Beyond Prompt Engineering: Inside Agentic Context Engineering, The Future of Self-Evolving AI

1 Introduction
This article shares insights from the paper “Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models,” which was uploaded to arXiv in October 2025 and has been submitted to the ICLR 2026 conference. The submission outcome is still pending.
The methodology in this paper is primarily an enhancement of “Dynamic Cheatsheet.” It is recommended that readers first review our previous article on Dynamic Cheatsheet to gain a foundational understanding of that method before proceeding.
2 The Problem Agentic Context Engineering Aims to Solve
In today’s AI systems built upon Large Language Models (LLMs), the vast majority are based on the concept of Context Engineering (or Context Adaption). The entire AI system essentially acts as a “Context Scheduler,” striving to provide the most suitable context into the LLM’s limited input context window for any given state, enabling the LLM to generate the correct output.
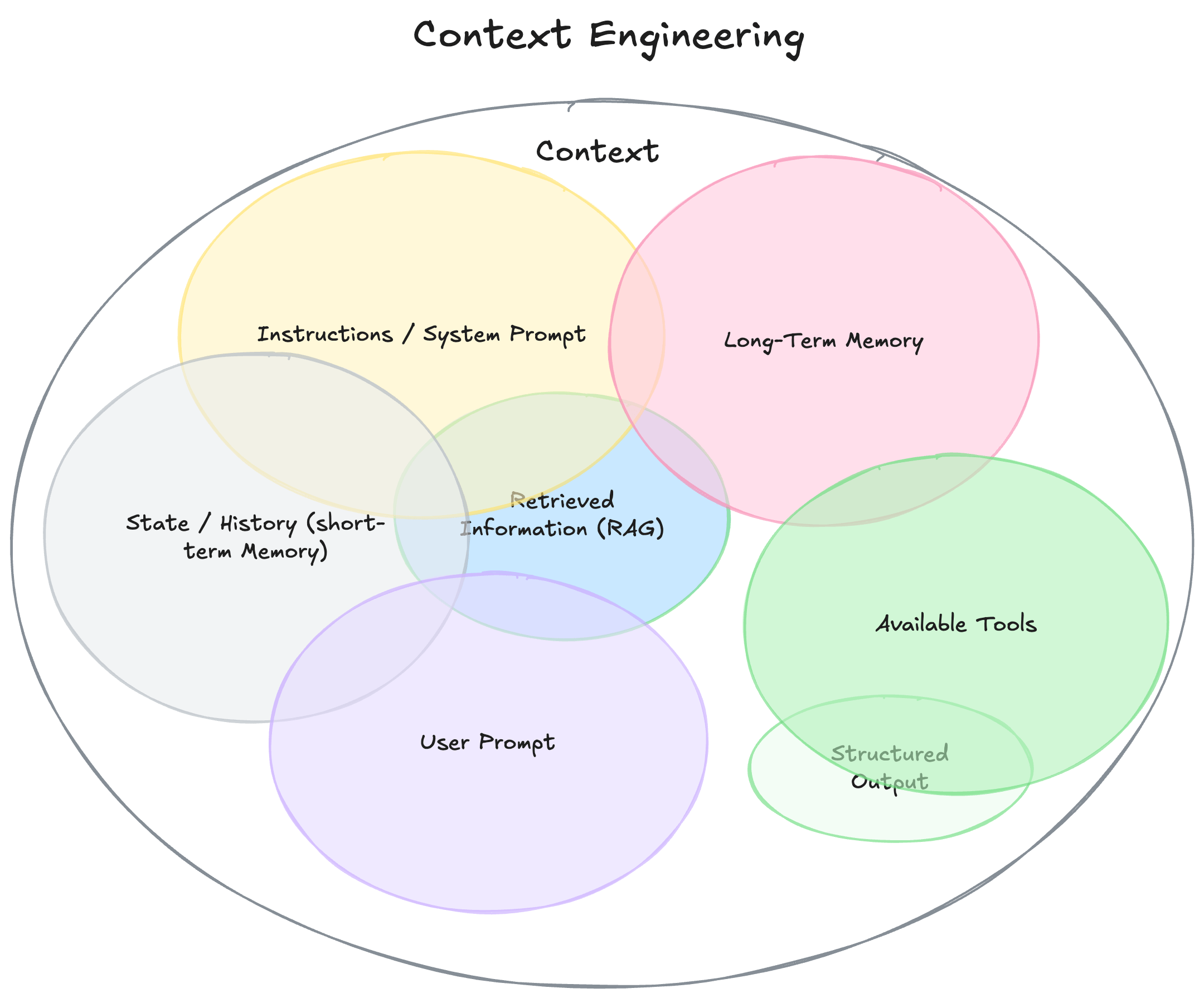
As shown in the image above, an LLM’s input context can contain various types of information, such as a System Prompt, User Prompt, Long-Term Memory, Short-Term Memory, and more. Within Context Engineering, we can optimize this context through several different methods.
