Harness Engineering: Building Self-Evolving AI Agents with Ralph Loop and MemRL

1 Introduction
- Paradigm Shift in Agent Development: Moving from purely chasing “smarter large models” toward “building better systems engineering.” True intelligence comes not just from Weights, but from the system’s memory and feedback mechanisms.
- Core Pain Points: Two major challenges when AI Agents are deployed in industry:
- Statelessness and Hallucinations: Agents tend to fall into the same trap twice, and simple RAG (Retrieval-Augmented Generation) can introduce “semantic noise.”
- Scalability and Stability: Complex tasks lead to Context Rot, and the cost of fine-tuning models is extremely high, often leading to catastrophic forgetting.
- Goal of this Note: Combining the algorithmic design of the 《MemRL》paper with the system perspectives of LangChain’s 《Agent Harness》 and 《Continual Learning》, providing a comprehensive architectural blueprint from “memory retrieval” to “execution harness.”
2 Anatomy of the Three-Layer Agent Architecture
In traditional software development, we focus on “Code + Database”; in early AI development, we focused on “The Model.” But in the Agent engineering practices of 2026, we must follow this golden formula:
Agent = Model + Harness + Context
The relationship between these three can be compared to: The Model is the neurons of the brain, the Harness is the physical body and senses, and the Context is the memory and current perception.
2.1 Model Layer: The Frozen Brain and Reasoning Engine
The Model is the decision-making core of the system, responsible for transforming input text sequences into logical reasoning or tool calls.
- Industry Reality: “Frozen” is the Norm
In production environments, we typically treat the Model as “Immutable Infrastructure.” The reasons are:
- Catastrophic Forgetting: Fine-tuning a model to learn new rules can easily destroy its original foundational reasoning capabilities.
- Compute and Latency: Frequent fine-tuning leads to skyrocketing MLOps costs.
- Post-training Alignment with the Harness:
This is a hardcore observation in current trends. Top-tier models like Claude 3.5 Sonnet are already trained within specific harnesses during the post-training phase (RLHF).
- Example: Claude 3.5 is trained with a high preference for specific file modification formats like
str_replaceorapply_patch. If you switch to an OpenAI model, even if the “IQ” is the same, it might fail because it cannot accurately generate strings that match that specific format, causing the harness parser to fail. This is known as “Harness-specific optimization.”
- Example: Claude 3.5 is trained with a high preference for specific file modification formats like
2.2 Harness Layer: The Agent’s Life Support and Control Center
The Harness consists of all the code and infrastructure wrapped around the model. It is the key to turning an Agent from “all talk” into “actual action.”
2.2.1 Infrastructure
- Filesystem: Models are stateless. The Harness must provide a persistent working directory. An Agent’s progress should not reside in the prompt, but in files on the disk (e.g.,
CLAUDE.mdorTODO.json). - Sandboxes: The Harness is responsible for scheduling Docker or virtual machines so that Bash commands or Python code generated by the model can be executed safely.
2.2.2 Action Space & MCP
- Tool Encapsulation: The Harness wraps APIs into JSON Schemas that the model can understand.
- Progressive Disclosure: To save tokens, the Harness doesn’t give the model 100 tools at once. Instead, it provides a
list_toolsfunction, allowing the model to dynamically load specific tool definitions as needed (Just-in-Time Injection).
2.2.3 Orchestration & Hooks
- Middleware: The Harness performs “format interception” on model outputs.
- Example: If the model outputs an extremely long log, the Harness actively performs Tool Call Offloading, storing only the head and tail of the log in the Context and the rest in a file, preventing the model from becoming “dumber” due to context overload.
- Self-Verification: The Harness can automatically run a test suite before the model replies to the user. If an error occurs, it throws the error directly back into the Ralph Loop.
2.3 Context Layer: Injection of Dynamic Experience
The Context is the input dynamically pieced together by the Harness based on the current task and external data.
- Hierarchical Memory Isolation:
In enterprise applications, memory must be layered according to privacy permissions:
- Agent-level: General best practices, safety principles.
- Org-level: Internal project standards, proprietary API documentation.
- User-level: User coding preferences, historical operation habits.
- Injection Logic: Before sending a request to the Model, the Harness performs a retrieval (for example, using the MemRL algorithm) to inject the most relevant “High-utility experiences” into the Context.
