Intorduction to LangMem
1 Introduction
This article serves as notes for the DeepLearning.AI course, Long-Term Agentic Memory with LangGraph. It is hoped that through this article, readers can understand the basic concepts of Agent Memory and how to implement Agent Memory using LangMem!
2 Why Does an Agent Need Memory
Before understanding Agent Memory, let’s first consider this question:
Why does an Agent need Memory?
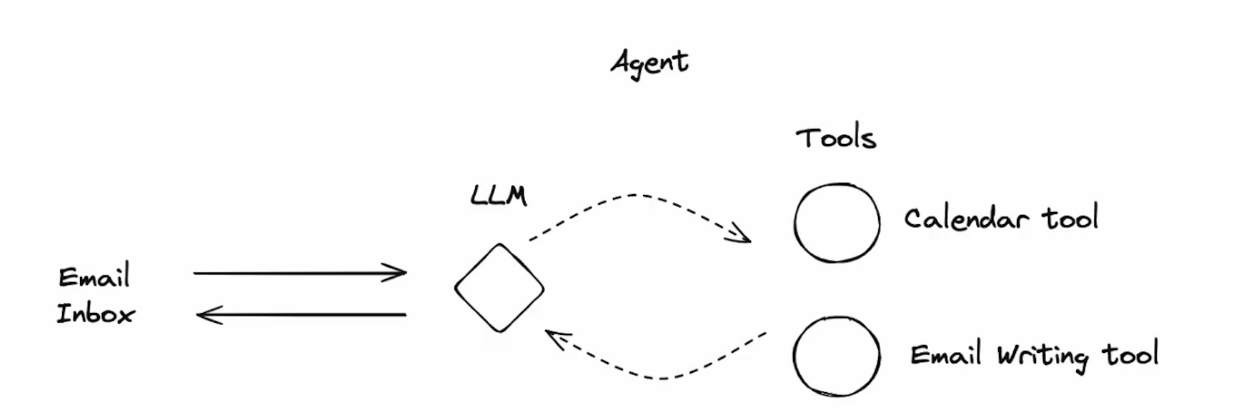
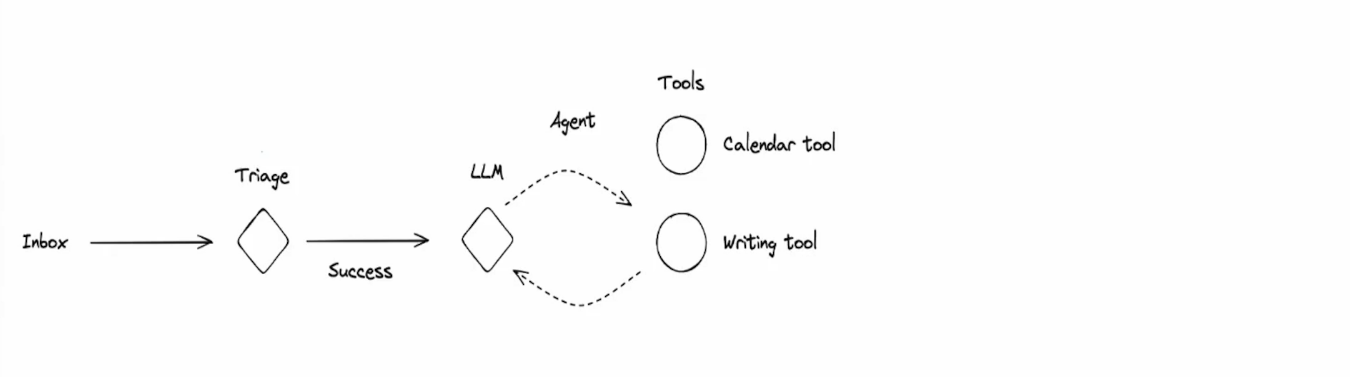
The author uses an Agent capable of automatically replying to emails as an example. As shown in the figure below, this LLM needs to read the email content, then check the recipient’s calendar using Tool Calling (Calendar Tool), and finally use Tool Calling to draft the email content (Email Writing Tool):
In this process, the LLM needs past experience to help it overcome some challenges. As described in the red text in the figure below:
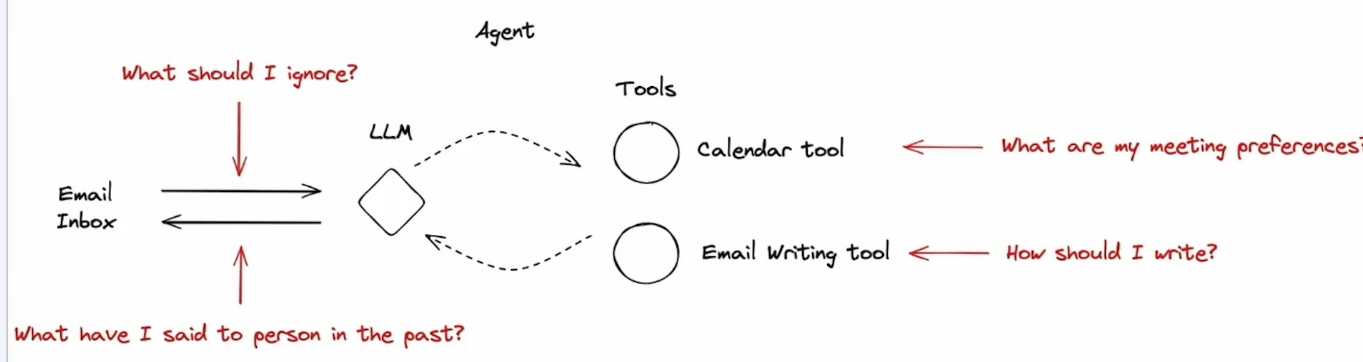
If the Agent has memory capability, it can refer to past experience to handle new tasks. This way, the Agent can become more capable as it processes more tasks and gathers more experience.
