HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face

1 Introduction
Recently (2025/01), the release of the DeepSeek-R1 model (Paper, GitHub) sparked significant discussion in both the AI academic and industry fields. It demonstrated the feasibility of creating a model comparable to OpenAI o1 with such low training costs.
Many AI industry giants (ex. OpenAI, Claude) have even begun speculating that AGI might arrive in the next 3 years!
Exactly when AGI will appear and what capabilities it will possess still feel a bit vague at the moment. Instead, let’s revisit a classic Single Agent paper from the past two years — HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face, to envision what future AGI might look like!
HuggingGPT was jointly published by Zhejiang University and Microsoft Research Asia and was accepted as a NeurIPS 2023 Poster. As of 2025/01/27, HuggingGPT’s Citation count has reached 1029. While not as exaggerated as Attention Is All You Need (150520 Citations) or Chain-of-Thought (9831 Citations), HuggingGPT is considered a Must-Read in the LLM Agent research field!
2 Challenges HuggingGPT Aims to Solve
The challenges addressed in this paper:
- LLMs only accept text as input and output, which limits their ability to handle vision or speech-related tasks.
- Some more complex tasks include many subtasks, requiring the LLM to act as a Coordinator to manage other Models to complete them.
- Although LLMs have Zero-Shot Capabilities in most domains, there is still a gap in capability compared to Domain Experts (ex. Specialized Models).
3 HuggingGPT’s Method Concept
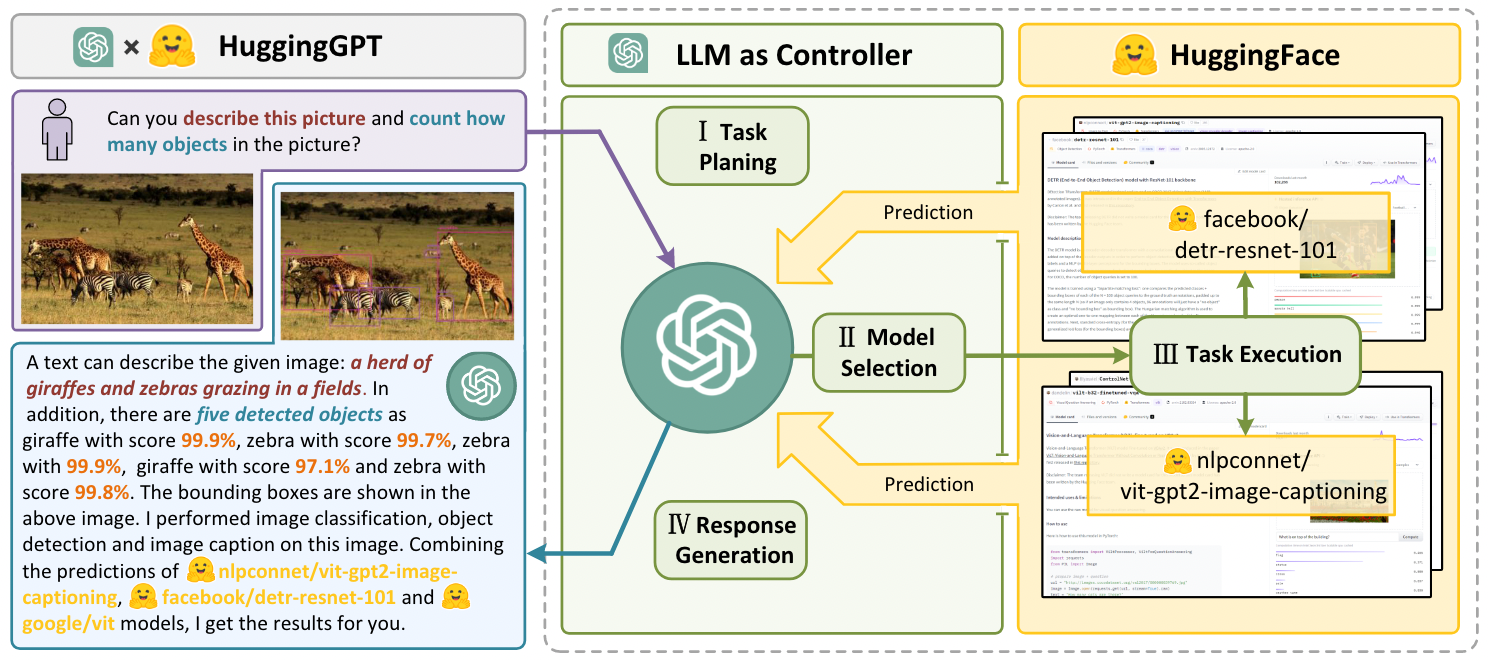
The HuggingGPT method proposed in this paper aims to allow the LLM to act as a Coordinator (Controller), using other external Models/Tools/Domain Experts to complete more complex tasks. HuggingGPT’s concept, as shown in Figure 1, primarily positions the LLM as the Controller responsible for Task Planning, Model Selection, Task Execution, and Response Generation.