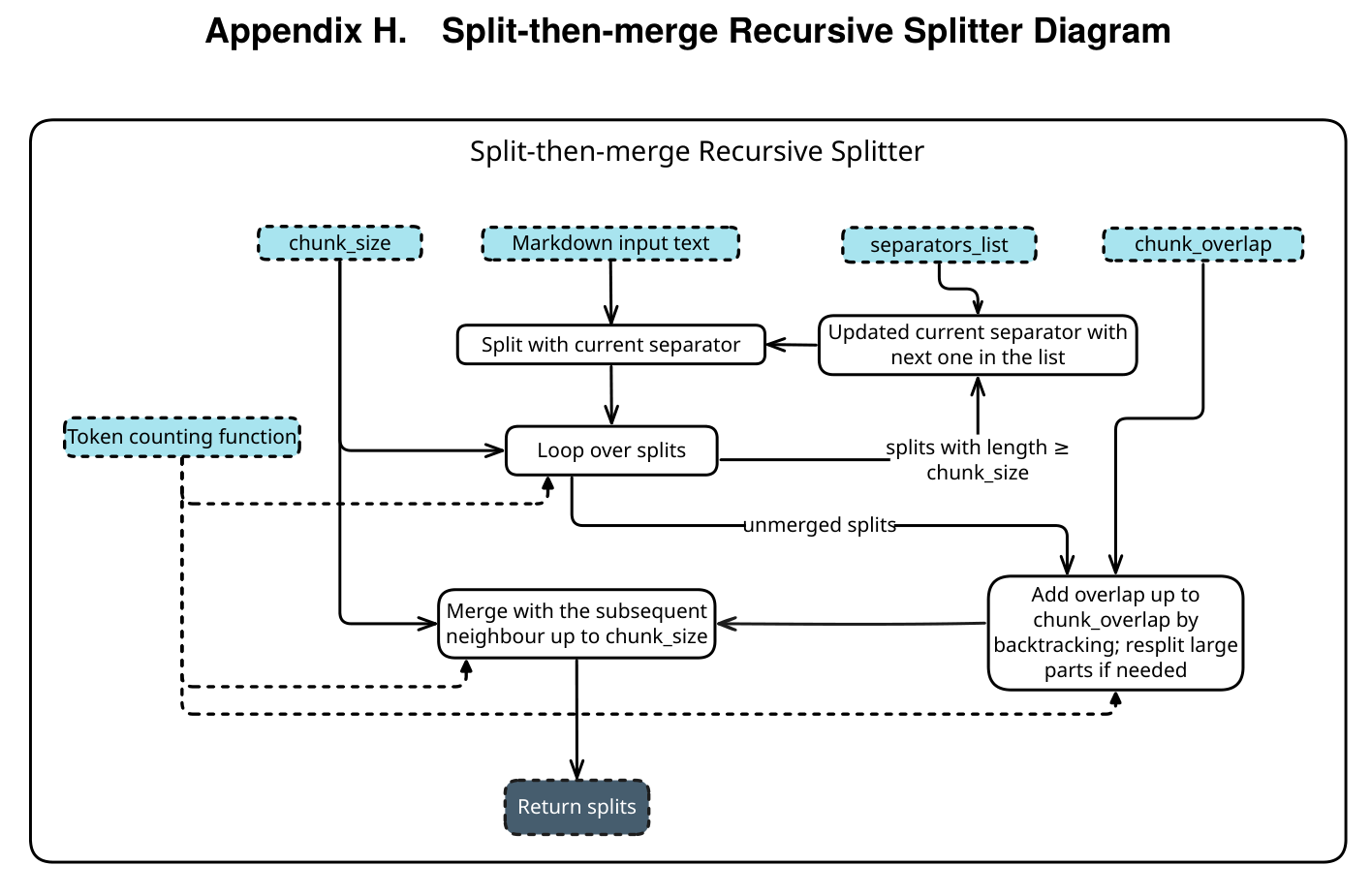
2.4 Harness Engineering Pseudo-code
# Internal control logic of the Harness (Pseudo-code)
def run_agent_loop(user_input):
context = load_hierarchical_memory(user_id, org_id) # Load multi-level memory
base_tools = ["list_skills", "read_file"] # Initially provide minimal tools
while True:
# 1. Assemble the final Prompt for the model
prompt = assemble_prompt(user_input, context, base_tools)
# 2. Model Decision
response = model.call(prompt)
# 3. Harness Interception (Hooks)
if response.calls_tool == "list_skills":
# Progressive Disclosure: Model needs DB tools, dynamically inject definition
db_tool_definition = fetch_tool_schema("database_query_tool")
base_tools.append(db_tool_definition)
continue # Restart loop without consuming external reply
if response.has_long_output:
# Anti-corruption: Automatically truncate long output (Head/Tail Truncation)
response.content = truncate_log(response.content)
# 4. Execute and get Observation
result = sandbox.execute(response.action)
context.update_short_term_memory(response.action, result)3 Continual Learning in the Context Layer —— MemRL Implementation
3.1 Core Philosophy: Shifting from “Similarity” to “Utility” (Utility-Driven)
Traditional RAG memory has a fundamental flaw: Semantic Similarity Functional Utility.
