Dynamic Cheatsheet: The Secret to Self-Improving LLMs that Learn During Inference

1 Introduction
This article will share insights from the paper “Dynamic Cheatsheet: Test-Time Learning with Adaptive Memory,” which was uploaded to arXiv in April 2025. I wanted to discuss this paper because its methods form the basis for a recent and popular Self-Improving Agent paper, “Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models.” The authors of Dynamic Cheatsheet have also open-sourced their code on GitHub, which interested readers can explore and test for themselves!
2 The Problem Dynamic Cheatsheet Aims to Solve
The problem that the Dynamic Cheatsheet paper aims to solve is very straightforward:
How can an LLM Agent continuously learn during the inference phase, so that its performance improves as the number of inferences increases?
The Dynamic Cheatsheet method is designed for Black-Box LLMs. Therefore, it does not aim to alter the LLM’s weights through Gradient Descent. Instead, it seeks to modify the LLM’s input context, allowing the model to incorporate past experiences to produce correct outputs. This technique falls under the popular field of Context Engineering.
3 How Dynamic Cheatsheet (DC) Works
In this paper, the authors propose two main methods:
- DC-Cumulative (DC-Cu)
- DC with Retrieval & Synthesis (DC-RS)
The core concept behind both methods is to allow the LLM to autonomously manage a non-parametric memory. By recording noteworthy information from the inference process into this memory, the memory itself can evolve adaptively. With each new inference, the model references the information in the memory to generate a better output.
3.1 DC-Cumulative (DC-Cu)
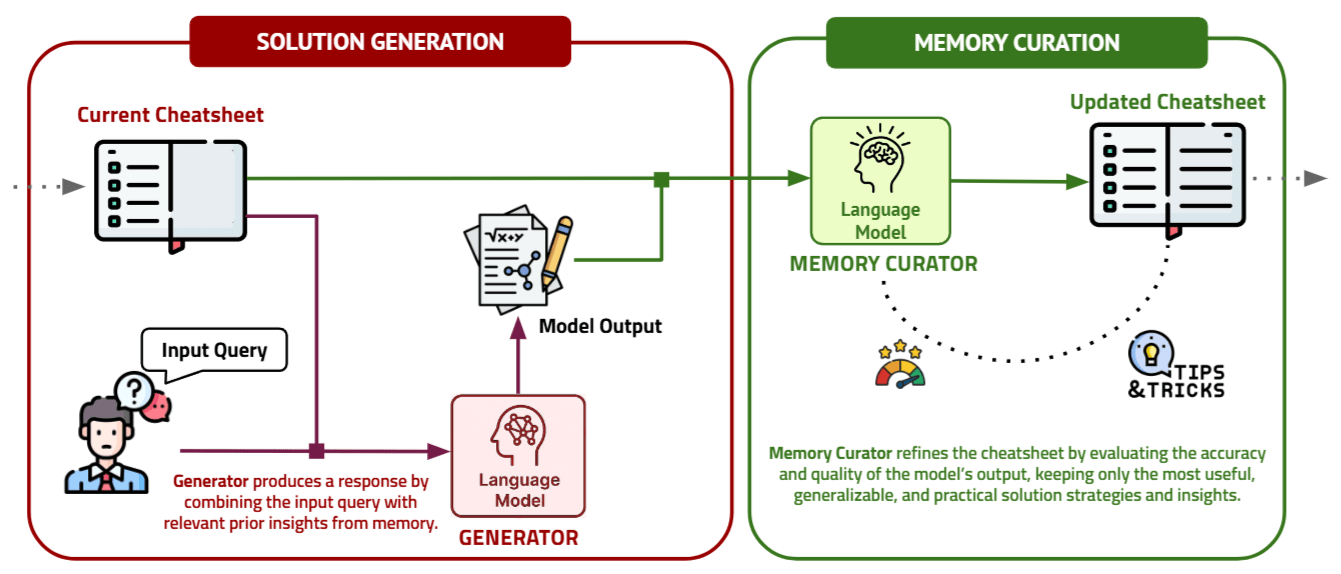
Let’s start with the DC-Cumulative (DC-Cu) method. The image above illustrates its complete workflow, which is primarily divided into two stages: Solution Generation and Memory Curation.
- Solution Generation: The model generates an answer based on (1) the current Input Query and (2) all the content within the Memory.
- Memory Curation: The model generates a new Memory based on (1) the current Input Query, (2) all the content within the Memory, and (3) the answer it just produced. Memory Curation involves the following three operations:
- Extracting meaningful insights from the newly generated answer and storing them in the Memory.
- Deleting or modifying incorrect or outdated information in the Memory.
- Making the Memory more concise.
From this process, it’s clear that the success of the DC-Cumulative method hinges on the LLM’s ability to determine whether the current answer is correct during the Memory Curation stage and, consequently, update the Memory reasonably.
3.2 DC with Retrieval & Synthesis (DC-RS)
As its name suggests, DC with Retrieval & Synthesis (DC-RS) adds retrieval and synthesis steps to the DC method. DC-RS is designed to address two main drawbacks of DC-Cu:
- During Solution Generation, the content in the Memory is outdated and not perfectly suited for the current Input Query.
