ChatEval: Towards Better LLM-Based Evaluators Through Multi-Agent Debate

1 Introduction
In this article, I’d like to share a paper related to “LLM Agents” — ChatEval: Towards Better LLM-Based Evaluators Through Multi-Agent Debate. This is an ICLR 2024 Poster paper, and it’s a fairly simple and easy-to-understand Multi-Agent framework (so simple, in fact, that my professor wondered how it even got accepted by ICLR…). If you’re looking to start exploring research on Multi-Agent systems, I believe this paper is an excellent starting point.
2 What is an LLM Agent?
Before diving into the paper, I want to share my understanding of the term “Agent.” This comes from my reading of the survey paper The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey. An “Agent” should possess at least the following three capabilities:
- Perception: The ability to “understand” input data.
- Think: The ability to “reason” and “plan” based on the current task.
- Act: The ability to take “action.”
In my mind, let’s imagine we have a Large Language Model:
If I give it a prompt: “Please try to help me solve this calculus problem,” and it replies, “I’m sorry, I don’t know how to solve this math problem,” or “2” (giving me a wrong answer directly).
Even though it didn’t tell me how to do it or got the answer wrong, it understood that it was a “math problem.” In this case, I would consider it to have the ability to “understand” the input data (the text I provided).
If I then use some prompting techniques (like Chain of Thought) to encourage it to articulate its intermediate reasoning (calculation) process and thereby arrive at the correct final answer, I would consider it to have the ability to “reason.”
If, from the beginning, I provide it with tools like a Web Browser or a Code Interpreter and tell it how to use them, and during its reasoning process, it realizes it doesn’t fully grasp the concept of calculus and uses the Web Browser to look it up, or it converts the intermediate calculations into code and executes it via the Code Interpreter to get the result, then I believe it has already acquired the ability to take “action.” At this stage, we can call it an “Agent.”
3 The Architecture of LLM Agents
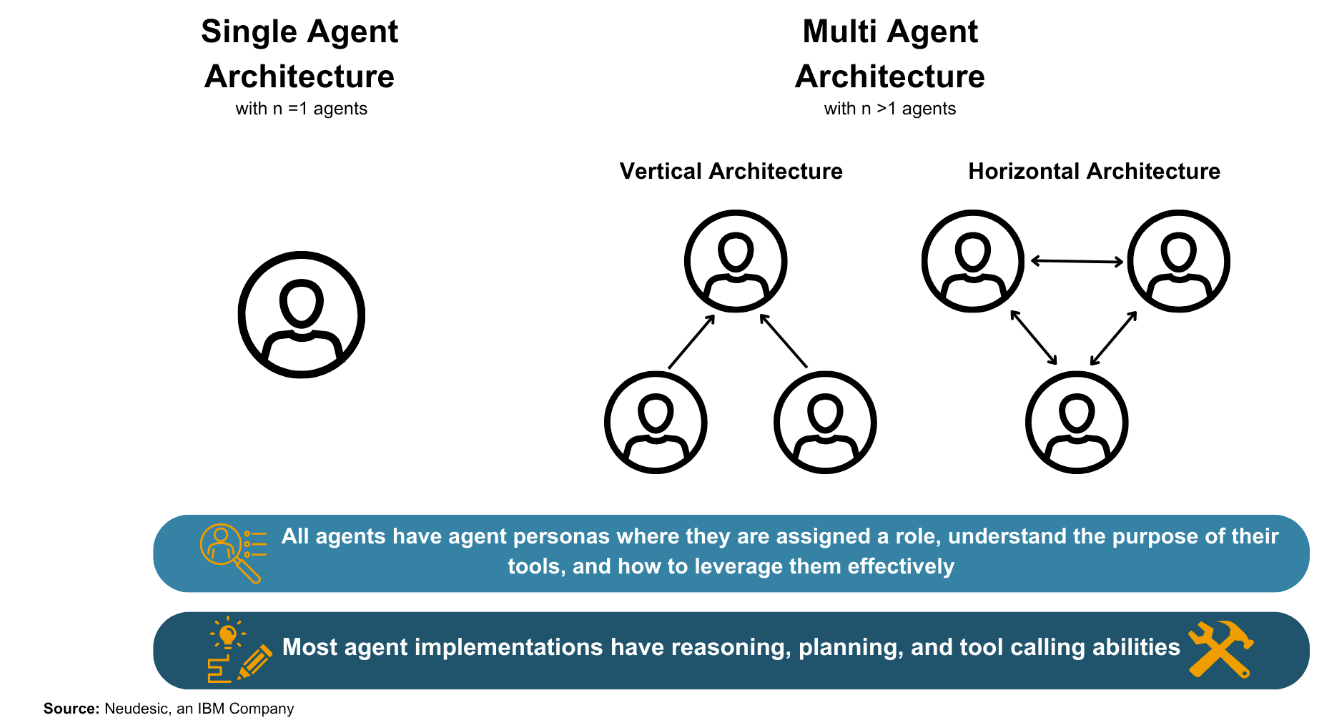
As shown in the figure above, LLM Agent methods can be simply classified into “Single-Agent Architecture” or “Multi-Agent Architecture.” The names themselves are quite self-explanatory, so there’s no need for a detailed explanation. Multi-Agent Architectures can further involve vertical or horizontal collaborative relationships.
