The 3 Stages of LLM Training: A Deep Dive into Reinforcement Learning from Human Feedback (RLHF)
1 Introduction
2023 can be considered the inaugural year of Generative AI, with Large Language Models (LLMs) in particular beginning to integrate into our daily lives. This article provides a brief introduction to the LLM training process, with a special focus on the third stage: Reinforcement Learning from Human Feedback (RLHF).
A quick heads-up: This article contains many terms that might seem technical but are quite straightforward. Therefore, it may be more suitable for readers who already have a basic understanding of LLMs!
2 The 3 Stages of LLM Training
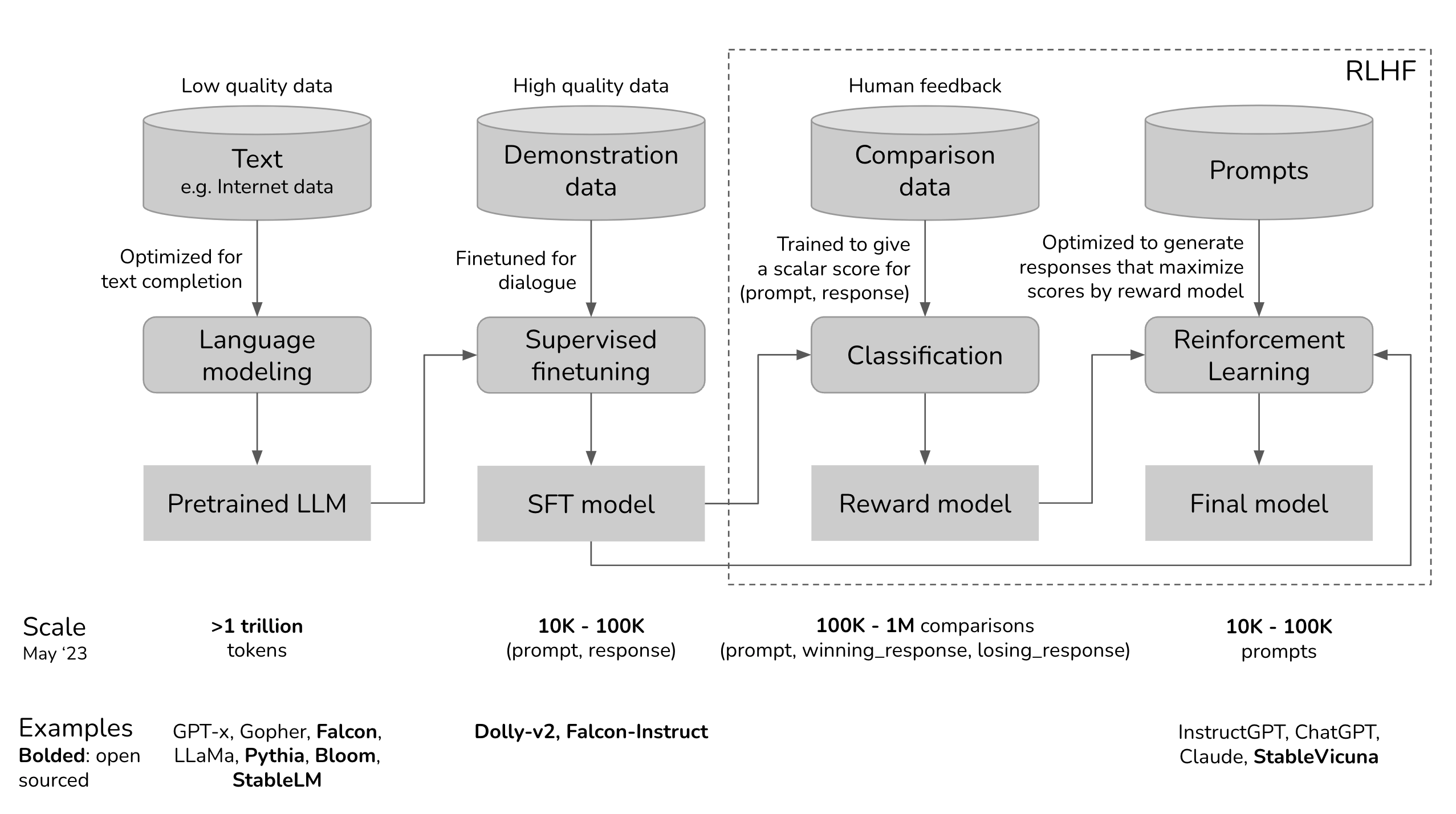
As shown in the diagram above, the complete training pipeline for a chat-based LLM typically involves these three steps: Self-Supervised Pre-Training, Supervised Fine-Tuning, and Reinforcement Learning from Human Feedback. There are specific terms to note in each stage:
- Stage 1 (Self-Supervised Pre-Training): Pre-trained LLM
- Stage 2 (Supervised Fine-Tuning): SFT LLM
- Stage 3 (Reinforcement Learning from Human Feedback): Reward Model and Final Model
3 Stage 1: Self-Supervised Pre-Training
The first stage of training is Self-Supervised Pre-Training, which aims to train the LLM on a vast amount of unlabeled data (typically text found across the internet). There are usually two training methods: one is called Masked Language Modeling (MLM), and the other is Causal Language Modeling (CLM).