- During Memory Curation, the model can only reference the immediately preceding input-output pair, rather than a wider range of past examples.
Therefore, the DC-RS method consists of the following steps:
- Example Retrieval: Based on (1) the current Input Query, use an Embedding Model to retrieve the Top-K most similar input-output examples.
- Memory Curation: The model generates a new Memory based on (1) the current Input Query, (2) all the content within the Memory, and (3) the Top-K input-output examples just retrieved.
- Solution Generation: The model generates an answer based on (1) the current Input Query and (2) all the content within the Memory.
4 Dynamic Cheatsheet Experiments
4.1 Baselines
- Baseline prompting (BL).: Directly prompting the LLM to generate an answer without the aid of Memory Curation or Example Retrieval.
- DC- (empty memory).: Using the DC method but with an initially empty memory.
- Full-History Appending (FH).: Continuously accumulating the entire history of interactions within the LLM’s input context.
- Dynamic Retrieval (DR).: For each inference, retrieving the input-output examples most similar to the current query and placing them in the LLM’s input context (this is equivalent to performing retrieval without curation, as the raw examples are used directly instead of first being distilled into insights).
4.2 Benchmarks
- AIME 2020–2025 Exam Questions
- GPQA-Diamond
- Game of 24
- Math Equation Balancer
- MMLU-Pro (Engineering and Physics)
4.3 Results
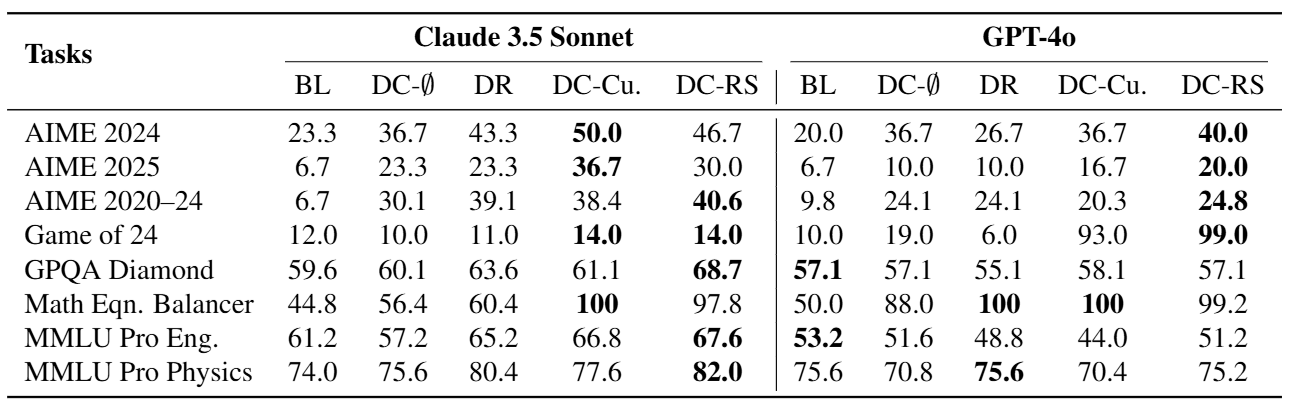
Taking the Game of 24 from Table 1 as an example, we can see that the DC-RS method achieves the best performance with GPT-4o. In contrast, the performance of DC- is quite poor, which indicates that empowering the LLM with memory retrieval and curation capabilities can indeed enhance its performance.
However, when using Claude 3.5 Sonnet, the improvement of DC-RS over the baseline method is less significant. The paper explains that while Dynamic Cheatsheet provides the LLM with the potential for test-time adaptation, the effectiveness of this adaptation still depends on the inherent capabilities of the LLM itself.
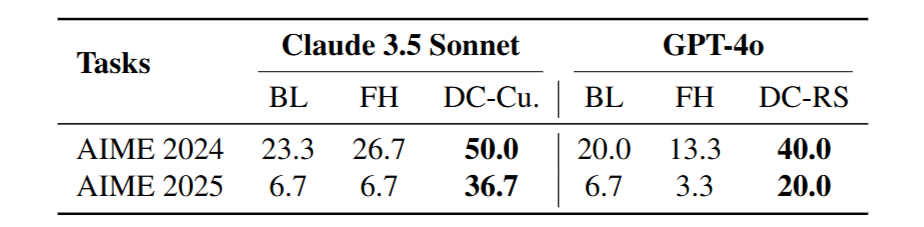
From Table 2, we can observe that simply retaining all past experiences (input-output examples) in the LLM’s input context (the FH method) not only fails to significantly improve performance but can sometimes perform worse than the baseline method of simply prompting the LLM (BL).
This highlights the importance of the retrieval and curation steps in the DC-RS method. Retrieving truly relevant past experiences and curating them into more concise and generalizable insights is crucial for effective performance enhancement.
5 Conclusion
This article introduced the “Dynamic Cheatsheet: Test-Time Learning with Adaptive Memory” paper, explaining how to implement a simple Self-Improving LLM using the technique of adaptive memory. The experimental results also show us that merely stuffing all information into memory or retrieving everything from it yields limited performance gains. To achieve effective improvement, these steps must be combined with Memory Retrieval and Curation.