4 HuggingGPT #1 Step: Task Planning

The key in the Task Planning stage is to analyze the User’s Query using the LLM, decompose it into multiple Structured Tasks, including their Execution Order or Dependency, and finally output a Task List. To enable the LLM to perform Task Planning effectively, the Prompt Design at this stage is also crucial.
The authors specifically mention using two techniques in the prompt for this stage: Specification-based Instruction and Demonstration-based Parsing.
As shown in the Task Planning stage Prompt in Table 1, the concept of Specification-based Instruction is to tell the LLM how to perform Task Parsing: “Each Task will be represented by a Json, which includes 4 slots: ’task’, ‘id’, ‘dep’, and ‘args’. In addition, the Json will have a ‘dep’ field to represent the Dependency relationship between Tasks.” Demonstration-Based Parsing, on the other hand, leverages the technique of In-Context Learning, allowing the LLM to learn Task Parsing based on Demonstrations.
In the entire Task Planning stage Prompt, the part that I found most interesting is the “Chat Logs” section. It can be observed that the authors included Chat Logs in the Prompt, allowing the LLM to refer to past interactions between the User and the Assistant during Task Planning, instead of just responding directly to the User’s latest Query.
This way, I believe if the LLM’s own capability (intelligence) is good enough, it can make more accurate Task Planning by considering more Context, avoiding errors due to the Ambiguity or Incompleteness in a single User Query.
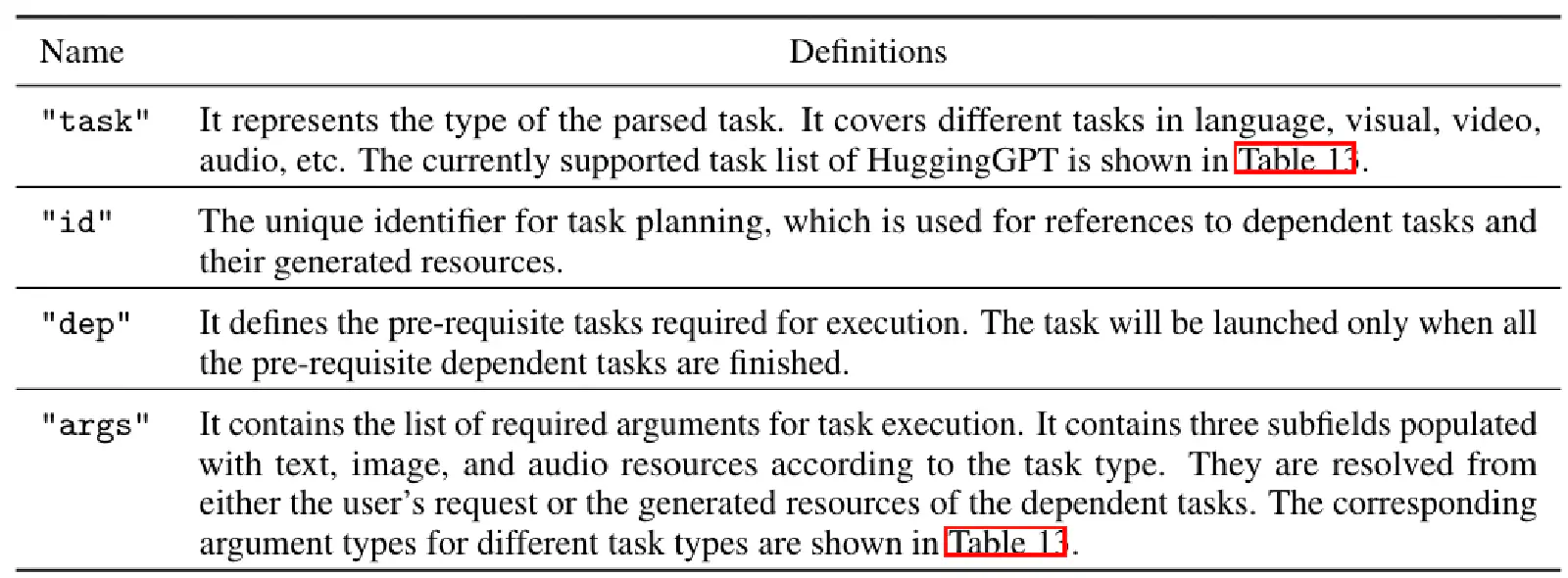
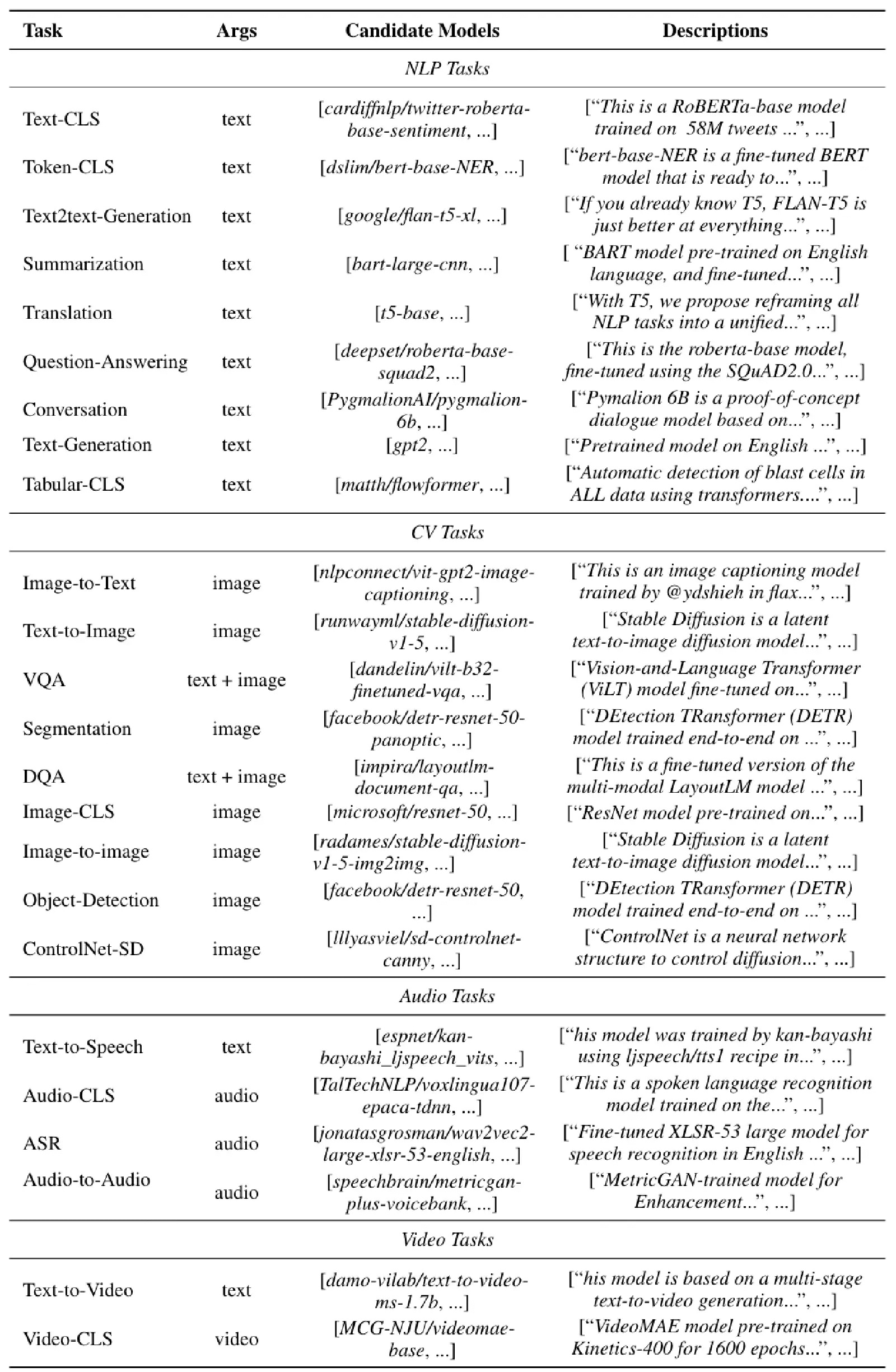
Table 9 also shows the meaning of each Slot; Table 13 presents all Tasks supported by HuggingGPT (“Available Task List”).
