GAIA: A Benchmark for General AI Assistants

1 Introduction
In a previous article on ChatEval, I introduced the concept of LLM Agents and how a multi-agent framework can be used to have multiple LLM Agents debate and evaluate the outputs of other LLMs.
However, is there a benchmark to measure the capabilities of a single agent?
Today, I want to share a paper from ICLR 2024, presented as a poster, titled GAIA: A Benchmark for General AI Assistants. This paper proposes a benchmark specifically designed to measure the capabilities of a General AI Assistant! The reason I’m excited to share this paper is not just because it’s interesting, but also because one of its authors is none other than Yann LeCun! Anyone in the AI field has heard of Yann LeCun, who recently had a major debate with Elon Musk on X…

2 The Problem GAIA Benchmark Aims to Solve
With so many benchmarks already available to evaluate LLM Agents, why do we need another one like GAIA? What makes it different from the benchmarks we’ve been using? For instance, when Meta announced Llama 3, they used common benchmarks like MMLU, HumanEval, and GSM-8K to measure its LLM’s performance:
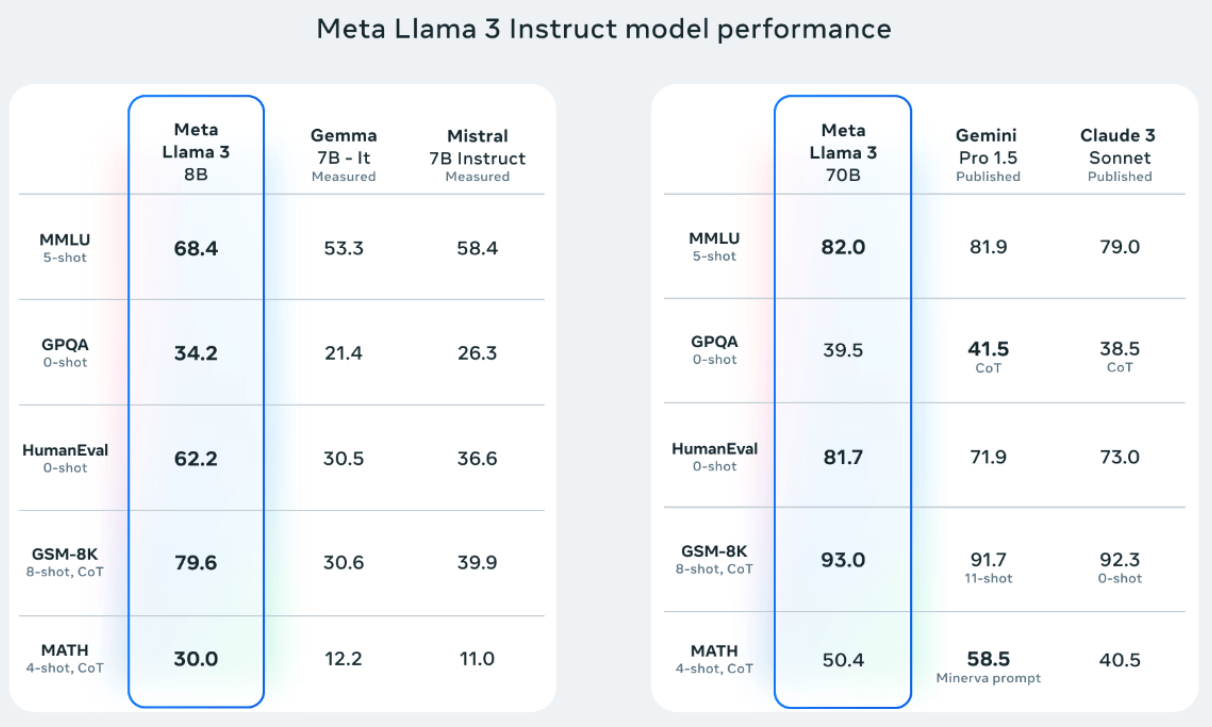
The problem GAIA aims to solve is the belief that while these existing benchmarks can measure an LLM’s knowledge (or how “smart” it is), they don’t fully align with the capabilities of a General AI Assistant. For example, here are two samples from the MMLU benchmark and one from the GSM8K benchmark:
# Question
Paper will burn at approximately what temperature in Fahrenheit?
