Selective Clarification: Overcoming LLM Hallucinations via the CLAM Framework

1 Introduction
This paper introduces a framework called CLAM (CLarify-if-AMbiguous), designed to address a major pain point of Large Language Models (LLMs): their tendency to “blindly guess” or hallucinate when faced with ambiguous or under-specified questions. If this problem sounds familiar, our article on INTENT-SIM tackles the exact same “when should an LLM ask a clarifying question” challenge from a different angle — simulating possible user intents rather than a three-stage funnel.
CLAM equips models with a human-like meta-cognition capability. Instead of answering directly, it passes the input through a “three-stage funnel”:
- Detection: Determine if the question is ambiguous.
- Questioning: if ambiguous, generate a specific clarifying question for the user.
- Answering: Provide a final, precise answer based on the user’s supplemental information.
Furthermore, to overcome the challenges of expensive and hard-to-replicate multi-turn conversation evaluations, the authors propose an automated evaluation protocol based on an Oracle.
2 Problem Definition
2.1 Pain Point Analysis: Silent Hallucinations and Annoying Clarifications
Before diving into CLAM, we must understand why this problem is so tricky. Modern LLMs like GPT-3 are typically trained to “predict the next most likely token.” This mechanism causes models to exhibit a dangerous behavior when faced with ambiguous or under-specified user input: overconfident guessing.
Consider this scenario: A user asks, “When did he land on the moon?”
- User’s Intent: They are thinking of Alan Bean (Apollo 12).
- Model’s Behavior: Since Neil Armstrong appears most frequently in the training data, the model directly answers “July 20, 1969.”
This creates two major issues:
- Hallucination and Misattribution: The model provides a “factually correct” but “contextually wrong” answer. This is harder to detect than complete nonsense.
- Lack of Meta-cognition: The model fails to realize “I don’t have enough information to answer this,” lacking the human-like self-reflection mechanism of saying, “Wait, who do you mean?”
However, solving this isn’t as simple as making the model “ask more questions.” If we overcorrect and design a Force Clarification system, the model becomes an annoying bot that asks, “Do you mean modern-day France?” even for clear questions like “What is the capital of France?”.