5 HuggingGPT #2 Step: Model Selection
The Model Selection stage is to select “one” most suitable Model for each Task in the output of the Task Planning stage (Task List). As seen in Table 1, the Prompt for the Model Selection stage will include Model Candidates. Due to LLM’s Context Limitation, we cannot put all Model Candidates into the Prompt. Therefore, the authors will pre-filter based on the current Task Type and then select the Top-K based on the filtered results to include in the Prompt as Model Candidates.
6 HuggingGPT #3 Step: Task Execution
In the Task Execution stage, the most critical problem is Resource Dependency, which means which Task should be executed before the current Task. To handle this problem, HuggingGPT designates <resource>-task_id (ex. <resource>-0) in the “arg” field of the Task List generated by the LLM during the Task Planning stage, indicating which Task’s output should serve as the Argument for the current Task.
7 HuggingGPT #4 Step: Response Generation
From the Prompt for the Response Generation stage in Table 1, it can be seen that it primarily asks the LLM to generate the final Answer based on information from all previous stages.
I think the way the Prompt is written in this stage (ex. “You must first answer the user’s request in a straightforward manner. Then describe the task process and show your analysis and model inference results to the user in the first person.”) is quite worth learning! In my previous experience developing Chat-like Agents, I deeply realized that the Prompt in the Response Generation stage significantly affects the Response Style, thereby influencing the User’s experience.
8 Experimental Results
In the experimental setup, the authors used 3 LLMs as the Backbone for HuggingGPT: gpt-3.5-turbo, text-davinci-003, gpt-4, and set the Temperature to 0 to ensure stable output from the LLM. Furthermore, to ensure the LLM is better able to output JSON Format, the logit_bias for the tokens “{” and “}” was set to 0.2.
What is logit_bias? Its principle is actually super simple!
During the Decoding stage of an LLM, a specific value can be added to or subtracted from the LLM’s Predicted Logit for each Token (before Softmax) to influence the probability of a Token being Sampled. This specific value can differ for different Tokens and acts on the Logit, hence it is called Logit Bias.
For example, if we don’t want the LLM to generate bad Tokens (ex. stupid), we can set a negative value (ex. -0.5) as the logit_bias for this Token. Then, during the Decoding stage, this Logit Bias (-0.5) will be added to the logit for the “stupid” Token, making its Logit smaller. This also makes the result after Softmax smaller, and the probability of this Token being Sampled becomes smaller.
After understanding HuggingGPT’s method, it is conceivable that the Task Planning stage is the key to whether the entire HuggingGPT method can perform well. Therefore, let’s first look at a practical example of HuggingGPT performing Task Planning:
Figure 1 shows that the User’s Query includes 2 Sub-Tasks (Describe the Image & Object Counting), which the LLM converts into 3 Sub-Tasks (Image Classification, Image Captioning & Object Detection).

Figure 2 also shows that the User’s Query includes 3 Sub-Tasks:
- Detecting the pose of a person in an example image
- Generating a new image based on that pose and specified text
- Creating a speech describing the image
The LLM then converts these into 6 Sub-Tasks:
- Pose detection -> Text-to-image conditional on pose
- Object detection
- Image classification
- Image captioning -> Text-to-speech
After reviewing the practical examples, the authors also used a Quantitative Approach to analyze HuggingGPT’s Task Planning capability.