# Answer
986 degrees
# Question
Which of the following heavenly bodies have never had a spacecraft landed on it?
# Answer
Jupiter# Question
Paddington has 40 more goats than Washington. If Washington has 140 goats, how many goats do they have in total?
# Answer
If Washington has 140 goats, Washington has 140+40 = <<140+40=180>>180 goats. In total, they have 140+180 = <<140+180=320>>320 goats #### 320From these examples, you can probably sense that if an LLM answers these questions well, we might think it’s very smart (it knows everything). But does performing well on these questions mean we are closer to achieving a General AI Assistant? I believe the answer is a firm no.
The GAIA paper also points out that we often evaluate AI models (LLMs) using problems that are difficult even for humans, typically in specialized domains. However, the trend in recent years shows AI models achieving high scores on benchmarks like MMLU and GSM-8K, indicating that AI is becoming increasingly proficient at these specific, difficult tasks.
Furthermore, some current benchmarks for evaluating AI models (LLMs) are of the open-ended generation type. This means the questions don’t have a single standard answer, or the answers require extensive text to describe. This leads to a situation where evaluating a model’s performance on such a benchmark might require other AI models or humans to act as judges, making it impossible to check the output through rule-based methods.
However, it’s also possible that these questions are ones that existing AI models or even humans can’t answer. If that’s the case, how can they be qualified to be judges?
3 Introducing the GAIA Benchmark
Now that we understand the problem GAIA aims to solve, let’s dive into what makes the GAIA benchmark unique. The benchmark consists of 466 question/answer pairs. Each question is text-based and sometimes comes with additional files (like images or CSV files).
The chart below shows the distribution of file types in the GAIA benchmark:
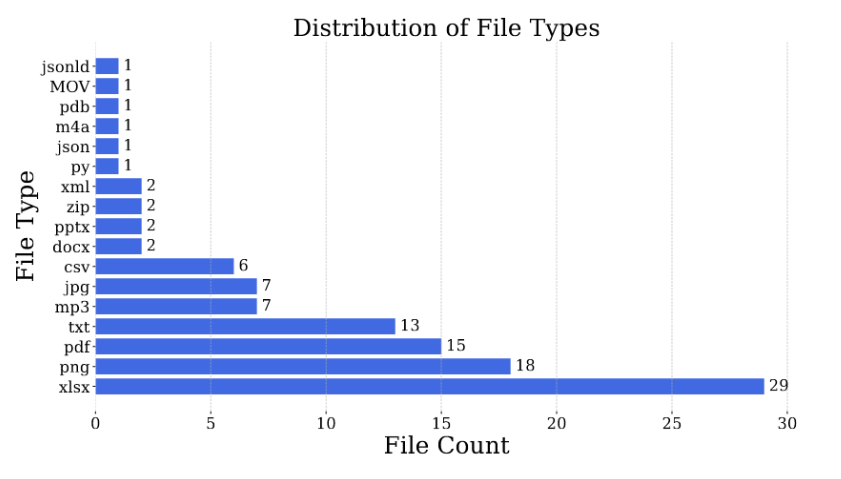
The questions in GAIA can range from common workplace administrative tasks and scientific problems to general knowledge questions. The most important feature of GAIA is that every answer is short, simple, and easily verifiable (to avoid ambiguity), yet arriving at that answer requires a wide range of fundamental skills. Specifically, an answer in GAIA is either a number, a string, or a list of strings, and there is only one correct answer.
