ERL: Teaching LLM Agents to Learn from a Single Attempt Without Fine-Tuning

1 Introduction
1.1 💡 TL;DR
This paper introduces a lightweight framework called ERL (Experiential Reflective Learning). It enables LLM Agents to reflect on single-task execution trajectories to extract highly condensed “Heuristics”—all without “fine-tuning model parameters” or “repeated trial-and-error.” When facing new tasks, the system intelligently retrieves the most relevant experiences and injects them into the prompt. This allows the Agent to truly “learn from its mistakes,” significantly boosting the success rate on the Gaia2 benchmark by 7.8%.
1.2 🎯 Core Value
In the current development of LLM Agents, we face a major bottleneck: Agents don’t learn from their lessons. When we deploy Agents in the real world (such as customer service or personal assistants), they act as if they have “amnesia,” starting from scratch every time they encounter a new task. The traditional solution is “Fine-tuning,” but this is impractical for closed-source models (like GPT-4) and comes with extremely high costs.
The core value of this paper lies in creating a “plug-and-play mistake log and secret manual” for Agents. We don’t need to alter the Agent’s underlying reasoning logic (such as the standard ReAct loop). Instead, through an elegant dual-module design of reflection and retrieval, we distill long and hard-to-transfer “Raw Trajectories” into highly generalizable “Trigger-Action Guidelines.”
2 Problem Definition
2.1 Pain Point Analysis: Why Can’t Existing Agents “Learn Lessons”?
Before diving into the methodology of this paper, let’s look at the current dilemmas in the field of LLM Agents. We know that modern general-purpose Agents (like ReAct Agents based on GPT-4) possess strong reasoning capabilities. However, when deployed in “new environments” containing domain-specific rules or unfamiliar tools, their performance often falls short.
The most fatal issue is: they start “from scratch” every time they face a new task. They cannot learn from past interaction experiences, leading to the same mistakes (e.g., incorrect tool parameter input) being repeated over and over.
To solve this “amnesia,” the academic community has proposed several solutions, but all have difficult-to-overcome flaws:
Fine-Tuning: The most traditional approach, but it is extremely resource-intensive, cannot be applied to API-based closed-source models, and does not support dynamic “Continuous Learning.”
Trajectory-based Learning (e.g., ExpeL or AutoGuide):
- Unrealistic Assumptions: These SOTA methods rely heavily on “repeated trial-and-error.” They require the Agent to attempt the same task multiple times and compare “successful” vs. “failed” trajectories to extract experience. However, in real-world scenarios (e.g., sending emails for a boss, modifying a database), tasks are often irreversible; we only get a “Single-attempt” chance.
- Scalability Issues: Using ExpeL as an example, it “blindly stuffs” all extracted experiences into the prompt of every new task. As the experience pool grows, the Context Window quickly fills up, and irrelevant information begins to interfere with the Agent’s judgment.
- Execution Overhead: AutoGuide goes to the other extreme by dynamically retrieving experiences at every single turn of the Agent’s execution. This not only incurs massive API call costs but also causes unbearable system latency.
Raw Trajectory Few-shotting: The most intuitive idea is to directly feed the full dialogue history of past failures to the Agent. However, experiments show this doesn’t work because raw trajectories are too long and filled with task-specific details, making it hard for the Agent to extract “abstract principles” applicable to new tasks.
2.2 💡 The Solution: Core Insights of ERL
Understanding the pain points above makes it clear why ERL (Experiential Reflective Learning) is so powerful. The insight of this paper is: We don’t need a perfect “success-failure comparison”; we just need a system that can “self-critique.”
ERL breaks the limitation of trial-and-error by proposing a mechanism that extracts experience from only a single attempt. It compresses long raw trajectories into highly abstract “Heuristics” and stores them in a persistent experience pool. When facing a new task, it adopts a “pre-exam review” strategy—precisely retrieving the Top- most relevant rules to inject into the context before the task begins, achieving highly efficient execution with zero interference.