Therefore, the real challenge is Selectivity: the model must have the discernment to seek clarification only when necessary while remaining efficient when the question is clear.
2.2 The Evaluation Deadlock
Beyond model behavior, the research field faces a massive methodological hurdle: multi-turn conversations are difficult to evaluate. To test a system that “asks back,” human intervention (Human Evaluation) is traditionally required to answer the model’s clarifying questions. This makes experiments extremely expensive, slow, and impossible to guarantee reproducibility (as the quality of responses varies between participants).
3 Methodology
Let’s break down the operational mechanism of CLAM (CLarify-if-AMbiguous). Imagine a user’s question entering the system and passing through a “three-stage decision funnel.”
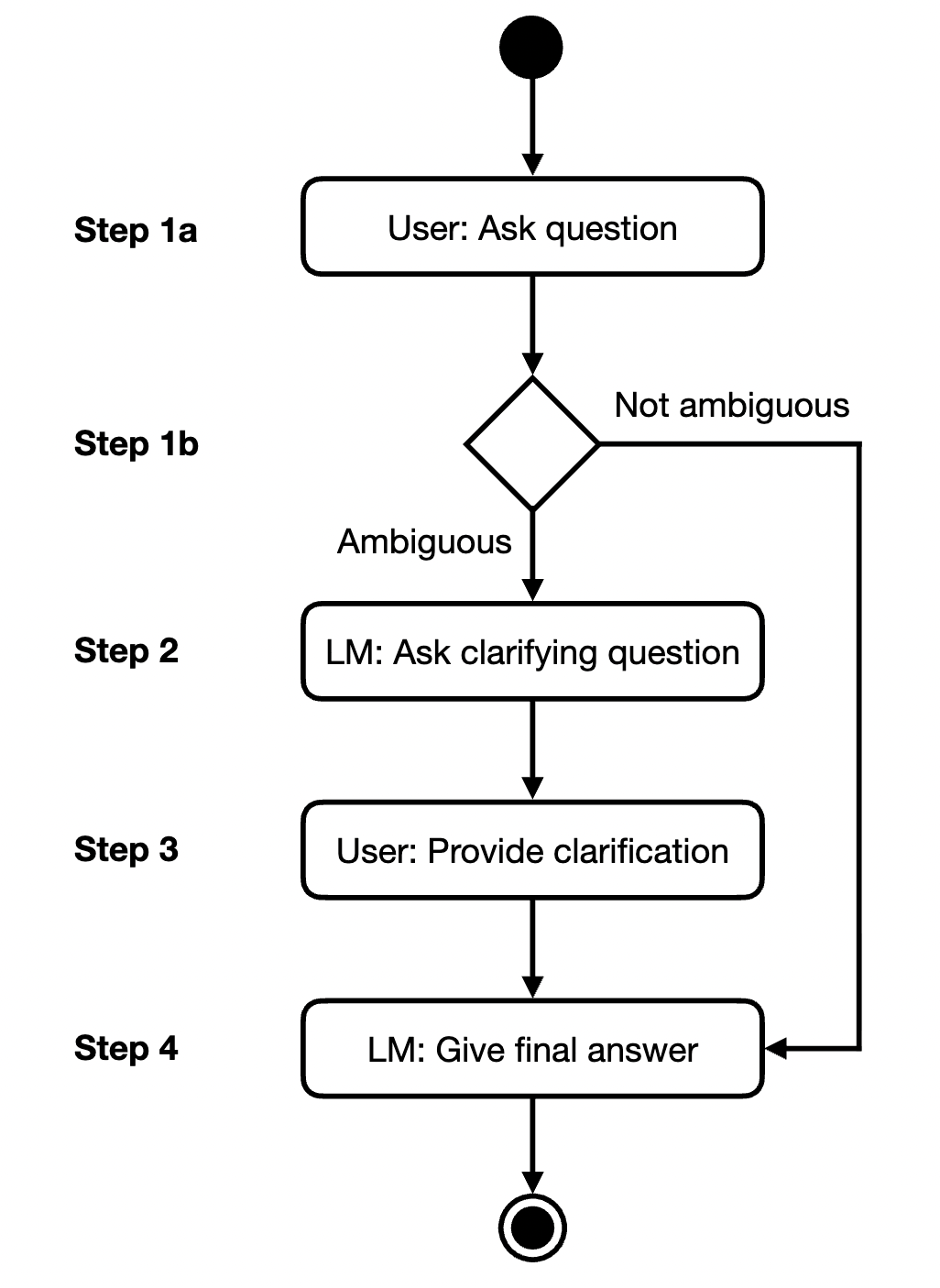
3.1 Stage 1: Ambiguity Detection — The Gatekeeper
This is the “brain” of the entire system. If this classifier fails, the system either becomes mute or overly talkative.
3.1.1 Core Mechanism: Transforming Generation into Classification
The authors did not retrain a classifier; instead, they leveraged the LLM’s own generative capabilities. Using Few-shot Prompting, the model is shown several examples:
Q: Who was the first woman to make a solo flight across this ocean?
This question is ambiguous: True.
Q: Who was the first woman to make a solo flight across the Atlantic?
This question is ambiguous: False.
Q: [User Input]
This question is ambiguous:3.1.2 Key Technique: Application of Log Probability
The output should not be judged solely on the generated text (“True” or “False”), as text is discrete and loses confidence information. CLAM calculates the Log Probability of the model generating “True” as the next token:
Next, a threshold is set (set to -0.3 in the paper).
- If , it is judged as Ambiguous -> enters the clarification workflow.
- If , it is judged as Unambiguous -> answers directly.
3.2 Stage 2: Clarifying Question Generation — The Inquirer
Once the gatekeeper gives the green light (identifies ambiguity), the model’s task shifts from “answering” to “questioning.”
3.2.1 The Art of Prompt Design: Forced Prefix
To prevent the model from rambling or giving up, the authors designed a prompt with a forced guiding sentence:
This is a conversation between a user and a question-answering bot.