3 Types of Memory and When They Operate
Agent Memory can mainly be divided into three types:
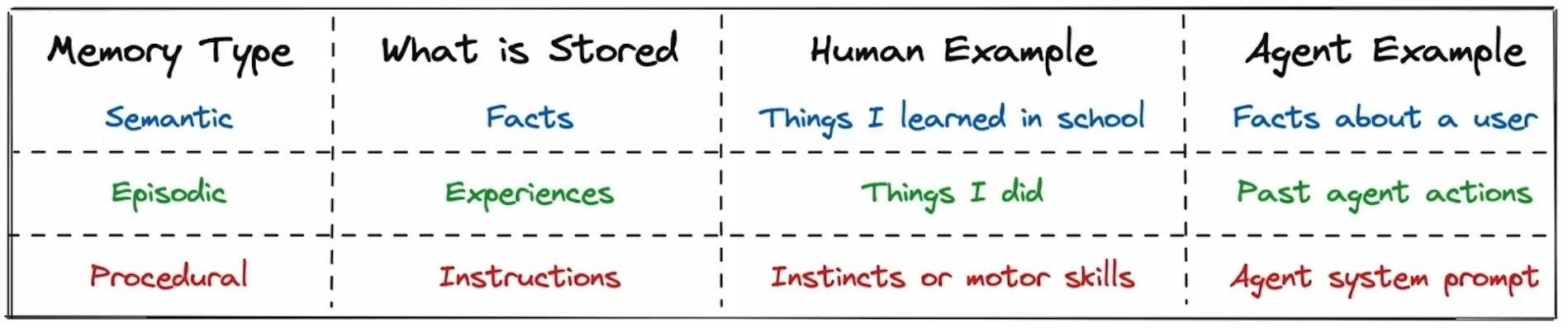
- Semantic Memory: Stores content related to “facts” (I think broadly speaking, “documents” can also fall into this category).
- Episodic Memory: Stores content related to “experiences” (Ex. Few-Shot Examples placed in the Prompt).
- Procedural Memory: Stores content related to “instructions” (Ex. System Prompt given to the LLM).
And there are two main operating times for Agent Memory:
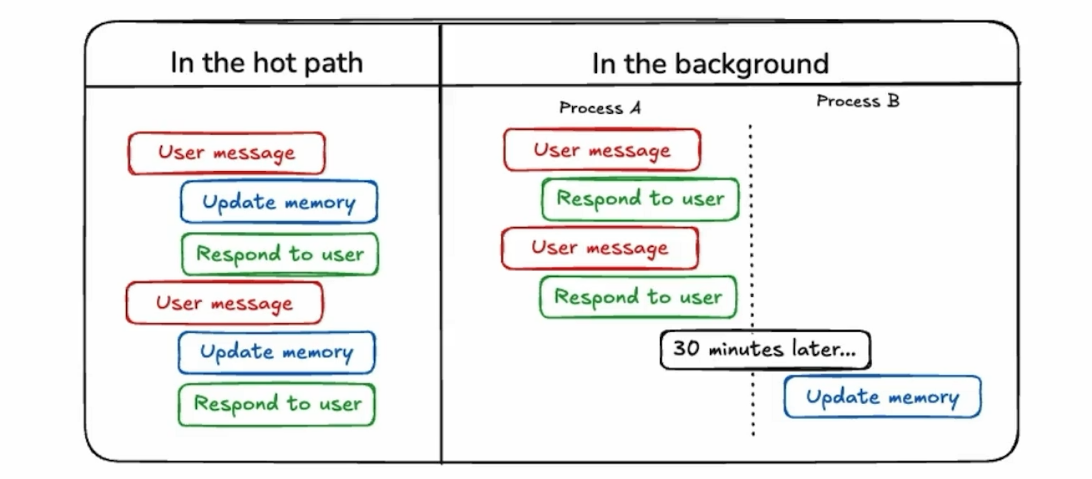
- In the hot path: Memory is read and written every time a User Query is received.
- In the background: Memory is periodically read and written during the Agent’s operation.
