Dropout Explained: The Simple Secret to Preventing Neural Network Overfitting

1 Introduction
When training a neural network, if the network is too complex (i.e., has a large number of parameters) but the amount of training data is limited, it is prone to overfitting. If you are unfamiliar with the concept of overfitting, you can refer to this article on the Bias-Variance Tradeoff.
In practice, when a model has overfitted, you will see the training error continuously decrease while the validation error fails to improve. There are many techniques to combat overfitting, and Dropout is one of the fundamental ones. No matter where you learn about Deep Learning, if you encounter overfitting while training a neural network, you will inevitably be told to insert a Dropout layer between your Linear/Dense layers.
However, do you truly understand what a Dropout layer does to a neural network? This article will guide you through the origins of Dropout, its underlying principles, its implementation, and finally, why it is so effective at resolving overfitting.
2 The Origin of Dropout
The concept of Dropout was introduced by Hinton et al. in their 2012 paper, “Improving neural networks by preventing co-adaptation of feature detectors”.
The paper’s abstract states: “When a large feedforward neural network is trained on a small training set, it typically performs poorly on held-out test data. This ‘overfitting’ is greatly reduced by randomly omitting half of the feature detectors on each training case. This prevents complex co-adaptations in which a feature detector is only helpful in the context of several other specific feature detectors.”
In essence, this means that when we have a very complex model (many parameters) but only a small amount of training data, the model is likely to overfit. If we can reduce the “co-adaptation” between neurons (feature detectors) during the model’s “training process,” we can effectively mitigate overfitting. We will explain the concept of “co-adaptation” later in this article.
In the same year, Alex Krizhevsky, Geoffrey Hinton, et al. published the paper “ImageNet Classification with Deep Convolutional Neural Networks”. The paper introduced AlexNet for an image classification task and used Dropout during training to reduce model overfitting. This approach led them to win the 2012 ImageNet competition by a significant margin.
Since then, Deep (Convolutional) Neural Networks have soared in popularity, becoming the go-to solution for computer vision tasks, and Dropout has become a standard technique for preventing model overfitting.
3 How Dropout Works (The Simple Version)
Next, let’s understand the working principle of Dropout from a high-level perspective.
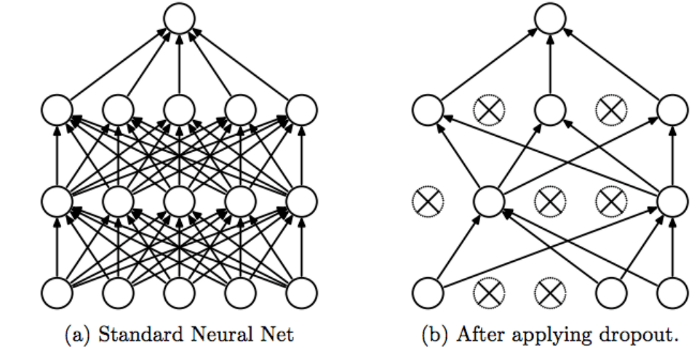
As shown in Figure (a) above, we have a standard neural network. Typically, we feed an input x into the network and calculate the cost for that batch based on the output y. With the cost, we can then use the concept of Gradient Descent to update all the parameters in the network.
If you are not yet familiar with how a neural network updates its parameters, you can refer to these articles:
If we use a Dropout layer during training, our neural network changes from Figure (a) to Figure (b). In both the TensorFlow API and the PyTorch API, when we initialize a Dropout layer, we must pass a “probability” (or rate) that determines the likelihood of each neuron being “dropped out.”
“Dropped out” means that regardless of the input to the neural network, the output (activation) of these selected neurons will always be 0. When a neuron’s output is 0, the result of multiplying it by any connected weight will also be 0.
Furthermore, during the backpropagation process, if the input to a weight (the activation from the previous layer) is 0, its corresponding gradient will also be 0, preventing that weight from being updated.
Therefore, in Figure (b) above, we use (✕) to represent the dropped-out neurons and remove their connecting lines (weights), making the entire neural network behave as if these neurons do not exist.
If you don’t understand why the gradient becomes 0, you can refer to this article: Understanding Backpropagation: How Gradients Are Calculated
When the next input batch is fed into the neural network, the Dropout layer restores the previously dropped-out neurons and randomly selects a new set of neurons to drop out. This process repeats, so in each iteration, a portion of the neurons does not contribute to the network’s output, and their corresponding weights are not updated.
4 How Dropout Works (The Detailed Version)
Now that you understand the basic concept of Dropout, let’s explore its principles from a mathematical perspective.
