Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM

1 Introduction
Today, I’m excited to share a paper with a concept that is both simple and fascinating—Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM! This paper was published by Meta FAIR in March 2024. It’s also the second Mixture of Experts (MoE) paper we’re exploring, following our discussion on Sparse Upcycling.
Branch-Train-MiX, or BTX for short, caught my attention not only because it uses the popular MoE technique, but also because it demonstrates how to integrate multiple domain experts into a single model, which I find quite interesting! The concepts in this paper are straightforward and easy to understand, making it a light read. Let’s take a quick 10-minute break to learn something new!
2 What Problem Does Branch-Train-MiX Aim to Solve?
To quickly grasp a paper’s core idea, we must first understand the “problem” it aims to solve. Simply put, Branch-Train-MiX addresses the challenges associated with the “distributed training” of Large Language Models (LLMs). To accelerate model training, companies with access to a large number of GPUs (e.g., Meta) use distributed training to increase throughput and reduce the time required for training.
Distributed training primarily falls into two categories: Data Parallelism and Model Parallelism. The diagram below illustrates the Data Parallelism approach. You can see that the same model is replicated across multiple nodes (devices equipped with GPUs), and the entire training dataset is split into multiple subsets, each sent to a different node.
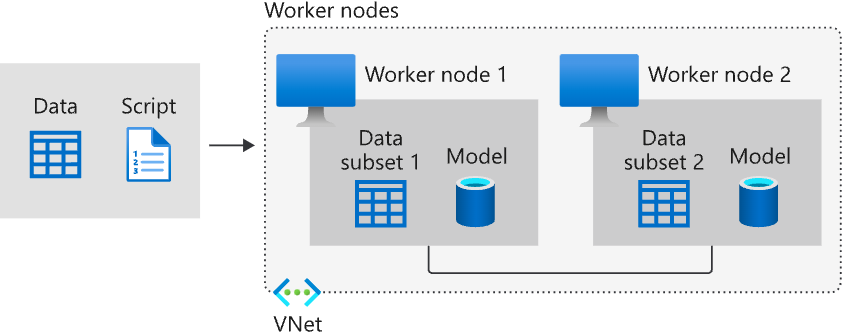
Typically in distributed training, each model copy computes different gradients from its unique batch of training data. These gradients must then be aggregated in some way (e.g., by averaging). This aggregated gradient is used to update the model’s parameters, and the updated parameters are then distributed back to all nodes.
Have you spotted the issue? A major problem with distributed training is that while the models are trained on different nodes, these nodes require frequent “synchronization” and “communication.” This constant communication (e.g., transmitting newly updated parameters) creates a performance bottleneck: adding more GPUs no longer significantly speeds up training. Furthermore, if a single GPU fails, the entire training process can be disrupted.
To avoid frequent synchronization between nodes, we could have each node train its own model separately and then find a way to merge these different models together at the end.
A previous paper proposed the Branch-Train-Merge (BTM) method. During the training phase, multiple LLMs (replicated from the same seed LLM) are trained on different GPUs. Each LLM only sees its own subset of the training data, allowing it to become a domain expert.
During the inference phase, a router decides which experts should handle the current input, and the output distributions of these experts are combined for next-token prediction. However, while Branch-Train-Merge allows for “asynchronous” training across multiple GPUs, it results in “multiple models.” This makes it impossible to perform subsequent training stages (like SFT or RLHF).
Therefore, the Branch-Train-MiX method proposed by Meta aims to enable models to be trained “asynchronously” and “independently” on multiple GPUs, while ultimately producing a single model instead of multiple ones!
3 Introducing the Branch-Train-MiX Method: Branch ⭢ Train ⭢ MiX
As its name suggests, the Branch-Train-MiX (BTX) method consists of three main stages:
- Branch: A single model (the seed LLM) is replicated and distributed to different nodes. Each node also receives a training dataset for a specific domain.
- Train: Each node independently trains its own LLM.
