Steering Large Language Models Between Code Execution and Textual Reasoning

1 Introduction
This article introduces the paper “Steering Large Language Models Between Code Execution and Textual Reasoning”, published on arXiv in October 2024 by researchers from MIT, Harvard, Microsoft, and Google DeepMind, and accepted by the ICLR 2025 conference. The impressive list of authors and the prestigious conference suggest this is a high-quality paper!
2 The Problem This Paper Aims to Solve
As the title suggests, this paper seeks to address/explore the question:
For a Large Language Model (LLM), is it better to reason using Code Execution or Textual Output?
For some Natural Language Processing (NLP) tasks, like generating summaries or engaging in dialogue, Textual Output reasoning is clearly more natural and effective. However, for tasks involving mathematics or logical inference, Code Execution reasoning can often lead to the correct answer more efficiently.
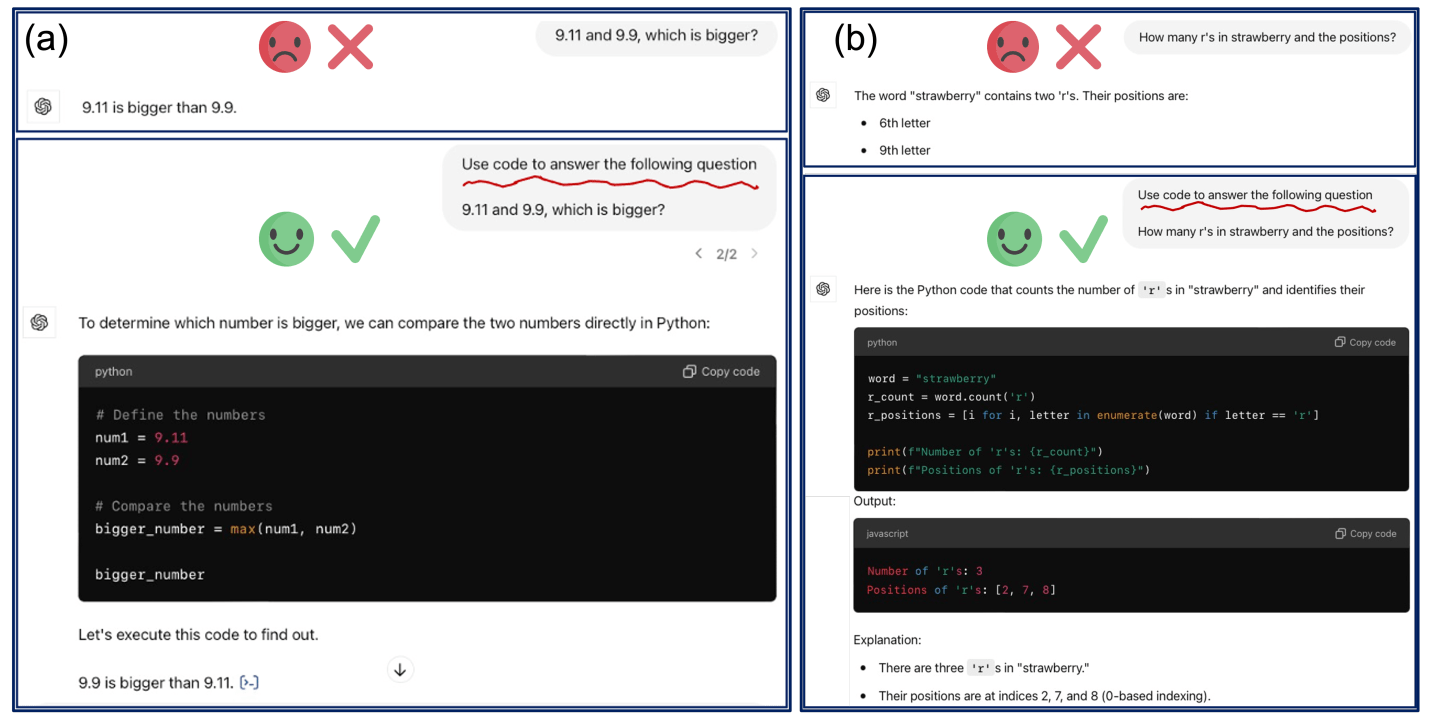
For example, consider the two tasks shown above: “Which is larger, 9.11 or 9.9?” and “How many ‘r’s are in ‘strawberry’ and what are their positions?” These tasks are quite simple, yet GPT-4o provides incorrect answers when using Textual Output reasoning. In contrast, it easily gets them right using Code Execution.