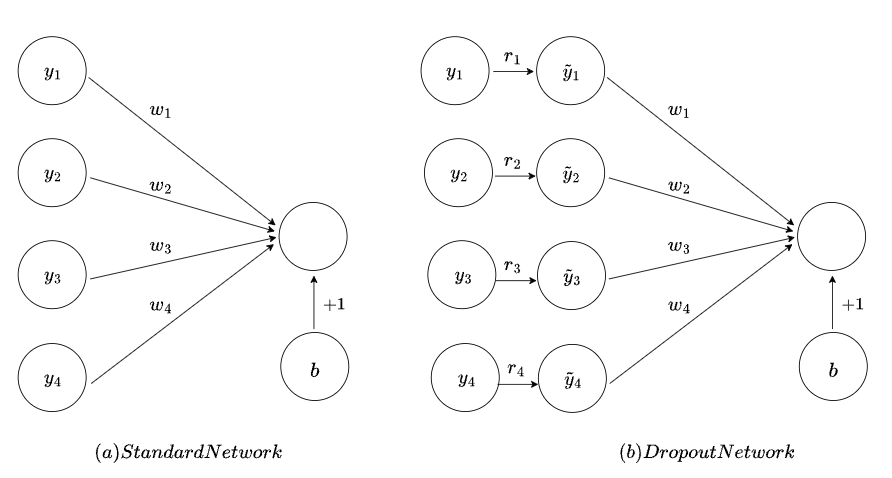
As shown in the figure above, in a standard neural network, the output y from the previous layer is directly multiplied by the weights of the current layer and added to the bias. With Dropout, each output y from the previous layer is first multiplied by a value r before being multiplied by the weights and added to the bias.
Here, r is a random variable drawn from a Bernoulli distribution with a probability p. The value of r can be either 0 or 1. When r is 0, it means the neuron is dropped out, as its output is set to 0.
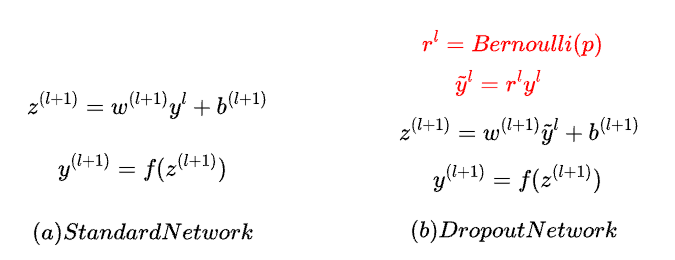
The image above presents the mathematical formulas for a standard neural network versus one with Dropout. You can see that the only difference is the part highlighted in red, where each neuron’s output is multiplied by a value sampled from a Bernoulli distribution (0 with probability p, and 1 with probability 1-p).
For example, suppose the layer before the Dropout layer is a Dense/Linear layer with 1000 neurons. If we set the Dropout probability p to 0.5, then each neuron has a 50% chance of being dropped. In other words, about 500 of the 1000 neurons will be deactivated (their outputs will be set to 0).
A crucial point to note is that we must ensure the expected value of each neuron’s output remains the same during both the training and testing phases.
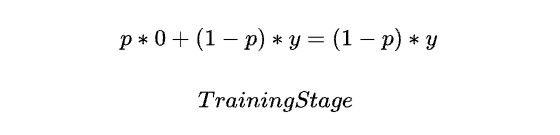
As shown in the formula above, during the training phase, a neuron affected by Dropout has a probability p of having its output become 0 (dropped out) and a probability (1-p) of its output remaining unchanged. Therefore, the expected output of that neuron is (1-p) * y.
To ensure the expected output of the neuron is the same during both training and testing, we have two options: we can either multiply the neuron’s output by 1 / (1-p) during the training phase or multiply the neuron’s output by (1-p) during the testing phase.
5 Why Does Dropout Mitigate Overfitting?
Now that we have a complete understanding of how Dropout works, let’s revisit the question of why it is so effective at solving the overfitting problem.
We can explain this from two perspectives:
The first is the concept of “Ensemble”.
In Ensemble Learning, we train multiple models and consider their collective predictions to arrive at a final result. By averaging or taking a majority vote, ensemble learning improves the overall performance of the model.
The Dropout mechanism is analogous to an ensemble. In each iteration, we “drop out” certain neurons, which is like removing them from the network. As a result, we get a neural network with a “different structure” in every iteration.
Ultimately, although it seems like we are training a single model, we are actually training a combination of various model structures. Therefore, the neural network’s output is not just the output of “one” network but the combined result of “multiple” networks.
The second perspective is the concept of “Co-Adaptation”.
Co-adaptation refers to the dependency between neurons. For example, suppose the first neuron in the second layer receives outputs from all neurons in the first layer but becomes highly dependent on the value output by the first neuron of the first layer. This means that although the neuron in the second layer technically receives features from all neurons in the first layer, it primarily pays attention to the feature from just one of them.
We don’t want neurons to be overly sensitive to a single feature. By using Dropout, the first neuron of the first layer and the first neuron of the second layer may not always appear together. This forces the second-layer neuron to learn from the features of other neurons in the first layer as well.
If every neuron in the network learns to consider the features from all neurons in the previous layer, rather than relying on a single one, the model will be less affected by imperfections in the input features. This naturally leads to better generalization ability for the entire model.
6 Conclusion
In this article, we introduced “Dropout,” a classic technique in Deep Learning for combating overfitting. We explored its operational principles, understanding what it does to a neural network during both training and testing. Through the concepts of “Ensemble” and “Co-adaptation,” we explained why Dropout can effectively resolve overfitting and improve model performance.