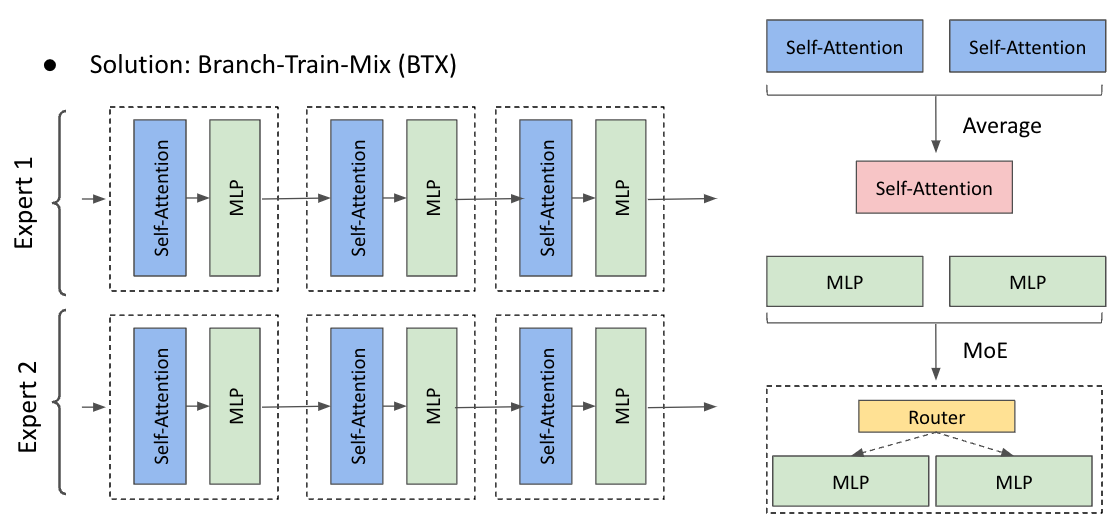
- MiX: All the resulting LLMs are integrated into a single model using weight averaging and the Mixture-of-Experts concept.
Specifically, the first two steps of BTX (Branch-Train) involve creating N copies of the seed LLM and training them on N different domain datasets. Since these N LLMs are trained independently, the process can be fully parallelized: there are no synchronization issues between GPUs, and the failure of one GPU does not affect the others. Each LLM specializes in its own domain, becoming a domain expert.
The third step of BTX (MiX) combines the Feed-Forward Networks (FFNs) of all domain experts into a single MoE layer (as shown in the bottom right of the image below). For example, the k-th FFN layer from all domain experts is merged into a single k-th MoE layer. Other layers (e.g., Self-Attention, Embedding) are integrated by averaging the weights of the multiple domain experts (as shown in the top right).
The authors’ rationale is that FFNs are more domain-specialized layers. To preserve the unique domain knowledge of each expert, they are kept intact within an MoE layer. In contrast, other layers are considered less domain-specific, so their parameters can be safely averaged.
The MoE layer’s router uses Token Choice Routing. This type of routing must address the expert load balancing problem to prevent tokens from favoring only a few specific experts. The most common solution for this is to add an auxiliary loss to each router:
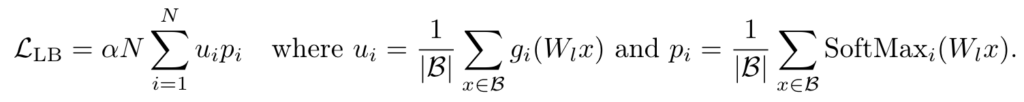
As you can see from the formula, the auxiliary loss is the sum of the product of u and p for each expert in the MoE layer. Here, u is the “average number of times” an expert is selected by the router within a batch, and p is the “average probability” of that expert being selected. This load balancing loss is added to the language modeling loss to form the total loss, which is then used to update the entire model.
4 Experimental Results
In their experiments, the authors used Llama-2 7B as the seed model and created 3 copies, which were trained on Math, Code, and Wikipedia datasets, respectively. For the final Mix step, they combined the 3 domain experts with the original seed model, resulting in 4 experts in each MoE layer of the final model. This final model was then trained on a combined dataset of all domains.
