HuatuoGPT-o1: Towards Medical Complex Reasoning with LLMs

1 Preface
How to apply AI techniques (ex. LLM, MLLM) in the Medical Domain has always been one of the directions valued by researchers.
In the previous article, we introduced EHRAgent (EMNLP 2024) and how it integrates LLMs with knowledge from the Medical Domain, utilizing the LLM’s Reasoning and Coding abilities to enable it to perform Table QA tasks based on EHR Databases containing a large number of tables.
In addition, since OpenAI released the o1 model on 2024/9/12, many studies have been proposed hoping to reproduce the capabilities of the o1 model and clarify its training methods.
Combining the above two points, this article aims to share with readers HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs (2024/12) — an o1 model specifically for the Medical Domain. After reading about HuatuoGPT-o1, we will be able to learn how to train an o1 model in the Medical Domain.
However, since OpenAI has not disclosed the training methods for the o1 model, HuatuoGPT-o1 is therefore just an o1-like model. To avoid verbosity, this article will still refer to it as the o1 model. The biggest difference between the so-called o1 model and previous models lies in the Decoding stage, where the o1 model can generate Long Chain-of-Thought Style answers and simultaneously detect and correct its own errors during the reasoning process, demonstrating more powerful reasoning capabilities; for this reason, o1-type models, in addition to being Large Language Models, are often also referred to as Large Reasoning Models.
2 Brief Introduction to HuatuoGPT-o1 Method
The method of HuatuoGPT-o1 can be mainly divided into the following 4 steps:
- Medical Question-Answer Pair Collection
- Long Chain-of-Thought Style Rationale Generation
- Supervised Fine-Tuning
- Reinforcement Learning
Next, let’s understand the meaning of each step in order!
3 HuatuoGPT-o1 #1 Step: Medical Question-Answer Pair Collection
The purpose of this step is to prepare a Verifiable Dataset, meaning that each Data Sample in this Dataset should have a Ground-truth Answer in addition to the Question.
First, the authors first collected 192k “multiple-choice questions” from existing Closed-Set Medical Exam Datasets (MedQA-USMLE, MedMcQA). Then, through the following 3 steps, the better 40k were filtered out from these 192k multiple-choice questions:
- Only select challenging Questions (if the question can be answered by 3 Small LMs, it will be removed)
- Delete Questions with multiple correct answers
- Convert Closed-Set Questions into Open-Ended Questions (transforming the answer from multiple-choice options into discursive short answers)
4 HuatuoGPT-o1 #2 Step: Long Chain-of-Thought Style Rationale Generation
The purpose of this step is to generate the Rationale that the process from Question to Answer goes through for each Data Sample in the Verifiable Dataset.
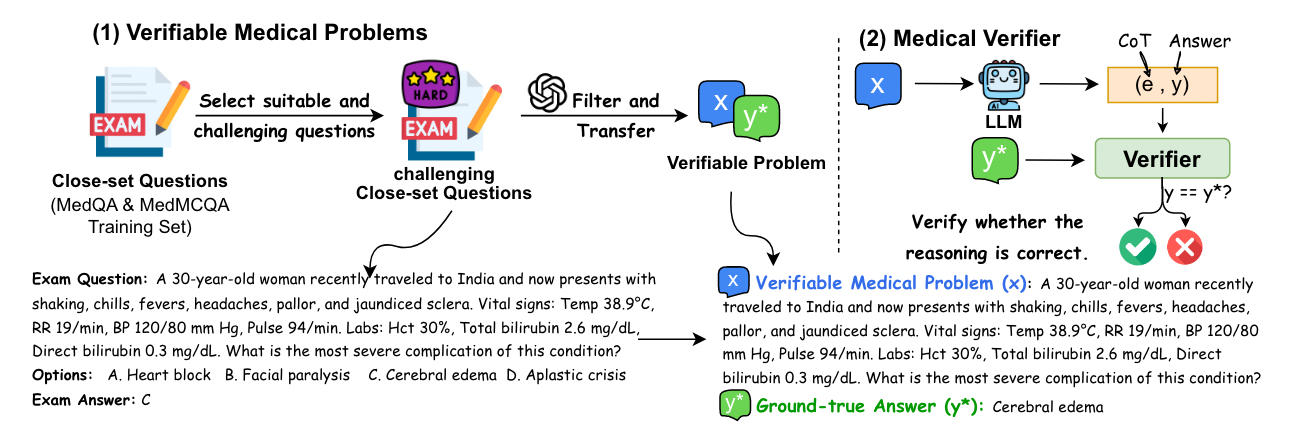
As shown in Figure 1, since each Question has a known Ground-truth Answer, therefore, when we use Prompting to make the LLM generate the Rationale and Answer based on the Question, we can check if the LLM’s Answer matches the Ground-truth Answer to confirm if the Rationale is correct.