3 Methodology
The ERL framework is an elegant “plug-and-play design.” It does not require any changes to the Agent’s underlying architecture (e.g., it keeps the original ReAct loop). Instead, it completes the system’s “self-evolution” through two independent stages.
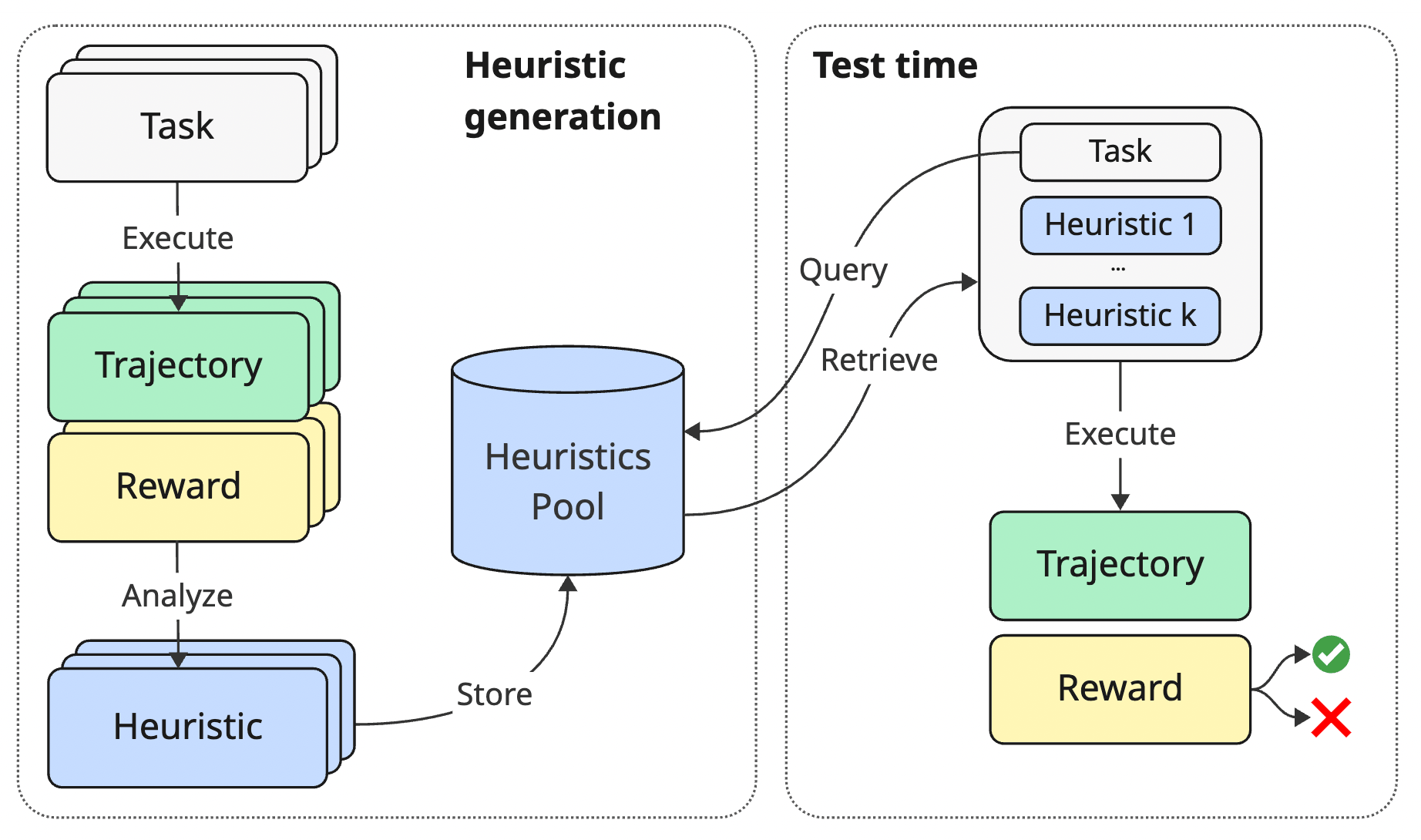
The data flow can be clearly divided into two stages:
3.1 Stage 1: Experience Accumulation and Reflection (Heuristic Generation)
Once the Agent completes a task in the environment (whether it succeeds or fails), this stage is triggered. Think of it as the Agent’s “journaling and review” time after work.
