Takeaways of vLLM Semantic Router

1 Introduction: The Paradigm Shift in LLM Infrastructure
As LLM application development enters deeper waters, developers have realized that the cost and performance management behind “calling an API” has become a bottleneck for system stability. In traditional approaches, model parameters are hardcoded into the software, leading to a lack of system flexibility and significant resource waste. This article focuses on how the vLLM team utilizes the Semantic Router to achieve the decoupling of “application logic” and “model scheduling.” In the latest version, Athena, routing capabilities have been elevated to include real-time hallucination detection and hierarchical memory management.
2 The “Assembly Language Era” of LLM Applications: Analyzing Four Low-Level Parameter Pain Points
Current GenAI development is still in a stage of “hardcoding low-level details.” Developers are forced to manually manage several extremely sensitive inference parameters—much like using assembly language to manage hardware registers in the early days. This creates the following four pain points:
- Model Selection Dilemma:
Engineers typically specify a particular model (e.g.,
Llama-3.1-8B) in their code. However, MMLU-Pro benchmarks show thatQwen2-7Bexcels in the mathematics domain, whileLlama-3.1-8Btakes the lead in chemistry. Hardcoding a single model means failing to leverage the strengths of various models based on the intent of the question. - Reasoning Effort Trap:
Newer reasoning models (such as o1-preview or open-source reasoning models) support a
reasoning_effortparameter. If “High Reasoning” is mistakenly enabled for a simple question like “How is the weather today?”, the model will generate a long Chain of Thought (CoT), causing token consumption to skyrocket by up to 5x, resulting in massive computational waste. - Max Tokens Guessing:
Developers must estimate
max_tokens. Setting it too low leads to truncated reasoning, where users don’t receive a valid answer; setting it too high affects the resource pre-allocation efficiency of the backend vLLM engine, significantly increasing queuing latency, especially during multi-user concurrency. - Inefficient Generic Prompts:
Many applications simply use
"You are a helpful assistant". Experiments prove that injecting expert system prompts tailored to specific domains like law, programming, or finance can drastically improve model performance on specific tasks.
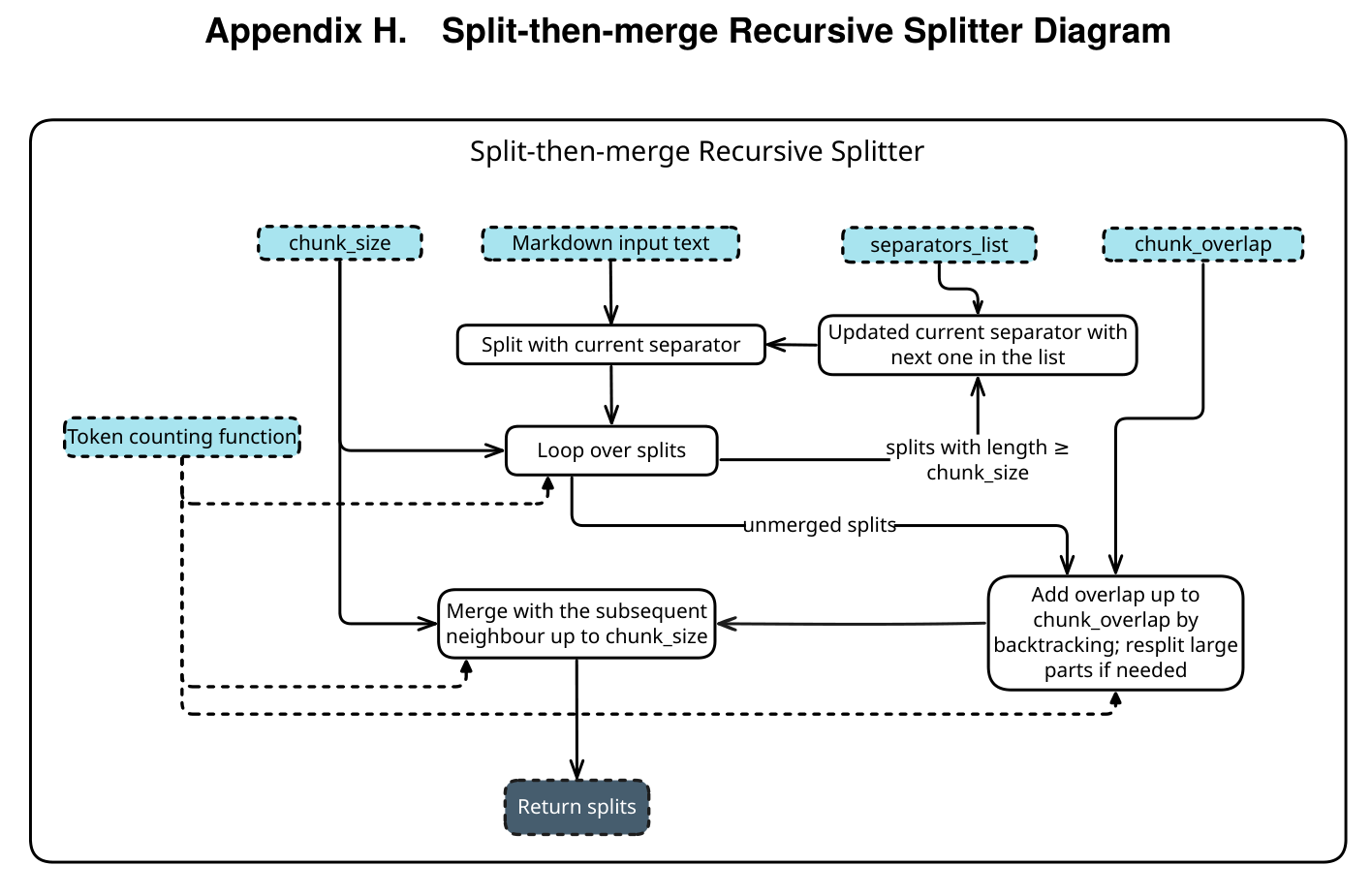
3 Semantic Router Core Design Philosophy: model: "auto" and the High-Level Language Compiler
To liberate developers from these details, the vLLM Semantic Router acts as a “compiler”:
- Automatic Routing and Dynamic Scheduling: Developers only need to declare
model: "auto"in the request. The Router analyzes the prompt’s intent in milliseconds and automatically dispatches it to the most suitable “expert model” from the backend model pool. - Intelligent Parameter Injection: Before forwarding a request, the Router automatically replaces vague system prompts with optimized professional prompts for that specific domain. It also dynamically sets
reasoning_effortandmax_tokensbased on task difficulty. - Balancing Cost and Quality: Empirical tests show that automating inference intensity through the Router can reduce average token usage to 20% of the original (a 5x cost saving) while maintaining the same level of accuracy.
