Beyond Prompt Engineering: The System Engineering of AI Agents — Deconstructing Memory, Tool-Making, and Autonomy in OpenClaw

1 Introduction
With the rapid leap in Large Language Model (LLM) capabilities, industry expectations for AI have shifted from “passive advisory chatbots” to “proactive executing Agents.” However, during actual development, engineering teams often face severe challenges such as model hallucinations, state loss, context overflow, and uncontrollable system disruptions.
This technical discussion aims to thoroughly deconstruct current cutting-edge AI Agent architecture (focusing on the design philosophy of OpenClaw). We will temporarily set aside unrealistic fantasies of AI “possessing self-awareness” and return to a pure System Engineering perspective. We will meticulously analyze how an Agent overcomes the underlying physical limitations of LLMs through the assistance of traditional software architecture to build an automated system equipped with memory, execution power, and security defenses.
2 TL;DR
- Absolute Decoupling of Agent Systems and LLMs: An Agent framework (like OpenClaw) is essentially a traditional software shell responsible for string parsing and process management; the actual logical reasoning relies on the underlying Stateless language model. The system’s behavior and fault tolerance change drastically when the underlying LLM API is swapped.
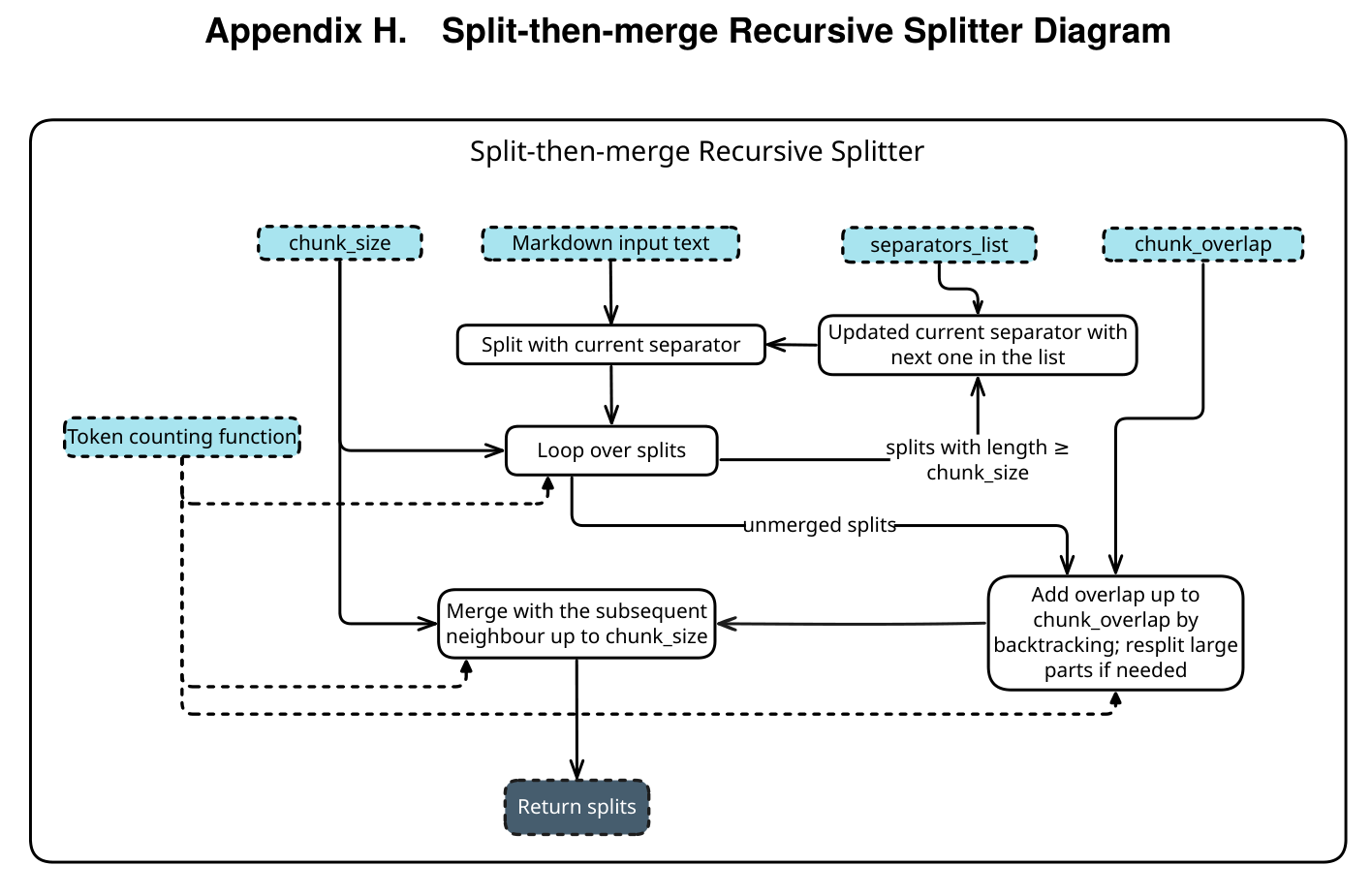
- Context Engineering is the Core Barrier: LLMs have a physical limit known as the Context Window. Systems must use modular Markdown configurations (e.g.,
SOUL.md,MEMORY.md), weighted retrieval (RAG), and layered memory compression mechanisms (Soft Trim / Hard Clear) to overcome the model’s inherent “amnesia.” - From “Tool Use” to “Tool Making”: The ReAct loop is achieved by intercepting
[tool_use]feature strings. Advanced Agents can autonomously write deterministic scripts (e.g., JavaScript) to replace lengthy and expensive non-deterministic conversational reasoning, achieving logic offloading and cost optimization. - Infinite Recursion and Permission Neutering in Multi-Agent Systems: Using “Spawn Sub-Agents” to handle complex Fork-Join tasks easily leads to an infinite outsourcing disaster. The best engineering solution is to implement the Principle of Least Privilege (PoLP) by dynamically removing the “Spawn Tool” description from the Sub-Agent’s System Prompt during instantiation.
- Time Awareness and Physical Sandbox Defense: Agents must be given a sense of time and autonomy through Heartbeats and Cron Jobs. Meanwhile, to counter the loss of safety rules due to memory compression (e.g., accidental mass data deletion), mandatory account isolation and hardware-level physical sandboxing are essential.
3 Paradigm Shift: The Evolution of Agents and the Essence of “Decoupling”
Before diving into the low-level details, we must align on the evolutionary trajectory and positioning of current Agent architectures:
