AutoMind: Adaptive Knowledgeable Agent for Automated Data Science

1 Introduction
This article introduces the paper “AutoMind: Adaptive Knowledgeable Agent for Automated Data Science,” published on arXiv in June 2025 by researchers from Zhejiang University and Ant Group.
The goal of the AutoMind paper is to propose an LLM-based agentic framework for tackling data science challenges, such as Kaggle competitions.
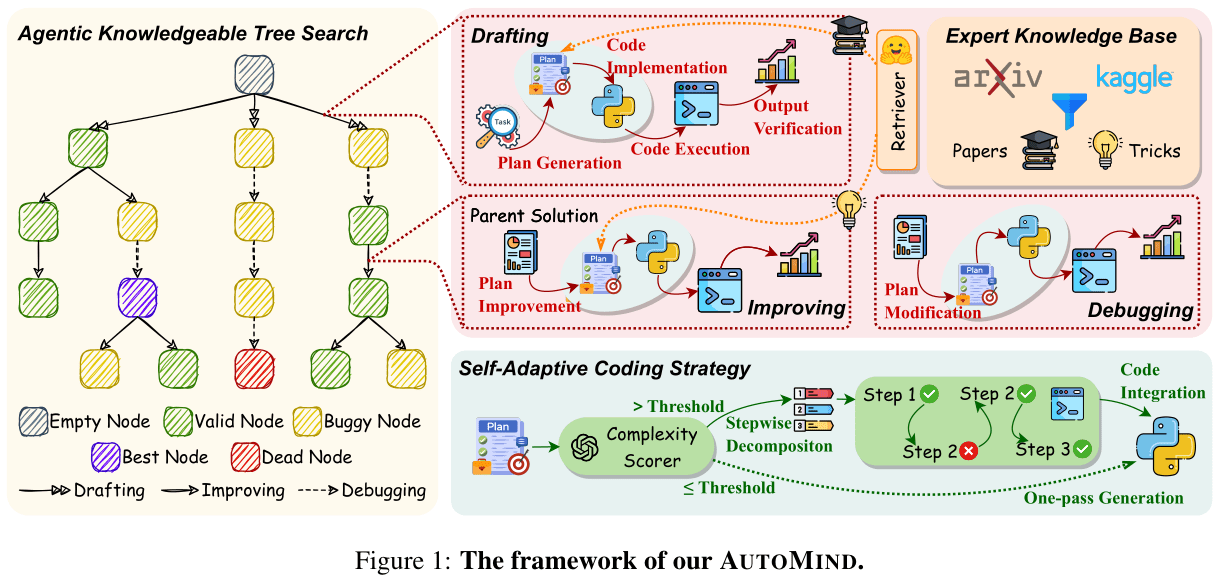
As shown in the figure above, the AutoMind framework includes three core methods:
- Expert Knowledge Base for Data Science: Building a specialized knowledge base for data science tasks.
- Agentic Knowledge Tree Search Algorithm: Using a tree structure to organize the agent’s exploration of the solution space.
- Self-Adaptive Coding Strategy: Decomposing complex problems into multiple steps and generating code for each step individually.
2 The Problem AutoMind Aims to Solve
As mentioned, AutoMind’s objective is to create an LLM-based agentic framework for data science tasks (you can think of AutoMind as a data science agent). The authors argue that previous methods (e.g., AIDE, Data Interpreter, AutoML-Agent) suffer from two key shortcomings that limit their performance:
- Insufficient Data Science Knowledge in LLMs: Although LLMs are pre-trained on vast code-based corpora, the methods (and code) used in data science are often the result of iterative experiments by human experts. LLMs lack sufficient knowledge in this specialized domain.
- Inflexible Code Generation Process: Previous methods employ rigid strategies for code generation, restricting LLMs to generating effective code only for simpler or well-established tasks.
It’s clear that AutoMind’s first two methods (Expert Knowledge Base and Agentic Knowledge Tree Search) address the first problem, while the third method (Self-Adaptive Coding Strategy) tackles the second.
3 AutoMind’s Method (1): Expert Knowledge Base
To equip the LLM with the necessary knowledge for data science tasks, AutoMind constructs a knowledge base containing two main types of information:
- Kaggle Competition Solutions: The authors selected 455 Kaggle competitions from this website and collected 3,237 posts, where each post represents a solution to a competition.
