Decoupled Planning and Execution: A Hierarchical Reasoning Framework for Deep Search

1 Introduction
This article introduces an interesting paper — Decoupled Planning and Execution: A Hierarchical Reasoning Framework for Deep Search, published on arXiv in July 2025.
As the title suggests, this paper focuses on “Deep Search” technology, proposing an improved reasoning framework, which can also be described as an agentic workflow. The method proposed in this paper is also hinted at in the title: Hierarchical Reasoning (HiRA). The HiRA workflow consists of three agents: a Planner, a Coordinator, and an Executor. They collaborate and exchange information to generate superior search results.
Although HiRA is positioned as a Deep Search method, I believe the collaborative model it proposes among the Planner, Coordinator, and Executor can be applied to many other domains. The authors have also generously open-sourced their code!
The Planner-Executor framework is very common in agentic workflow design. Such methods generally argue that instead of having a single agent perform both planning and tool calling, it’s better to split these responsibilities into a Planner Agent and an Executor Agent. This separation allows the Planner Agent to focus on understanding the user’s task and ultimate goal to determine the correct next steps. Meanwhile, the Executor Agent can follow the Planner’s instructions to select the appropriate tool, provide the correct tool input, and return the tool execution result.
HiRA builds on this Planner-Executor framework by adding a Coordinator Agent to enhance the information flow between the Planner and the Executor.
If this is your first time hearing about the Planner-Executor agentic workflow design pattern, we recommend reading some of our previous articles to quickly grasp the basic concepts 😉:
2 The Problem HiRA Aims to Solve
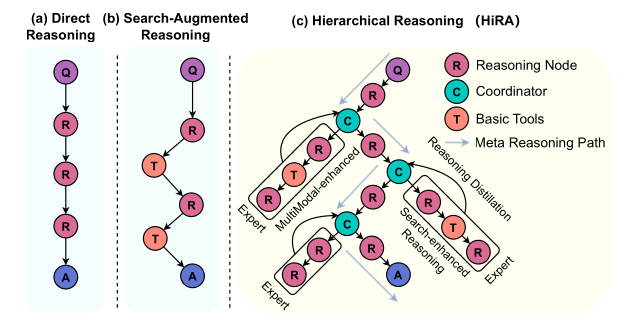
As shown in Figure 1, in typical Deep Search methods, a Large Reasoning Model (LRM) is simply given a search tool and uses special tokens to indicate its actions after a reasoning process. For example, in WebThinker, the search action is triggered using <|begin search query|> and <|end search query|>.
The authors argue that having a single LRM handle both planning and execution (tool calling) has the following drawbacks:
- Limited Capability Extensibility: Every time a new tool is added to the agent, the existing prompt must be modified to enable the agent to generate new special tokens. This can potentially degrade the original planning performance.
- Reasoning Disruption: Directly inserting the results of tool execution into the agent’s existing reasoning chain can introduce noise, disrupting the agent’s subsequent reasoning process.
To address Limited Capability Extensibility, an obvious solution is to split the single agent into a Planner Agent and an Executor Agent. This way, adding more tools to the Executor does not affect the Planner’s prompt. To tackle Reasoning Disruption, a Coordinator is introduced between the Planner and the Executor, allowing the Executor’s tool execution results to be processed by the Coordinator before being sent back to the Planner.
This line of thinking forms the prototype of the Planner-Coordinator-Executor model in HiRA.