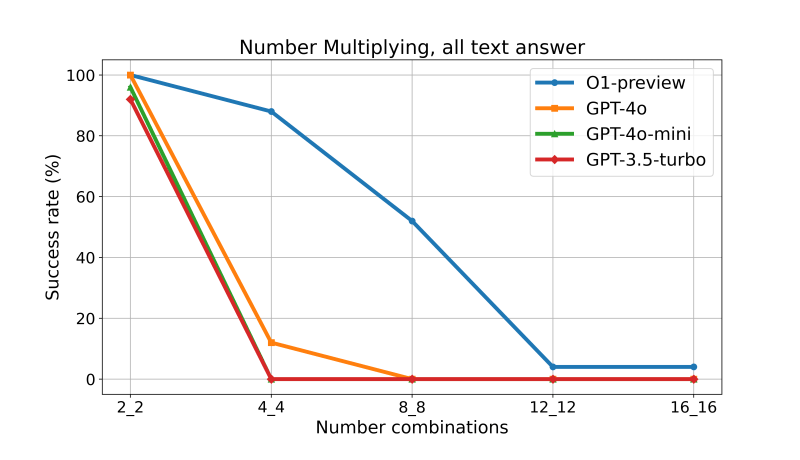
As shown above, or when performing multiplication of two numbers where “2_3” means a 2-digit number multiplied by a 3-digit number, we find that as the number of digits increases, even OpenAI’s O1-type models cannot answer correctly through more Textual Output reasoning.
Clearly, for LLMs, no single reasoning method can solve all problems. Sometimes Textual Output is more suitable, while other times Code Execution is better. Therefore, another question this paper addresses is:
How can we guide LLMs to use the appropriate reasoning method (Textual Output vs. Code Execution) for the right tasks?
Besides answering these two questions, the paper also analyzes the differences in performance when using Textual Output versus Code Execution for reasoning across six LLMs (O1-preview, GPT-4o, GPT-4o-mini, GPT-3.5, Claude-sonnet, Mixtral-8x7b) on various tasks.
3 OpenAI GPT-4o: Code Execution vs. Textual Output
OpenAI’s GPT-4o defaults to Textual Output reasoning, but it can use Code Execution through its Code Interpreter Tool when necessary. The authors analyzed three models—GPT-4o, GPT-4o-mini, and GPT-3.5-turbo—to see whether they would choose Code Execution or Textual Output reasoning for two different tasks: Number Multiplying (calculating the product of two numbers) and Game 24 (given some numbers, select and output an equation that results in 24).
