Beyond Top-k: How Adaptive-k Dynamically Selects the Best Context for RAG Without Latency

1 Introduction
This article introduces the paper “Efficient Context Selection for Long-Context QA: No Tuning, No Iteration, Just Adaptive-k,” which was uploaded to arXiv in June 2025 and accepted by the EMNLP 2025 (Main) conference.
The authors have also open-sourced their code on GitHub. Interested readers are encouraged to try it out!
2 The Problem Adaptive-k Aims to Solve
In the Retrieval-Augmented Generation (RAG) framework, we often use the “Top-k” method to select the k document chunks most similar to a query. These chunks are then fed into the Large Language Model’s (LLM) context, enabling it to generate answers based on external knowledge and reduce hallucinations.
However, in practice, the Top-k approach is too simplistic. Sometimes, it retrieves too much irrelevant information, causing the LLM to hallucinate or perform poorly. Other times, it fails to retrieve enough information, preventing the LLM from generating a correct answer. Therefore, determining the optimal value for “k” in “Top-k” has always been a challenge in the RAG field.
To enhance retrieval flexibility, many Adaptive RAG methods have been proposed, such as Self-RAG and Adaptive-RAG. These methods allow the LLM to choose different retrieval strategies based on the query itself or to decide when to retrieve, using an iterative process to gather sufficient information. Additionally, techniques for refining retrieved documents are common, with CRAG being a classic example.
However, a common thread among these approaches, whether from the Adaptive RAG or Corrective RAG families, is that they invariably lead to longer inference latency, which in turn affects the user experience.
This brings us to the core problem that this paper (hereafter referred to as “Adaptive-k”) aims to address:
How can we more dynamically and flexibly determine the value of k for each retrieval without sacrificing inference latency?
3 Introducing the Adaptive-k Method
The essence of the Adaptive-k method can be summarized in a single sentence:
For each set of retrieval results, the Adaptive-k method sorts the similarity scores between the query and each document chunk in descending order and then identifies the largest drop, or “gap,” in these scores. Only the document chunks with higher similarity scores preceding this gap are retained.
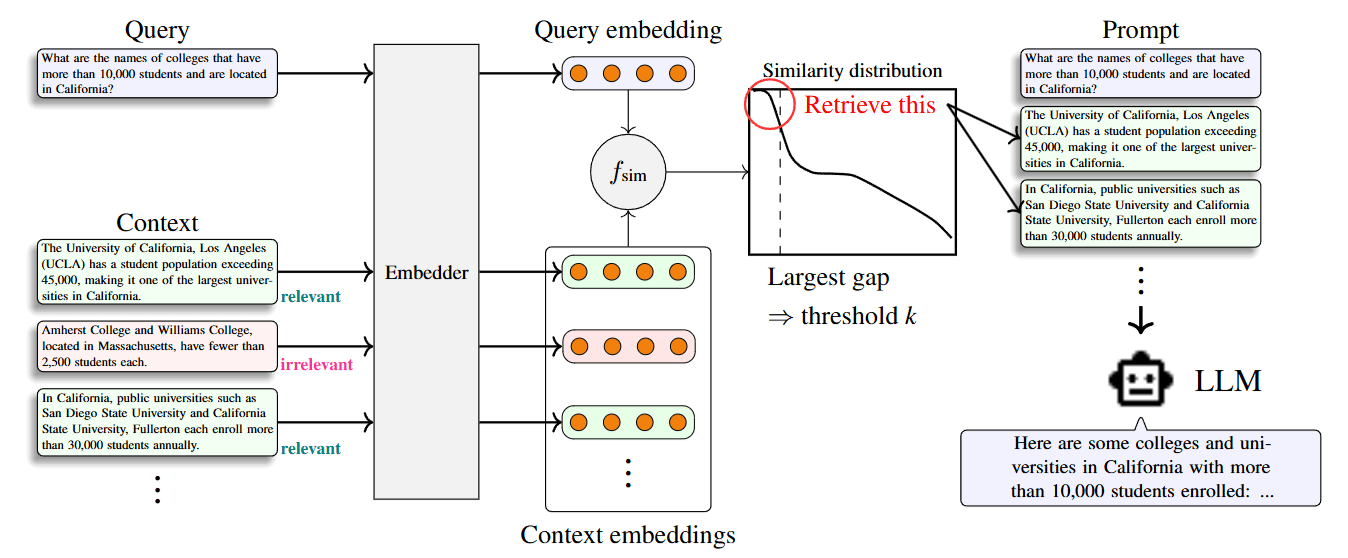
The image above illustrates the Adaptive-k method, while the one below shows its algorithm:

The authors note that in practice, relying solely on the similarity score gap to select the top k document chunks might cause some relevant chunks distributed after the gap to be excluded. To address this, they introduced a Buffer Size “B.” The total number of retrieved document chunks becomes “k+B.” (In the paper, B is set to 5).
4 Conclusion
This article reviewed the paper “Efficient Context Selection for Long-Context QA: No Tuning, No Iteration, Just Adaptive-k,” explaining how it improves upon the traditional Top-k retrieval in RAG. By analyzing the distribution of similarity scores, the authors designed the Adaptive-k retrieval mechanism to overcome the shortcomings of conventional methods.