... (Few-shot Examples) ...
User: {Ambiguous Question}
Bot: To answer this question, I need to ask the following clarifying question:Note the last line. The system does not let the model generate this part; it is pre-filled. This forces the model to continue the sentence and enter “questioning mode.”
3.2.2 Operational Logic
Based on In-context Learning, the model mimics the patterns in the examples, identifies the point of ambiguity in the question (such as the pronoun “he” or a polysemous word like “bank”), and generates a targeted question (such as “Who is ‘he’?”).
3.3 Stage 3: Resolution & Final Answer — The Solver
This is the conclusion of the process. The system concatenates all information to form a complete context.
3.3.1 Context Concatenation
The final prompt structure fed to the model is as follows:
3.3.2 Implicit Coreference Resolution
This is an LLM’s strength. The model does not need to explicitly rewrite the question (e.g., replacing “he” with “Alan Bean”). Through the Attention mechanism, the model automatically aligns the entity information in with the ambiguous reference in , retrieves the correct knowledge, and generates the final answer.
3.4 Automated Evaluation Protocol (The Oracle Setup)
To solve the “expensive evaluation” problem, the authors introduced an Oracle model. This is an LLM that plays the role of the user during the evaluation phase.
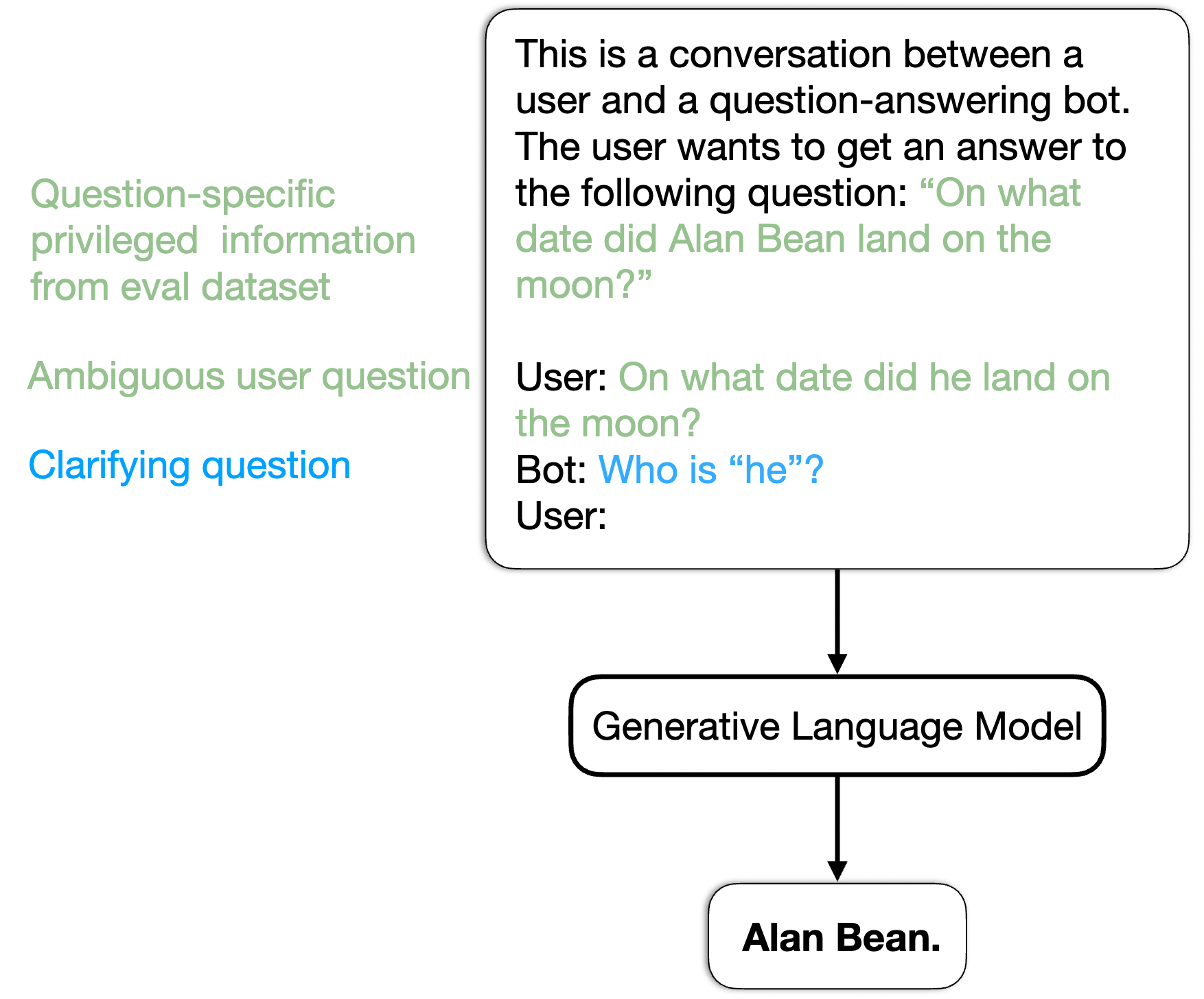
3.4.1 How it works
A paired dataset is used.