This experiment revealed:
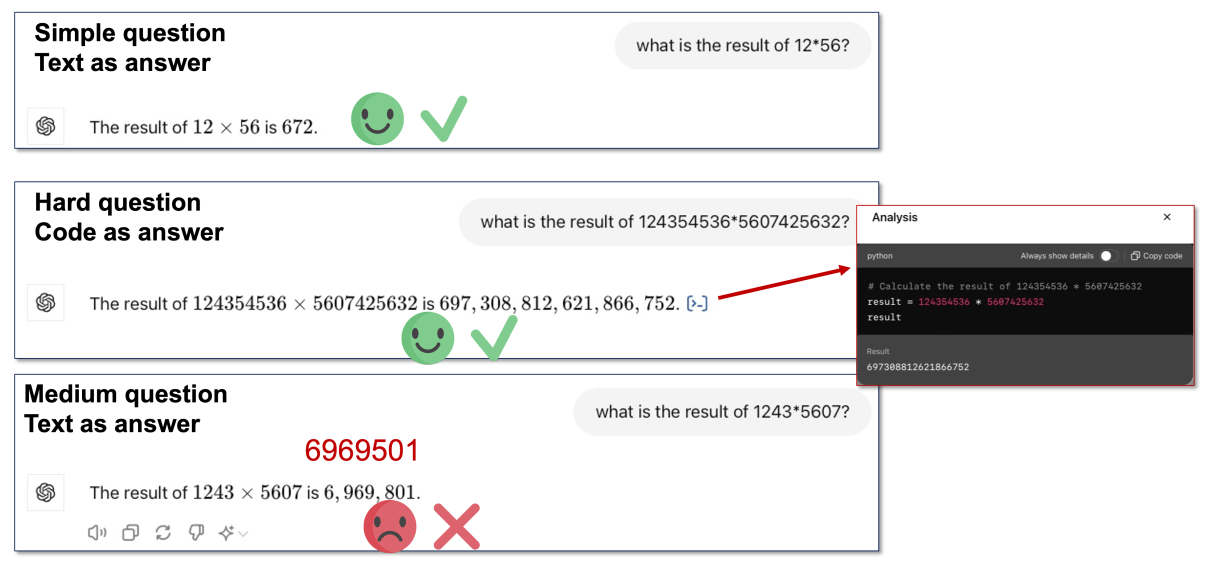
As shown above, GPT-4o confidently uses Textual Output reasoning to correctly answer simple 2-digit multiplication. For very difficult multi-digit multiplication (the second example), GPT-4o knows to use Code Execution. However, in the third example, faced with a moderately difficult 4-digit multiplication, GPT-4o still confidently uses Textual Output reasoning and gets the wrong answer.
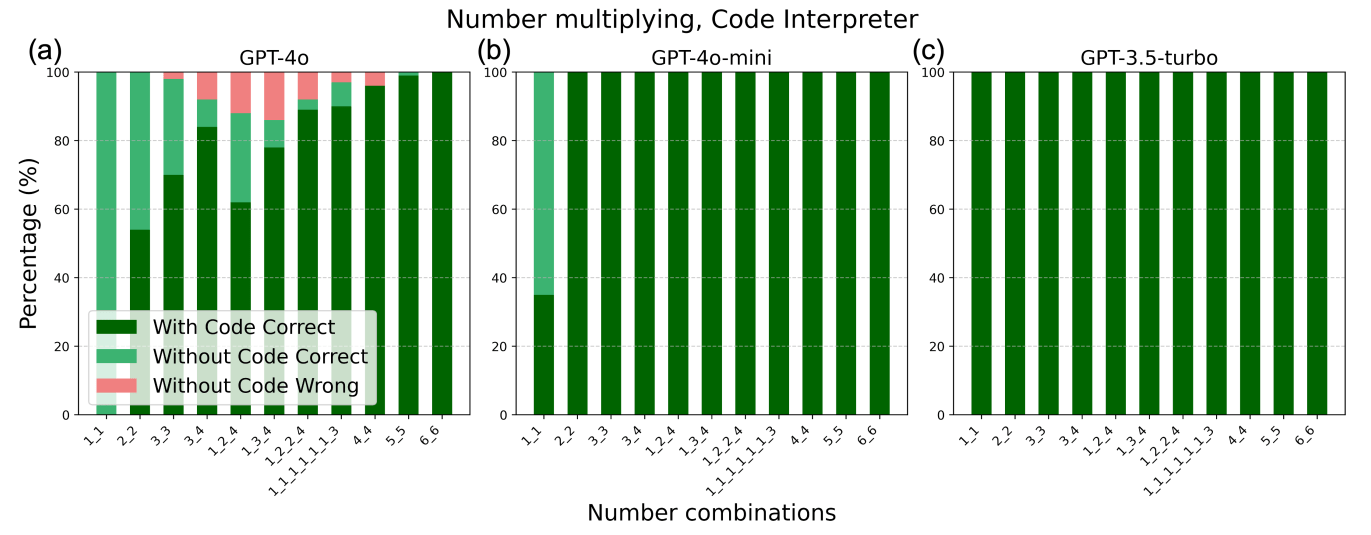
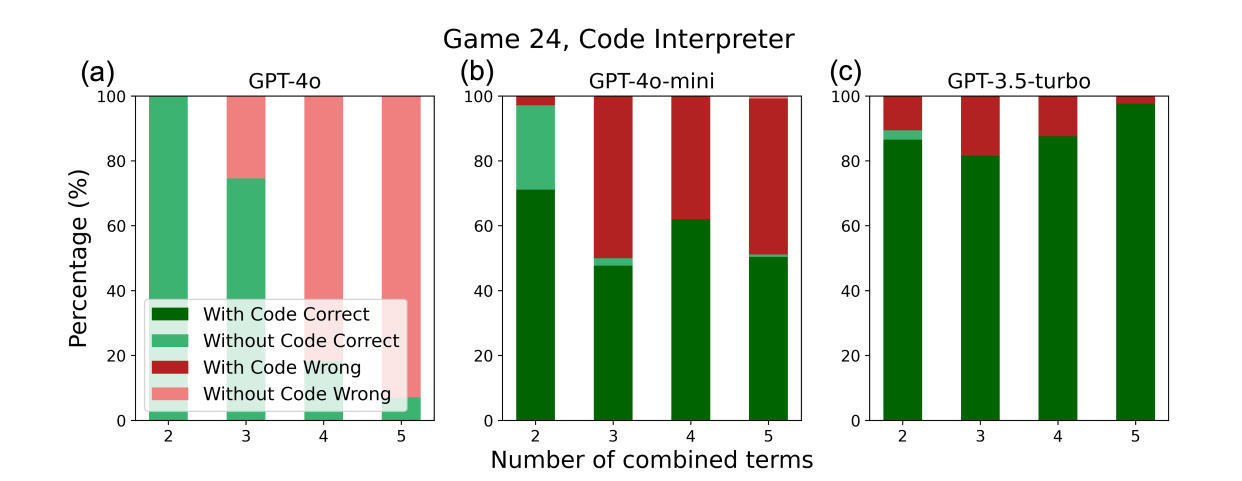
The two images above correspond to Figures 3 and 4 in the paper. The quantitative analysis clearly shows that GPT-4o tends to use Textual Output reasoning for simple tasks and Code Execution for clearly difficult tasks. However, for moderately difficult tasks, it still opts for Textual Output reasoning, leading to a higher error rate. In contrast, GPT-3.5-turbo uses Code Execution reasoning for tasks ranging from simple to difficult.
Since Number Multiplying and Game 24 are tasks well-suited for Code Execution reasoning, the smaller model (GPT-3.5-turbo) actually outperformed the larger model (GPT-4o).
What if we directly instruct the model in the prompt to use Code Execution reasoning? Would all models perform equally well? The authors conducted this experiment but found that:

As shown above, even when GPT-4o is asked to use Code Execution reasoning, it might be inherently confident that the task can be solved with Textual Output reasoning. This can result in code that still mimics textual thought processes, leading to an incorrect final result.
4 Larger-Scale Experimental Analysis
To more thoroughly analyze and compare the performance of existing LLMs on Code Execution and Textual Output reasoning, the authors used 7 baseline methods with 6 LLMs, tested on 14 different tasks.
4.1 Task Types
The 14 tasks are listed below:
- Math
- Number Multiplying
- Game 24
- GSM-Hard
- MATH-Geometry
- MATH-Count&Probability
- Logical Reasoning
- Date Understanding
- Web of Lies
- Logical Deduction
- Navigate
- Robot Planning
- BoxNet
- Path Plan
- Symbolic Calculation
- Letters
- BoxLift
- Blocksworld
These tasks can all be handled by Code Execution reasoning but vary in difficulty. Each task has over 300 test samples, so random variations in LLM output can be largely ignored. For a description of each task and its source paper, please refer to Appendix D of the original paper.
4.2 Method Types
The 7 baseline methods are as follows:
- Only Question: Only the input question is provided.