- Pain Point: If an Agent once tried a wrong method to solve a SQL query task, traditional RAG will still retrieve that wrong experience the next time it encounters a similar task simply because the “semantics are close.”
- Solution (M-MDP): Model memory as a Memory-Based MDP, where each experience is no longer just
(Vector, Content), but a triplet:(Intent, Experience, Utility/Q-value).- Intent: Vector features of the original task.
- Experience: Execution traces, successful code, or failure reflections.
- Utility/Q-value: The probability and reward of this experience helping task success historically.
3.2 Two-Phase Retrieval Mechanism
To balance “search speed” and “experience quality,” we implement a two-stage filter in the Harness:
3.2.1 Phase A: Similarity-Based Recall (Coarse Filtering)
- Action: Perform a Top-k1 Cosine Similarity search in the Vector DB.
- Purpose: Act as a “gatekeeper” to ensure the retrieved experiences are relevant to the business logic.
- Engineering Trick: Set a hard similarity threshold (e.g., 0.38). Experiences below this value are discarded to prevent the Agent from being distracted by unrelated “high-score memories.”
3.2.2 Phase B: Value-Aware Selection (Fine Ranking)
- Action: Weight and score the candidate experiences.
- Formula:
- Significance: controls the Agent’s “stubbornness.”
- If , the system considers both “how similar it looks” and “past success.”
- This effectively filters out “semantic noise”—experiences that look similar but actually lead to failure.
3.3 Q-Value Dynamic Update Rule (Non-Parametric Learning)
This is the fuel for Agent self-evolution. We don’t update model weights; we update the Metadata (Q-value field) in the Vector DB.
Update Formula (Monte Carlo / EMA):
- (Reward): Feedback from the environment (Success = +1, Failure = -1).
- (Learning Rate): The speed of memory update.
Engineering Implementation (Runtime Update): When the Ralph Loop completes a task and obtains a verification result (e.g., Test Suite passes), the Harness immediately goes back and updates the Q-values of the memories just retrieved.
- Advantage: This is “Hot-path” (real-time learning). The next time the Agent handles a similar task, the Q-values are already updated, and it will immediately avoid the path that just failed.
3.4 Learning from Failure: High-Utility Near-Misses
The most engineering-inspiring point in the MemRL paper is: Failure experiences can be more valuable than success.
- Failure Reflection:
When a task fails, the Harness assigns an LLM to analyze the Traces and generate a
[PATTERN TO AVOID]. - Memory Writing: This failure reflection is given an initial Q-value. Even though it represents “failure,” because it explicitly tells the Agent “what NOT to do,” its decision utility in similar contexts is extremely high.
- Example:
- Experience A (Success): “Use
seddirectly to replace config.” (Q: 0.8) - Experience B (Failure Reflection): “Note:
sedskips commented lines; suggest uncommenting before replacing.” (Q: 0.95) - Result: Next time, the Agent will prioritize reading Experience B, avoiding a potential bug.