In Single-Agent Architecture, classic papers include ReAct (ICLR 2023) and Reflexion (NeurIPS 2023). In Multi-Agent Architecture, classic papers include ChatEval (ICLR 2024) and MetaGPT (ICLR 2024).
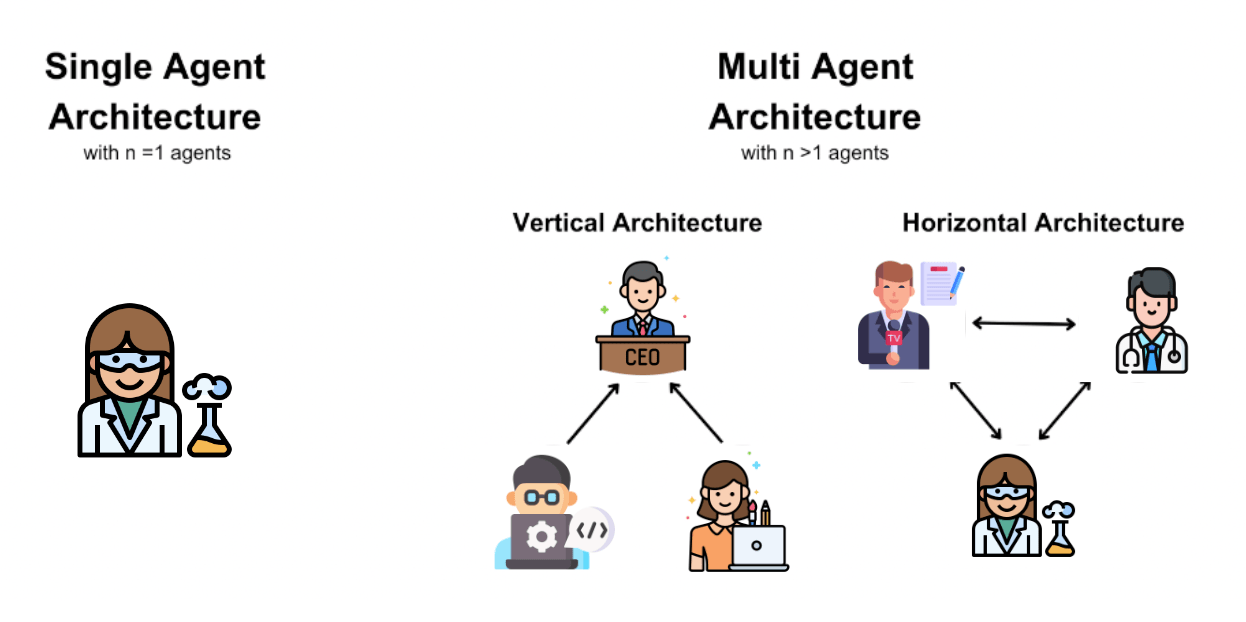
In agent-related approaches, “Persona” is a particularly crucial concept: Agent + Persona = Role. As shown above, if we give an Agent a persona through a System Prompt, its subsequent output “content,” “style,” or “reasoning method” will change accordingly. This is especially important in Multi-Agent frameworks, where defining different personas for each agent is critical. It significantly impacts whether the group of agents can successfully complete the given task.