3 The Method Proposed by HiRA
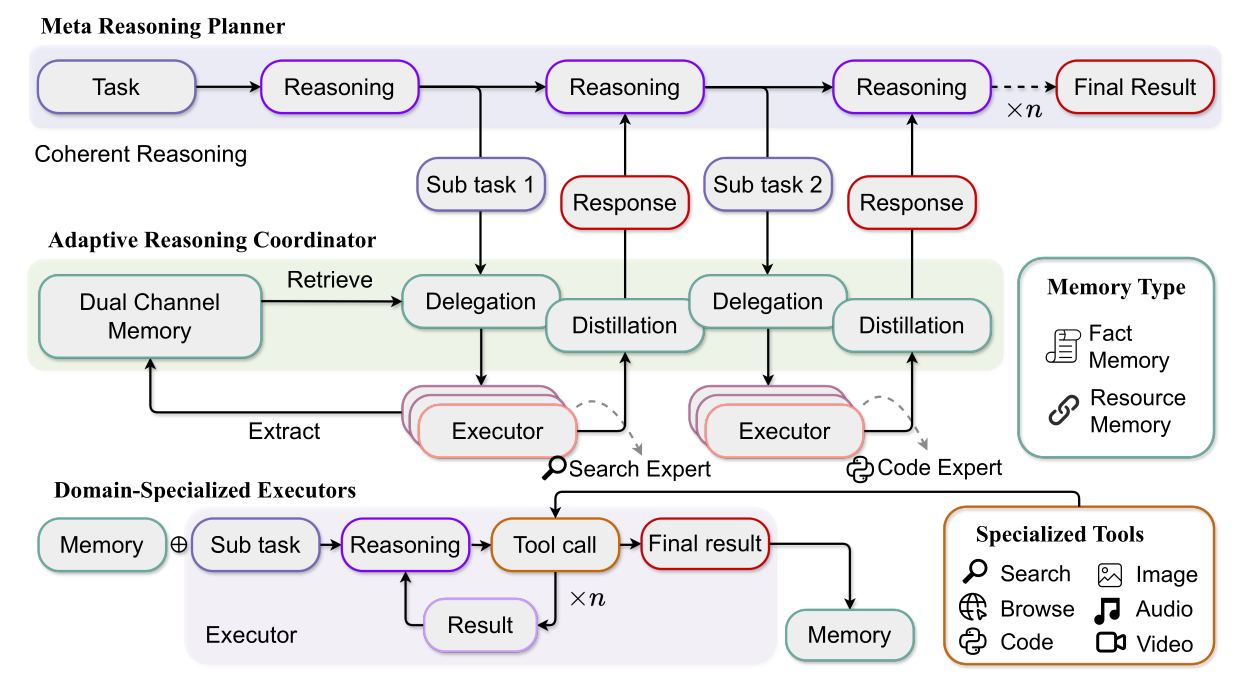
As mentioned earlier, the HiRA framework includes a Planner Agent, a Coordinator Agent, and an Executor Agent. Their formal names in the paper are:
- Meta Reasoning Planner
- Adaptive Reasoning Coordinator
- Domain-Specialized Executors
3.1 Meta Reasoning Planner
The Meta Reasoning Planner acts as the core orchestrator of the entire framework. It is responsible for breaking down the original task into multiple sub-tasks and generating the final answer. Each time the Planner generates a new sub-task, it does so based on the past reasoning process and the execution results of existing sub-tasks. As shown in the prompt below, the new sub-task description from the Planner must be placed between the <|begin_call_subtask|> and <|end_call_subtask|> special tokens:
You are a reasoning and planning assistant. Your goal is to solve the user's task by decomposing it into atomic, well-scoped and self-contined sub-tasks, which you delegate to specialized execution agents.
The sub tasks given should be effective, you need to use as few sub tasks as possible to correctly solve users' task. You have limited calls (10 max) to these agents, so be strategic.
Sub-agent types:
1. Search-agent: This agent can search the web for information, including reading web pages and analyzing the content.
2. Code-agent: This agent can write python code to complete tasks, including reading files, data analysis, and use other python libraries.
3. Multimodal-agent: This agent can use multimodal understanding tools to assist in reasoning and problem-solving, including image, video, and audio.