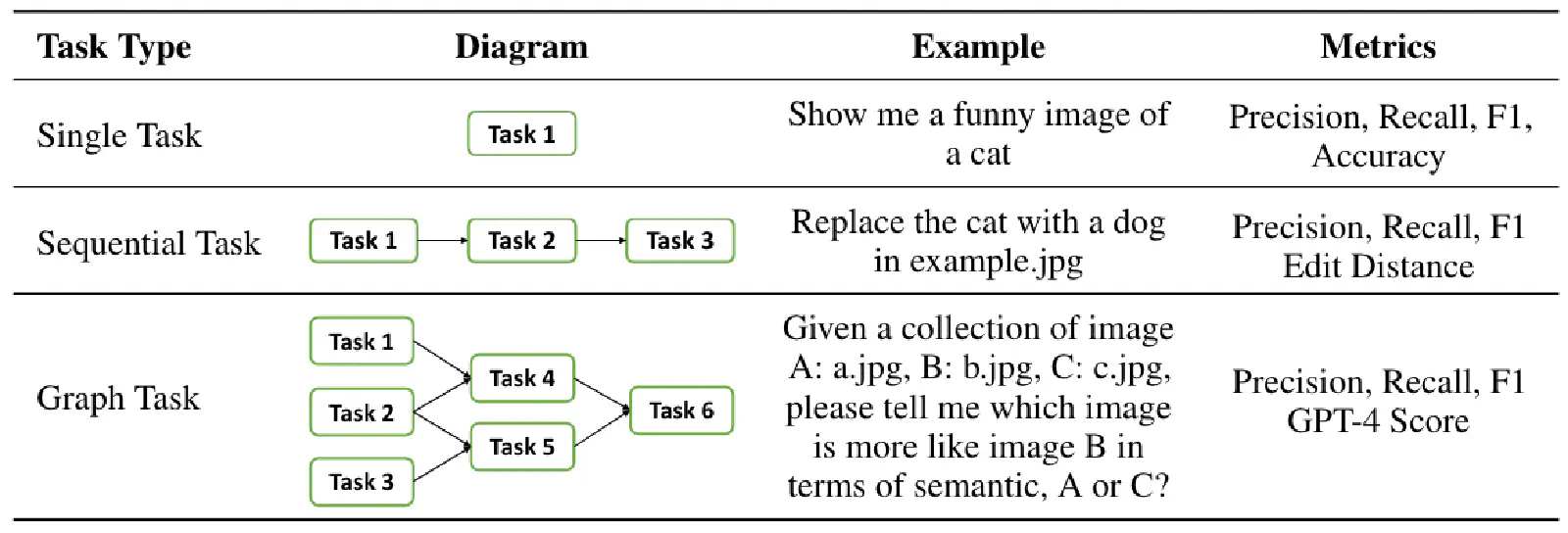
As shown in Table 2, three common Planning Tasks are Single Task (Single-Hop), Sequential Task (Multi-Hop), and Graph Task (Mulit-Hop).
