拒絕 Text-to-SQL 玩具!從 OpenAI 內部 Data Agent 看企業級 AI Agent 的「六層脈絡」與閉環除錯

1 前言
資料是推動現代企業決策與產品迭代的核心。然而,隨著企業規模擴張,最大的挑戰早已不是「如何儲存數據」,而是「人類如何理解龐大且混亂的數據」。
這篇由 OpenAI 團隊發布的工程部落格《Inside our in-house data agent》,罕見地揭露了這家頂尖 AI 實驗室如何解決自身的數據痛點。
OpenAI 內部擁有超過 3,500 名來自工程、產品、研究及財務部門的使用者,並坐擁高達 7 萬個資料集、總量超過 600 PB 的海量數據。在如此龐大的規模下,分析師光是「找出正確的資料表」並「釐清歷史 SQL 隱藏的商業邏輯」,就耗費了大量時間。
為了解決這個「人力頻寬瓶頸」,OpenAI 沒有選擇導入更多的儀表板,而是利用自家的 GPT-5 旗艦模型、Codex、Embeddings API 與 Evals API,從零打造了一個專屬內部的 Data Agent。這個系統成功將原本需要數天的分析流程,縮短至短短幾分鐘內完成,徹底展示了真正的企業級 AI Agent 該具備的深度與穩定性。

2 核心系統架構:決定 Agent 智商的「六層脈絡 (Six Layers of Context)」
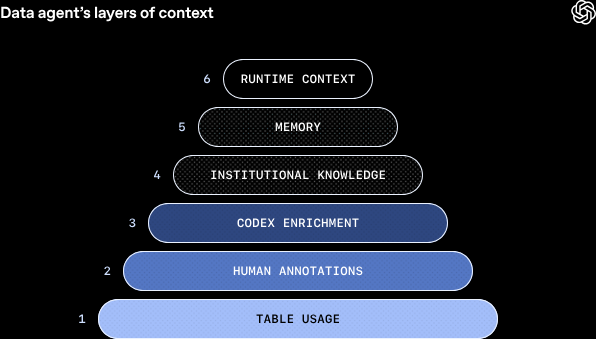
許多初階的 Text-to-SQL 工具之所以在企業環境中失敗,是因為它們迷信「只要把資料庫 Schema 餵給 LLM,模型就能寫出完美的 SQL」。然而,欄位名稱往往會騙人,真實的商業邏輯根本不存在於 Schema 之中。
為此,OpenAI 設計了極度深度的 RAG (檢索增強生成) 系統,賦予 Agent 等同於資深人類分析師的「六層脈絡」:
- 資料表使用狀況 (Table Usage): 系統不只看欄位型態,更深度解析資料血緣 (Lineage) 與歷史查詢紀錄。Agent 會學習過往的數據科學家通常將哪些表進行 JOIN,從而掌握真實的查詢習慣,而非盲目瞎猜。
- 人為註解 (Human Annotations): 由各部門領域專家手動維護的文字描述。例如:「計算每月經常性收入 (MRR) 時,必須排除測試帳號。」這些由人類定義的精確商業規則,是 Agent 避開邏輯地雷的關鍵。
- Codex 語意強化 (Codex Enrichment):
這是極具突破性的一層。Agent 透過 Codex 模型,直接去「閱讀」產生這張表的 ETL 資料管線原始碼 (如 Airflow 或 dbt)。它從源頭的轉換邏輯中萃取語意,知道
status = 4在程式碼裡代表的是「流失用戶」,而不僅僅是一個數字。 - 組織內部知識 (Institutional Knowledge): 整合企業內部的非結構化資料,如 Slack 討論、Notion 文件與 Google Docs。這讓 Agent 能解釋「為什麼去年 11 月法國用戶數下滑?」(因為 Notion 記錄了當時有伺服器停機事件)。
- 對話與學習記憶 (Memory): 具備「不貳過」的能力。記錄過去 Agent 犯錯後被糾正的經驗,以及學習到的慣用過濾條件。當不同使用者問類似問題時,Agent 能直接提取這些修正記憶。
- 執行時脈絡 (Runtime Context / Warehouse Checks):