4 Email Agent w/ & w/o Memory
Having understood the basic concepts of Agent Memory, let’s look at how Memory operates in the Email Agent. The figure below shows the workflow of a basic Email Agent without using Memory:
And the figure below shows the workflow of an Email Agent using Memory:
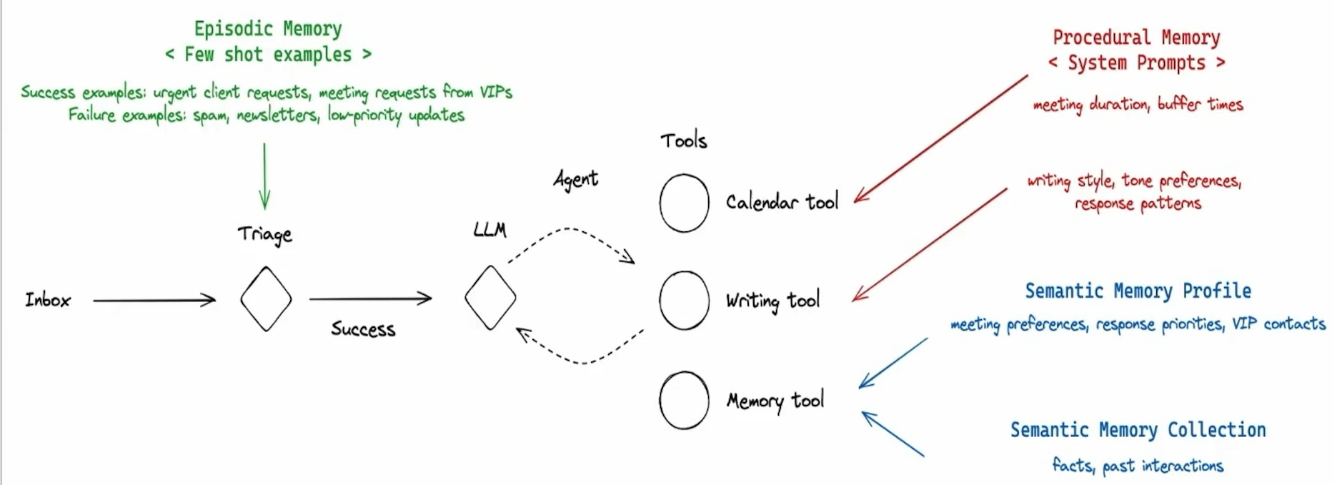
It can be observed that:
- Episodic Memory: Essentially, it’s the Few-Shot Examples placed in the Prompt, helping the LLM decide if the email needs a reply.
- Procedural Memory: Essentially, it’s the content written in the LLM’s System Prompt, telling the LLM how to use the Calendar Tool and Email Writing Tool.
- Semantic Memory: Stores established facts (Ex. Response Preference).
5 Email Agent Implementation (Without Memory)
Next, let’s first implement a basic Email Agent without Memory functionality:
5.1 Triage Implementation
Triage basically involves classifying the current email through an LLM into three categories:
- ignore: Ignore this email.
- notify: This email contains important information but does not require a reply.
- respond: This email requires a reply.
from pydantic import BaseModel, Field
from typing_extensions import TypedDict, Literal, Annotated
from langchain.chat_models import init_chat_model
llm = init_chat_model("openai:gpt-4o-mini")
class Router(BaseModel):
"""Analyze the unread email and route it according to its content."""
reasoning: str = Field(
description="Step-by-step reasoning behind the classification."
)
classification: Literal["ignore", "respond", "notify"] = Field(
description="The classification of an email: 'ignore' for irrelevant emails, "
"'notify' for important information that doesn't need a response, "
"'respond' for emails that need a reply",
)
llm_router = llm.with_structured_output(Router)pydantic here to define the structured output of this Router. This approach makes the LLM’s output more structured and facilitates subsequent processing. Besides LangChain supporting this method, outlines is another option for structured text generation with LLMs.The actual usage of llm_router is as follows:
result = llm_router.invoke(
[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
)And the content of the System Prompt is as follows:
< Role >
You are John Doe's executive assistant. You are a top-notch executive assistant who cares about John performing as well as possible.
</ Role >
< Background >
Senior software engineer leading a team of 5 developers.
</ Background >
< Instructions >
John gets lots of emails. Your job is to categorize each email into one of three categories:
1. IGNORE - Emails that are not worth responding to or tracking
2. NOTIFY - Important information that John should know about but doesn't require a response
3. RESPOND - Emails that need a direct response from John
Classify the below email into one of these categories.
</ Instructions >
< Rules >
Emails that are not worth responding to:
Marketing newsletters, spam emails, mass company announcements
There are also other things that John should know about, but don't require an email response. For these, you should notify John (using the `notify` response). Examples of this include:
Team member out sick, build system notifications, project status updates
Emails that are worth responding to:
Direct questions from team members, meeting requests, critical bug reports
</ Rules >
< Few shot examples >
None
</ Few shot examples >And the content of the User Prompt is as follows:
Please determine how to handle the below email thread:
From: Alice Smith <alice.smith@company.com>
To: John Doe <john.doe@company.com>
Subject: Quick question about API documentation
Hi John,
I was reviewing the API documentation for the new authentication service and noticed a few endpoints seem to be missing from the specs. Could you help clarify if this was intentional or if we should update the docs?
Specifically, I'm looking at:
- /auth/refresh
- /auth/validate
Thanks!
Alice5.2 Tools Implementation
Next, the author defines 3 types of Tools for the LLM to use:
from langchain_core.tools import tool
@tool
def write_email(to: str, subject: str, content: str) -> str:
"""Write and send an email."""
# Placeholder response - in real app would send email
return f"Email sent to {to} with subject '{subject}'"
@tool
def schedule_meeting(
attendees: list[str],
subject: str,
duration_minutes: int,
preferred_day: str
) -> str:
"""Schedule a calendar meeting."""
# Placeholder response - in real app would check calendar and schedule
return f"Meeting '{subject}' scheduled for {preferred_day} with {len(attendees)} attendees"
@tool
def check_calendar_availability(day: str) -> str:
"""Check calendar availability for a given day."""
# Placeholder response - in real app would check actual calendar
return f"Available times on {day}: 9:00 AM, 2:00 PM, 4:00 PM"5.3 Main Agent Implementation
The task of the Main Agent is to use Tools to complete the email replying task:
from langgraph.prebuilt import create_react_agent
tools=[write_email, schedule_meeting, check_calendar_availability]
agent = create_react_agent(
"openai:gpt-4o",
tools=tools,
prompt=create_prompt,
)And the content of create_prompt here is as follows:
< Role >
You are John Doe's executive assistant. You are a top-notch executive assistant who cares about John performing as well as possible.