4 Findings on LLM Agents
The paper The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey also lists some characteristics related to agents in its conclusion:
- Single-Agent Frameworks are suitable for simpler tasks with “clear” answers, like question-answering with standard solutions.
- Multi-Agent Frameworks are suitable for tasks that require feedback (discussion). These tasks are often more complex and may not have a standard answer, such as Evaluation Tasks (LLM as a Judge) or Software Development (MetaGPT).
- In a Multi-Agent Framework, when multiple agents communicate using natural language, their communication can sometimes become increasingly noisy (e.g., they might start engaging in small talk), causing their final communication to deviate from the originally set goal.
- In a Multi-Agent Framework, a “vertical” collaboration model (where one agent acts as a leader and assigns tasks to other agents) can lead to better performance.
- In both Single and Multi-Agent Frameworks, defining the personas of the agents has a significant impact on the results.
5 The Problem ChatEval Aims to Solve
Now that we have a basic understanding of LLM Agents, let’s look at what problem the ChatEval paper aims to solve.
In the past, when we developed a new language model and wanted to compare its summarization ability with other language models, we might have to give many articles to both models for summarization and then hire some humans to score the outputs of the two models.
You can see that this evaluation method is inefficient (humans are slow…) and costly (you have to pay them by the hour!). However, if we use rule-based metrics (like ROUGE, BLEU, etc.), these metrics, designed based on N-grams, sometimes produce scores that don’t align well with human preferences.
Therefore, is there a more efficient, cost-effective, and human-aligned way to evaluate these language models?
6 Introduction to ChatEval
Yes, there is! This is one of the problems ChatEval aims to solve.
Since the rise of Large Language Models (LLMs), much research has focused on using LLMs to evaluate other LLMs. This line of work is often referred to as LLM-as-a-Judge.