- Experience A (Success): “Use
3.5 Implementation Example: Memory Hierarchy and Update Timing
In a 2026 enterprise architecture, we combine Hot-path and Dreaming:
| Layer | Timing (When) | Content (What) | Purpose |
|---|---|---|---|
| Hot-path | Moment of task completion (Runtime) | Update Q-values of existing memories | Instant correction, avoiding repeated mistakes. |
| Dreaming | Offline batch (Offline/Daily) | Scan Traces, Summarize multiple similar experiences into high-level rules | Compress Context space, combat “memory bloat.” |
3.6 MemRL Q-Value Update Pseudo Code
def post_task_learning(task_trace, feedback_reward):
# 1. Get IDs of experiences "selected and injected into Context" during this task
retrieved_memory_ids = task_trace.metadata["retrieved_ids"]
# 2. Execute Non-Parametric RL update
alpha = 0.3 # Learning rate
for mem_id in retrieved_memory_ids:
old_q = vector_db.get_metadata(mem_id, "q_value")
# Calculate new Q-value
new_q = old_q + alpha * (feedback_reward - old_q)
# Write back to Vector DB Metadata
vector_db.update_metadata(mem_id, {"q_value": new_q})
# 3. If failed, trigger failure reflection and write new experience
if feedback_reward < 0:
reflection = llm.generate_reflection(task_trace)
vector_db.add_new_experience(
intent=task_trace.intent,
content=reflection,
initial_q=0.5 # Give a moderate initial weight to trigger next attempt
)4 Harness Layer Engineering Techniques
4.1 Ralph Loop: The Orchestrator
The Ralph Loop is an architectural philosophy to combat the “Multi-agent complexity trap.” it argues that “A robust loop is better than grand theories.”
- Core Concept: Monolithic > Multi-Agent
- Pain Point: Introducing multiple Agents talking to each other too early increases system entropy, leading to debugging difficulties and instability.
- Ralph Mode: Let one powerful model (like Claude 3.5 or GPT-5) operate within a simple
whileloop. Each loop does only one thing: “Observe → Think → Act → Get Feedback.”
- “Throw it back on the wheel”:
- When the Agent fails or errors in the loop, the Harness doesn’t crash. Instead, it captures the error, reassembles the context, and “throws it back onto the wheel.” This allows the software to be reshaped like clay through repeated loops until it meets validation standards.
4.2 Battling Context Rot
Context space (Context Window) is an extremely expensive and fragile resource. Excessive context leads to Reasoning Degradation. The Harness must act as a “filter.”
4.2.1 Tool Call Offloading
- Engineering Trick: Head/Tail Truncation
- If an Agent executes
cat log.txtand returns 50,000 words, the Harness intercepts this output. - Method: Keep only the first 500 words (Head) and the last 500 words (Tail) of the log to put in the Prompt; store the rest on the disk.
- Reason: The core of error messages is usually at the beginning (command state) and the end (Stacktrace). Long content in the middle only distracts the model’s attention.
- If an Agent executes
4.2.2 Just-In-Time (JIT) Tool Injection
- Method: The initial System Prompt only provides basic navigation tools. When the Agent realizes it needs a specific skill (e.g., handling a PDF), the Harness then dynamically injects the JSON Schema of the PDF tool into the Context.
- Purpose: Reduce the initial token burden, ensuring the model retains its maximum IQ to handle core logic.
4.3 Git-based State & Sandboxes
Agents need an environment where they “can afford to lose.” The Harness must provide powerful undo and branching capabilities.
4.3.1 Rollback & Branching
- Advanced Implementation: The Harness binds the Agent’s working directory to Git.
- Mechanism: When the Agent is about to perform a high-risk refactor, the Harness secretly executes
git checkout -b experiment. - Auto-Rollback: If the test fails and the Agent cannot fix it within 3 loops, the Harness automatically executes
git reset --hard. This allows the Agent to “painless restart” after failure, solving the problem of stuck long-term tasks.
4.3.2 Sandbox Fan-out
- Method: Use Docker or VMs to provide independent execution environments.
- Value: When an Agent needs to try multiple solutions, the Harness can instantly launch 5 parallel sandboxes, allowing the Agent to test 5 code branches simultaneously, finally merging the successful one back to the main branch.
4.4 Harness Meta-Optimization
When an Agent performs poorly, engineers should not prioritize changing the model but rather “Programming the loop.”
- Fixing Failure Domains:
- If an Agent consistently fails to understand an API error message, you should modify the
Error Messagedefinition for that tool in the Harness to make it more “instructional.”