Additionally, we can use a system prompt to tell the agent what format the answer should be in, which is very helpful for automated evaluation. For an AI model to score high on the GAIA benchmark, it must possess several capabilities:
- Advanced Reasoning
- Multi-Modality Understanding
- Coding Capability
- Tool Use
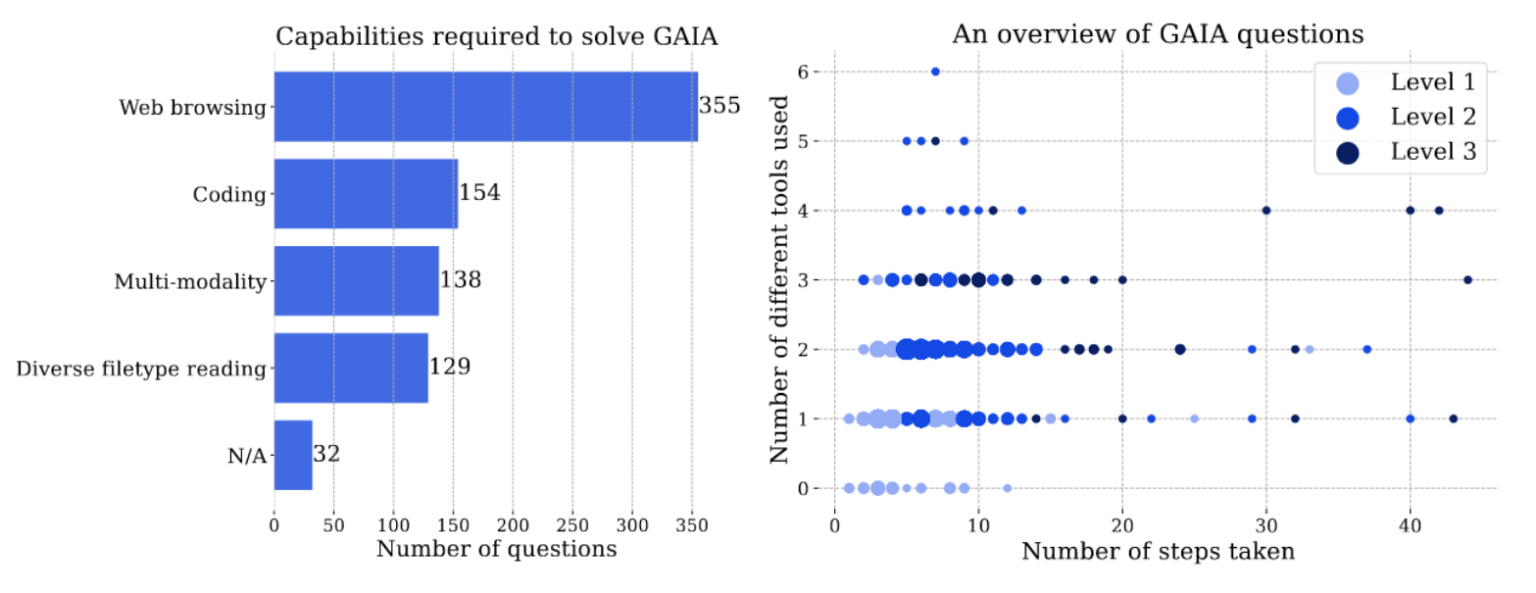
The figure below (left) shows the number of questions corresponding to each skill. It’s clear that most questions cannot be answered directly from the AI model’s existing knowledge; the model must learn to use web browsing to find the correct answer. The figure on the right shows how many different tools and steps are needed to answer questions of varying difficulty.