Besides being faster and cheaper, using an LLM to evaluate another LLM has another advantage: an LLM can be trained through SFT or RLHF / DPO to make its output more aligned with Human Preference.
In essence, ChatEval is a method that uses LLMs to evaluate other LLMs. What makes it interesting, however, is that it doesn’t use just one LLM (Agent), but rather a method where multiple LLMs (Agents) debate with each other to reach a consensus (essentially, the concept of a jury). The ChatEval paper and its methodology are quite simple, primarily involving understanding two parts: “how each agent’s role is defined” and “how the agents communicate with each other.”
7 Introduction to ChatEval ⭢ Agent & Role

As shown in the figure above, ChatEval defines 5 types of personas: General Public, Critic, News Author, Psychologist, and Scientist.
The prompt given to an agent each time would look like the figure below:
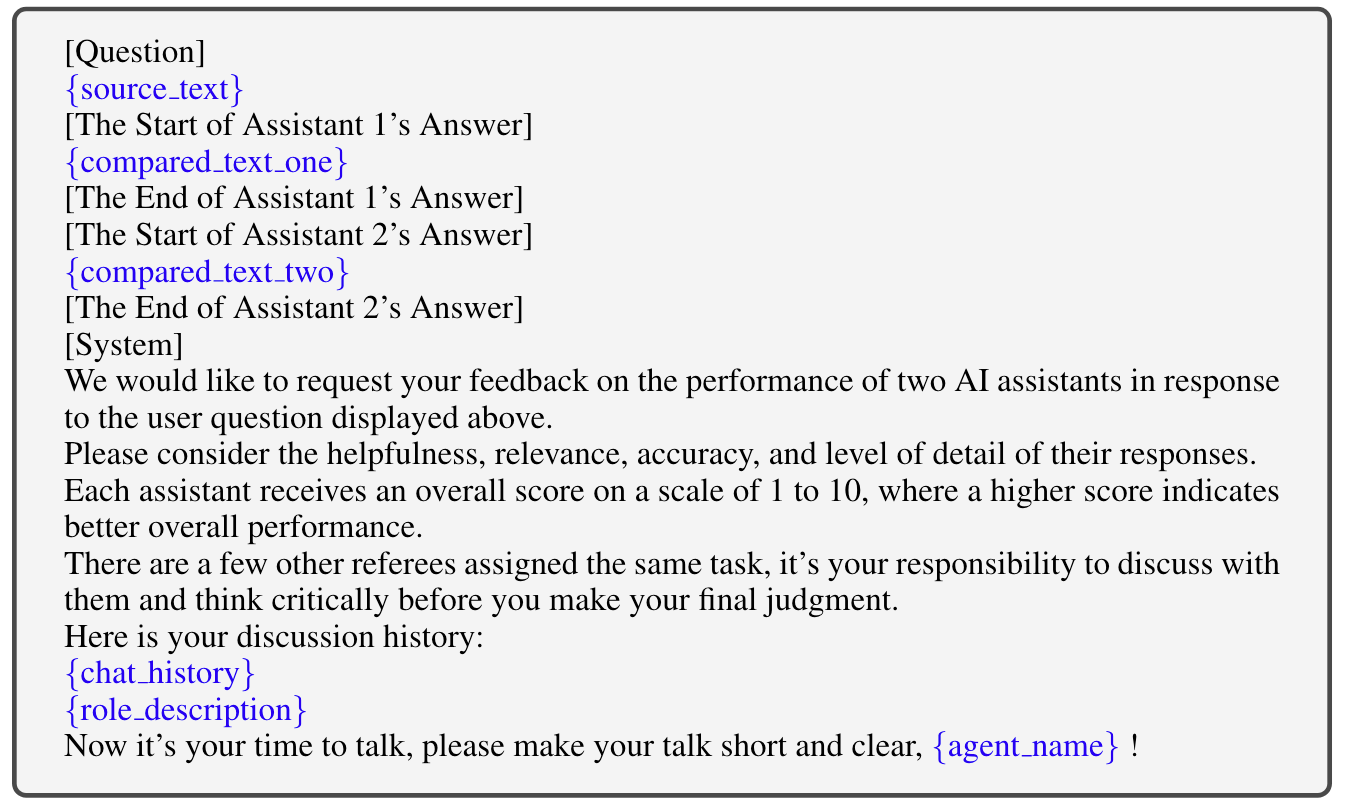
We can clearly see that this prompt is mainly divided into two parts: the Question Prompt and the System Prompt. The Question Prompt provides a question and the answers from two language models, while the System Prompt tells the current agent how to score the answers of these two language models.
8 Introduction to ChatEval ⭢ Communication between Agents
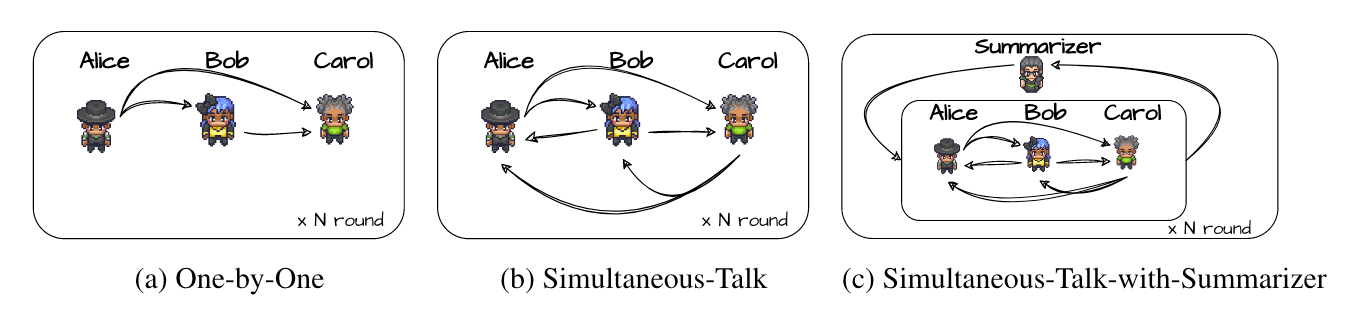
As shown in the figure above, ChatEval defines 3 types of communication methods among agents. Suppose there are 3 agents: Alice, Bob, and Carol. Given a question and the responses from 2 language models, these 3 agents will use the following 3 communication/debate methods to reach a final conclusion (which language model’s response is better):
- One-by-One: All agents speak “sequentially.” As shown above, Alice first expresses her opinion, followed by Bob, and finally Carol. When speaking, later speakers can see the content shared by previous speakers. In other words, when Bob speaks, in addition to the original question and the 2 language model responses, he can also see Alice’s thoughts. When Carol speaks, she can see the thoughts of both Alice and Bob. In the next round of speaking, the order remains the same, but this time everyone can see each person’s statements from the previous round of discussion.