3.1.1 Single-attempt Input
The system collects all information from the single execution just completed and packages it into a context for the LLM acting as the “Reflector”:
- Task: The original task description (e.g., “Please help me cancel tomorrow’s wine tasting”).
- Trajectory: The complete execution trajectory (including reasoning, tools called, and environment feedback).
- Reward: A binary feedback signal indicating if the task was a
SuccessorFailure.
3.1.2 Post-Mortem Analysis and Rule Generation
This is the most brilliant part of ERL—the authors designed a strictly structured prompt that forces the LLM to follow different reflection logics based on “success” or “failure”:
- IF FAILURE: The LLM must first “Pinpoint the Breakpoint” to find where logic failed or a tool was misused. Then, it derives a specific corrective rule to prevent such errors.
- IF SUCCESS: The LLM must identify the “Winning Move,” analyzing which decision made execution efficient and sublimating it into a best practice.
3.1.3 The Power of Structured Output: Trigger -> Action
Regardless of success or failure, the “Heuristic” output by the LLM must follow a specific format. This includes an analysis and a Learned Guideline, which must be conditional:
- Trigger: For example, “When I need to send an email and the input only contains participant names…”
- Action: For example, “I must first call the Contacts tool to retrieve addresses and verify the format before calling the Emails tool.”
Once generated, this rule is stored in a persistent “Heuristics Pool (denoted as )”.
In our discussion, we found that transforming experience into a Trigger -> Action format not only achieves “information compression” (saving massive amounts of tokens) but, more importantly, aligns perfectly with the Agent’s ReAct (Reasoning and Acting) execution framework!
In the future, when the Agent encounters a situation matching the Trigger during the Thought phase, it’s like triggering muscle memory. It automatically recalls the Action SOP, cleverly avoiding traps and truly turning “cases” into “generalizable rules.”
3.2 Stage 2: Retrieval-Augmented Execution
When the Agent faces a completely new and unknown task, the ERL system initiates the second stage, which we call “pre-exam review.”
3.2.1 Task Decomposition and Intelligent LLM Retrieval
How do we pick the most suitable experience from a massive experience pool ? The authors found in experiments that simply using Embeddings (semantic vectors) for literal similarity matching didn’t work well. Therefore, ERL employs LLM-based Retrieval.
The data flow works as follows:
- Task Decomposition: The LLM Retriever first analyzes the new task and breaks it down into potential “sub-tasks” and “action steps” (an implicit Chain-of-Thought that helps more accurately match specific underlying experiences).
- Multi-dimensional Scoring: Next, the LLM scores rules in the experience pool from 0 to 100. Scoring is based not only on “Similarity” but also strictly includes “Diversity” (avoiding rules that all talk about the same tool) and “Informativeness” (whether the rule is specific and actionable).
