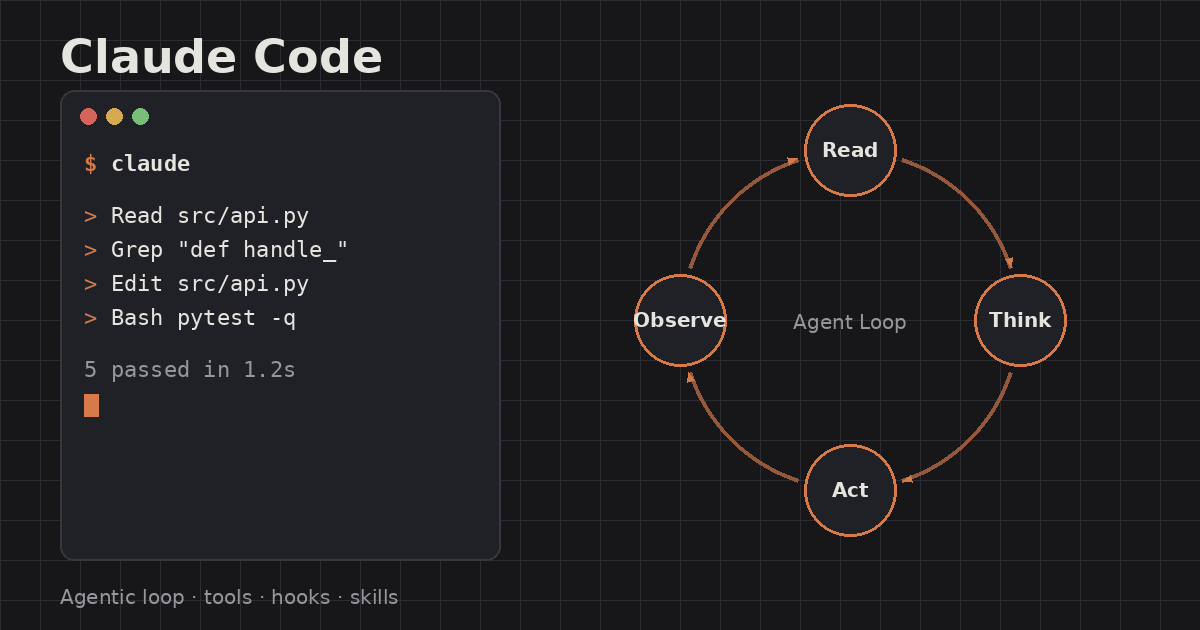
A concept-level tour of Claude Code's architecture: the read-think-act agentic loop, its tool system, CLAUDE.md project memory, hooks, skills, MCP, and permission model.
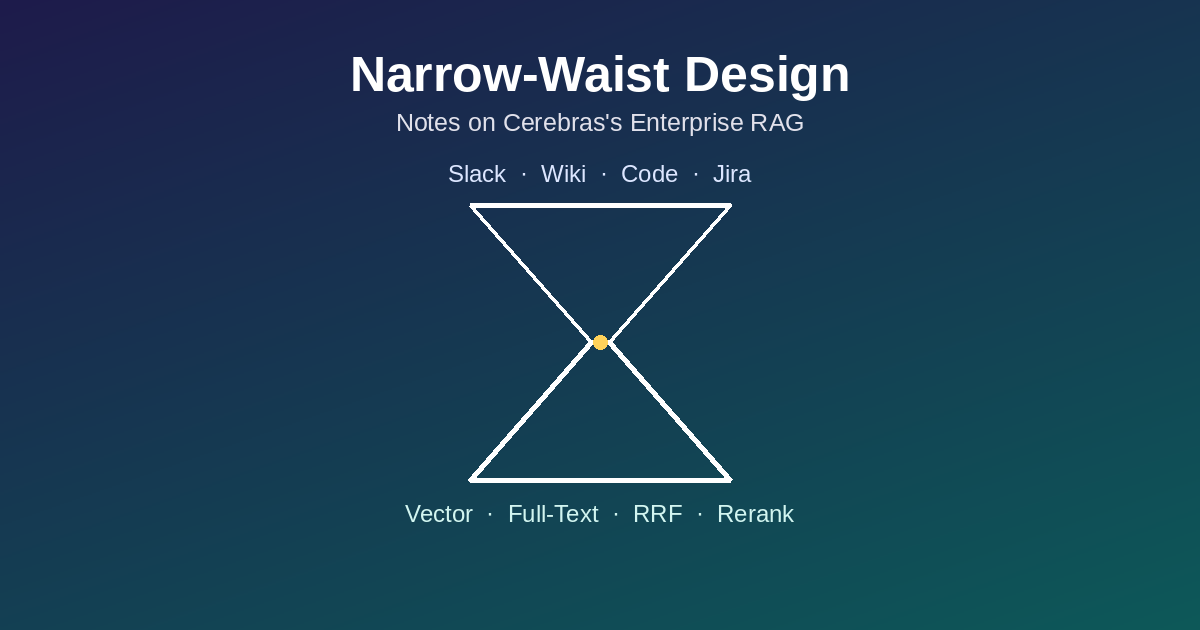
How Cerebras's enterprise RAG uses narrow-waist design to decouple ingestion from retrieval, fuses rankings with RRF, and why it's a pipeline, not an agentic loop.