- Simultaneous-Talk: All agents speak “simultaneously.” As shown above, Alice, Bob, and Carol speak at the same time. At the moment of speaking, they only see the question and the two language model responses; they do not see the other’s statements. After everyone has spoken in this round, each person’s statement is recorded in a notebook, and this notebook is then shown to everyone. In the next round, everyone speaks simultaneously again, but they have all seen the dialogue from the previous round.
- Simultaneous-Talk-with-Summarizer: This is basically the same as Simultaneous-Talk, except that at the end of each round, a Summarizer (which is actually just another LLM) first summarizes the contents of the notebook (the statements of the three people in that round) before the notebook is shown to the three people. In other words, the content these three people see is the summarized result, not the original statements of the three individuals.
The above is the concept of these 3 communication/debate methods. The paper provides algorithms for each, so if you prefer a less personified explanation, you can refer to the original paper! Before we move on to the final experiment introduction, why not take a moment to guess which communication method would perform best?
9 ChatEval’s Experimental Results
The ChatEval paper uses 2 tasks to measure the effectiveness of the ChatEval method:
- Open-ended Question Answering
- Dialogue Response Generation
As shown below, in the Open-ended Question Answering task, there are many questions. Each question has responses from 2 LLMs, and it’s pre-labeled which response is better. We hope the ChatEval method can also determine which response is better:
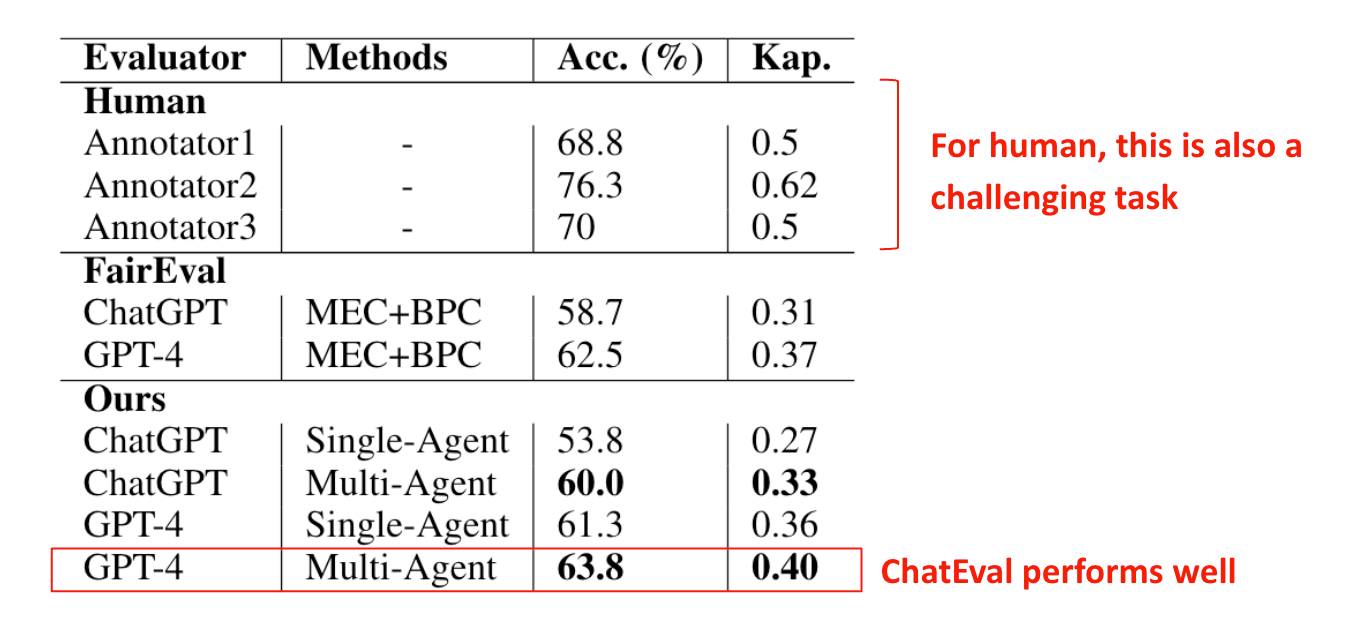
The figure below shows ChatEval’s experimental results on this task. It can be seen that for both ChatGPT and GPT-4, three methods were used (MEC+BPC, Single-Agent, and Multi-Agent), where Multi-Agent refers to the ChatEval method. Naturally, the experimental results show that their proposed method (ChatEval) performs very well.