- If an Agent consistently fails to understand an API error message, you should modify the
- ACI (Agent-Computer Interface) Optimization:
- Research shows that giving a model a “text interface designed specifically for it (e.g., a simplified
ls -R)” is more effective than giving it a “GUI screenshot intended for humans.” This is the core value of Harness Engineering.
- Research shows that giving a model a “text interface designed specifically for it (e.g., a simplified
4.5 Ralph Loop Framework Pseudo Code
def ralph_loop_harness(task_goal):
# 1. Prepare clean Git environment and Sandbox
repo = git.initialize_workspace()
sandbox = docker.create_sandbox()
while not task_completed:
# 2. Prepare context (including Log truncation)
obs = repo.get_current_state()
context = prepare_lean_context(task_goal, obs)
# 3. LLM Thinking and Action
thought_and_action = model.generate(context)
# 4. Intercept and Execute (Git Branching as an example)
if is_high_risk_action(thought_and_action):
repo.create_checkpoint_branch()
# 5. Execute and get Feedback (Observation)
result = sandbox.execute(thought_and_action.code)
# 6. Automated Check (Self-Verification)
if result.exit_code != 0:
# Failed? Don't crash, throw the error back to the Loop for it to fix
# If failures exceed a threshold, trigger Harness-level rollback
if retry_count > threshold:
repo.rollback_to_last_stable()
task_goal.append_hint("Last attempt failed, try a different approach.")
continue
task_completed = verify_with_tests(repo)5 Conclusion
5.1 Core Concept Convergence: The Paradigm Shift in Agent Engineering
In the context of 2026 Agent development, we must admit one reality: Relying solely on “more powerful models” can no longer solve complex long-horizon tasks. The true battle lies in the depth of systems engineering.
- Model is a Frozen Engine: We no longer fantasize about solving ever-changing business logic through fine-tuning, because the cost is too high and the risk too great.
- Harness is a Robust Skeleton: Through the monolithic loop of the Ralph Loop, the state rollback of Git, and the parallel expansion of Sandboxes, we create an environment for the Agent that can “afford to fail and learn.” This pushes Agent performance from “random” toward “deterministic.”
- Context is the Evolving Soul: Through MemRL’s two-phase retrieval and dynamic Q-value updates, we give Agents the ability to “learn from their mistakes.” This is the optimal solution for Continual Learning without touching model weights.
5.2 Traces are the Only Truth
In this architecture, whether it’s layer one, two, or three, their operation entirely depends on one underlying infrastructure: Structured Traces.
Without complete Trace records (including: inputs, thoughts, tool calls, errors, final results), you will not be able to:
- Dream (Offline): Cannot summarize high-level rules.
- Hot-path Learning: Cannot update MemRL Q-values.
- Harness Optimization: Cannot discover where the Agent is stuck in a loop.
“Observability comes before the evolution of intelligence.” This is a motto every engineer must keep in mind.
5.3 Action Checklist
If you are starting to implement your own Agent today, please follow these steps and do not over-complicate too early:
- Step 1: Start your Ralph Loop
- Write a 300-line Python script and run your Agent with
while(True). - Give it a standard Sandbox environment (even a local Temp Dir) and a set of Bash tools.
- Write a 300-line Python script and run your Agent with
- Step 2: Build a Trace Collection System
- Introduce LangSmith or Langfuse. Ensure every tool call return value (especially Errors) is fully recorded.
- Implement Head/Tail Log Truncation to prevent Context explosion.
- Step 3: Implement a Dynamic Experience Library (MemRL Lite)
- Add
q_valueMetadata to your Vector DB. - Manually write 10 “Success Examples” and 10 “Failure Reflections.”
- During retrieval, introduce a simple weighted score ().
- Add
- Step 4: Iterate with your “Engineer Hat” on
- Watch the Traces. If the Agent makes the same mistake twice, modify the Tool description or the System Prompt in the Harness.
5.4 Epilogue: Programming the Loop, Not the Logic
The future of software development will shift from “writing if-else brick by brick” toward “designing a system that can evolve itself.” You are no longer the creator of code; you are the “Programmer of the Ralph Loop” and the “Curator of Experience.”
As Geoffrey Huntley said, it is a process like “shaping clay on a pottery wheel.” The more stable your Harness and the purer your Context, the closer your Agent will come to a perfect solution within its infinite cycles.