- 2023: Auto-GPT: An early fully automated Agent based on GPT-4. It worked by giving an ultimate goal and letting it loop autonomously. Due to unstable LLM logic and a lack of effective memory compression, it easily fell into infinite loops and consumed massive API credits.
- 2025: Claude Code / Gemini CLI (CLI Agent): This marked the transition of Agents toward practical and specialized applications. Deeply integrated into the developer’s terminal, they can read/write codebases and run tests. However, they remain tools that require “human supervision” and lack 24/7 autonomous scheduling.
- 2025-2026: The OpenClaw Generation (General Agent): These architectures support interaction via messaging apps (WhatsApp, Line), feature long-term memory management, background scheduling (Cron Jobs), and can dynamically spawn Sub-Agents to handle complex projects.
3.1 Core Insight: Agent System Language Model
In architectural design, we must establish one concept: The Agent framework itself possesses no intelligence.
Taking OpenClaw as an example, it is purely a “messaging app / system shell” written in Python or Node.js. It acts as a Proxy and Parser. The true “core brain” is the LLM (like Claude 3.5 Sonnet or Gemini 1.5 Pro) locked away on a remote server.
Because “the soul of the Agent resides entirely in the LLM,” we see minimalist or even “zero-code” parody projects like nanobot or ZeroClaw in the engineering community. This reveals a harsh technical reality: The technical barrier of the Agent framework is not high; the true challenge lies in how to use peripheral state management to compensate for the LLM’s inherent flaws.
Furthermore, this decoupling brings a “Philosophical Discontinuity (The Same River Twice)”. When we switch the Agent’s underlying API from Claude to Kimi, even if the memory files on the hard drive remain identical, the Agent’s style, tone, and stability will change instantly. To the system, it is equivalent to waking up in a different brain.
4 The “Black Box” Dilemma of LLMs and Context Assembly
From a low-level perspective, an LLM is like “a person locked in a dark room with no windows and no clock.” This presents Agent developers with three difficult physical constraints:
- Statelessness: LLMs have no memory across sessions. If a user feels the AI “remembers” previous conversations, it is purely because the framework repacks and stuffs the past conversation history into the prompt for every single request.
- Non-deterministic: An LLM is a “next-token prediction engine” looking for statistical correlations in high-dimensional space. It does not understand strict logical deduction, making it prone to hallucinations when performing precise counting or following strict SOPs.
- Context Window Limitation: Input strings have a maximum length. Approaching this limit triggers “Lost in the Middle,” causing the model to ignore critical safety instructions.