When I read this part, I felt that this step could be simpler: simply provide the Question-Answer Pair to the LLM and let the LLM generate the intermediate Rationale itself, or add some Prompting techniques to make the Rationale more detailed.
After reading the entire paper, I realized that although this approach is simple and intuitive, the Rationale generated by this method is actually quite simple. This Rationale seems to represent only 1 Reasoning Path from Question to Answer.
However, if you look closely at the OpenAI o1’s Response, you will find that it spends a lot of time on Thinking. During the Thinking process, o1 explores different Reasoning Paths (Search), and when it finds that the current Reasoning Path is incorrect (Self-Verification), it will try other Reasoning Paths (Backtracking).
In order for the LLM to learn such a complex thinking process, the method for Rationale Generation also needs to have corresponding designs: First, Prompting will be used to make the LLM generate the Initial CoT/Rationale (e0) and Answer (y0) based on the current Question. If the Verifier deems the Answer generated by the LLM incorrect (meaning the current CoT is also incorrect), the LLM will then randomly select a Search Strategy and generate a new CoT and Answer based on the past CoT and Answer. There are four types of Search Strategies:
- Exploring New Paths: Use a completely new CoT (different from existing past CoTs) to deduce the answer
- Backtracking: Select a previous CoT and continue the reasoning process
- Verification: The LLM first assesses where the current CoT and Answer are wrong, then gets a new CoT and Answer
- Correction: The LLM corrects errors in the current CoT, and then gets a new CoT and Answer
For a given Question, the authors set the LLM’s Maximum Search Iteration to 3 times. If the correct answer is still not deduced after 3 Iterations, it will start all over and try again, which means generating a new Initial CoT and Answer. After trying a maximum of 3 times, if the answer is still not found, that Question will be discarded.

Up to this point, for each Question, we already have a Trajectory of CoT and Answer. For example, if the LLM successfully gets the correct answer after 3 Searches, then this Trajectory will include [e0, e1, e2, e3, y3] (only the final correct answer is kept). Next, we need to convert this Trajectory into a Single Complex CoT. The specific Input and Output are shown in the formula below, and the result is as shown in Figure 3 above.
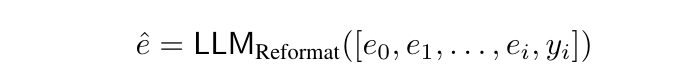
From Fig 3, an interesting observation can be made: after converting this Trajectory into a Complex CoT, the entire thinking process is like that of a human: performing deeper and longer Chain-of-Thought, revising its own results during the process (ex. “But, wait”, “But hold on”), and the transitions in the thinking process are also natural. The Prompt for converting the CoT Trajectory into a Single Complex CoT is shown below:
<Thought Process>
{Thought_Process}
</Thought Process>
<Question>
{Question}
</Question>
The <Thought Process> above reflects the model’s reasoning based on the <Question>. Your task is to rewrite the <Thought Process> to resemble a more human-like, intuitive natural thinking process. The new version should:
1. Be presented as step-by-step reasoning, with each thought on a new line separated by a line break.
2. Avoid structured titles or formatting, focusing on natural transitions. Use casual and natural language for transitions or validations, such as "hmm," "oh," "also," or "wait."
3. Expand the content, making the reasoning richer, more detailed, and logically clear while still being conversational and intuitive.
Return directly the revised natural thinking in JSON format as follows: “‘json {
"NaturalReasoning": "..."
}The Prompt to get the final Response based on the Complex CoT and Question is shown below:
<Internal Thinking>
{Complex_CoT}
</Internal Thinking>
<Question>
{Question}
</Question>
The <Internal Thinking> represents your internal thoughts about the <Question>. Based on this, generate a rich and high-quality final response to the user. If there is a clear answer, provide it first. Ensure your final response closely follows the <Question>. The response style should resemble GPT-4’s style as much as possible. Output only your final response, without any additional content.Finally, the authors extracted 20k Data Samples from the original 40k Data Samples (Question-Answer Pairs) and performed the above process. Therefore, there are currently 20k (Question, Complex Rationale, Response) Tuples, and 20k (Question, Answer) Pairs.