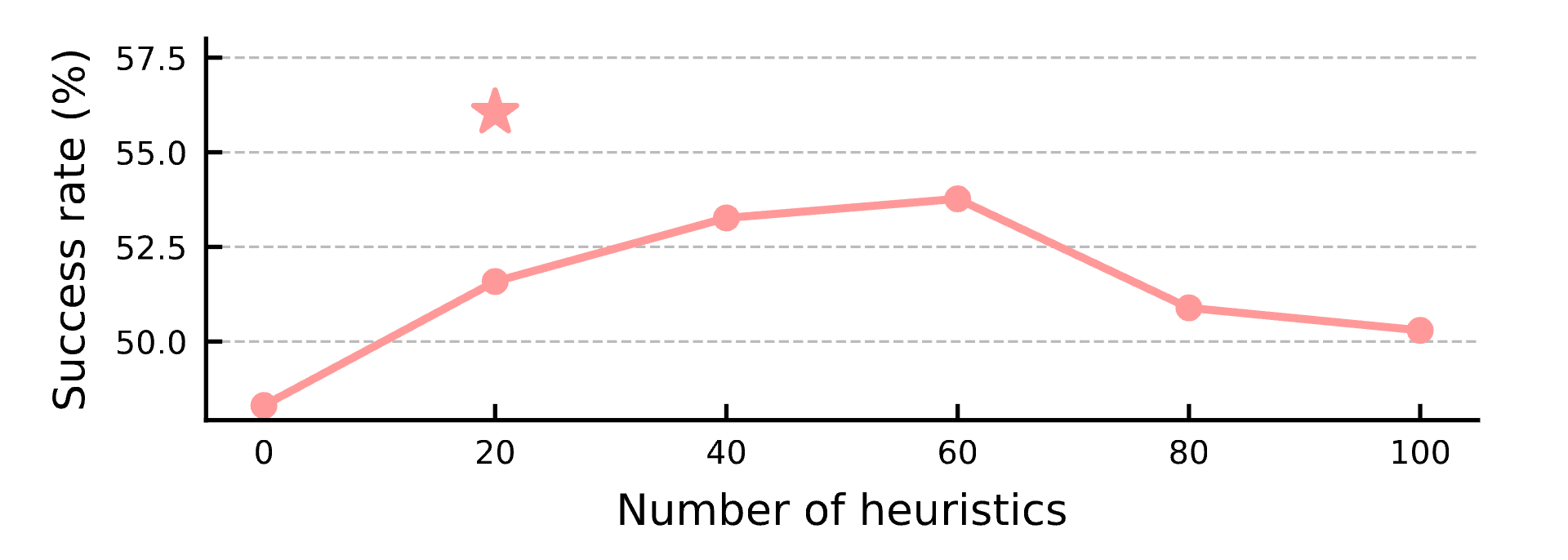
- Precise Extraction: Finally, the LLM outputs the IDs and selection reasons for the Top- rules (experiments prove works best).
3.2.2 Context Injection and Zero-Interference Execution
After selecting the Top- heuristics, the system directly inserts them into the Agent’s System Prompt. Then, the Agent officially enters the environment and begins its standard ReAct execution loop.
This is a very clever architectural choice: because the “secret manual” is given to the Agent before the task starts, we don’t need to consume computational resources to dynamically retrieve experiences at every step (turn), unlike AutoGuide. This perfectly achieves what we call Zero-overhead during execution.
4 Experimental Results
To verify ERL’s real-world capabilities, the authors chose the Gaia2 benchmark. This is a highly challenging environment containing 12 applications and 101 tools, where tasks usually require long-path reasoning.
4.1 Core Results: Significantly Outperforming SOTA Methods
ERL demonstrated strong competitiveness in Gaia2’s “Search” and “Execution” tasks.