離線向量庫的資料可能會過期。Agent 在生成 SQL 的當下,會悄悄對資料倉儲下達輕量查詢 (如
SELECT DISTINCT),實際偷看資料庫裡的數值格式是Shipped還是SHIPPED,確保產出的語法 100% 吻合真實資料。
3 關鍵機制一:Closed-loop Self-correction
這項機制是區分「玩具 (Demo)」與「企業級產品 (Production)」的最重要分水嶺。傳統系統是「開環 (Open-loop)」,模型出錯就直接把錯誤丟給人類。而 OpenAI 的 Agent 把自己當作一名工程師,形成自動迭代的閉環機制:
- 短期執行閉環 (Runtime Self-Correction):
Agent 寫完 SQL 送出執行後,如果遇到語法錯誤 (如
Column Not Found),它會將報錯訊息當作新的 Context 自動重寫。更強大的是「邏輯異常診斷」:如果語法全對但回傳 0 筆資料,Agent 會自主懷疑是否 JOIN 條件寫錯,並主動修改邏輯重新嘗試,直到跑出合理結果才回報給人類。 - 長期學習閉環 (Long-term Self-Learning): 經歷跌跌撞撞或人類糾正後,系統會將「修正後的正確邏輯」提取出來,存入上一節提到的「記憶 (Memory)」層。這讓整個系統用得越久,累積的防呆機制越強,越來越聰明。
4 關鍵機制二:Conversations & Workflows
為了解決人類的互動體驗與效率問題,系統設計了兩種截然不同的任務處理模式:
- Conversations — 專注於「探索性分析」: 系統保留了跨輪對話的脈絡。使用者可以自然地追問:「那改成按國家拆分呢?」,甚至可以在 Agent 執行一半時「中途打斷 (Interrupt & Redirect)」,直接給予新方向。這就像與真人實習生協作一樣自然。
- Workflows — 專注於「例行性任務」:
LLM 的缺點在於「隨機性 (Stochastic)」。為確保每週財務報告的絕對一致性,系統允許使用者將驗證成功的對話結果,打包成「指令集 (Instruction sets)」。當呼叫
@Weekly_Report工作流時,系統會關閉 Agent 的自主規劃層,直接套用固化好的 SQL 骨架與參數。這確保了「確定性 (Deterministic)」的產出,無論誰來問,算出來的數字絕對一致。
5 系統防護網:使用 Evals API 進行自動化評估
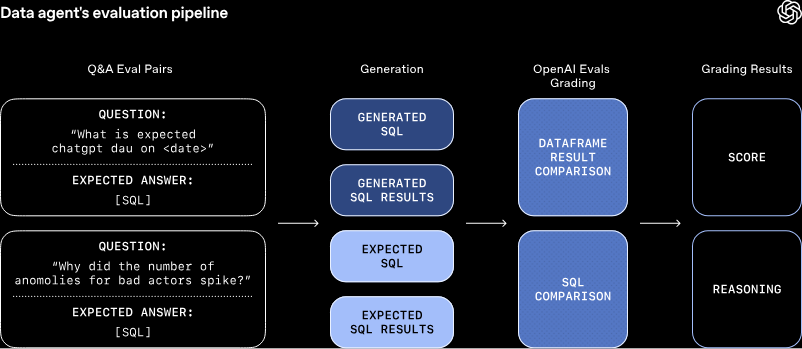
OpenAI 把數據分析當作「軟體單元測試 (Unit Tests)」來對待:
- Golden SQL 資料集:由資深專家手寫高價值的完美 SQL 作為「黃金標準」。
- 雙軌執行 (Dual Execution):測試時,將 Agent 生成的 SQL 與 Golden SQL 同時送入資料庫執行。
- LLM 當裁判 (LLM as a Judge):將兩份執行結果交由 Evals API 進行「語意比對」。只要數據邏輯一致(即使欄位順序或小數點格式不同),就給予滿分。
- 防退化機制 (Regression Testing):這套機制被整合進 CI/CD 流程中。任何 Prompt 或底層架構的更新,若導致原本算對的報表算錯,就會觸發紅燈並阻擋發布,確保系統在數學上始終安全可靠。
6 文章沒說的 4 個挑戰
身為 AI 開發者,當你實際落地這套概念時,絕對會撞到以下 4 面 OpenAI 文章未明說的挑戰:
- 檢索 7 萬張表的真相:單靠 Vector Search 絕對會死 Schema 是高度結構化的。若單純依賴向量相似度,模型會迷失在大量同名欄位中。必須實作「混合檢索 (BM25 + Vector)」,並引入「PageRank 思維」—— 根據資料表在過去 90 天內的 Query 熱度賦予權重,優先檢索最常被使用的核心表。
- 執行時脈絡的陷阱:如何防止 Agent 把資料庫搞掛? 放任 Agent 下 SQL 容易引發災難 (如缺少 LIMIT 或引發笛卡爾積)。系統必須在程式層實作「Dry Run 與 EXPLAIN 攔截」,預估掃描量過大即擋下,並強制設定沙盒唯讀權限與 Timeout (如 30 秒中斷) 機制。
- Enum 與「分類值」的對齊地獄
使用者問「台灣」,但資料庫存的是
TW。若每次都靠 Runtime 去查會太慢。工程上必須離線建立「分類值語意索引 (Categorical Value Index)」,在使用者提問當下先做一次映射,將真實的 Value 硬塞進 Prompt 中給 LLM 參考。 - 閉環修正的架構實作:擁抱狀態機 傳統 ReAct 框架在處理「寫 SQL -> 報錯 -> 修復 -> 再報錯」的長迴圈時極易陷入死胡同。業界最佳實踐已轉向「狀態機 (State Machine / LangGraph)」架構,明確切分規劃、執行與評估節點,並設立修復次數上限與 Human-in-the-loop (人類介入) 中斷點。
7 官方避坑指南:3 個經驗教訓
在文章尾聲,OpenAI 坦誠分享了他們從零打造系統時踩過的 3 個「違反直覺」的坑:
- Less is More: 給 Agent 太多功能重疊的工具(Tools),反而會造成它選擇困難與混淆。將零散的小工具封裝成綜合性大工具,系統穩定度會大幅提升。
- High-level guidance beats rigid instructions: 不要在 Prompt 裡進行微觀管理(「你必須先做A再做B」)。應該專注於定義商業目標與邊界,放手讓強大的模型去發揮「動態推理 (Reasoning)」能力。過度僵化的 Prompt 反而會抹殺模型的智商。
- The true meaning of a table is in the code: Schema 會騙人!它只定義了形狀,沒有定義邏輯。要讓 Agent 真正理解資料,必須讓它去讀取產生資料的 ETL Pipeline (轉換原始碼)。「轉換邏輯,才是真實的商業意圖。」
8 結論
OpenAI《Inside our in-house data agent》這篇文章向我們揭示了一個殘酷且真實的結論:強大的 Enterprise AI Agent 絕非僅靠「最強的 LLM 模型 + 一段厲害的 Prompt」就能實現。
它是一個極度複雜的系統工程,必須建立在「深度的企業知識脈絡 (Six Layers of Context)」、「嚴謹的狀態管理與自我除錯迴圈 (Closed-loop)」,以及「防退化的自動化評估防線 (Evals API)」之上。
對於正在打造 AI 應用的企業與開發者而言,最大的啟發在於:技術原物料 (GPT-5, Embeddings, Codex) 已經全面普及,未來的決勝點在於 「誰能將企業內部混亂的商業脈絡整理得最乾淨」,以及 「誰的產品設計最符合人類分析師的協作習慣」。當這些基礎設施到位,AI 才能真正從「展示用的玩具」,蛻變為為企業創造巨大價值的數位大腦。