</ Role >
< Tools >
You have access to the following tools to help manage John's communications and schedule:
1. write_email(to, subject, content) - Send emails to specified recipients
2. schedule_meeting(attendees, subject, duration_minutes, preferred_day) - Schedule calendar meetings
3. check_calendar_availability(day) - Check available time slots for a given day
</ Tools >
< Instructions >
Use these tools when appropriate to help manage John's tasks efficiently.
</ Instructions >The usage of the Main Agent is as follows:
response = agent.invoke(
{"messages": [{
"role": "user",
"content": "what is my availability for tuesday?"
}]}
)Output of the Main Agent:
================================== Ai Message ==================================
You have the following available times on Tuesday:
- 9:00 AM
- 2:00 PM
- 4:00 PM
If you need me to schedule anything or make any arrangements, just let me know!5.4 Integrating into a Workflow via LangGraph
Finally, integrate the above Triage and Main Agent into a workflow.
from langgraph.graph import add_messages
from langgraph.graph import StateGraph, START, END
from langgraph.types import Command
from typing import Literal
class State(TypedDict):
email_input: dict
messages: Annotated[list, add_messages]
def triage_router(state: State) -> Command[
Literal["response_agent", "__end__"]
]:
author = state['email_input']['author']
to = state['email_input']['to']
subject = state['email_input']['subject']
email_thread = state['email_input']['email_thread']
system_prompt = triage_system_prompt.format(
full_name=profile["full_name"],
name=profile["name"],
user_profile_background=profile["user_profile_background"],
triage_no=prompt_instructions["triage_rules"]["ignore"],
triage_notify=prompt_instructions["triage_rules"]["notify"],
triage_email=prompt_instructions["triage_rules"]["respond"],
examples=None
)
user_prompt = triage_user_prompt.format(
author=author,
to=to,
subject=subject,
email_thread=email_thread
)
result = llm_router.invoke(
[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
)
if result.classification == "respond":
print("📧 Classification: RESPOND - This email requires a response")
goto = "response_agent"
update = {
"messages": [
{
"role": "user",
"content": f"Respond to the email {state['email_input']}",
}
]
}
elif result.classification == "ignore":
print("🚫 Classification: IGNORE - This email can be safely ignored")
update = None
goto = END
elif result.classification == "notify":
# If real life, this would do something else
print("🔔 Classification: NOTIFY - This email contains important information")
update = None
goto = END
else:
raise ValueError(f"Invalid classification: {result.classification}")
return Command(goto=goto, update=update)
email_agent = StateGraph(State)
email_agent = email_agent.add_node(triage_router)
email_agent = email_agent.add_node("response_agent", agent)
email_agent = email_agent.add_edge(START, "triage_router")
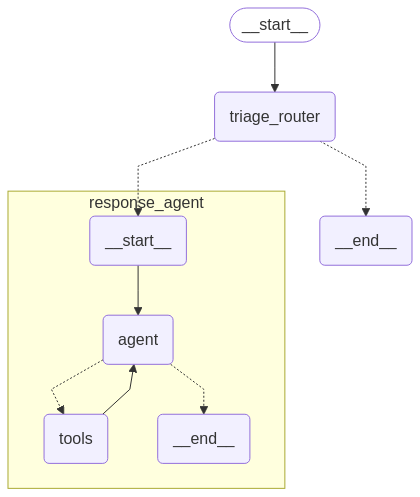
email_agent = email_agent.compile()The overall workflow of the Email Agent is shown in the figure below:
5.5 Email Agent Example Input and Output
Example Input 1: Email that does not require a reply
email_input = { "author": "Marketing Team <marketing@amazingdeals.com>", "to": "John Doe <john.doe@company.com>", "subject": "🔥 EXCLUSIVE OFFER: Limited Time Discount on Developer Tools! 🔥", "email_thread": """Dear Valued Developer, Don't miss out on this INCREDIBLE opportunity! 🚀 For a LIMITED TIME ONLY, get 80% OFF on our Premium Developer Suite! ✨ FEATURES: - Revolutionary AI-powered code completion - Cloud-based development environment - 24/7 customer support - And much more! 💰 Regular Price: $999/month 🎉 YOUR SPECIAL PRICE: Just $199/month! 🕒 Hurry! This offer expires in: 24 HOURS ONLY! Click here to claim your discount: https://amazingdeals.com/special-offer Best regards, Marketing Team --- To unsubscribe, click here """, } response = email_agent.invoke({"email_input": email_input})🚫 Classification: IGNORE - This email can be safely ignoredExample Input 2: Email that requires a reply
email_input = { "author": "Alice Smith <alice.smith@company.com>", "to": "John Doe <john.doe@company.com>", "subject": "Quick question about API documentation", "email_thread": """Hi John, I was reviewing the API documentation for the new authentication service and noticed a few endpoints seem to be missing from the specs. Could you help clarify if this was intentional or if we should update the docs? Specifically, I'm looking at: - /auth/refresh - /auth/validate Thanks! Alice""", } response = email_agent.invoke({"email_input": email_input})📧 Classification: RESPOND - This email requires a responsefor m in response["messages"]: m.pretty_print()================================ Human Message ================================= Respond to the email {'author': 'Alice Smith <alice.smith@company.com>', 'to': 'John Doe <john.doe@company.com>', 'subject': 'Quick question about API documentation', 'email_thread': "Hi John,\n\nI was reviewing the API documentation for the new authentication service and noticed a few endpoints seem to be missing from the specs. Could you help clarify if this was intentional or if we should update the docs?\n\nSpecifically, I'm looking at:\n- /auth/refresh\n- /auth/validate\n\nThanks!\nAlice"} ================================== Ai Message ================================== Tool Calls: write_email (call_1ndxzPIinVSvav1pBioakpQR) Call ID: call_1ndxzPIinVSvav1pBioakpQR Args: to: alice.smith@company.com subject: Re: Quick question about API documentation content: Hi Alice, Thank you for reaching out with your question about the API documentation. I can confirm that the endpoints /auth/refresh and /auth/validate should indeed be included in the documentation. It was an oversight, and the documentation needs to be updated. I'll ensure that the team updates the documentation to include these endpoints as soon as possible. Best regards, John Doe ================================= Tool Message ================================= Name: write_email Email sent to alice.smith@company.com with subject 'Re: Quick question about API documentation' ================================== Ai Message ================================== I have responded to Alice's email, clarifying that the endpoints she mentioned should be included in the documentation and that the team will update the documentation accordingly.