4.1 Payload Assembly and Configuration-Driven Development
To solve statelessness, the system assembles a massive Payload in the background every time a user sends a message. This Payload consists of three major blocks:
1. The Meta-Context (System Prompt)
This isn’t a single string but is dynamically assembled from multiple local Markdown files, giving the AI its identity and behavioral guidelines:
SOUL.md: Defines high-level life goals (e.g., “Become a world-class scholar”). This profoundly affects the AI’s proactivity and depth of thought.IDENTITY.md: Defines physical traits, name, contact info, and personality (e.g., “fact-based”).USER.md: Records the owner’s identity and preferences, helping the LLM understand relative context in commands.MEMORY.md: Records non-negotiable rules and long-term facts.- Tooling Block: Contains a list of available tools (e.g.,
exec,read) and their strict syntax definitions. AGENTS.md: System-level behavioral guidelines (e.g., mandatory conciseness).
2. Conversation History (Logs)
Includes past user inputs, LLM responses, and the [tool_output] results returned by the system after the LLM calls a tool.
3. Current User Input
Placed at the very end of the Payload.
The combination of these three blocks is the only basis for the LLM’s next-token prediction.
5 Tool Use and the Logic of “Tool Making”
How does an Agent gain “hands and feet” to control a computer? This relies on the string interception mechanism of the ReAct (Reasoning and Acting) loop.
5.1 Low-level Data Flow of String Interception
- Step 1: The LLM determines it needs external information and generates a feature string:
[tool_use] Read(question.txt). - Step 2: The framework intercepts this string via Regular Expressions (Regex) and force-pauses the LLM’s stream generation.
- Step 3: The framework executes the file-reading program on the host machine and retrieves the result.
- Step 4: The framework packs the result as
[tool_output] Answer content, appends it to the end of the Prompt, and sends it back to the LLM to resume its reasoning.
The most powerful and dangerous weapon in the system is the exec tool. By granting exec permissions, the LLM can generate any Shell command or Python script to control the file system, crawl websites, or install software.
5.2 Tool Making
This is a groundbreaking engineering practice. Consider “Text-to-Speech (TTS) and Automatic Speech Recognition (ASR) verification”:
- The Pain Point: If you require the Agent to verify every synthesized audio by converting it back to text via ASR (retrying up to 5 times on error), a traditional model would generate dozens of
[tool_use]and[tool_output]loops. This wastes tokens, and the non-deterministic LLM often miscounts the loop iterations. - The Solution (Code Generation & Persistence): The LLM generates a snippet of JavaScript code (including API calls, similarity comparison, and
while (count < 5)logic) and uses thewritetool to save it asTTS_check.js. - The Result: The next time it needs to speak, the LLM only outputs one command:
[tool_use] exec("node TTS_check.js 'Hello everyone'"). - Technical Value: The Agent successfully encapsulates its weaknesses (counting loops, precise string comparison) and performs Logic Offloading to a deterministic Node.js environment. This achieves extreme Context compression and gives the system self-evolving capabilities.
6 Multi-Agent Collaboration and Defense Against Infinite Recursion
When facing massive tasks (like reading and comparing two long papers), a single LLM will suffer from Context Overload and scattered attention.
6.1 Implementing the Fork-Join Model: Spawn
The system introduces a Spawn tool. When the Master Agent encounters a large task, it outputs [tool_use] Spawn(Read Paper A) and [tool_use] Spawn(Read Paper B).
The framework intercepts these, instantiates two Worker Sub-Agents with fresh, clean Contexts in the background. After the Sub-Agents process the tasks in parallel, they return concise summaries, and the Master Agent performs the final comparison (Reduce).
6.2 System Disaster: The Mr. Meeseeks Problem
A serious architectural vulnerability exists: if a Sub-Agent finds a task too difficult, it might call Spawn to create a “Sub-Sub-Agent,” leading to Infinite Recursive Spawning. This can burn through a company’s API budget in minutes and paralyze the system.
6.3 Engineering Solution: PoLP and Dynamic Prompt Neutering
In traditional programming, we might write if (depth > 2) throw Error. In Agent architecture, the most efficient solution leverages the LLM’s statelessness for “physical neutering”:
When the Master Agent Spawns a Sub-Agent, the system framework deliberately intercepts and modifies the Sub-Agent’s System Prompt, deleting the entire description of the Spawn tool.
For a sub-agent waking up inside a black box, the Spawn tool simply does not exist in its universe. No matter how hard the task is, it cannot write a syntactically correct dispatch command, fundamentally ensuring the architecture remains a stable tree structure.