- Top Conference Papers: The authors gathered papers from top conferences like ICLR, NeurIPS, KDD, ICML, and EMNLP published in the last three years.
After building the knowledge base, the next challenge is retrieval. The most straightforward approach is dense retrieval, comparing the embeddings of the task description with the approach descriptions in the knowledge base. However, this method is often ineffective because the correlation between a task and an approach can be weak, making it difficult to retrieve helpful knowledge.
AutoMind’s approach to knowledge retrieval is somewhat brute-force. The authors use an LLM to pre-tag each Kaggle Competition Solution. The process involves defining 11 top-level categories, each with its own sub-categories. The LLM first identifies the relevant top-level categories for a solution and is then prompted to select the appropriate sub-categories. The authors also employ the Self-Consistency method to ensure the stability of the tagging process.
For Top Conference Papers, which are more diverse in content than competition solutions, assigning specific tags is challenging. Therefore, the authors use an LLM to generate a summary for each paper, including information on the Data, Task, Approach, and Contribution.
During actual retrieval, AutoMind uses an LLM to classify the input task with tags and then retrieves solutions under those tags. However, the paper does not clearly specify whether the implementation uses dense, sparse, or hybrid retrieval.
4 AutoMind’s Method (2): Agentic Knowledgeable Tree Search
4.1 Node Definition
As shown in Figure 1, AutoMind uses a tree to organize the agent’s exploration within the solution space. Each node in the tree is called a Solution Node and contains the following information:
- Plan: A text description outlining the plan to solve the current data science task in sequential stages, including Data Preprocessing, Feature Engineering, Model Training, and Model Validation.
- Code: A Python script to implement the plan.
- Metric: The validation score extracted from the code execution result.
- Output: The terminal output from the code execution.
- Summary: A summary of the node provided by an LLM-based verifier, based on the Plan, Code, Metric, and Output. It also determines if the node is a “Valid Node” or a “Buggy Node.”
4.2 Search Policy
The search process on the tree is governed by a Search Policy. The policy takes the current state of the entire tree as input and outputs a tuple containing a selected node and the action to perform on it.
In AutoMind, the Search Policy is determined by a series of rule-based probabilistic judgments, with no LLM involvement. The process is outlined in the algorithm below:

4.3 Action Types
There are three types of actions that can be performed on each node. Each action prompts an LLM to generate a new plan based on different inputs:
- Drafting: Takes the Task Description and relevant Papers from the knowledge base as input to output an initial plan.
- Improving: Takes a randomly selected Valid Node (Plan, Code, Output) from the tree and relevant Solutions from the knowledge base as input to output an improved plan.
- Debugging: Takes a randomly selected Buggy Node (Plan, Code, Output) from the tree as input to output a debugged plan.
Regardless of which action is executed, once a new plan is generated, it undergoes code implementation and execution. The resulting (Plan, Code, Metric, Output, Summary) is then packaged into a new node and added to the tree.
5 AutoMind’s Method (3): Self-Adaptive Coding Strategy
To improve the correctness of code implementation, AutoMind uses an LLM-as-a-Judge to generate a complexity score for the plan. If the score is below a predefined threshold, the LLM generates the complete code in one go. Conversely, if the score is above the threshold, it indicates a complex plan. The LLM then first breaks the plan down into multiple sub-steps and proceeds to implement the code for each sub-step sequentially.
When implementing code for each sub-step, the code is first checked using an Abstract Syntax Tree (AST) before execution. The execution result serves as feedback, which the LLM uses to proceed with the code implementation for the next sub-step.