For instance, during the system’s Offline phase, we can use prompt optimization techniques to refine the System Prompt and User Prompt beforehand or generate more high-quality few-shot examples. During the system’s Online phase, we can employ agentic memory methods that allow the LLM to analyze each inference trace, extracting feedback or insights to update its memory. The information in the memory then serves as part of the input context for the LLM’s next inference, leading to more accurate outputs.
However, the authors of this paper argue that existing methods for automated Context Engineering suffer from two main drawbacks:
- Brevity Bias: During the context optimization process, LLMs tend to make the context overly concise, causing much of the domain-specific information to be lost, which in turn degrades the system’s performance (e.g., GEPA).
- Context Collapse: In the process of context optimization, once the context accumulates to a certain size, LLMs tend to drastically reduce it into a much shorter summary. Because a significant amount of information is removed from the context, the system’s performance deteriorates (e.g., Dynamic Cheatsheet).
As shown in the figure below, at the 60th adaptation step, the LLM abruptly shrinks the context from 18,282 tokens to just 122 tokens, causing a sudden drop in the system’s performance:
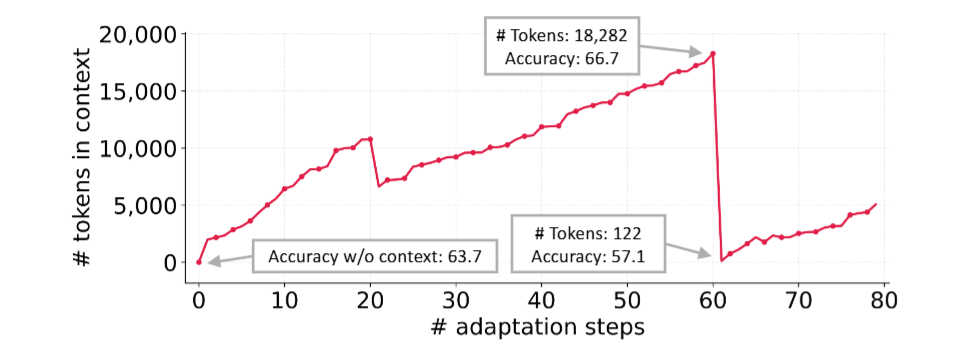
An example of Context Collapse
Based on these two shortcomings, the Agentic Context Engineering method advocates for the following principle:
The context should not be a concise summary. Instead, it should be a knowledge base that (1) contains comprehensive and diverse information and (2) is continuously updated over time.
3 Agentic Context Engineering Methodology
The method proposed in this paper is called Agentic Context Engineering (ACE), and it is applicable to both offline optimization (e.g., System Prompt Optimization) and online adaptation (e.g., Test-Time Memory Adaptation).
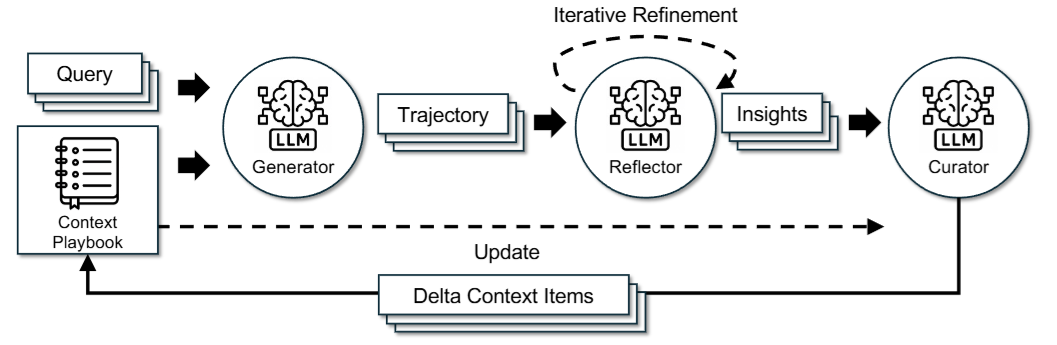
As illustrated in the diagram, the ACE method can be broken down into three main roles:
- Generator: Responsible for generating reasoning trajectories.
- Reflector: Responsible for deriving insights from both successful and failed reasoning trajectories.