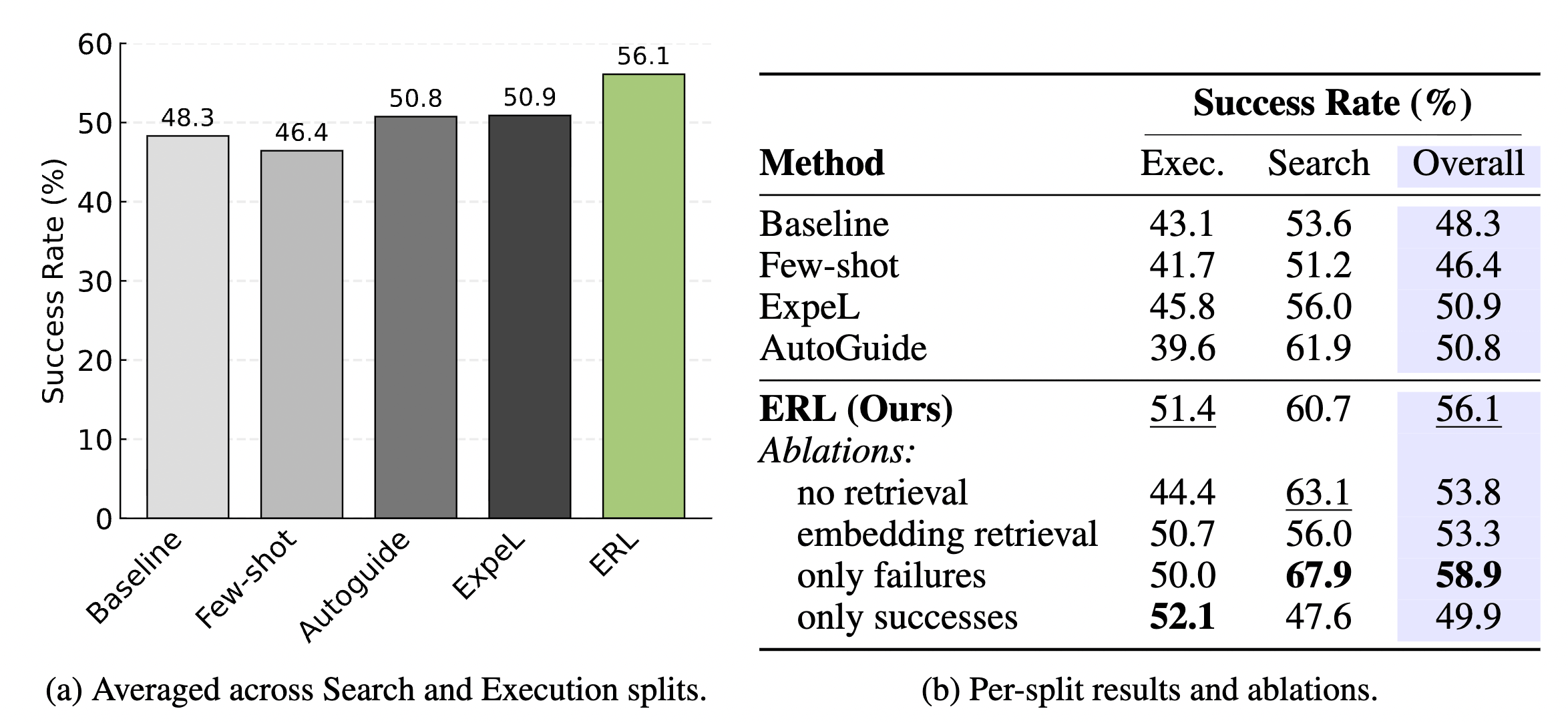
Why did ERL win?
- Reliability: As mentioned in our discussion, ERL not only increased the success rate but also significantly improved (meaning the task was completed successfully three times in a row). This indicates the Agent is no longer “getting lucky” but has truly mastered a stable operational SOP.
- Generalization: Compared to feeding raw trajectories (Few-shot), the Heuristics provided by ERL filtered out unnecessary distractions, allowing the Agent to focus more on the underlying logic.
4.2 Ablation Study: Necessity of Modules
Through a series of “decomposition” experiments, the authors proved that every part of ERL’s design is essential.
4.2.1 Heuristics vs. Raw Trajectories
This might be the experiment we care about most. What if we just show the Agent past raw dialogues (Raw Trajectories)?