6 Email Agent Implementation (With Memory)
6.1 Semantic Memory Implementation
As mentioned above, Semantic Memory primarily stores content related to “facts,” which are also typically stored in a Long-Term Memory.
The author simulates the storage of Semantic Memory using LangGraph’s InMemoryStore:
from langgraph.store.memory import InMemoryStore
store = InMemoryStore(
index={"embed": "openai:text-embedding-3-small"}
)And creates two Tools to Manage and Search Semantic Memory:
from langmem import create_manage_memory_tool, create_search_memory_tool
manage_memory_tool = create_manage_memory_tool(
namespace=(
"email_assistant",
"{langgraph_user_id}",
"collection"
)
)
search_memory_tool = create_search_memory_tool(
namespace=(
"email_assistant",
"{langgraph_user_id}",
"collection"
)
)When calling create_manage_memory_tool and create_search_memory_tool, namespace is passed to differentiate between different Memory Collections. langgraph_user_id here will be passed when LangGraph is Invoked, thus allowing for the separation of Memory Collections for different users.
For example, User A’s Memory Collection is ("email_assistant", "user_a", "collection"), while User B’s Memory Collection is ("email_assistant", "user_b", "collection"). Different users have their own independent Memory Collections.
Information related to
manage_memory_tool:- Name:
print(manage_memory_tool.name)manage_memory - Description:
print(manage_memory_tool.description)Create, update, or delete persistent MEMORIES to persist across conversations. Include the MEMORY ID when updating or deleting a MEMORY. Omit when creating a new MEMORY - it will be created for you. Proactively call this tool when you: 1. Identify a new USER preference. 2. Receive an explicit USER request to remember something or otherwise alter your behavior. 3. Are working and want to record important context. 4. Identify that an existing MEMORY is incorrect or outdated. - Arguments:
print(manage_memory_tool.args)It can be seen that the{ 'content': {'anyOf': [{'type': 'string'}, {'type': 'null'}], 'default': None,'title': 'Content'}, 'action': {'default': 'create', 'enum': ['create', 'update', 'delete'], 'title': 'Action', 'type': 'string'}, 'id': {'anyOf': [{'format': 'uuid', 'type': 'string'}, {'type': 'null'}], 'default': None, 'title': 'Id'} }argshere mainly have three parameters:- content: The content to be stored.
- action: The action to be performed (create, update, delete).
- id: Refers to the ID of the Memory Block. This ID is automatically generated when a Memory Block is created and is used when updating or deleting a Memory Block.\
- Name:
Information related to
search_memory_tool:- Name:
print(search_memory_tool.name)search_memory - Description:
print(search_memory_tool.description)Search your long-term memories for information relevant to your current context. - Arguments:
print(search_memory_tool.args)It can be seen that{ 'query': {'title': 'Query', 'type': 'string'}, 'limit': {'default': 10, 'title': 'Limit', 'type': 'integer'}, 'offset': {'default': 0, 'title': 'Offset', 'type': 'integer'}, 'filter': {'anyOf': [{'type': 'object'}, {'type': 'null'}], 'default': None, 'title': 'Filter'} }search_memory_toolmainly takes a ‘query’ and uses Embedding to calculate Cosine Similarity to find the most similar Memory, and then returns the content of these Memories.
- Name:
6.2 Adding Semantic Memory to the Main Agent
Next, add Semantic Memory to the workflow of the Main Agent. Similar to the definition of the Main Agent above, this is changed to add manage_memory_tool and search_memory_tool to the Tools of the Main Agent:
from langgraph.prebuilt import create_react_agent
tools= [
write_email,
schedule_meeting,
check_calendar_availability,
manage_memory_tool,
search_memory_tool
]
response_agent = create_react_agent(
"anthropic:claude-3-5-sonnet-latest",
tools=tools,
prompt=create_prompt,
# Use this to ensure the store is passed to the agent
store=store
)At the same time, create_prompt must also include information related to manage_memory_tool and search_memory_tool:
< Role >
You are John Doe's executive assistant. You are a top-notch executive assistant who cares about John performing as well as possible.
</ Role >
< Tools >
You have access to the following tools to help manage John's communications and schedule:
1. write_email(to, subject, content) - Send emails to specified recipients
2. schedule_meeting(attendees, subject, duration_minutes, preferred_day) - Schedule calendar meetings
3. check_calendar_availability(day) - Check available time slots for a given day
4. manage_memory - Store any relevant information about contacts, actions, discussion, etc. in memory for future reference
5. search_memory - Search for any relevant information that may have been stored in memory
</ Tools >
< Instructions >
Use these tools when appropriate to help manage John's tasks efficiently.