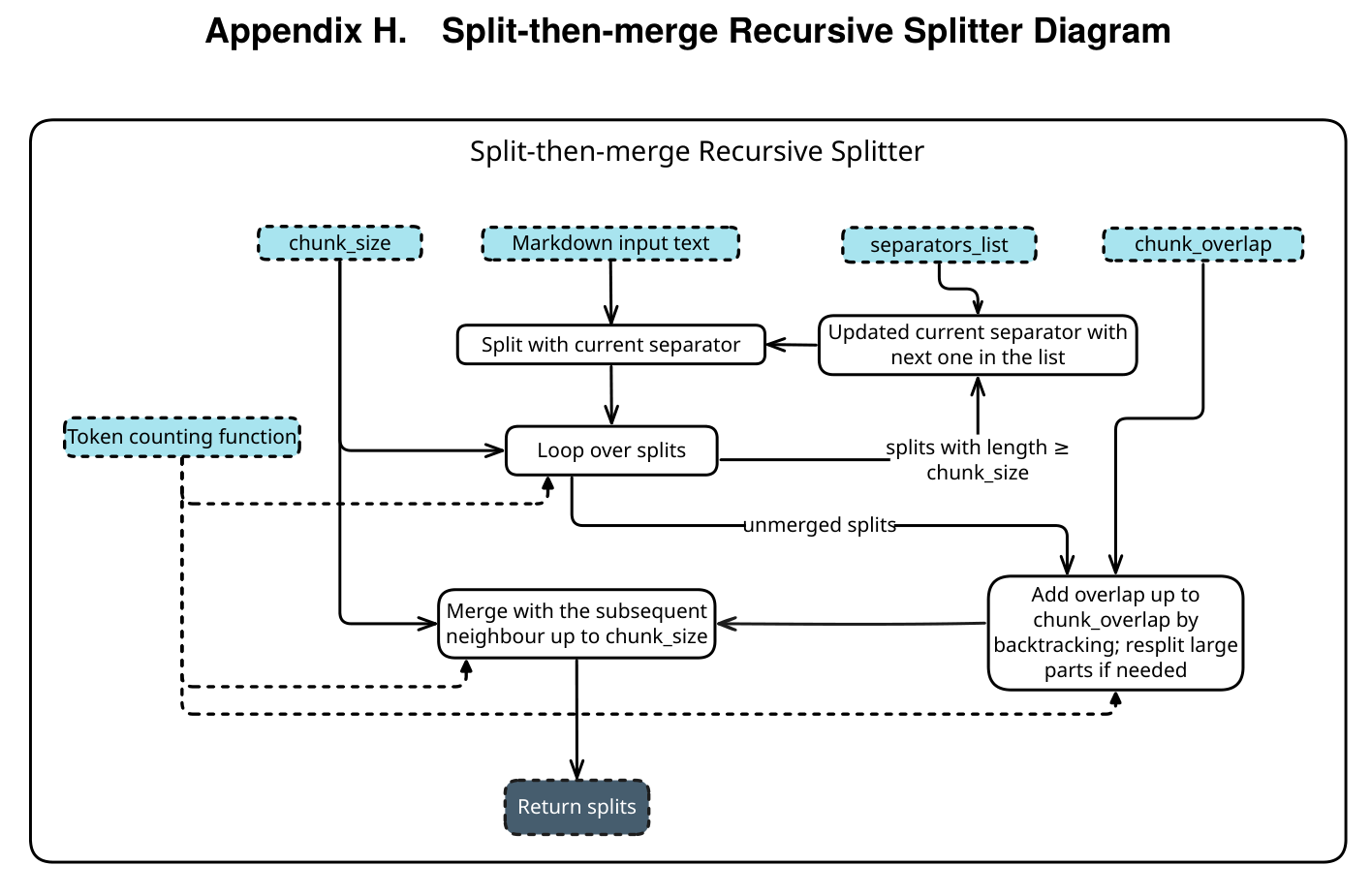
One-size-fits-all text splitting quietly wrecks RAG pipelines. See how Adaptive Chunking scores candidate splits with five metrics and keeps the best per document.