5 HuatuoGPT-o1 #3 Step: Supervised Fine-Tuning
The purpose of this step is to train the LLM to first output the Long Chain-of-Thought Style Rationale, and then get the final Response. Therefore, this stage is mainly based on the 20k (Question, Complex Rationale, Response) Tuples. The input to the LLM is the Question, and the output is Complex Rationale + Response.
6 HuatuoGPT-o1 #4 Step: Reinforcement Learning
To further optimize the model’s reasoning ability, the authors also trained the model using the remaining 20k (Question, Answer) Pairs combined with PPO.
Regarding the calculation of Reward, it is mainly determined by comparing the LLM’s Output and the Ground-truth Answer through a Verifier: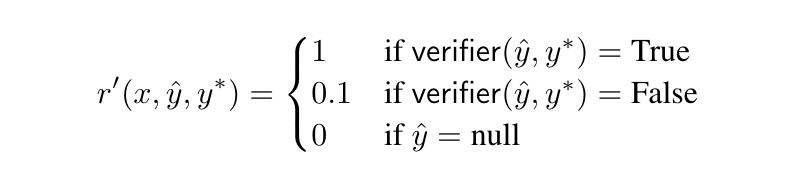
What’s more interesting is that, if the LLM deduces a wrong answer, it will still receive a Positive Reward (just a smaller one), but when the LLM’s Output does not follow the Think-before-Answering behavior pattern, it will not receive any Reward. To ensure stable learning under Sparse Reward, KL Divergence is also added to the final Reward Function to prevent updates from deviating too much from the Initial Policy.
7 Experimental Performance of HuatuoGPT-o1
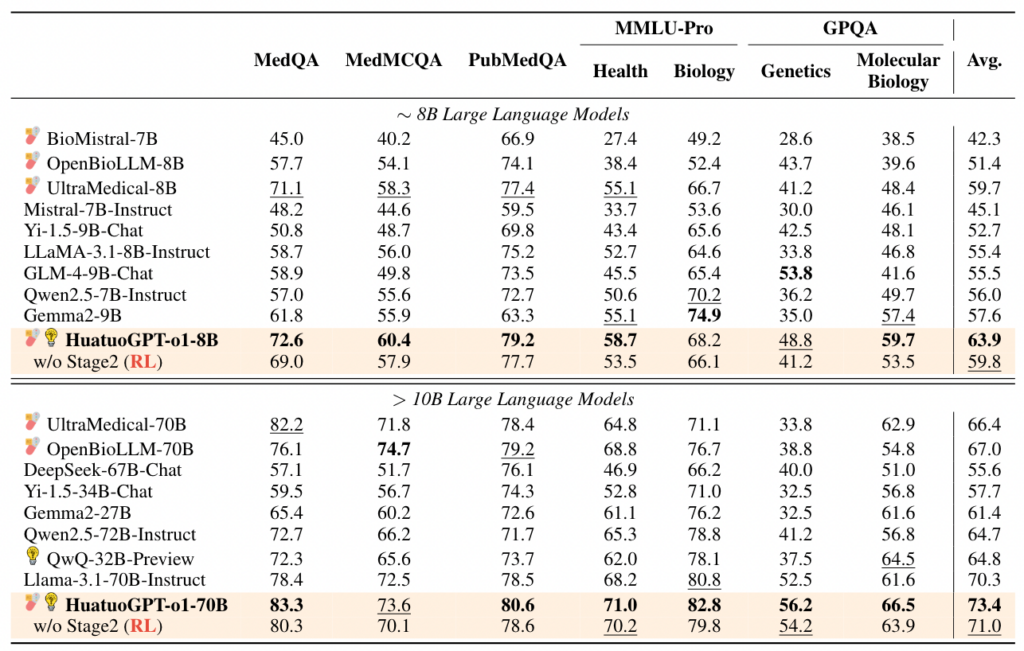
Regarding the details of model training, the authors trained HuatuoGPT-o1-8B and 70B based on Llama-3.1-8B-Instruct and 70B. It is worth noting that the LR for SFT in Stage 1 was set to only 5e-6 and the LR for RL in Stage 2 was set to only 5e-7. From the table below, Table 1, it can also be seen that HuatuoGPT performs better than the Baseline.
8 Conclusion
This article shared HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs (2024/12) — an o1 model specifically for the Medical Domain. After reading about HuatuoGPT-o1, we were able to learn how to train an o1 model in the Medical Domain. I feel that what we learned the most from this paper is how to build a Domain-Specific o1 model from scratch in a relatively low-cost way (compared to OpenAI o1). This includes how to design the overall process (Dataset Collection, Preprocess, Transformation, SFT, RL), and how to write the Prompts (Search Strategy, CoT Trajectory to Complex CoT).