EHRAgent: Code Empowers Large Language Models for Few-shot Complex Tabular Reasoning on Electronic Health Records

1 Preface
Tabular Data is a common data format in daily work. For any large company, data is often stored in a Relational Database; for smaller companies, they will at least use Excel or CSV to record some daily financial status. Whether it is Relational Database, Excel, CSV…, they are all Tabular Data!
Since the advent of LLMs, we have begun to use LLMs to perform reasoning tasks on various Data Modalities, and LLMs are no exception for reasoning tasks on the Tabular Modality. There is even a Poster “Position: Why Tabular Foundation Models Should Be a Research Priority” at ICML 2025 discussing that research on Foundation Models should begin to shift from Text and Image to Tabular Data.
This article aims to share a paper from EMNLP 2024 — EHRAgent: Code Empowers Large Language Models for Few-shot Complex Tabular Reasoning on Electronic Health Records. This paper uses Electronic Health Record, a Domain-Specific Tabular Data, as an example to illustrate how to design an LLM-Based Single Agent for complex Tabular Reasoning.
2 Challenges Faced by EHRAgent
The task addressed in this paper is to apply an LLM Agent to a Medical Domain Table-Based Question-Answering Task. In the Medical Domain, there is something called Electronic Health Record (EHR), which is essentially the concept of electronic medical records.
A large amount of EHR is stored in a hospital’s Relational Database. Suppose there is an EHR Query today. Typically, an engineer needs to perform many searches from the Database to find the relevant Tables to infer the final answer. Therefore, if an LLM Agent can understand these Tables, it will undoubtedly reduce significant search time. However, designing an LLM Agent for the EHR TableQA task still faces the following challenges:
- LLMs lack Medical Domain knowledge, making it difficult to correctly retrieve Tables or Records.
- The Relational Database involved in EHR Queries is usually very large. For example, there might be data for 46K Patients across 26 Tables. How to retrieve the correct data from such a large amount of Records?
- If the Query itself is Multi-Hop, it also requires Multi-Step Operations on the Tables.
Therefore, the EHRAgent proposed in this paper aims to improve the performance of LLM Agents on Multi-Table Reasoning Tasks!
3 EHRAgent Method Overview
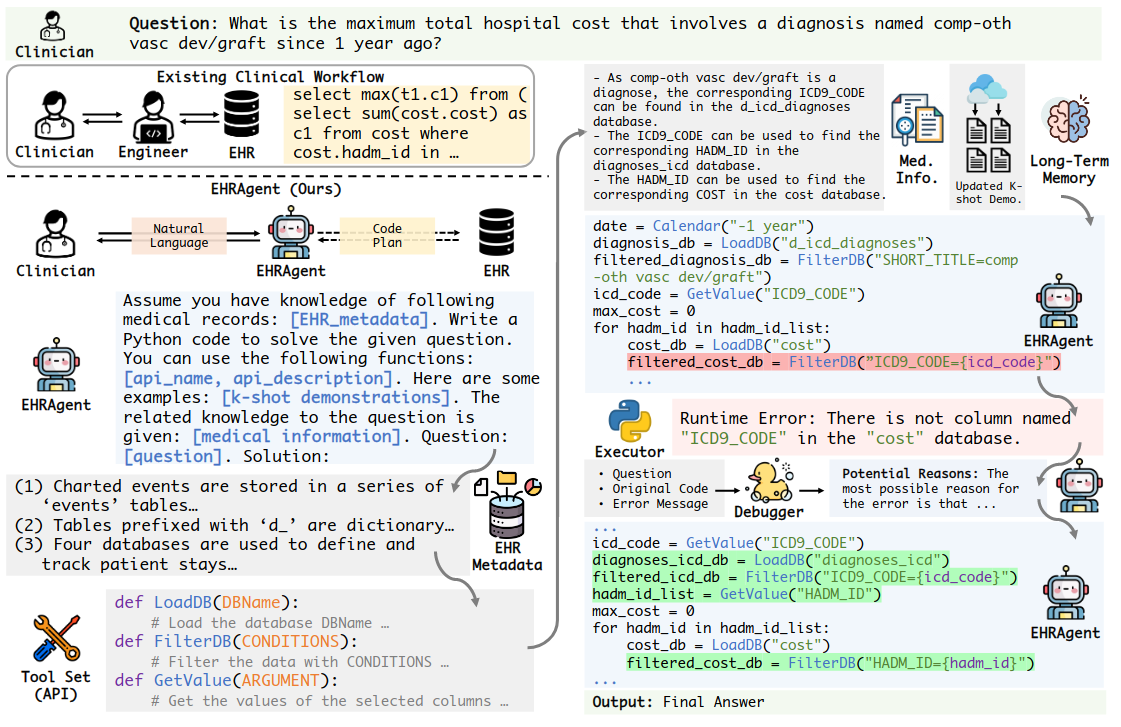
As shown in Figure 3 above, EHRAgent generates a Code Plan based on the User (Clinician)’s Query to obtain the Answer from the EHR Database.