Using the GAIA benchmark is also quite straightforward: you just use the official system prompt to perform zero-shot inference on the AI model. Below are the official system prompt and a sample question:


Finally, the authors used the GAIA benchmark to evaluate the performance of several SOTA LLMs and humans:
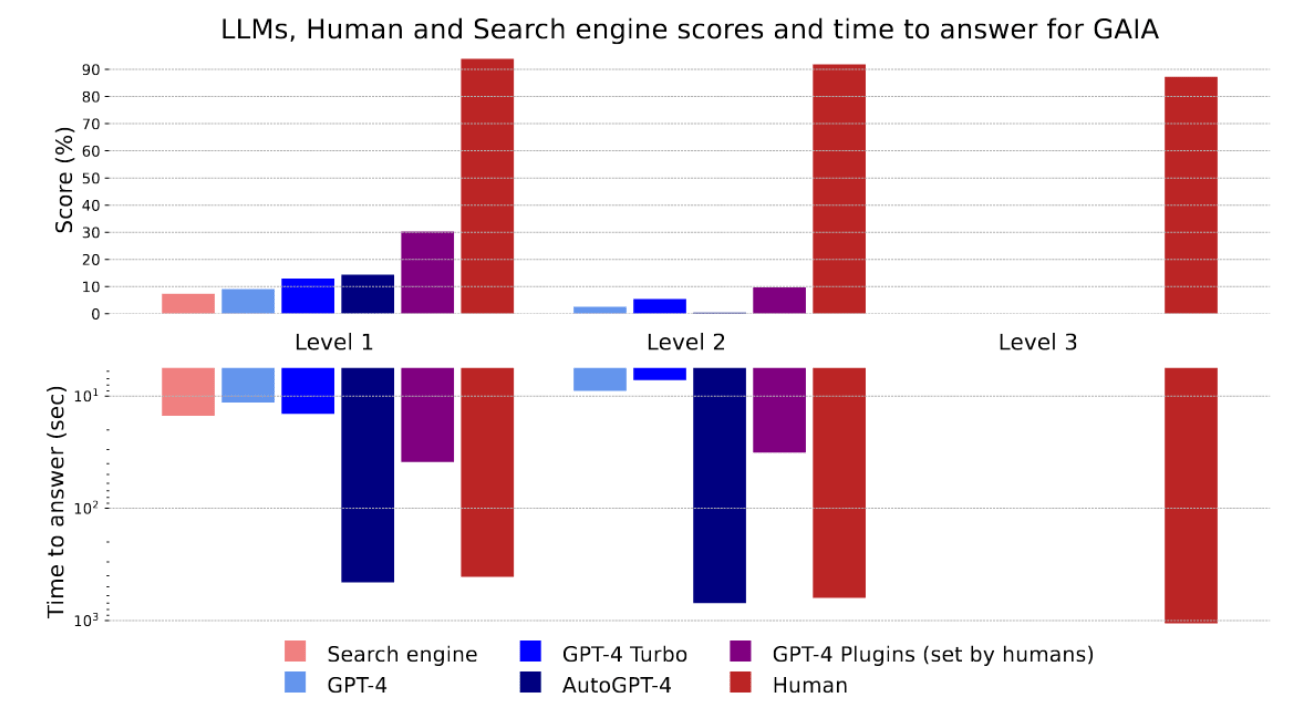
We can see that even the powerful GPT-4 Turbo model only scored between 10-20 on Level 1 questions, and with human assistance, it barely reached 30. On Level 2 and 3 questions, these SOTA LLMs performed even worse. But did you notice? For Levels 1, 2, and 3, humans scored around 90%!
I think this is what makes the GAIA benchmark so fascinating—it designs tasks that are simple for humans but difficult for current AI models. It doesn’t just test how much knowledge an AI model has memorized. It goes a step further to measure if the AI model can use tools, understand different data types, possess stronger reasoning abilities, and write simple code for analysis. When an AI model can perform well on the GAIA benchmark, it signifies that it is one step closer to becoming a General AI Assistant.
4 Conclusion
In this article, I shared insights from the ICLR 2024 poster paper, GAIA: A Benchmark for General AI Assistants. My journey with this paper began with “Oh, it’s an ICLR paper” (sounds worth reading), then “Wow, it’s published by Meta” (seems very interesting), and finally, “Yann LeCun is one of the authors!” (then I absolutely must read it!).
This paper proposes a benchmark to more accurately measure whether an AI model possesses the capabilities of a General AI Assistant. It cleverly designs its answers to avoid ambiguity, making it easier for us to evaluate the model’s output using rule-based methods. Lastly, the experiments show that current SOTA AI models still perform poorly on this benchmark, whereas humans perform exceptionally well.