DPO:Direct Preference Optimization

1 Introduction
In the article LLM Fine-Tuning: Reinforcement Learning from Human Feedback, we introduced the three steps of Large Language Model (LLM) training: Self-Supervised Pre-Training, Supervised Fine-Tuning, and Reinforcement Learning from Human Feedback (RLHF).
The paper we are sharing in this article, DPO (Direct Preference Optimization), was accepted at NeurIPS 2023. It primarily focuses on improving the third stage of the training process, RLHF, by proposing a more efficient training method.
Quick reminder: Before reading this article, please make sure you fully understand the concept of RLHF!
2 Why is RLHF Necessary?
Before explaining the problems with RLHF, let’s first review why LLM training needs to go through the RLHF stage.
This is mainly because after Self-Supervised Pre-Training, an LLM becomes a veritable “master of text completion.” Given a prompt, it can generate countless possible outputs. When we ask an LLM a question, even if it knows all the possible answers, it doesn’t know which one humans prefer.
In other words, depending on the context, we want the LLM to produce an answer that satisfies human preference. Therefore, we need to perform Preference Learning on the pre-trained LLM!
Currently, the mainstream approach to LLM Preference Learning involves the second stage, Supervised Fine-Tuning, followed by the third stage, RLHF. However, the complexity and instability of RLHF training make it difficult for the average person to efficiently train an LLM with it. Therefore, this paper specifically addresses the problems in the RLHF training stage by proposing a new training method: “DPO”.
3 What are the Problems with RLHF?
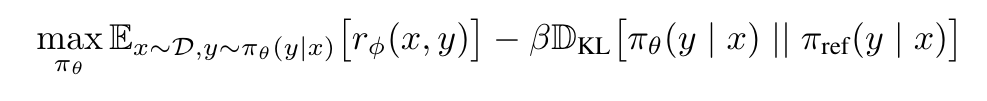
Next, let’s talk about the problems within the RLHF training stage. The image above shows the optimization problem that needs to be addressed during the RLHF stage. At this stage, the goal is to train the LLM to “maximize the reward” while being constrained by “KL Divergence.” We can identify two problems here:
- We need to train a Reward Model using a pre-collected Preference Dataset.
- We need to use an RL algorithm (e.g., Proximal Policy Optimization, PPO) to enable the LLM to learn the correct output by maximizing the reward.
4 DPO: Direct Preference Optimization
The DPO method attempts to solve the two problems mentioned above:
- Can we skip the step of building a Reward Model and directly train the LLM using the Preference Dataset to make the training process more efficient?
- Can we use a Supervised Learning method instead of Reinforcement Learning to reduce the instability of the model training process?
And it proposes a new Loss Function:
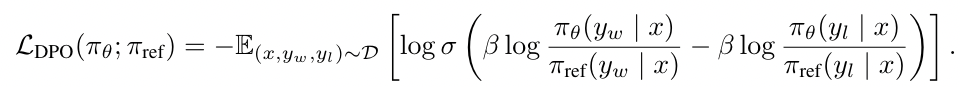
From the DPO Loss Function, we can see that given a Preference Dataset, we sample a data point containing a prompt (), a winning response (), and a losing response (). Based on the prompt (), the model () must learn to increase the probability of generating the winning response () and decrease the probability of generating the losing response ().
This process is essentially equivalent to the original RLHF, where the model learns to output the winning response to get a higher reward (and avoid outputting the losing response, which yields a smaller reward).
Furthermore, you can see that both the first and second terms of the subtraction are divided by the probability of the reference model () generating the corresponding response. This echoes the KL-Divergence constraint in the original RLHF (to prevent the model being trained, , from deviating too much from its original self, ).
Finally, we can also see that in the DPO training process, the model undergoes Supervised Learning rather than Reinforcement Learning, and it doesn’t require the assistance of a Reward Model. This not only enhances the stability of model training but also reduces the required computational resources.
In the original DPO paper, the authors clearly explain how to derive the DPO optimization method from the original RLHF optimization process. Interested readers should definitely read the paper. Additionally, the effectiveness of the DPO method can be seen in the paper’s experiments as well as on Hugging Face, so we won’t elaborate further here.
5 Conclusion
In this article, we briefly introduced the concept of DPO: Direct Preference Optimization, explaining how it retains the advantages of RLHF while improving upon its instability and inefficiency during training. After understanding DPO, you might have this question in mind: Although DPO eliminates the need for a Reward Model and can directly optimize the model via Supervised Learning, it still requires a pre-existing Preference Dataset.
We all know that the Preference Dataset used to train the Reward Model in RLHF is a high-cost dataset that requires significant human effort and time to create. Is it possible to further improve DPO to avoid the need for creating a Preference Dataset?
Yes! In January 2024, several papers (such as Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models and Self-Rewarding Language Models) were uploaded to Arxiv, aiming to eliminate the need for creating a Preference Dataset through various techniques.