To make the Prompt generated by the LLM Agent clearer and reduce ambiguity, a common approach is to let the Plan generated by the LLM Agent be expressed through Code rather than Natural Language. Therefore, in EHRAgent, Plan = Sequence of Action = Sequence of Executable Code = Iterative Coding: the LLM Agent (Planner) is responsible for generating Code, the Executor actually executes the Code, and the execution result is returned as Feedback to the LLM Agent (Planner), allowing it to continue refining the Code.
The authors believe that having the Planner and Executor engage in such a Multi-Turn Dialogue can enable the Planner to generate a better Code Plan. Specifically, EHRAgent includes 4 steps:
- Information Integration
- Demonstration Optimization through Long-Term Memory
- Interactive Coding with Execution
- Rubber Duck Debugging via Error Tracing
4 EHRAgent #1 Step: Information Integration
The purpose of this stage is to provide more Medical Domain Information to the LLM to make it better understand the Background Knowledge of the current Query. Specifically, each Table in the EHR Relational Database has a complete description:
- Table Description
- Each Column Description
Summarize the Key Information of each Table’s description (Table Description + Each Column Description) in advance, then combine the Key Information of all Tables and use an LLM to extract information relevant to the current Query as part of the Prompt. This is the “[medical information]” presented in the Prompt in Figure 3. In addition, the Table’s Metadata information is also included in the Prompt ("[EHR_metadata]").
5 EHRAgent #2 Step: Demonstration Optimization through Long-Term Memory
The purpose of this stage is to provide Experience similar to the current Query to the LLM, allowing the LLM to refer to this Experience to generate a better Code Plan. Specifically, it is necessary to maintain a Long-Term Memory, which mainly records previously successfully processed Queries and their corresponding Actions (Code Plan).
Based on a Query, the K most similar Queries and their Actions to the current Query are retrieved from the Long-Term Memory, allowing the LLM to refer to these Demonstrations to perform subsequent reasoning. This is the “[k-shot demonstrations]” presented in the Prompt in Figure 3.
6 EHRAgent #3 Step: Interactive Coding with Execution
The purpose of this stage is to allow the LLM to generate a Code Plan based on the Query and modify the Code Plan through the execution results of the Code. Specifically, the LLM is allowed to generate the Code Plan based on the following content:
- Input Query
- Database Metadata (generated in #1 Step)
- Database Key Information (generated in #1 Step)
- K-Shot Demonstration (generated in #2 Step)
- Tool Function Definition
Tool Function Definition is actually the “[api_name, api_description]” in the Figure 3 Prompt. It explains the functions usable by the LLM (ex. Calendar, LoadDB, GetValue, …).
In this stage, the Executor will first Parse out the Code to be executed from the LLM’s Output, then execute it step by step and return the execution results to the LLM, allowing the LLM to continue modifying the Code.
It is clear that the core idea here is actually to let the LLM improve its output based on Feedback. This idea is widely present in various papers!
For example, in Self-Refine (NeurIPS 2023), the LLM itself (rather than external tools) is directly Prompted to generate Feedback, and then modifies the original output based on the Feedback; while in CRITIC (ICLR 2024), the concept of external tools is introduced, allowing the LLM to choose external tools to check its output and generate some Feedback. In this paper, EHRAgent also uses external tools to generate Feedback, except that it fixes the Code Executor tool without allowing the LLM to choose other tools.