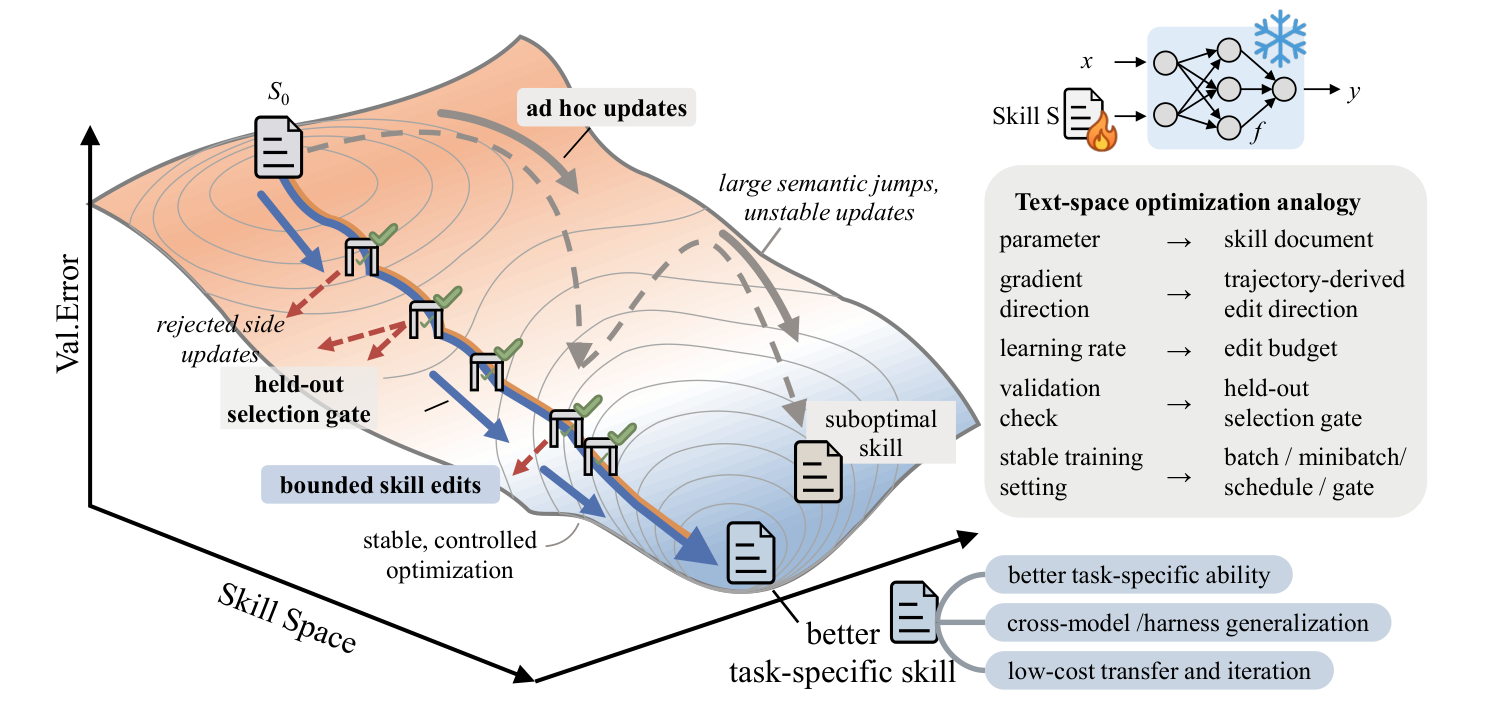
SkillOpt treats an agent's skill file as a trainable weight: batched rollouts, a bounded edit budget, and a strict validation gate replace ad hoc prompt patching.
Explore the architecture of OpenAI’s in-house Data Agent. Learn how they leverage six layers of context, self-correction, and Evals to analyze 600 PB of data.
Optimize your LLM agents with AgentOpt. Discover how this open-source, client-side framework uses MAB to find the best model combo and cut API costs by 67%.
Boost LLM Agent performance with ERL (Experiential Reflective Learning). This framework extracts "Trigger-Action" heuristics from single attempts to solve Agent amnesia, increasing Gaia2 success by 7.8% without fine-tuning.