The MLM task is essentially “fill-in-the-blanks.” We mask some tokens in a sentence, feed the sentence to the LLM, and have it predict what the masked tokens are. During the MLM process, the LLM learns to understand the meaning of the unmasked tokens in the sentence to predict the masked ones.
On the other hand, the CLM task is “next-token prediction.” We show the LLM the first N tokens of a sentence and want it to predict the (N+1)-th token. In this process, the LLM learns the meaning of the first N tokens to predict what the most suitable (N+1)-th token should be.
In the Self-Supervised Pre-Training step shown in the diagram, the LLM learns “next-token prediction” (CLM) from a massive amount of text data. The model after this first stage of training is called a Pre-trained LLM.
4 Stage 2: Supervised Fine-Tuning
The second stage of training is Supervised Fine-Tuning. Since it’s “Supervised,” we know that this stage requires “labels.” The dataset used here is often called Instruction-Following Data or Demonstration Data, and its format is typically [Prompt, Response].
We input a Prompt into the LLM and train it to output the corresponding Response. Sometimes, this [Prompt, Response] training data cannot be simply scraped from the web and requires humans to label it, making the dataset cost relatively higher than in the first stage.
Why does a Pre-trained LLM need to be Supervised Fine-Tuned on this [Prompt, Response] data? The main reason is that a Pre-trained LLM is a master of “next-token prediction.” Given a prompt, its response can have many possibilities because, from a next-token prediction perspective, all these responses could plausibly follow the given prompt.
For example, if we give a Pre-trained LLM the prompt “How to make a pizza,” its response could be “for a birthday party,” “and a cake,” or “Step 1: You will need…”. We can clearly see that the third response is the one we “prefer”!
Therefore, in this stage of training, we use a lot of [Prompt, Response] data to teach the Pre-trained LLM what kind of response we “prefer” for a given prompt.
I emphasize “prefer” here because the primary goal of this stage and the next (Reinforcement Learning from Human Feedback) is more akin to Preference Learning—training the LLM to output a human-preferred response, rather than teaching it new knowledge (you can think of the necessary knowledge as already having been learned during the pre-training stage). The LLM that has gone through this stage of training is usually called an SFT LLM.
5 Stage 3: Reinforcement Learning from Human Feedback
The third stage of training is Reinforcement Learning from Human Feedback, abbreviated as RLHF.