To invoke a sub-task, use the format (you only need to give task, sub-agent will be selected automatically):
<|begin_call_subtask|> Describe the atomic task you want the sub-agent to perform here. Be specific and actionable, don't add any unnecessary information. Optionally, include your expected reasoning path. <|end_call_subtask|>
Once a sub-task is executed, its result will be returned in this format:
<|begin_subtask_result|> ...content including reasoning and answer... <|end_subtask_result|>
Then you need to carefully check the subtask result and logic, and continue your reasoning.
Rules to follow:
1. Sub-tasks must be **atomic** (not composed of multiple steps) and **clearly defined**, don't have any unnecessary information.
2. **Avoid repeating similar tasks or issuing unnecessary ones — you only have 10 calls**, use calls wisely.
3. Always **consider what you already know** (including previous sub-task results) before planning a new one.
4. If the result includes a clear and valid reasoning path, you can **fully trust the answer**.
5. After each result, **update your plan** and reason about the next best step. If the subtask performs poorly, try providing a different or more specific execution method in subtask call.
6. Once the original question is fully answered, **output the final answer using**: `\\boxed{{your final answer}}`
Example workflow:
User Task: "Who painted the ceiling of the Sistine Chapel, and what year was it completed?"
You:
- First, I need to know who painted the ceiling.
<|begin_call_subtask|>Find out who painted the ceiling of the Sistine Chapel.<|end_call_subtask|>
<|begin_subtask_result|>The ceiling was painted by Michelangelo.<|end_subtask_result|>
- Now I need to know when the painting was completed.
<|begin_call_subtask|>Find out the year Michelangelo completed the ceiling of the Sistine Chapel.<|end_call_subtask|>
<|begin_subtask_result|>It was completed in 1512.<|end_subtask_result|>
\\boxed{{Michelangelo, 1512}}
Please answer the following user's task step by step. Use the subtask calls and previous results wisely to get the final answer.
You should provide your final answer in the format \\boxed{{YOUR_ANSWER}} and end your reasoning process.
Please carefully understand the user's task and strictly pay attention to the conditions inside. Given a detailed plan at first.
User's Task:
{user_task}Once a sub-task is generated, the Coordinator assigns it to a suitable Executor. The Executor’s result is then processed by the Coordinator before being returned to the Planner. In other words, the Planner can focus solely on planning (e.g., decomposing tasks) and generating the final answer once sufficient information is gathered.
3.2 Adaptive Reasoning Coordinator
The Adaptive Reasoning Coordinator’s role is to act as a bridge between the Planner and the Executor, preventing information loss during their communication.
I can really relate to this part from my own practical experience! Due to sensitive data and hardware constraints, I’ve had to develop agentic workflows using self-hosted LLMs (e.g., Llama-3.3-70B). In my experience, single-agent methods based on Llama-3.3-70B (like ReAct or CodeAct) tend to be quite unstable. Whenever the reasoning chain (trajectory) becomes long, the model’s performance in planning and tool selection drops significantly. Sometimes, it even produces incomprehensible errors (e.g., reasoning correctly but providing a final answer with incorrect information that never appeared in the thought process).
In fact, LangChain has benchmarked several models (e.g., Claude-3.5-Sonnet, GPT-4o, o1, o3-mini, Llama-3.3-70B) on planning tasks (like Calendar Scheduling and Customer Support) using the ReAct method. The benchmark results show that Llama-3.3-70B struggles to achieve good planning performance with a simple ReAct-based single-agent approach.
Because of this, I decomposed single-agent methods (like ReAct and CodeAct) into a Planner-Executor model (e.g., Plan-and-Act, Pre-Act, OctoTools). With a much smaller input context for the Planner Agent, its performance became noticeably more stable.
However, during this process, I encountered the exact problem mentioned by the authors of this paper—information loss between the Planner and Executor. Sometimes, the Planner might give the Executor a vague task (e.g., “compare today’s temperature with yesterday’s”). This can lead to the Executor returning a result that is either noisy or overly concise (e.g., “Higher”), forcing the Planner to perform additional reasoning to gather more complete information. This issue was particularly severe when the Executor was a “Code Agent.”