- Curator: Responsible for updating these insights into the LLM’s structured context.
To address the problems of Brevity Bias and Context Collapse, ACE introduces two methods for updating the context:
- Incremental Delta Updates
- Grow-and-Refine
3.1 Incremental Delta Updates
ACE posits that the context is composed of many structured “items” rather than being just a single, long string of text. Each item consists of Metadata and Content. The metadata records the number of times an item has been used, signifying its usefulness, while the content is a piece of text describing a reusable strategy, domain knowledge, or a common mistake.
When the Generator processes new problems, it also provides feedback on these items. This feedback allows the Reflector to gain more insights for revising the context. The Reflector then organizes these insights into multiple candidate items, which the Curator integrates into the structured context.
The ACE method specifically emphasizes that because the context is structured, updates can be targeted only at the items that need modification, or new items can simply be added, rather than having the LLM rewrite the entire context from scratch.
3.2 Grow-and-Refine
To avoid redundant information in the context, ACE identifies whether an item to be updated already exists. If it does, it is merged with the existing item; if not, a new item is added to the context. Furthermore, semantic embeddings are used to compare the similarity between two items. If the similarity is too high, the duplicate item is removed.
3.3 Agentic Context Engineering vs. Dynamic Cheatsheet
To summarize, the ACE method has three key features, which we compare with the Dynamic Cheatsheet method:
- Reflector: In ACE, the roles of Reflector and Curator are distinctly separated. In Dynamic Cheatsheet, a single LLM performs both tasks.
- Incremental Delta Updates: ACE updates the context on an item-by-item basis within a structured context. In Dynamic Cheatsheet, the LLM rewrites the entire context each time.
- Grow-and-Refine: ACE actively works to prevent duplicate information in the context, a feature not explicitly mentioned in Dynamic Cheatsheet.
4 Agentic Context Engineering Experimental Results
For the experimental phase, ACE used two types of benchmarks:
- Agent Benchmark: LLM Agent: AppWorld
- Domain-Specific Benchmark (Financial Analysis): FiNER and Formula
All benchmarks followed the original train/validation/test split methodology. For the Offline Context Engineering scenario, all methods were first optimized on the training split and then evaluated on the test split using the Pass@1 metric. For the Online Context Engineering scenario, all methods were tested directly on the test split, with the context being updated after each inference. Therefore, in theory, later test samples should yield more accurate outputs.
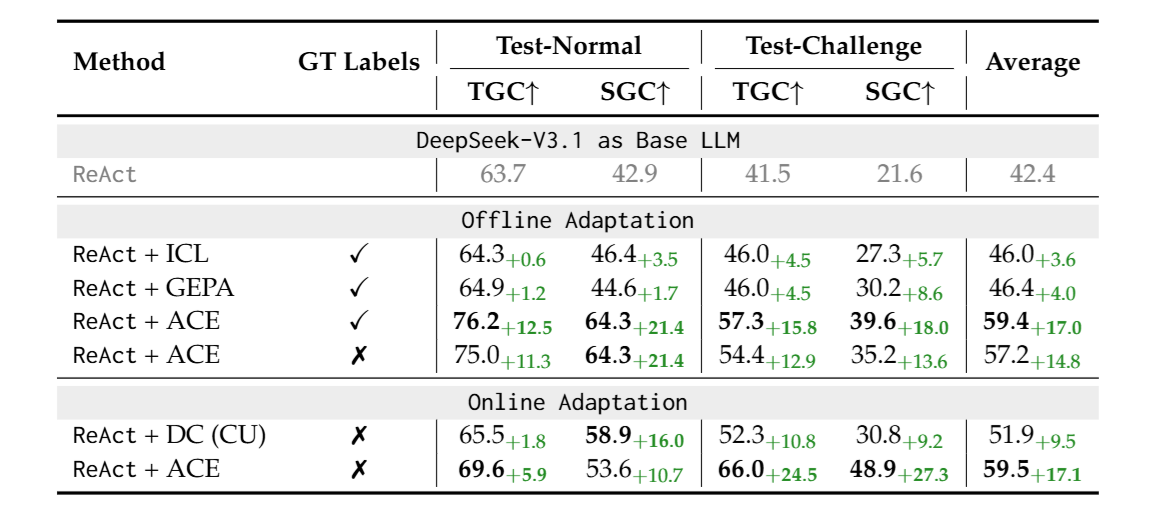
Table 1 above shows the performance of ACE and baseline methods on the AppWorld Agent Benchmark. “GT labels” indicates whether the Reflector had access to ground-truth labels when extracting insights from inference traces. From Table 1, we can see that ACE outperforms other baseline methods in both Offline and Online scenarios.
