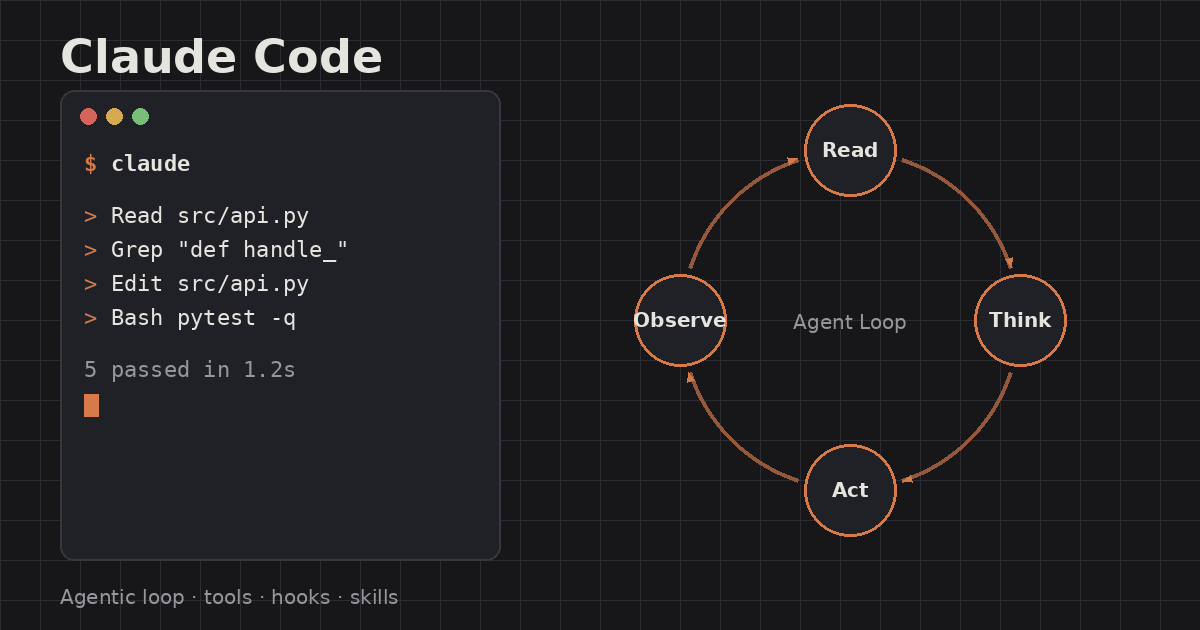
從概念層拆解 Claude Code 的架構:read-think-act 的 Agentic Loop、工具系統、CLAUDE.md 專案記憶、Hooks、Skills、MCP,以及讓自主編碼 Agent 能安全運作的權限機制。
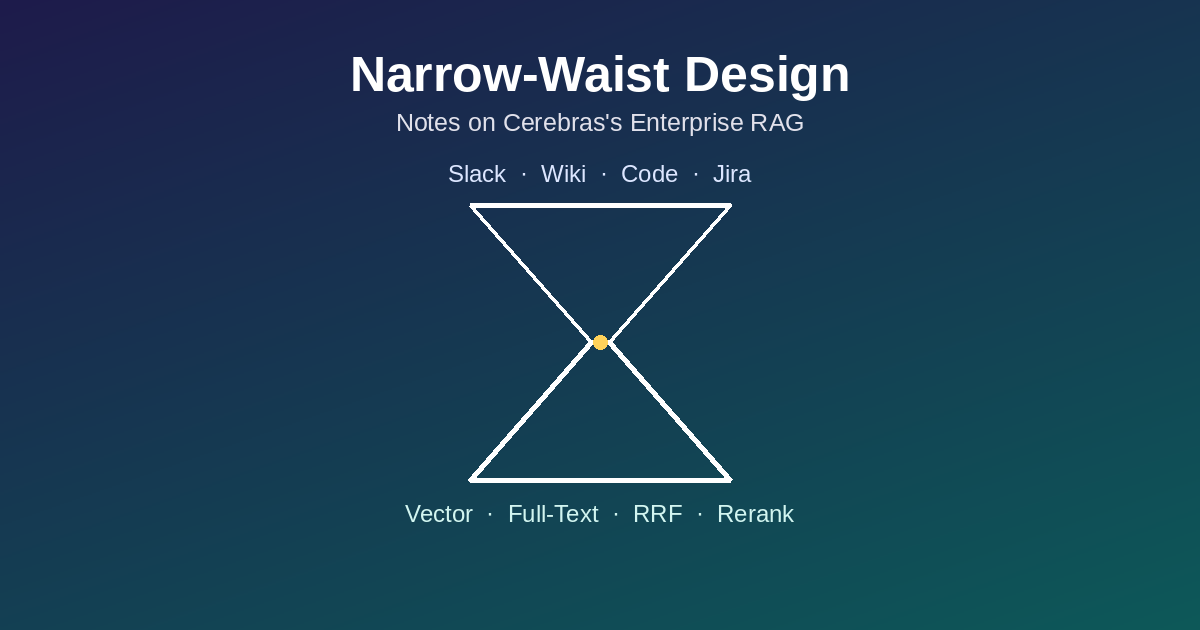
深入拆解 Cerebras 內部知識庫的 RAG 架構:窄腰設計如何讓寫入端與讀取端獨立演化、RRF 如何融合多路檢索排序,以及為什麼這套系統本質上是單輪 pipeline 而非 agentic loop。
花大錢換 Embedding 模型、調 Prompt 卻還是答非所問?問題可能出在最前面的文本切分。看 Adaptive Chunking 如何用五個指標為每份文件自動評分、挑出最佳切法。