- All Text: The prompt includes hints to make the LLM reason only with Textual Output.
- All Code: The prompt includes hints to make the LLM reason only with Code Execution.
- All Code + CoT: The prompt includes hints to make the LLM reason only with Code Execution using Chain-of-Thought.
- AutoGen Conca.: The input question is concatenated with the AutoGen system prompt. AutoGen’s System Prompt:
You are a helpful AI assistant. Solve tasks using your coding and language skills. In the following cases, suggest python code (in a python coding block) or shell script (in a sh coding block) for the user to execute. 1. When you need to collect info, use the code to output the info you need, for example, browse or search the web, download/read a file, print the content of a webpage or a file, get the current date/time, check the operating system. After sufficient info is printed and the task is ready to be solved based on your language skill, you can solve the task by yourself. 2. When you need to perform some task with code, use the code to perform the task and output the result. Finish the task smartly. Solve the task step by step if you need to. If a plan is not provided, explain your plan first. Be clear which step uses code, and which step uses your language skill. When using code, you must indicate the script type in the code block. The user cannot provide any other feedback or perform any other action beyond executing the code you suggest. The user can’t modify your code. So do not suggest incomplete code which requires users to modify. Don’t use a code block if it’s not intended to be executed by the user. If you want the user to save the code in a file before executing it, put # filename: filename inside the code block as the first line. Don’t include multiple code blocks in one response. Do not ask users to copy and paste the result. Instead, use ’print’ function for the output when relevant. Check the execution result returned by the user. If the result indicates there is an error, fix the error and output the code again. Suggest the full code instead of partial code or code changes. If the error can’t be fixed or if the task is not solved even after the code is executed successfully, analyze the problem, revisit your assumption, collect additional info you need, and think of a different approach to try. When you find an answer, verify the answer carefully. Include verifiable evidence in your response if possible. Reply ”TERMINATE” in the end when everything is done. - AutoGen System: Uses AutoGen’s system prompt as the LLM’s system prompt (LLMs do not use a system prompt by default).
- Code Interpreter: Allows the LLM to use a Code Interpreter.
4.3 LLM Model Types
The 6 LLMs are as follows:
- O1-preview
- GPT-4o
- GPT-4o-mini
- GPT-3.5-turbo-16k-0613 (GPT-3.5)
- Claude-3-sonnet-20240229 (Claude-sonnet)
- Open-mixtral-8x7b (Mixtral-8x7b)
Apart from the GPT series LLMs, which offer a Code Interpreter function, the other LLMs do not. Therefore, they were not tested with the Code Interpreter method. O1-preview cannot have its system prompt changed, so the AutoGen System method is not applicable to O1-preview.
4.4 Evaluation Metric
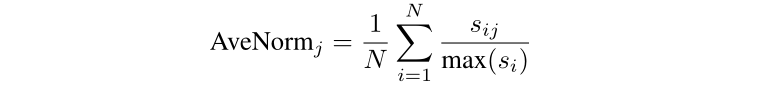
The authors used the Average Normalized Score as the score for each method. AveNorm represents the final score of the -th method, is the score of the -th method on the -th task, and max() is the maximum possible score for the -th task.