Interestingly, the Sparse Upcycling method from Google, which we’ve discussed before, can be seen as a special case of BTX—it’s essentially the X (Mix) step without the BT (Branch-Train) stages.
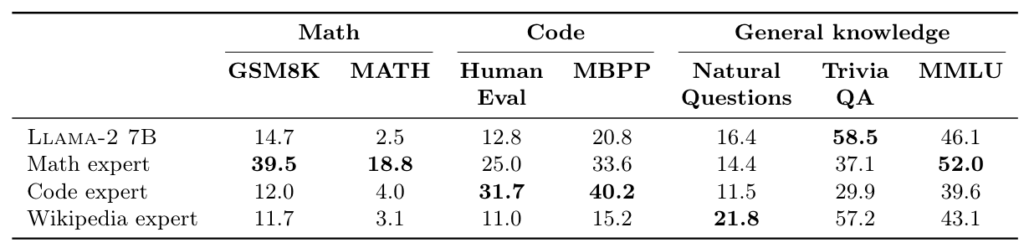
From the table above (Table 1), we can see that each expert in BTX performs well in its respective domain. However, an interesting phenomenon emerges: training a general-knowledge LLM (Llama-2 7B) on domain-specific knowledge leads to “catastrophic forgetting.” In other words, the Math and Code experts performed worse on general knowledge tasks than the original Llama model.
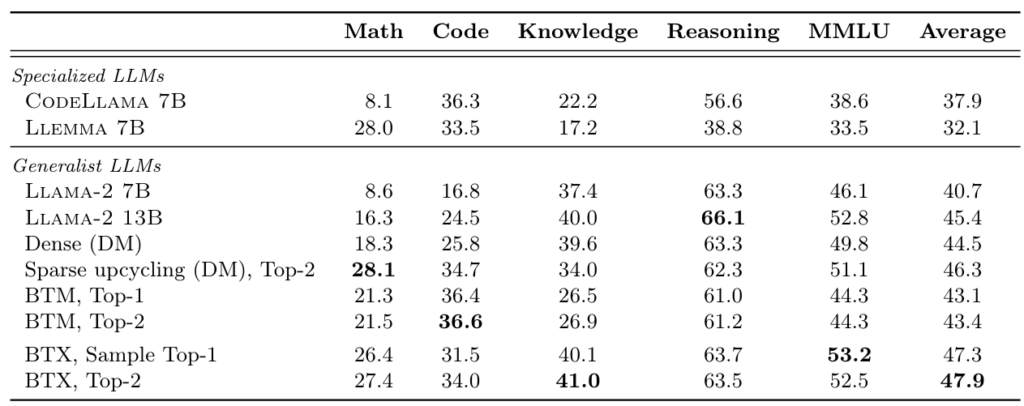
The final experimental data (Table 2) shows that the BTX model (bottom two rows), compared to the original seed model (Llama-2 7B), not only performs better on domain-specific knowledge (Math and Code) but also retains its original capabilities (Knowledge, Reasoning, MMLU)!
This suggests that besides avoiding the performance bottlenecks of distributed training, Branch-Train-MiX might have another use case: when we have a pre-trained LLM with general knowledge across various domains but not deep expertise in any single one. We can use the Branch-Train-MiX training method to enhance its performance in N specific domains simultaneously.
5 Conclusion
In this article, we’ve explored the Branch-Train-MiX paper by Meta FAIR. The BTX method avoids the performance bottlenecks caused by frequent synchronization in distributed training by allowing a base LLM to be replicated and trained independently on different GPUs, each with its own domain-specific dataset.
Furthermore, Branch-Train-MiX uses a sparse MoE technique to merge multiple domain experts into a single model. This consolidated model can then undergo further training (e.g., SFT or RLHF) for additional performance improvements. The final experiments also demonstrate that the model trained with Branch-Train-MiX can effectively mitigate the problem of catastrophic forgetting.