6 AutoMind’s Experimental Results
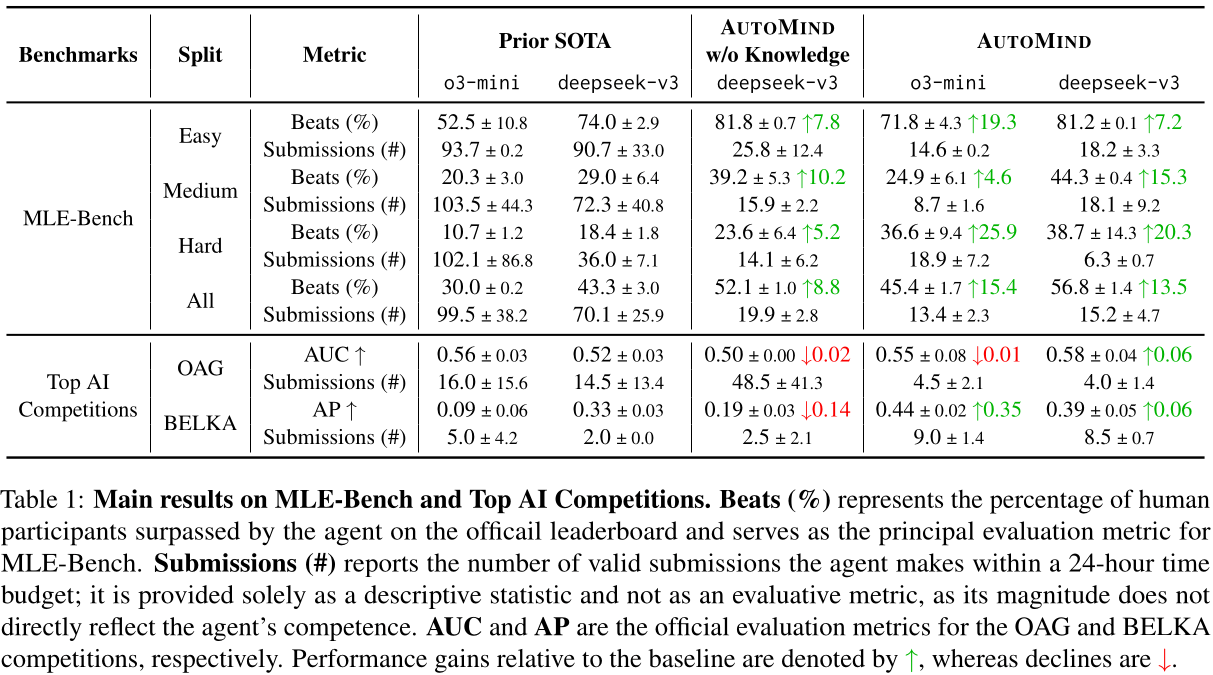
Table 1 shows that AutoMind achieves performance close to or better than baseline methods on both MLE-Bench and Top AI Competitions, and does so with significantly fewer submissions.
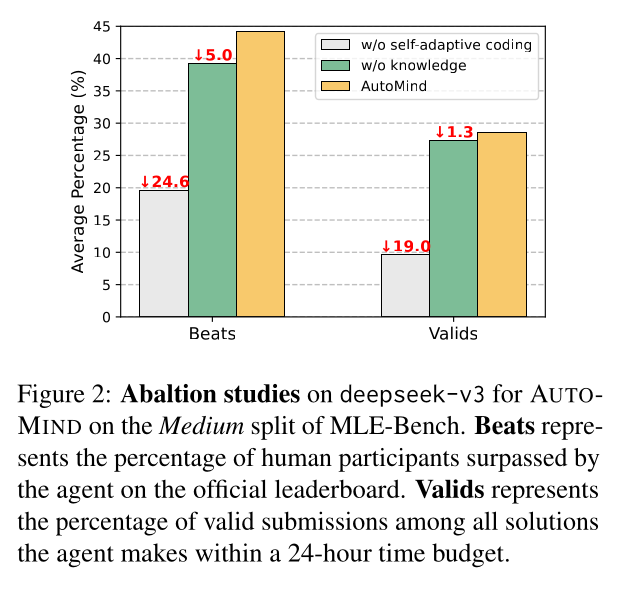
Interestingly, I initially assumed that AutoMind’s strong performance was largely due to its custom-built Data Science Expert Knowledge Base. However, the ablation study in the figure above reveals that removing the Expert Knowledge Base leads to only a slight decrease in performance. In contrast, removing the Self-Adaptive Coding Strategy (by generating code for all plans in a single pass) has a major negative impact on AutoMind’s performance.
7 Conclusion
In this article, we explored the paper “AutoMind: Adaptive Knowledgeable Agent for Automated Data Science,” learning how an agentic framework can be built using Large Reasoning Models (like o3-mini and deepseek-v3 used in the paper) to handle data science tasks.
AutoMind’s core methods—(1) the Expert Knowledge Base, (2) the Agentic Knowledgeable Tree Search, and (3) the Self-Adaptive Coding Strategy—enable it to outperform previous state-of-the-art methods on the MLE-Bench and Top AI Competitions benchmarks.