7 EHRAgent #4 Step: Rubber Duck Debugging via Error Tracing
The purpose of this stage is to allow the Executor’s Feedback to include more Insight, giving the LLM a better direction for modifying the Code Plan. This is mainly because the authors found in practice that if only a brief Error Message is provided to the LLM, the LLM will only make minor modifications to the original Code and cannot truly solve the problem.
Therefore, the authors Parse out more Detail from the Executor’s execution results, including Detailed Trace, Feedback Error Type, Error Message, Location, and other information, and then allow the LLM to first analyze based on this information why the original Code Plan had problems, and finally allow the LLM to modify the Code based on its own analysis results.
8 EHRAgent Experimental Results
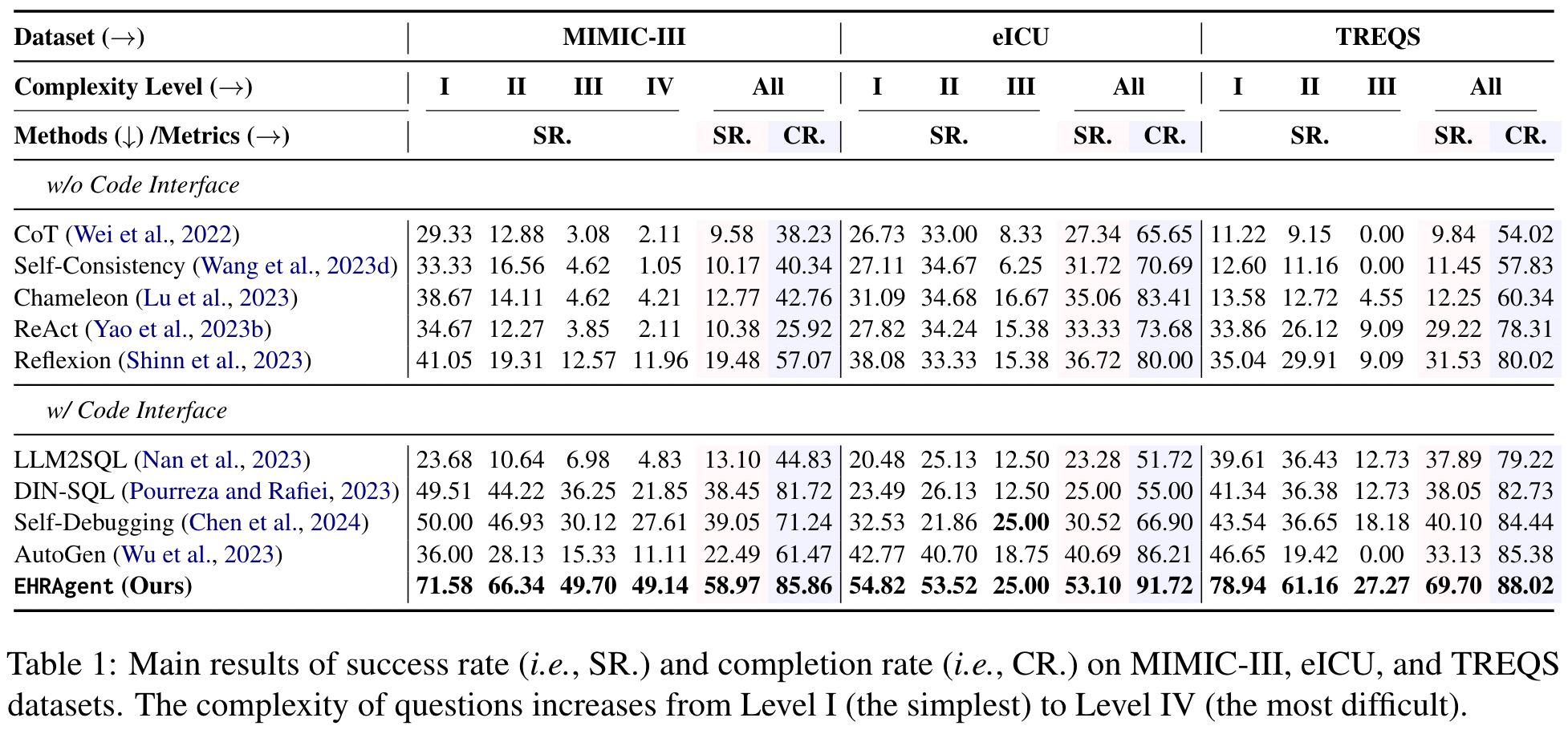
Table 1 presents the performance of EHRAgent and all Baselines. From the choice of Baselines, I think it is quite good, many classic Single Agent methods (ex. ReAct (ICLR 2023), Reflexion (NeurIPS 2023), Chameleon(NeurIPS 2023)) have been included. From Table 1, the authors propose the following Insight:
- EHRAgent’s performance significantly surpasses other Baselines.