In the Dialogue Response Generation task, there are many dialogues, and each dialogue has many responses. Each response can be ranked from different aspects (e.g., Naturalness, Coherence…). We hope that through the ChatEval method, the agents’ rankings of these responses on each aspect will be consistent with human (Groundtruth) rankings.
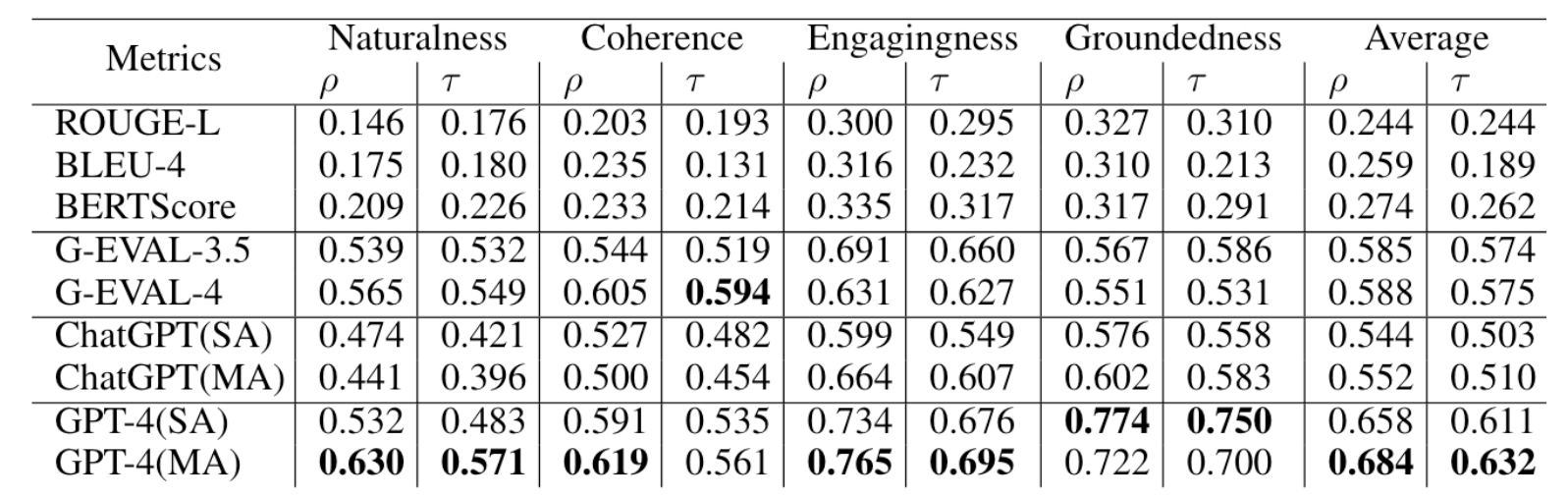
The figure below shows ChatEval’s experimental results on this task. It can be observed that in most cases, Multi-Agent (ChatEval) can achieve better performance than Single-Agent.