4.5 Experimental Results
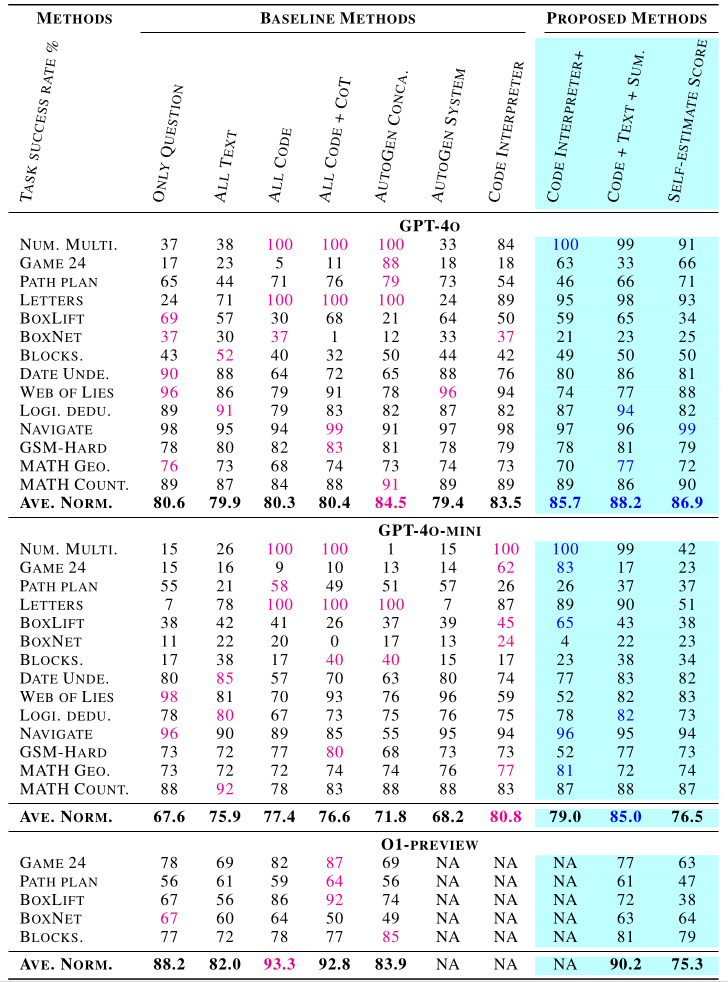
From the experimental results in the table above, the authors derived 2 insights:
- Among the 7 baseline methods, there is no single best method applicable to all tasks; different tasks are suited to different reasoning methods.
- Using Code Execution reasoning is not always best. For some tasks, Textual Output reasoning yields better performance, primarily because:
- Some tasks require consideration of too many aspects, and the LLM-generated code doesn’t fully account for them.
- Code restricts the tokens an LLM can output, thereby limiting the LLM’s thinking process.
5 Methods Proposed by This Paper
The authors propose 3 methods to improve LLM performance when using Textual Output or Code Execution reasoning:
Code Interpreter+: Similar to the baseline method “All Code,” this encourages the LLM to use Code Execution for reasoning (the paper doesn’t clearly distinguish this method from the “All Code” baseline).
Code + Text + Sum.: First, results are obtained using the “All Code” and “All Text” methods (based on Code Execution and Textual Output reasoning, respectively). Then, another LLM summarizes these two answers to produce a final answer. The prompt is as follows:
You are a helpful AI assistant. Solve tasks using your coding and language skills. In the following cases, there are two different agents respond to the same problem. In some cases, they output the direct answer, while sometimes they output the code to calculate the answer. I will display you the initial question and the answers from two agents. The code execution results will also be given if the code exists. Your task is to analyze this question based on the analysis and answers from above two agents and then output your final answer. If you want to generate code to acquire the answer, suggest python code (in a python coding block) for the user to execute. Don’t include multiple code blocks in one response, only include one in the response. Do not ask users to copy and paste the result. Instead, use ’print’ function for the output when relevant. I hope you can perform better than other two agents. Hence, try to choose the best answer and propose a new one if you think their methods and answers are wrong.Self-estimate Score: The LLM is first asked to give a score for both Textual Output and Code Execution reasoning methods based on the current problem, indicating which method is more suitable. Then, the LLM is asked to reason according to the method with the higher score. The prompt is as follows:
You will be presented with a task that can potentially be solved using either pure textual reasoning or coding (or a combination of both). Your goal is to determine which method will be most effective for solving the task and figure out the answer. Follow these steps: 1. **Estimate your confidence level** in solving the task using both approaches: - **Coding score (0-10)**: How confident are you that you can solve this task correctly by writing code? Provide reasoning. - **Text score (0-10)**: How confident are you that you can solve this task correctly by using textual reasoning? Provide reasoning. 2. **Choose the approach** that you believe has the highest chance of success: - If one score is significantly higher, start with that approach. - If both scores are close, start with textual reasoning first, then decide if coding is necessary after. 3. **Solve the task** using the chosen method: - If you chose coding, write the necessary code, explain the logic behind it, and run it. - If you chose textual reasoning, use detailed explanation and logical steps to reach the answer. 4. **Reflect** after attempting the task: - Did the chosen approach work well? If not, should you switch to the other method? Now, here is the task:
6 Experimental Results
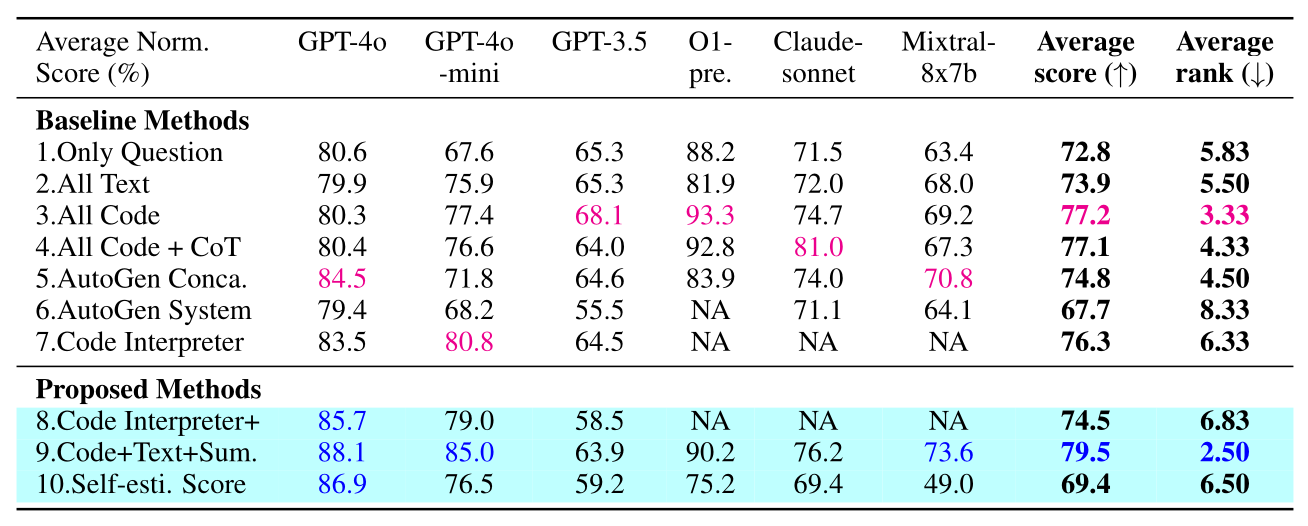
Both Table 1 and Table 2 show that Code + Text + Sum. performs the best among all methods. This suggests that instead of forcing an LLM to choose only Textual Output or Code Execution reasoning, allowing it to consider the results of both reasoning methods leads to the best performance.
7 Conclusion
This article introduced an ICLR 2025 paper — Steering Large Language Models Between Code Execution and Textual Reasoning — which primarily focuses on understanding LLM choices and performance between Textual Output and Code Execution reasoning methods.
Here are the key takeaways from this paper:
- Larger models (like GPT-4o) tend to use Textual Output reasoning for tasks of moderate difficulty, which can lead to incorrect answers. Conversely, smaller models (like GPT-3.5-turbo) tend to use Code Execution reasoning for tasks of all difficulty levels, resulting in higher accuracy.
- Requiring a model to use Code for reasoning in the prompt doesn’t guarantee good results; the model might generate inefficient code that resembles Textual Output, leading to incorrect answers.
- Some tasks are better suited for Textual Output reasoning, while others are better for Code Execution; there’s no absolute best method.
- When an LLM uses Code Execution for reasoning, it might perform poorly due to two reasons:
- Some tasks involve too many aspects, and the LLM-generated code doesn’t fully consider them.
- Code restricts the tokens an LLM can output, thereby limiting its thinking process.
- Allowing an LLM to summarize a final answer based on the results of both reasoning methods yields the best performance.