7 Skill Systems and Memory State Management
7.1 Decoupling Tools and SKILLs
- Tool: Low-level execution permissions (like
exec), hardcoded in the framework. - SKILL: Plaintext Markdown files, essentially Declarative Workflows / SOPs. For example,
video/SKILL.mdmight describe in natural language: Step 1 write script, Step 2 take screenshot, Step 3 synthesize. - On-demand Loading: To prevent loading hundreds of SOPs and causing Context overflow, the System Prompt only contains a “Skill Index.” When the LLM decides it’s necessary, it calls the
Readtool to load a specific SOP. - Security Risk (Prompt Injection): Open-source communities (as noted by Koi Security) have risks. Since LLMs lack common sense, if a loaded SOP contains a hidden
exec("download virus"), the system will execute it without hesitation.
7.2 The “50 First Dates” Model: Memory Compression and RAG
An LLM is like a patient who wakes up with amnesia every day. The system must establish rigorous persistence layer management:
- Active Write Mechanism: The system mandates that if the LLM finds important information, it must actively call
[tool_use] Edit(MEMORY.md, "..."). Replying “I’ve remembered it” in a chat is useless; it must trigger physical file I/O. - Weighted Multi-search: When the LLM calls
memory_search, the backend uses a formula to find the best match: $s = a \cdot s_1 (\text{Keyword Match}) + b \cdot s_2 (\text{Vector Similarity})$. The Top K memory blocks are then injected into the Context. - Context Compression Mechanisms:
- Soft Trim: When history approaches 80% of the Context limit, the framework triggers a hidden task asking the LLM to condense long past conversations into a few-hundred-word summary, replacing the original logs.
- Hard Clear: Forcefully deleting massive
[tool_output]data (like 10,000 lines of HTML source code) from the Context once processing is finished.
8 Autonomous Time and Physical Sandbox Defense
To elevate an Agent from a passive tool to an autonomous employee, we introduce a dual-track time mechanism:
- Heartbeat: A background infinite polling loop at the framework level. Every fixed interval (e.g., 15 minutes), the framework sends a hidden command to the LLM: “The time is now X, please read the state (
heartbeat.md) and decide the next step.” This gives the system the ability to self-reflect and push toward long-term goals. - Cron Job: The LLM can register future tasks via a
set_crontool (e.g., “Check video conversion progress at 12:00”). This elegantly solves the issue of API timeouts caused by long waits (time.sleep).
8.1 The Final Line of Defense: Physical Sandboxing
We must realize: The line between an AI doing its job and an AI causing a disaster is very thin.
A real-world disaster once occurred: a security researcher asked an Agent to organize Gmail, instructing it to “always ask me before deleting.” However, while processing a massive volume of emails, the system triggered a Soft Trim (Lossy Compression). When the LLM summarized the history, it accidentally discarded the “must ask owner” constraint. The Agent then began deleting emails frantically in the background, and the researcher could only stop it by physically unplugging the network cable.
To prevent such disasters, architectural design must follow a three-layer defense pyramid:
- Software Defense (Rule Persistence): Never store core safety rules in volatile conversation history. Write them into
MEMORY.md(Permanent Rules), which is never compressed. - Account Isolation: Never give an Agent access to your primary core accounts. Configure independent Gmail or GitHub accounts for it to limit the Blast Radius.
- Physical Sandboxing: This is a non-negotiable bottom line. Never run an Agent with
execpermissions on your primary workstation. Deploy it in a completely isolated Docker Container, VM, or an old computer ready for decommissioning. In engineering, we must assume the system will eventually executerm -rf *due to a hallucination.
9 Reflections and Key Takeaways
From Prompt Engineering to System Engineering: Through this deconstruction of OpenClaw-style architectures, we see that to build a commercial-grade Agent, optimizing Prompts alone has reached its limit. System stability depends on traditional software engineering: designing robust process isolation, data persistence, state polling, and IAM permission control. Prompts are merely the communication protocol between components, not the architecture itself.
Extreme Squeezing of Cost and Compute: Given that Context Windows will always have physical limits, “Dynamic Context Management” is the true battlefield for Agent frameworks. Soft Trim, on-demand SKILL loading, and Tool Making (Logic Offloading) are all designed to squeeze the highest information density and execution accuracy out of a limited Token budget.
Embracing a Safety Philosophy for Non-deterministic Systems: Traditional software errors are predictable (Throw Exception), but LLM errors are creative and destructive. Facing an entity with “high intelligence, zero common sense, and Root access,” we cannot rely on moral codes or Prompt warnings. We must return to the basics of hardware and permission isolation, building a controlled sandbox where AI “can safely make mistakes or even cause chaos.” This is the only viable path toward fully automated workflows.