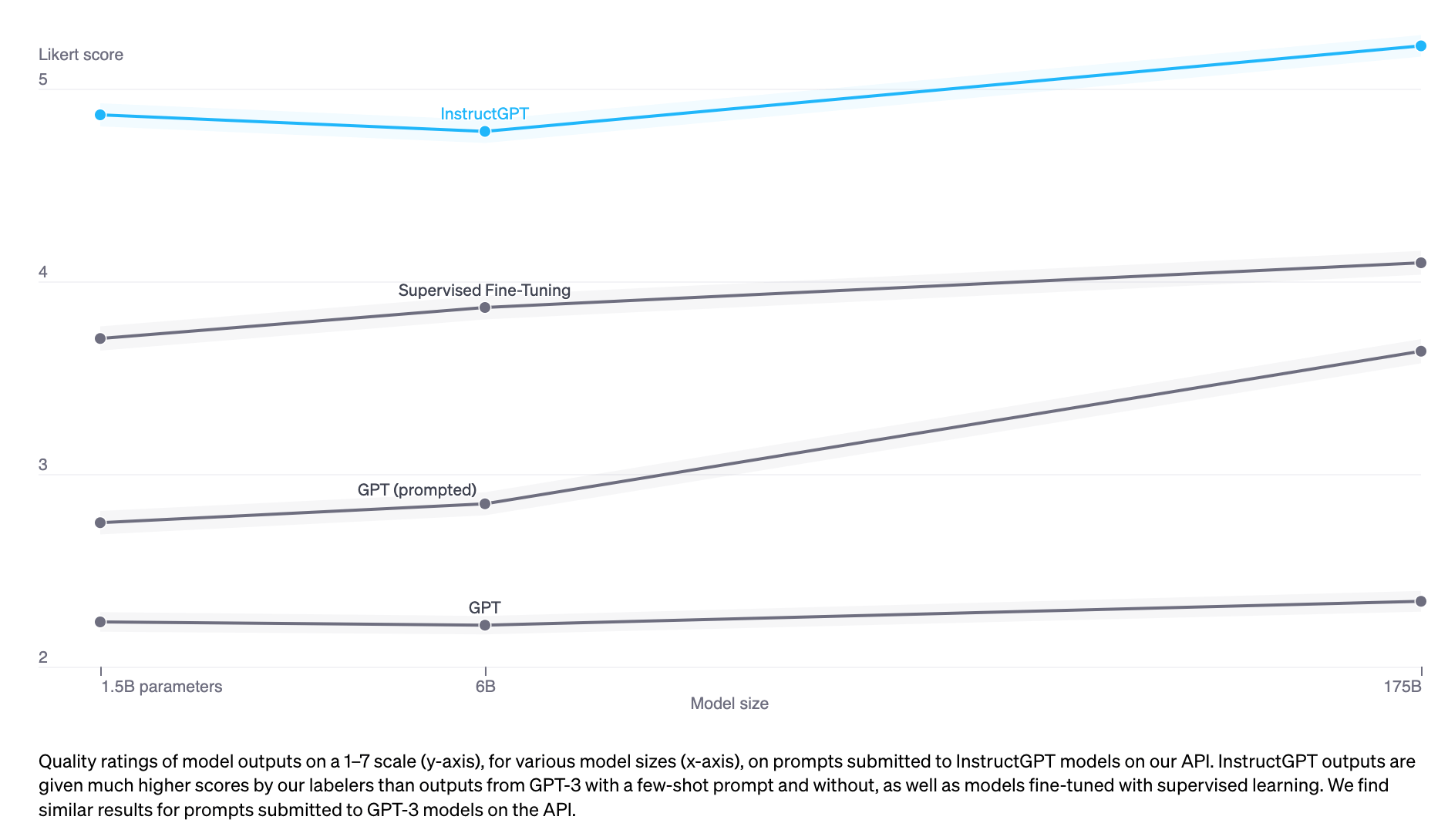
As the figure above shows, from an experimental results perspective, a model trained with RLHF (InstructGPT) performs better than models that have only undergone Supervised Fine-Tuning or Self-Supervised Pre-training.
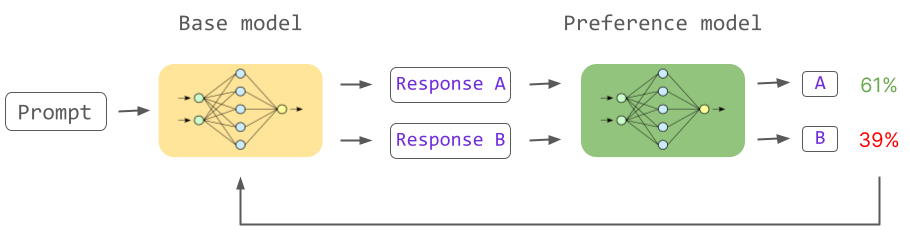
The diagram above illustrates the process of training an LLM with RLHF: the Base Model is the SFT LLM obtained from the second stage, and the Preference Model is the Reward Model. We give the SFT LLM a prompt and generate multiple different responses through sampling. These responses are then fed into the Reward Model to be scored (each response is given a reward).
In RLHF, we aim to use an RL algorithm (e.g., Proximal Policy Optimization, PPO) to train the SFT Model to maximize the reward it receives. You can see that the Reward Model plays a crucial role in this process, as it scores the SFT LLM’s responses, and the SFT LLM, in turn, updates itself based on these scores to achieve the best possible score.