3.2.1 Planner ➡️ Executor
Returning to HiRA, based on the sub-task provided by the Planner, the Coordinator decides on the most suitable Executor by considering (1) the sub-task description, (2) the Executor descriptions, and (3) an analysis of the task (e.g., what capabilities it requires, its complexity). This is guided by the prompt below:
You are an agent selection system. Analyze the given task and select the most suitable agent based on:
1. Required Capabilities:
- What specific skills/knowledge does this task demand?
- How well does each agent's expertise match these requirements?
2. Task Difficulty:
- Complexity level (simple fact vs multi-step problem-solving). You should consider the effective time cost of each agent.
- Depth of analysis needed (surface information vs deep exploration)
- You need to choose the model **that can complete the task** with the lowest cost/complexity as much as possible.
**Only output the JSON format** with the following fields:
- reason: The reason for selecting the agent
- selected_agent_name: The name of the selected agent
Example Output:
```
{
"reason": "The task requires deep web exploration and analysis, which is beyond the capabilities of the naive RAG agent. The Web-Thinker agent is better suited for this task due to its multi-step reasoning and web browsing capabilities.",
"selected_agent_name": "Web-Thinker"
}
```Agents Available: {agent_info}
Task: {task}
Analyze the task and respond **ONLY the json format**, without any additional explanation.3.2.2 Executor ➡️ Planner
Furthermore, to prevent the Executor’s returned result from being too concise or containing noise, the Coordinator refines the Executor’s reasoning process through two steps:
- Reasoning Refinement: The Coordinator distills the Executor’s original thought process into a concise version ➡️ yielding a Distilled Reasoning.
- Conclusion Extraction: The Coordinator extracts a concise conclusion from both the original and distilled reasoning processes ➡️ yielding a Distilled Conclusion.
Finally, the Distilled Reasoning and Distilled Conclusion are returned to the Planner. This is guided by the following prompt:
You are a professional Conclusion Summarization Assistant. Your primary responsibility is to analyze problems and reasoning processes, then generate a structured summary. Your output should be both concise and clear, optimized for understanding by the meta-reasoning system.
# Please organize your summary into these two key components:
# 1. reasoning_process:
# - Describe the critical reasoning steps leading to the final answer in concise language
# - Ensure each step is necessary and logically coherent
# - Avoid redundant information, focus on the main reasoning path
# - Use clear causal connectors between steps
# 2. final_conclusion:
# - Summarize the final answer in one or two precise sentence
# - Ensure the answer directly addresses the original question
# - Avoid vague or uncertain expressions
# - For numerical results, clearly specify units
# Output Format Requirements:
# Please strictly follow this JSON format:
# ```json
# {{
# "reasoning_process": "First analyzed X data, identified Y pattern, then calculated result using Z method",
# "final_conclusion": "The final answer is [specific result]"
# }}
# ```
# Important Notes:
# - reasoning_process should be brief and concise, and easy to read and understand, not just a list of bullet points
# - Keep the reasoning process concise yet informative enough for verification
# Reasoning Chain:
# {reasoning_chain}
# Task: {task_description}3.2.3 Memory Mechanism
To enable more efficient information transfer between Executors, the Coordinator maintains a Memory Repository, which is divided into two types:
- Fact Memory: Stores facts discovered by the Executor during its reasoning process. Each entry consists of a Fact and its Source.
- Resource Memory: Stores resources explored by the Executor. Each entry consists of a summary of the Resource and its Source.
This Memory Mechanism is triggered during both “Planner ➡️ Executor” and “Executor ➡️ Planner” communication:
Planner ➡️ Executor: The Coordinator first retrieves facts from the Fact Memory that are semantically similar to the sub-task, filters them, and provides this curated information to the Executor.