- CLAM sees and asks: “Who do you mean?”
- Oracle sees (privileged information) and knows the question is about Alan Bean.
- Oracle answers: “I mean Alan Bean.”
- CLAM generates the final answer based on this response.
3.4.2 Evaluation Metric: Adjusted Accuracy
To penalize “random questioning,” the authors designed a metric. If the model clarifies an unambiguous question (even if it eventually gets it right), the accuracy is multiplied by a penalty coefficient (e.g., 0.8).
This ensures that high-scoring models must possess both accuracy and selectivity.
4 Experimental Results
The experimental section is the moment of truth. The design is robust, proving not only that CLAM improves accuracy but also explaining “why it wins” and “where it wins.” We will focus on three core findings.
4.1 Experimental Setup
To comprehensively evaluate CLAM’s capabilities, the authors used three main datasets:
- Ambiguous TriviaQA (self-constructed): Contains paired ambiguous/unambiguous Q&A, serving as the primary testing ground for core capabilities.
- ClariQ: Query logs from real search engines, focusing on information retrieval scenarios.
- CLAQUA: A multi-turn conversation dataset focused on Entity Disambiguation.
4.2 Key Performance: The Sweet Spot of Accuracy and Efficiency
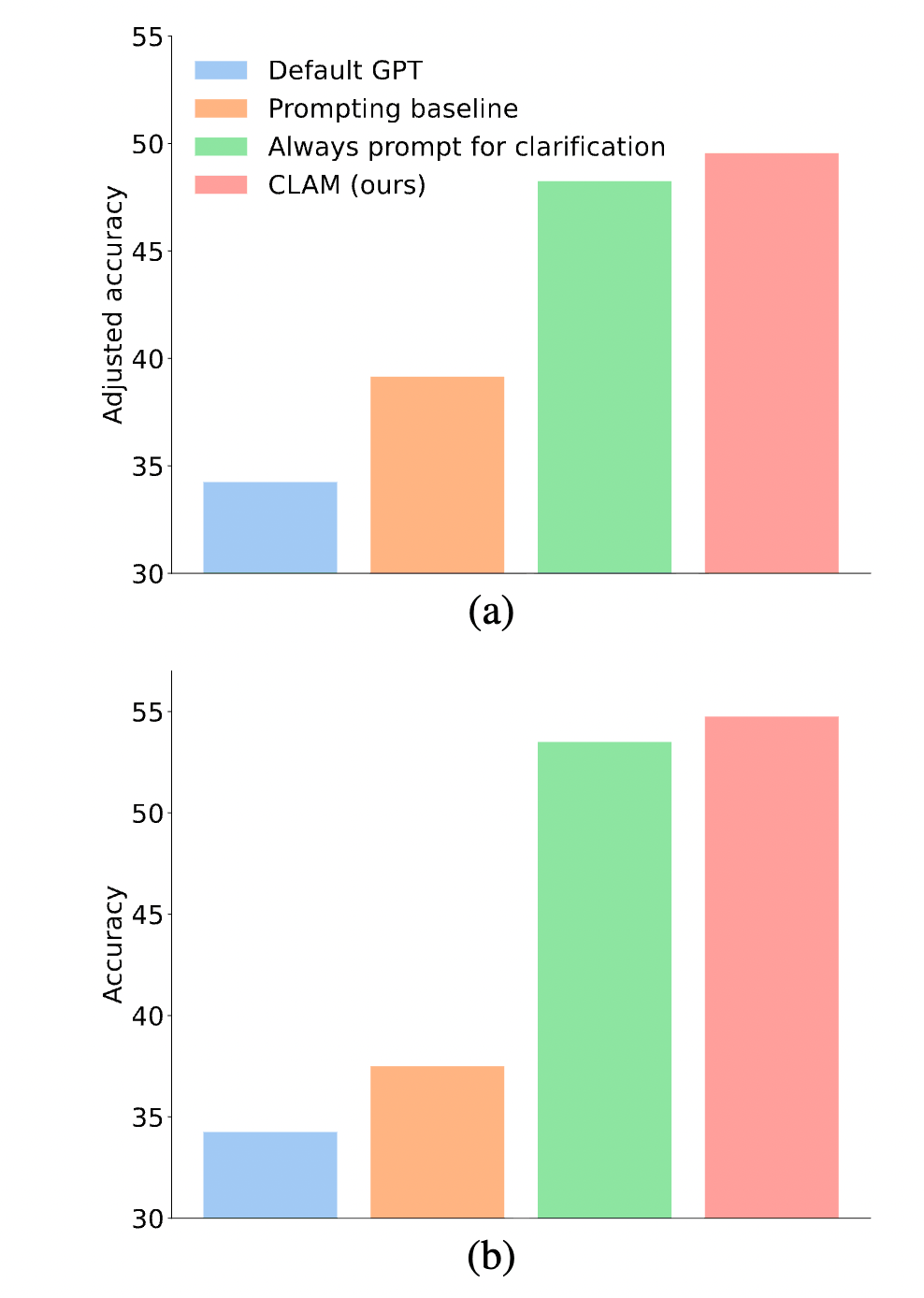
Core Finding 1: CLAM Finds the Optimal Balance In Figure 5(a), CLAM’s bars are significantly higher than all baselines.
- Default GPT (Blue): Because it never asks questions and guesses blindly when meeting ambiguity, its accuracy is extremely low.
- Force Clarification (Green): While it resolves ambiguity, it is heavily penalized by for asking questions even when they are unambiguous.