In other words, if the Reward Model is of poor quality, one can imagine that the final trained LLM will inevitably be poor as well. So, how is the Reward Model trained? First, let’s clarify the Reward Model’s Input, Output, and Objective:
- Input: A piece of text (composed of a Prompt and a Response)
- Output: A single number (the Reward given to the LLM, which is the score for the response)
- Objective: Better (Human-Preferred) responses should receive a higher reward; conversely, worse (Human-Dispreferred) responses should receive a lower reward.
To train such a Reward Model, we need to create a Preference Dataset:

The image above shows a sample from the Preference Dataset:
For a given prompt, we prepare a good (Human-Preferred) response (winning_response) and a bad (Human-Dispreferred) response (losing_response).
We feed data into the Reward Model twice: the first input is the text composed of the Prompt and the winning_response, and we get a reward (winning_reward); the second input is the text composed of the Prompt and the losing_response, and we get another reward (losing_reward).
We want the Reward Model to output a winning_reward that is as high as possible and a losing_reward that is as low as possible!
Specifically, we want to minimize the following Loss Function:
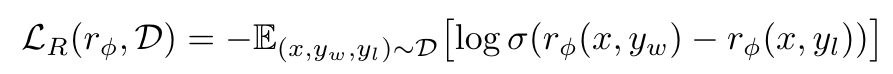
Because of the negative sign at the beginning, when the Reward Model minimizes this Loss Function, it is actually maximizing the difference between winning_reward and losing_reward within the Sigmoid function, thereby making winning_reward larger and losing_reward smaller.
Finally, since the quality of the Reward Model is extremely important, we must ensure it has at least the same level of text comprehension as the SFT LLM. Therefore, it is common practice to copy the original SFT LLM to serve as the initial parameters for the Reward Model.
At this point, you should have a general understanding of the role of the Reward Model and how it is trained! With the Reward Model, we can then proceed to train the SFT LLM using RLHF. In RLHF training, we aim to solve the following optimization problem:
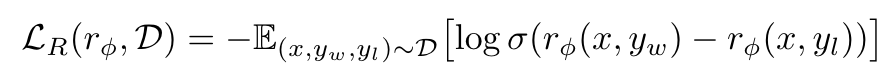
From this mathematical expression, we can understand that this optimization problem aims to find a set of LLM parameters, , such that given a prompt sampled from a dataset , the LLM will output a response :
- First Term: The [Prompt , Response ] pair should make the Reward Model’s output as large as possible.
- Second Term: Additionally, the KL Divergence between the LLM’s parameters and a Reference LLM should be as small as possible.
The first term should be straightforward—it’s about maximizing the received reward. But what does the second term mean?
In fact, the KL Divergence term in the second part plays a very important role in the RLHF stage!
Through KL Divergence, we calculate the distance between the parameters of the LLM being trained, , and the parameters of the Reference LLM, . The negative sign in front of the KL Divergence term means we want the distance between and to not be too large. The so-called Reference LLM is simply the SFT LLM obtained after the second stage of Supervised Fine-Tuning.
In other words, the introduction of KL Divergence is precisely to prevent the LLM from learning “Reward Hacking” tricks to maximize its reward (e.g., consistently outputting a certain pattern of response that yields a high reward from the Reward Model without genuinely understanding what a human-preferred response is). This prevents the parameters from being updated too drastically and diverging too far from the original parameters .
6 Why Can Reinforcement Learning from Human Feedback Improve the Performance of a Supervised Fine-tuned LLM?
Why does RLHF lead to better LLM performance? While there may not yet be a theoretical proof, from a more intuitive perspective, you can see a significant difference between the third stage (RLHF) and the second stage (SFT):
- SFT: Tells the LLM, given this prompt, this response “is the correct one,” using demonstration data.
- RLHF: Tells the LLM, given this prompt, “how correct” this response is, using a reward model.
Furthermore, in RLHF, the LLM has the opportunity to generate suboptimal responses and receive a lower reward from the Reward Model, teaching it how poor those responses are. This allows the LLM to learn what constitutes a good response and what does not.
Finally, to clarify the HF (Human Feedback) in RLHF, it signifies that the feedback, or reward, that the LLM receives ultimately comes from humans. This is because the Preference Dataset used to train the Reward Model is built based on human preferences.