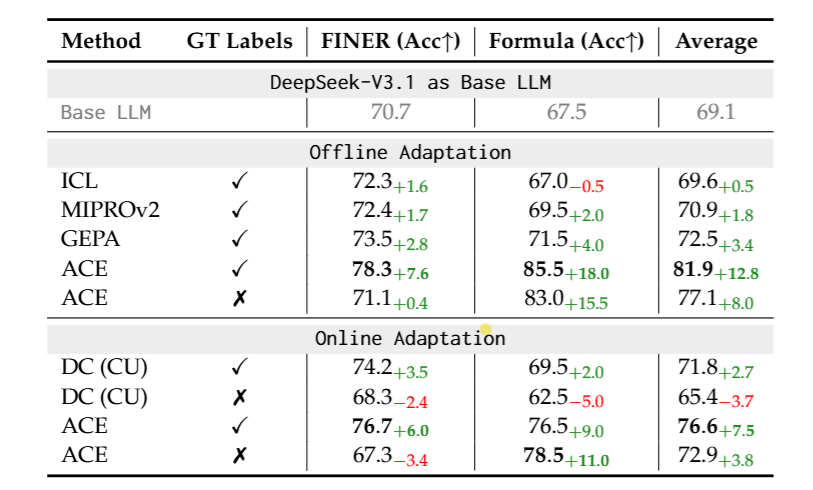
From Table 2 above, we can also see that the ACE method performs better than the baseline methods in both scenario settings.
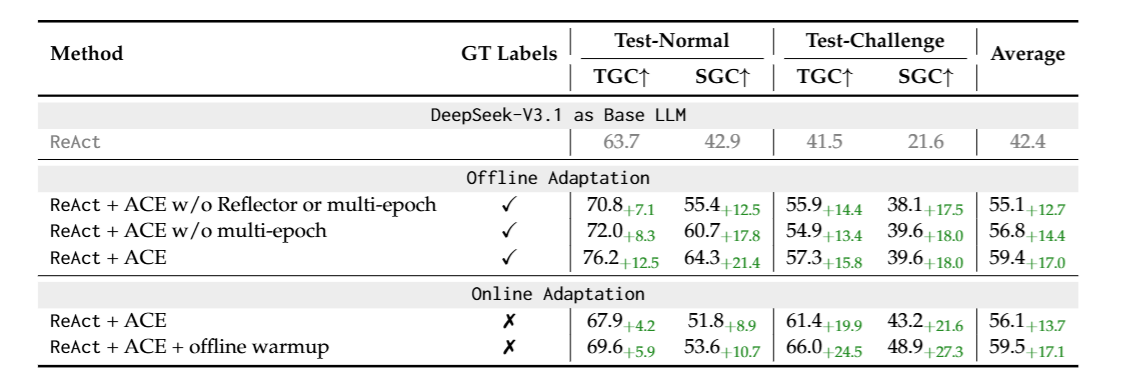
From Table 3, we observe that in the Offline scenario, removing the multi-epoch mechanism from ACE leads to a slight decrease in performance. This indicates that in the Offline setting, allowing the model to see a training sample multiple times during context optimization is beneficial.
This is analogous to training a model’s parameters. After one epoch, the model’s parameters change, moving it to a different position on the loss surface. In the next epoch, the model produces a different prediction for the same sample, which calculates a new gradient. This new gradient is then used to update the model’s parameters, moving it to an even lower position on the loss surface.
Similarly, in ACE’s multi-epoch process, making predictions on training samples based on the agentic workflow’s current context yields certain insights. These insights are used to update the workflow’s context. In the next epoch, because the workflow’s context has changed, the same training sample might produce a different result, leading to different insights and thus updating the workflow’s context from a different perspective.
Finally, Table 3 also shows that in the Online scenario, using a preliminary Offline Warmup (i.e., optimizing the context offline first and using this optimized context as the initial context for the online phase) can also improve the workflow’s performance in the Online setting.
5 Conclusion
This article has introduced “Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models,” explaining how ACE achieves self-evolution for agentic workflows through the use of a Reflector, Incremental Delta Updates, and Grow-and-Refine.
After reading the entire paper, my feeling is that while it does a great job of defining the problem and presents impressive experimental results, it seems to lack many details in its methodology description, apart from emphasizing that it builds upon Dynamic Cheatsheet. Currently, I have not been able to find a related GitHub repository, which is somewhat disappointing.