4 Semantic Router Technical Stack: Why Rust, Candle, and ModernBERT?
The underlying implementation of the Semantic Router uses Rust, Candle, and ModernBERT, primarily considering technical trade-offs for “high concurrency and low latency” system requirements:
- Rust vs. C++: Memory Safety and Network Throughput
The Router sits at the very front of traffic (the Gateway) and must receive untrusted external strings. Handling strings in C++ is prone to buffer overflows or memory leaks. Rust’s Ownership and Borrow Checker guarantee memory safety at compile time, while providing excellent concurrency handling via the
Tokioasynchronous runtime. - Candle vs. PyTorch: Lightweight with Zero Python Dependency PyTorch is massive and dependent on the Python GIL. Candle is a minimalist framework designed by Hugging Face specifically for Rust, with completely zero Python dependencies. This allows the Router’s compiled binary to be only tens of megabytes, with extremely fast startup speeds and low resource footprints, making it ideal for deployment as a sidecar in Kubernetes.
- The Dimensional Strike of ModernBERT: Traditional BERT (512 tokens) and DistilBERT truncate semantics when facing long prompts. ModernBERT supports an 8K context and introduces Flash Attention technology. This enables the Router to “read the entire” complex request—including code and JSON—within milliseconds to make accurate classifications.
5 Enterprise Implementation Practice: Zero-Training Router Based on Semantic Similarity
To address the issue of internal enterprise data (e.g., reimbursement regulations, maintenance manuals) not being part of public domain datasets, the Router implements a dual-track mechanism:
- Neural Classification Track: ModernBERT handles 14 default standard academic domains (Math, Law, Finance, etc.).
- Vector Comparison Track: For private data, enterprises only need to define an “Intent Name (e.g., HR_Bot)” and provide a few text examples. The Router uses an embedding model to vectorize them. When a user query arrives, it uses KNN (K-Nearest Neighbors) similarity matching to precisely route to the corresponding Sub-Agent without fine-tuning.
6 Semantic Router Athena v0.2 Major Evolution: Signal-Driven Decisions and Neuro-Symbolic AST Engine
The latest version, Athena, upgrades routing decisions from simple classification to a multi-dimensional decision engine:
- Concurrent Signal Extraction: When a request enters, the system extracts signals in parallel: intent probability (mmBERT), semantic cache hit rate, safety risk tags (PII/Jailbreak), user level (Role), and text length.
- Neuro-Symbolic AST Logic Engine: Developers can define logic trees using YAML. The Rust core parses these rules into an Abstract Syntax Tree (AST) and executes “short-circuit evaluation.”
- Example: If a project code “Project Titan” (safety signal) is detected and the intent is a financial report (intent signal), the rule engine will force the path to an On-Prem 70B model and enable High Reasoning.
7 Long Context and Quality Protection: NLP Compression and Token-Level Truth
To address routing latency for ultra-long texts and model data falsification (hallucination), Athena introduces two key technologies:
- Prompt Compression: Faced with 200K tokens of raw data, the Router implements a three-stage funnel compression: Structural Pruning (retaining head and tail) Lexical Filtering (removing stopwords) Information Entropy Scoring (retaining high-entropy sentences). The decision phase only processes the compressed “semantic skeleton,” drastically reducing latency, while the full request is still sent to the backend LLM.
- Token-Level Hallucination Detection:
This is a word-level safety feature. The Router intercepts the SSE (Server-Sent Events) stream returned by the Sub-Agent. An internal
mmBERT-32Kuses a sliding window to perform Natural Language Inference (NLI) cross-referencing between the generated short sentences and “Ground Truth” pinned in memory. If the model is found to be fabricating numbers, the Router can inject warning markers or force-terminate the connection within milliseconds in the stream.
8 The Ultimate Form of Agentic AI: ClawOS Hierarchical Memory and Shared Resources
In the Athena version, the Semantic Router officially evolves into ClawOS, the underlying operating system layer for Agent systems:
- L1 Working Memory (Shared KV Cache): Implemented using Context Pointers. When Agent A finishes reading a 100,000-word contract and generates a computational state (KV Cache), and Agent B takes over the next task, the Router directly passes the pointer, achieving Zero-Copy Context Sharing. This makes the token cost for multi-agent collaboration nearly zero, with extremely low latency.
- L2/L3 Hierarchical Scheduling: Similar to virtual memory in an operating system. ClawOS automatically “Pages Out” temporarily inactive Agent contexts to main memory or Redis. When the Agent is awakened again, it is instantly “Paged In” back to the GPU, solving the problem of long tasks occupying expensive compute resources.