Furthermore, the authors show in the Ablation Study that among the 3 communication/debate methods, One-by-One has the best performance:

In the Multi-Agent framework, Diverse Roles is a technique particularly emphasized by the authors. This means that by setting personas, each LLM is assigned a different role, making it more likely for them to propose different viewpoints during the debate, thus improving the final performance:

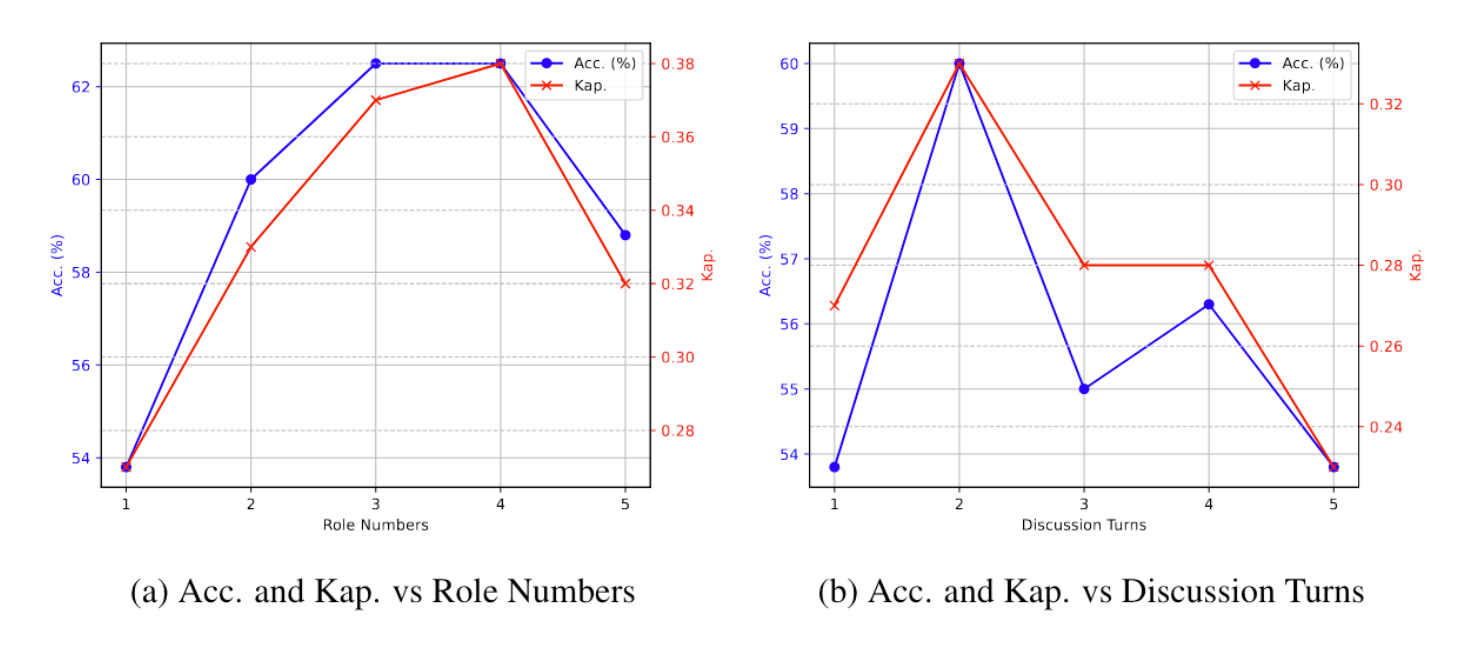
Finally, the authors also show how many agents and how many rounds of discussion yield the best results. To my surprise, I thought it would be many agents discussing for many rounds, but it turns out that just 3 agents discussing for 2 rounds is enough to reach a consensus:
10 Conclusion
After reading this article, I’m sure you also feel that the paper ChatEval: Towards Better LLM-Based Evaluators Through Multi-Agent Debate is very simple in its motivation, methodology, and experiments (yet it still made it into ICLR 2024…). Therefore, it serves as a great entry-level paper for the Multi-Agent field. Additionally, the authors have open-sourced the ChatEval GitHub, so if there’s an opportunity to design a Multi-Agent Debate method in the future, I think using ChatEval as a baseline would be a great idea