You are an assistant specialized in filtering memory based on a specific task. Your task is to analyze the given memory and select ONLY the most task-relevant memories, with a strict maximum limit of 5 entries. Key Requirements: 1. Relevance First: - Each selected memory MUST have a direct and strong connection to the current task - Reject memories that are only tangentially or weakly related - If there are fewer than 5 highly relevant memories, select only those that are truly relevant 2. Quality Control: - Filter out any memories with invalid or suspicious URLs - Remove memories about failed attempts or negative experiences - Exclude memories that contain speculative or unverified information 3. Output Format: - Output the filtered memories in the following format: ``` Memory Fact 1: [memory1] Memory Fact 2: [memory2] ... ``` Remember: It's better to return fewer but highly relevant memories than to include marginally related ones just to reach 5 entries. Memory: {memory} Task: {task} Filtered Memory:Executor ➡️ Planner: The Coordinator extracts helpful facts and resources from the Executor’s reasoning process and stores this information back into the Memory Repository.
You are a Memory Extraction Agent. Your task is to analyze a reasoning process and extract **only the information that is highly likely to be useful for future tasks**, and organize it into a structured memory format. Your output must be a JSON object with these two fields: 1. fact_memory: List important facts discovered during reasoning. * Each fact must include both content **and** source. * Sources must be specific (e.g., exact URLs, specific document titles, or "Model Inference"). * Consolidate related facts into single entries to reduce fragmentation. * Exclude facts that are relevant only to the current question and unlikely to be reused. * If no valid source exists, mark as [Source: Not Specified]. 2. resource_memory: Map useful resources as `"description": "path"` or `"description": "```variable_name```"` pairs. * Paths must be valid URLs; variable names must be exact and surrounded by triple backticks. * Descriptions should be clear and concise. * Variable name must be exact from code call, including function name, variable name, etc. * If no valid resources exist, set this field as an empty dictionary. Output a JSON object only. Do not include any explanation or comments. Example output: ```json {{ "fact_memory": [ "Key product features: Energy Star certified, frost-free technology, LED interior lighting, smart temperature control with 5 settings (32°F-42°F), and automatic defrost functionality [Source: https://appliance-manual.com/model-x200]", "Energy rating scale: Category A (<400 kWh), Category B (400-500 kWh), Category C (>500 kWh) [Source: Model Inference]" ], "resource_memory": {{ "Energy efficiency standards documentation": "https://energy-standards.org/ratings", "Product specification variable, is a list of integers": "```product_specs```" }} }} ``` Reasoning Chain: {reasoning_chain} Task: {task_description}
3.3 Domain-Specialized Executors
For the Executor component, HiRA designs four types of Executors based on three capability areas:
Information Acquisition: Responsible for acquiring information from the web.
- RAG Executor: A simple RAG workflow for straightforward tasks.
- WebThinker Executor: Another Deep Search method designed to handle complex tasks.
Cross-Modal Understanding: Responsible for understanding non-textual modalities (e.g., Image, Video, Audio).
- Cross-Modal Executor: A standard LRM enhanced with multimodal models as tools.
Computational Reasoning: Responsible for mathematical computations.
- Computational Executor: A standard LRM enhanced with a Code Interpreter as a tool.