</ Instructions >Invoke the Main Agent once:
config = {"configurable": {"langgraph_user_id": "lance"}}
response = response_agent.invoke(
{"messages": [{"role": "user", "content": "Jim is my friend"}]},
config=config
)
for m in response["messages"]:
m.pretty_print()================================ Human Message =================================
Jim is my friend
================================== Ai Message ==================================
[{'text': "I'll help you store this information about Jim in the memory system for future reference.", 'type': 'text'}, {'id': 'toolu_018NRmLraq49m8KVCuDHm6NT', 'input': {'content': "Jim is John Doe's friend"}, 'name': 'manage_memory', 'type': 'tool_use'}]
Tool Calls:
manage_memory (toolu_018NRmLraq49m8KVCuDHm6NT)
Call ID: toolu_018NRmLraq49m8KVCuDHm6NT
Args:
content: Jim is John Doe's friend
================================= Tool Message =================================
Name: manage_memory
created memory 4fd406ea-ba98-4ed0-92f3-838ea73e8a24
================================== Ai Message ==================================
I've recorded that Jim is your friend in my memory. This will help me better assist you with any future interactions or tasks involving Jim. Is there anything specific about Jim that you'd like me to know or help you with?It can be seen that after receiving the User’s input, the Main Agent will store this information in Semantic Memory using manage_memory_tool. Then, when the User asks a question about Jim again, the Main Agent can find the relevant information from Semantic Memory and respond:
response = response_agent.invoke(
{"messages": [{"role": "user", "content": "who is jim?"}]},
config=config
)
for m in response["messages"]:
m.pretty_print()================================ Human Message =================================
who is jim?
================================== Ai Message ==================================
[{'text': 'Let me search through my memories to see if I have any information about Jim.', 'type': 'text'}, {'id': 'toolu_01EEwQF4pLwxnZ1uoseND1jK', 'input': {'query': 'Jim'}, 'name': 'search_memory', 'type': 'tool_use'}]
Tool Calls:
search_memory (toolu_01EEwQF4pLwxnZ1uoseND1jK)
Call ID: toolu_01EEwQF4pLwxnZ1uoseND1jK
Args:
query: Jim
================================= Tool Message =================================
Name: search_memory
[{"namespace": ["email_assistant", "lance", "collection"], "key": "4fd406ea-ba98-4ed0-92f3-838ea73e8a24", "value": {"content": "Jim is John Doe's friend"}, "created_at": "2025-05-06T11:51:31.045122+00:00", "updated_at": "2025-05-06T11:51:31.045130+00:00", "score": 0.38053805045337047}]
================================== Ai Message ==================================
Based on the stored memory, Jim is John Doe's friend. However, this is fairly basic information. If you need more specific details about Jim or have a particular question about him, please let me know and I'll try to help further.6.3 Episodic Memory Implementation
Episodic Memory primarily stores content related to “experiences.” These experiences are typically used for Few-Shot Learning within the LLM’s Prompt.
In this Email Agent example, Episodic Memory is mainly used to help the LLM determine if an email needs a reply. These experiences can also be stored through a Long-Term Memory. The author uses InMemoryStore here to simulate the storage of Episodic Memory:
from langgraph.store.memory import InMemoryStore
store = InMemoryStore(
index={"embed": "openai:text-embedding-3-small"}
)Store a past experience:
import uuid
email = {
"author": "Alice Smith <alice.smith@company.com>",
"to": "John Doe <john.doe@company.com>",
"subject": "Quick question about API documentation",
"email_thread": """Hi John,
I was reviewing the API documentation for the new authentication service and noticed a few endpoints seem to be missing from the specs. Could you help clarify if this was intentional or if we should update the docs?
Specifically, I'm looking at:
- /auth/refresh
- /auth/validate
Thanks!
Alice""",
}
data = {
"email": email,
# This is to start changing the behavior of the agent
"label": "respond"
}
store.put(
("email_assistant", "lance", "examples"),
str(uuid.uuid4()),
data
)Store another past experience:
data = {
"email": {
"author": "Sarah Chen <sarah.chen@company.com>",
"to": "John Doe <john.doe@company.com>",
"subject": "Update: Backend API Changes Deployed to Staging",
"email_thread": """Hi John,
Just wanted to let you know that I've deployed the new authentication endpoints we discussed to the staging environment. Key changes include:
- Implemented JWT refresh token rotation
- Added rate limiting for login attempts
- Updated API documentation with new endpoints
All tests are passing and the changes are ready for review. You can test it out at staging-api.company.com/auth/*
No immediate action needed from your side - just keeping you in the loop since this affects the systems you're working on.
Best regards,
Sarah
""",
},
"label": "ignore"
}
store.put(
("email_assistant", "lance", "examples"),
str(uuid.uuid4()),
data
)When a new Email is received today, Episodic Memory will calculate the Cosine Similarity between the new Email and the Embeddings of past experiences using the search Method, and return the most similar experiences. The search Method here will pass a limit parameter to restrict the number of returned experiences:
# Template for formating an example to put in prompt
template = """Email Subject: {subject}
Email From: {from_email}
Email To: {to_email}
Email Content:
{content}
> Triage Result: {result}"""
# Format list of few shots
def format_few_shot_examples(examples):
strs = ["Here are some previous examples:"]
for eg in examples:
strs.append(
template.format(
subject=eg.value["email"]["subject"],
to_email=eg.value["email"]["to"],
from_email=eg.value["email"]["author"],
content=eg.value["email"]["email_thread"][:400],
result=eg.value["label"],
)
)
return "\n\n------------\n\n".join(strs)
email_data = {
"author": "Sarah Chen <sarah.chen@company.com>",
"to": "John Doe <john.doe@company.com>",
"subject": "Update: Backend API Changes Deployed to Staging",
"email_thread": """Hi John,
Wanted to let you know that I've deployed the new authentication endpoints we discussed to the staging environment. Key changes include:
- Implemented JWT refresh token rotation
- Added rate limiting for login attempts
- Updated API documentation with new endpoints
All tests are passing and the changes are ready for review. You can test it out at staging-api.company.com/auth/*
No immediate action needed from your side - just keeping you in the loop since this affects the systems you're working on.