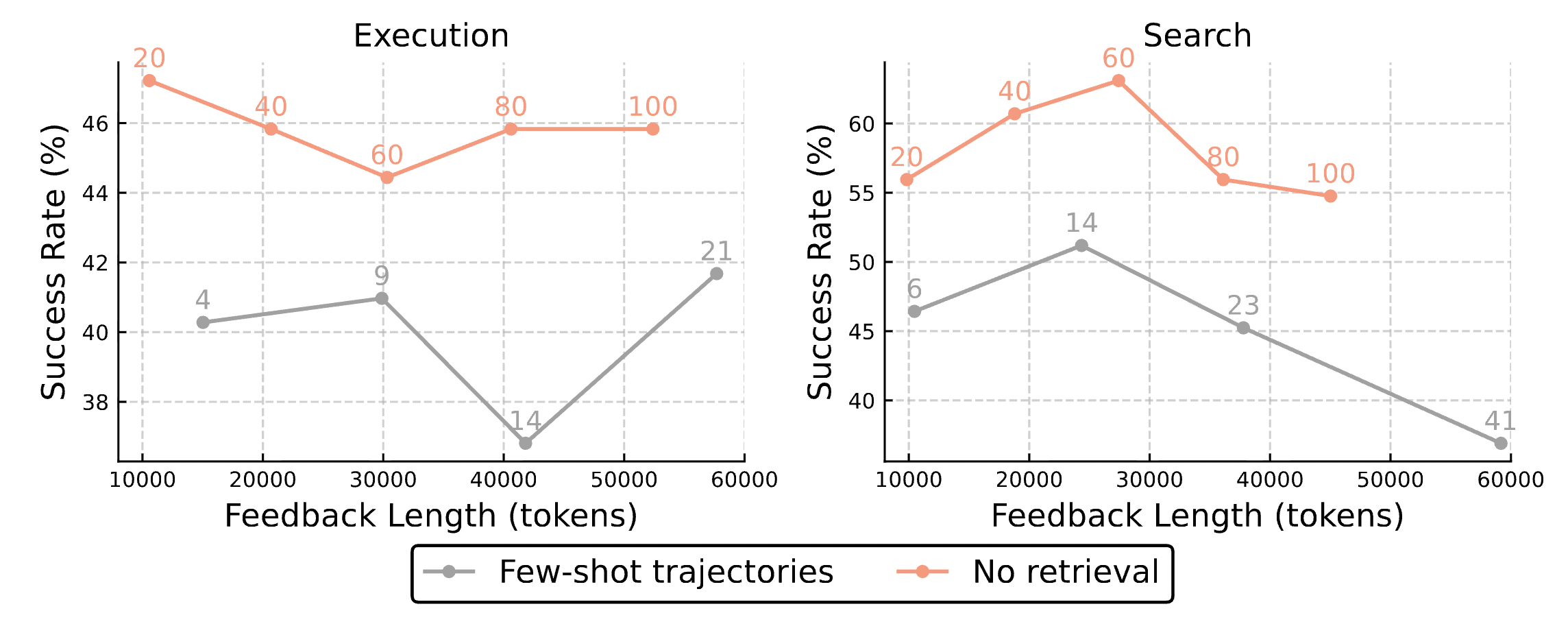
4.2.2 Importance of Retrieval Quality
What if we don’t use expensive LLMs for retrieval and just pick rules randomly?
5 Conclusion
This paper addresses the pain points of LLM Agents “lacking continuous learning capabilities” and “relying on repeated trial-and-error” by proposing the ERL (Experiential Reflective Learning) framework. It sits alongside other memory-driven, fine-tuning-free approaches such as Dynamic Cheatsheet and MemRL, but distinguishes itself by extracting structured Trigger-Action rules from a single execution attempt rather than an accumulated scratchpad or a learned utility score.
Through self-reflection after a single execution, experiences are transformed into structured Trigger-Action rules. During execution, intelligent LLM retrieval is used to inject the 20 most relevant rules into the context. Ultimately, it achieved performance and stability surpassing SOTA methods on the Gaia2 benchmark.
Despite ERL’s excellent performance, we must point out its limitations:
- Scalability and Cost: While the current retrieval mechanism (Full-context LLM ranking) is precise, its token cost and latency will become unacceptable when facing thousands of experiences. This will require optimization through “Two-stage Retrieval” in the future.
- Conflict Resolution: If the experience pool contains two contradictory rules (e.g., conflicting rules from different universes), the system does not yet have a clear arbitration mechanism.
- Automated Maintenance: As experiences accumulate, how to automatically clean up outdated or incorrect rules (Memory Consolidation) is also a direction worth exploring.