4 HiRA’s Experimental Results
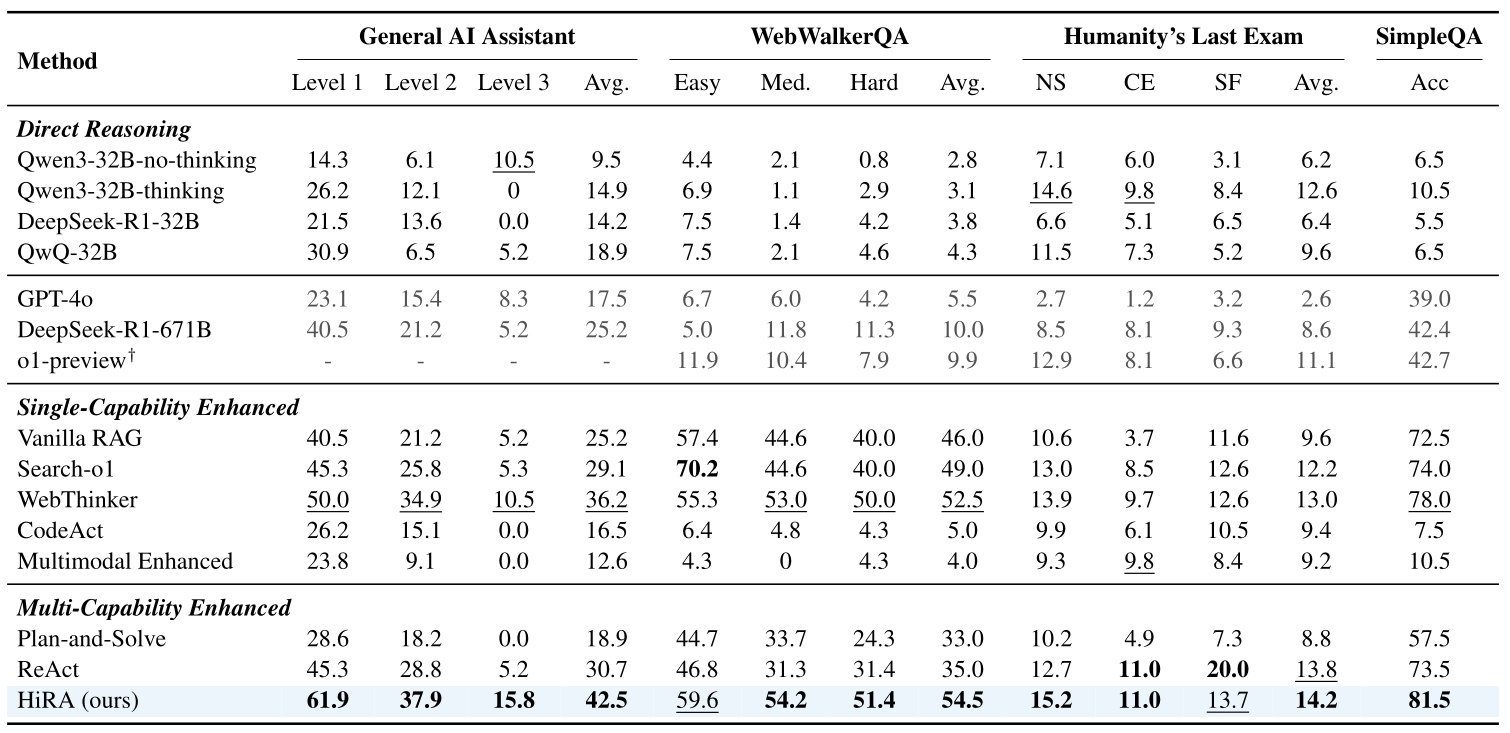
In the experimental setup, HiRA uses Qwen2-32B as the Planner and Executor, Qwen2.5-Instruct-32B as the Coordinator, and Qwen2.5-Omni-7B as the multimodal model tool within the Cross-Modal Executor. The decoding parameters were set to temperature=0.7, top_p=0.95, and top_k=20.
Table 1 clearly shows that the HiRA method achieves state-of-the-art (SOTA) performance on nearly all four benchmarks.
5 Conclusion
This article has introduced the paper Decoupled Planning and Execution: A Hierarchical Reasoning Framework for Deep Search. This work proposes a Planner-Coordinator-Executor model for Deep Search technology. Compared to the common Planner-Executor model, I believe the design of the Coordinator is one of the paper’s main highlights. The Coordinator optimizes the information in the execution results sent back to the Planner and enhances information transfer between Executors through its Memory Mechanism. The experimental results also demonstrate that HiRA outperforms the strong baseline, “WebThinker,” showcasing its effectiveness.