Best regards,
Sarah
""",
}
results = store.search(
("email_assistant", "lance", "examples"),
query=str({"email": email_data}),
limit=1)
print(format_few_shot_examples(results))Here are some previous examples:
------------
Email Subject: Update: Backend API Changes Deployed to Staging
Email From: Sarah Chen <sarah.chen@company.com>
Email To: John Doe <john.doe@company.com>
Email Content:
Hi John,
Just wanted to let you know that I've deployed the new authentication endpoints we discussed to the staging environment. Key changes include:
- Implemented JWT refresh token rotation
- Added rate limiting for login attempts
- Updated API documentation with new endpoints
All tests are passing and the changes are ready for review. You can test it out at st
> Triage Result: ignore6.4 Procedural Memory Implementation
Procedural Memory primarily stores content related to “instructions.” These instructions are essentially the System Prompts that the LLM needs when performing different tasks.
These System Prompts can also be stored through a Long-Term Memory. The author uses InMemoryStore here as well to simulate the storage of Procedural Memory:
from langgraph.store.memory import InMemoryStore
store = InMemoryStore(
index={"embed": "openai:text-embedding-3-small"}
)The current Email Agent is primarily defined by two System Prompts:
- Triage System Prompt: Used to determine if the email needs a reply.
- Main Agent System Prompt: Used to define the LLM’s behavior when replying to emails.
We can store these two System Prompts in Procedural Memory and retrieve their content using the search Method when the LLM performs Triage and email replies. The following is the implementation of Triage after adding Episodic Memory and Procedural Memory:
def triage_router(state: State, config, store) -> Command[
Literal["response_agent", "__end__"]
]:
author = state['email_input']['author']
to = state['email_input']['to']
subject = state['email_input']['subject']
email_thread = state['email_input']['email_thread']
namespace = (
"email_assistant",
config['configurable']['langgraph_user_id'],
"examples"
)
examples = store.search(
namespace,
query=str({"email": state['email_input']})
)
examples=format_few_shot_examples(examples)
langgraph_user_id = config['configurable']['langgraph_user_id']
namespace = (langgraph_user_id, )
result = store.get(namespace, "triage_ignore")
if result is None:
store.put(
namespace,
"triage_ignore",
{"prompt": prompt_instructions["triage_rules"]["ignore"]}
)
ignore_prompt = prompt_instructions["triage_rules"]["ignore"]
else:
ignore_prompt = result.value['prompt']
result = store.get(namespace, "triage_notify")
if result is None:
store.put(
namespace,
"triage_notify",
{"prompt": prompt_instructions["triage_rules"]["notify"]}
)
notify_prompt = prompt_instructions["triage_rules"]["notify"]
else:
notify_prompt = result.value['prompt']
result = store.get(namespace, "triage_respond")
if result is None:
store.put(
namespace,
"triage_respond",
{"prompt": prompt_instructions["triage_rules"]["respond"]}
)
respond_prompt = prompt_instructions["triage_rules"]["respond"]
else:
respond_prompt = result.value['prompt']
system_prompt = triage_system_prompt.format(
full_name=profile["full_name"],
name=profile["name"],
user_profile_background=profile["user_profile_background"],
triage_no=ignore_prompt,
triage_notify=notify_prompt,
triage_email=respond_prompt,
examples=examples
)
user_prompt = triage_user_prompt.format(
author=author,
to=to,
subject=subject,
email_thread=email_thread
)
result = llm_router.invoke(
[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
)
if result.classification == "respond":
print("📧 Classification: RESPOND - This email requires a response")
goto = "response_agent"
update = {
"messages": [
{
"role": "user",
"content": f"Respond to the email {state['email_input']}",
}
]
}
elif result.classification == "ignore":
print("🚫 Classification: IGNORE - This email can be safely ignored")
update = None
goto = END
elif result.classification == "notify":
# If real life, this would do something else
print("🔔 Classification: NOTIFY - This email contains important information")
update = None
goto = END
else:
raise ValueError(f"Invalid classification: {result.classification}")
return Command(goto=goto, update=update)It can be seen that the content forming the Triage System Prompt, in addition to triage_system_prompt, also includes ignore_prompt, notify_prompt, and respond_prompt. This content is retrieved from Procedural Memory.
Furthermore, regarding the Main Agent’s system Prompt, the original create_prompt was as follows:
def create_prompt(state):
return [
{
"role": "system",
"content": agent_system_prompt_memory.format(
instructions=prompt_instructions["agent_instructions"],
**profile
)
}
] + state['messages']After adding Procedural Memory:
def create_prompt(state, config, store):
langgraph_user_id = config['configurable']['langgraph_user_id']
namespace = (langgraph_user_id, )
result = store.get(namespace, "agent_instructions")
if result is None:
store.put(
namespace,
"agent_instructions",
{"prompt": prompt_instructions["agent_instructions"]}
)
prompt = prompt_instructions["agent_instructions"]
else:
prompt = result.value['prompt']
return [
{
"role": "system",
"content": agent_system_prompt_memory.format(
instructions=prompt,
**profile
)
}
] + state['messages']It can be seen that the instructions parameter in agent_system_prompt_memory here is no longer reading a fixed value, but rather retrieving it from Procedural Memory.