- CLAM (Red): Highest accuracy. This proves the success of its Selectivity mechanism—acting only when necessary and remaining quiet otherwise.
Core Finding 2: Simple Prompting Cannot Detect Ambiguity This is a crucial result from the ablation study; please refer to Figure 6.

4.3 Component Analysis: Quality of Generation
Beyond “when to ask,” we also care about “how well it asks.”
- Clarifying Question Quality: Manual evaluation shows that clarifying questions generated by CLAM have an 84.0% accuracy rate on Ambiguous TriviaQA and a staggering 99.0% on CLAQUA (see Table 2). This proves LLMs possess strong linguistic understanding to pinpoint ambiguity.
- Oracle Reliability: The Oracle model’s accuracy in answering clarifying questions is as high as 98.8%. This validates that the “automated evaluation protocol” proposed by the authors is highly reliable and can be used confidently in future research.
5 Conclusion
This paper successfully transforms Large Language Models from “blind answering machines” into “reflective conversationalists.”
- Problems Solved: Overcomes LLM overconfidence and hallucinations when facing ambiguity, and addresses the high cost of evaluating multi-turn conversations.
- Methods Used: Proposed the CLAM architecture, combining Few-shot Prompting with a Log Probability detection mechanism to achieve Selective Clarification. Introduced the Oracle automated evaluation protocol.
- Results Achieved: Significantly improved QA accuracy across multiple datasets and proved that the method effectively distinguishes between ambiguous and non-ambiguous questions, vastly outperforming simple prompting strategies.