- The reason for the poor performance of CoT, Self-Consistency, and Chameleon is mainly because they did not refine their Plan based on the Feedback from the Environment.
- Although ReAct and Reflexion considered Feedback, they focused too much on the Tool’s generated Error Message and did not consider the overall Planning. I guess the authors here intend to express that EHRAgent’s method can indeed help the LLM Agent make good modifications to the Plan based on Feedback.
Some methods that directly generate SQL (Ex. LLM2SQL or DIN-SQL) perform poorly, mainly because the Quality of the generated SQL Code is actually not good enough. In addition, they also lack a Debugging Process to make better modifications to the SQL Code they generate.
Finally, the authors also mentioned that Self-Debugging and AutoGen are among the better performing methods among all Baselines because they considered Feedback and also analyze based on Feedback before making modifications. But because they did not consider Domain Knowledge, their performance is not good.
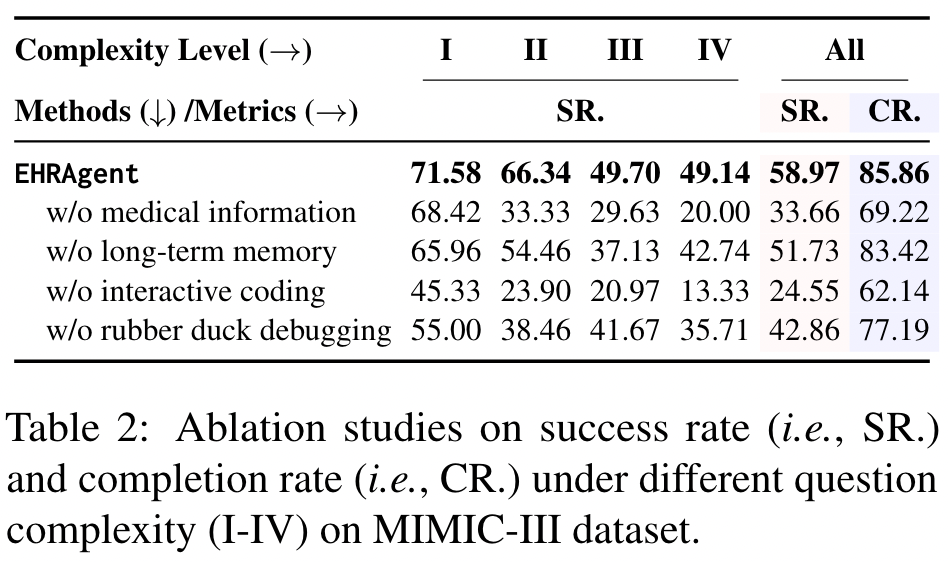
From the Ablation Study in Table 2, the authors emphasize two key points:
- The Interactive Coding method plays an important role.
- For more complex questions, Domain Knowledge Integration also becomes increasingly important.
9 Conclusion
This article mainly introduces the EHRAgent (EMNLP 2024) paper. EHRAgent improves the performance of LLM Agents on Multi-Table Question-Answering Tasks through techniques such as Domain-Specific Information Integration, Demonstration Optimization through Long-Term Memory, Interactive Coding with Execution, and Rubber Duck Debugging via Error Tracing.