In summary, the Triage System Prompt here retrieves the content of triage_ignore, triage_notify, and triage_respond from Procedural Memory, while the Main Agent retrieves the content of agent_instructions from Procedural Memory.
Below is the content of these 4 Instructions in Procedural Memory:
store.get(("lance",), "agent_instructions").value['prompt']
# "Use these tools when appropriate to help manage John's tasks efficiently."
store.get(("lance",), "triage_respond").value['prompt']
# 'Direct questions from team members, meeting requests, critical bug reports'
store.get(("lance",), "triage_ignore").value['prompt']
# 'Marketing newsletters, spam emails, mass company announcements'
store.get(("lance",), "triage_notify").value['prompt']
# 'Team member out sick, build system notifications, project status updates'Next, we hope that the Email Agent can adjust the content of these Instructions based on the Feedback provided by the User during interaction. The author here uses langmem’s create_multi_prompt_optimizer to create a Prompt Optimizer.
from langmem import create_multi_prompt_optimizer
optimizer = create_multi_prompt_optimizer(
"anthropic:claude-3-5-sonnet-latest",
kind="prompt_memory",
)Next, simulate the Feedback provided by the User:
conversations = [
(
response['messages'],
"Always sign your emails `John Doe`"
)
]Where response['messages'] refers to the interaction process between the User and the Email Agent:
================================ Human Message =================================
Respond to the email {'author': 'Alice Jones <alice.jones@bar.com>', 'to': 'John Doe <john.doe@company.com>', 'subject': 'Quick question about API documentation', 'email_thread': 'Hi John,\n\nUrgent issue - your service is down. Is there a reason why'}
================================== Ai Message ==================================
Tool Calls:
write_email (call_GuYrnvmS6n9ihfRQm6rlHpfX)
Call ID: call_GuYrnvmS6n9ihfRQm6rlHpfX
Args:
to: alice.jones@bar.com
subject: Re: Quick question about API documentation
content: Hi Alice,
I apologize for the inconvenience. I'm currently looking into the issue and will get back to you with an update as soon as possible.
Best regards,
John Doe
================================= Tool Message =================================
Name: write_email
Email sent to alice.jones@bar.com with subject 'Re: Quick question about API documentation'
================================== Ai Message ==================================
I've responded to Alice Jones regarding the urgent issue with the service being down, and I've assured her that the issue is being looked into.Therefore, the Feedback given by the User during this entire conversation is “Always sign your emails John Doe”.
In addition to the User’s Feedback, we also need to tell the Prompt Optimizer “when_to_update” and the “update_instruction” when updating:
prompts = [
{
"name": "main_agent",
"prompt": store.get(("lance",), "agent_instructions").value['prompt'],
"update_instructions": "keep the instructions short and to the point",
"when_to_update": "Update this prompt whenever there is feedback on how the agent should write emails or schedule events"
},
{
"name": "triage-ignore",
"prompt": store.get(("lance",), "triage_ignore").value['prompt'],
"update_instructions": "keep the instructions short and to the point",
"when_to_update": "Update this prompt whenever there is feedback on which emails should be ignored"
},
{
"name": "triage-notify",
"prompt": store.get(("lance",), "triage_notify").value['prompt'],
"update_instructions": "keep the instructions short and to the point",
"when_to_update": "Update this prompt whenever there is feedback on which emails the user should be notified of"
},
{
"name": "triage-respond",
"prompt": store.get(("lance",), "triage_respond").value['prompt'],
"update_instructions": "keep the instructions short and to the point",
"when_to_update": "Update this prompt whenever there is feedback on which emails should be responded to"
},
]Finally, pass this information to the optimizer so that the Prompt Optimizer can determine which Prompt needs to be updated based on the User’s Feedback and the “when_to_update” standard, and perform the update according to the content of “update_instruction”:
updated = optimizer.invoke(
{"trajectories": conversations, "prompts": prompts}
)The final updated Prompt is as follows:
print(updated)[
{
"name": "main_agent",
"prompt": "Use these tools when appropriate to help manage John's tasks efficiently. When sending emails, always sign them as \"John Doe\".",
"update_instructions": "keep the instructions short and to the point",
"when_to_update": "Update this prompt whenever there is feedback on how the agent should write emails or schedule events"
},
{
"name": "triage-ignore",
"prompt": "Marketing newsletters, spam emails, mass company announcements",
"update_instructions": "keep the instructions short and to the point",
"when_to_update": "Update this prompt whenever there is feedback on which emails should be ignored"
},
{
"name": "triage-notify",
"prompt": "Team member out sick, build system notifications, project status updates",
"update_instructions": "keep the instructions short and to the point",
"when_to_update": "Update this prompt whenever there is feedback on which emails the user should be notified of"
},
{
"name": "triage-respond",
"prompt": "Direct questions from team members, meeting requests, critical bug reports",
"update_instructions": "keep the instructions short and to the point",
"when_to_update": "Update this prompt whenever there is feedback on which emails should be responded to"
}
]It can be seen that the main_agent’s Prompt has been updated to “Use these tools when appropriate to help manage John’s tasks efficiently. When sending emails, always sign them as “John Doe”.” This way, when the Email Agent replies to emails, it will automatically change the signature to John Doe.
7 Conclusion
This article introduced the basic concepts of Agent Memory and demonstrated how to implement Semantic Memory, Episodic Memory, and Procedural Memory through an Email Agent example using LangMem.
This article is notes from the DeepLearning.AI course Long-Term Agentic Memory with LangGraph. The complete example code can be found at Building a Memory-Enhanced Email Agent with LangGraph.