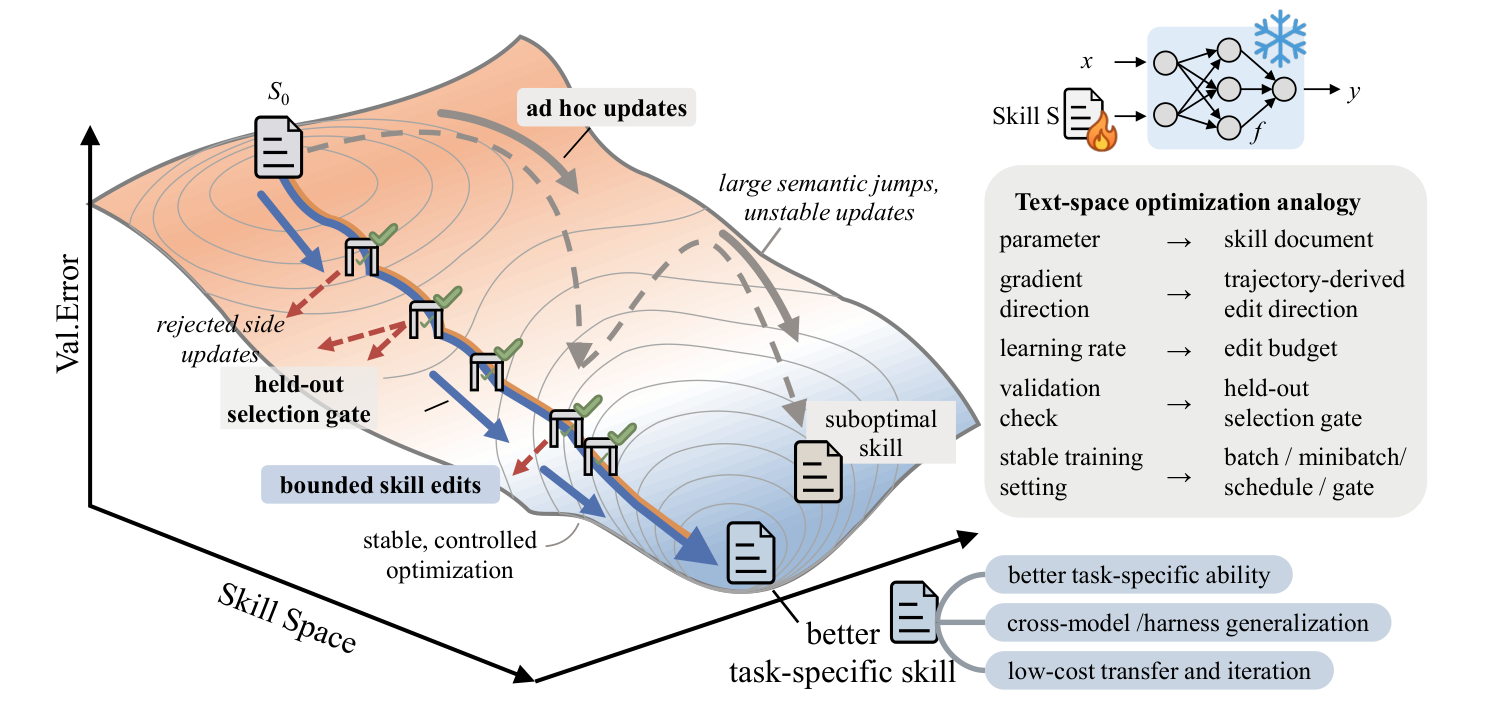
SkillOpt 把 AI Agent 的技能文件當成可訓練的權重:用批次 Rollout、餘弦衰減的編輯預算,以及嚴格的保留驗證集守門機制,取代隨性、容易過度擬合的提示詞修補。
訓練神經網路時遇到 Overfitting?本文將帶你深入了解 Dropout 原理,從 Ensemble 和 Co-Adaptation 的角度,解釋為何這個簡單的技巧能有效解決模型過擬合問題
Neural Network 的 Gradient 到底怎麼算出來的?本文從符號定義出發,逐一拆解 Backpropagation 的四大公式 BP(1) 到 BP(4),帶你看懂誤差如何一層一層往回傳遞。