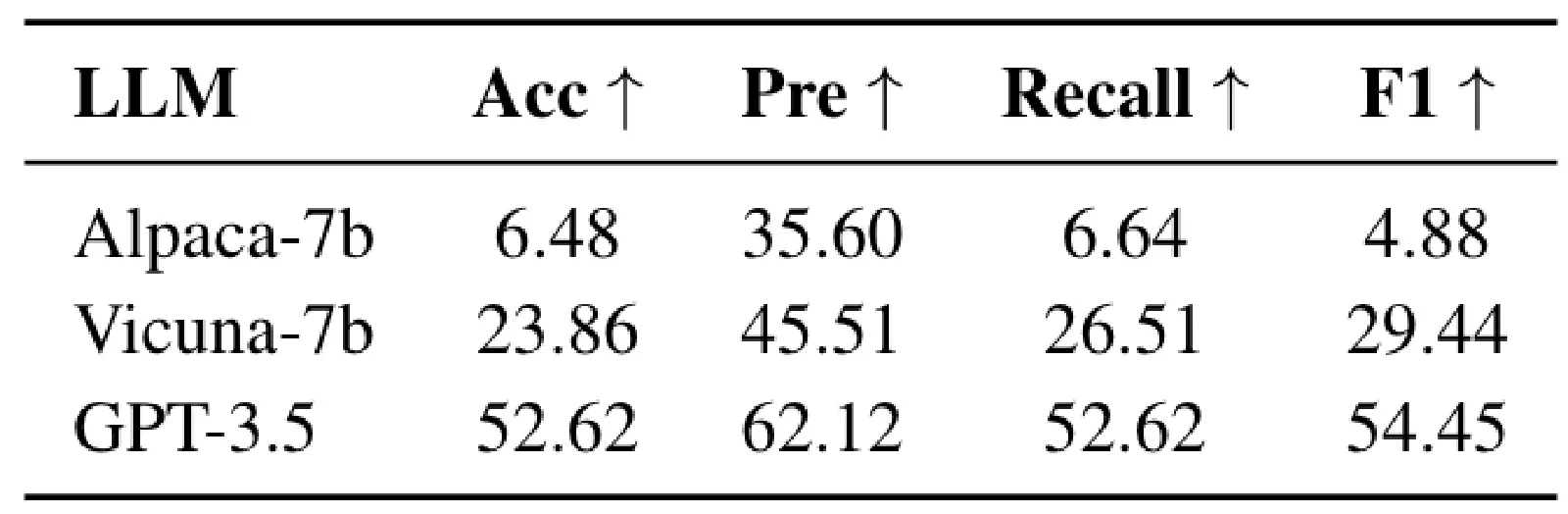
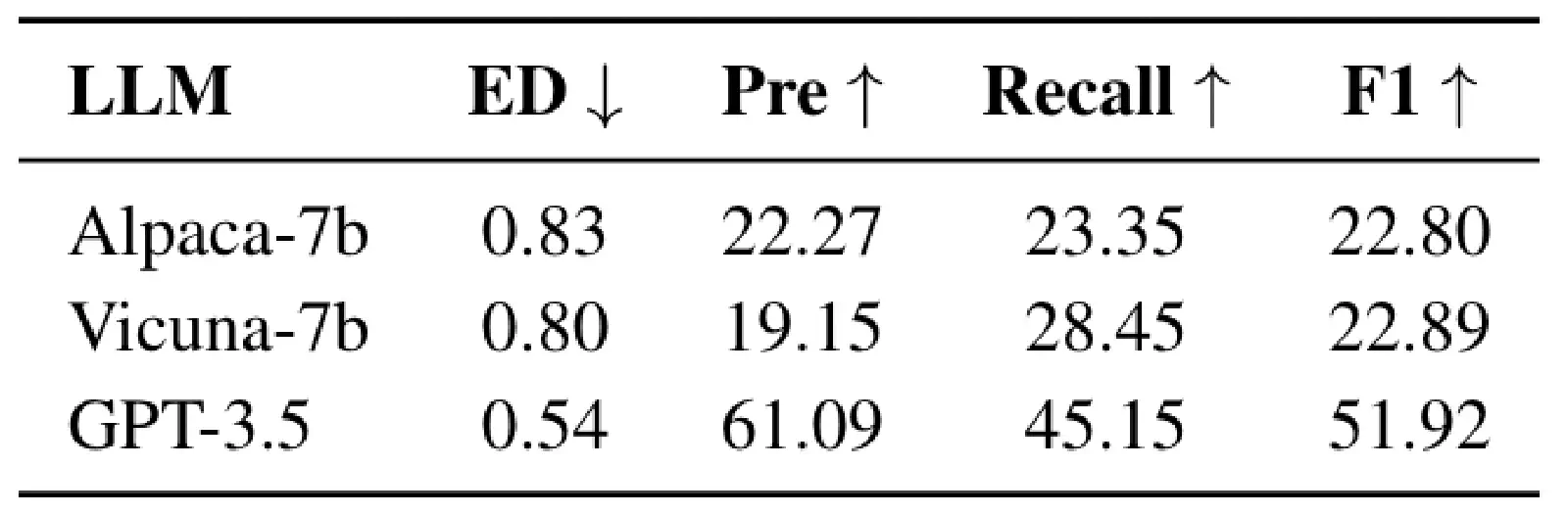
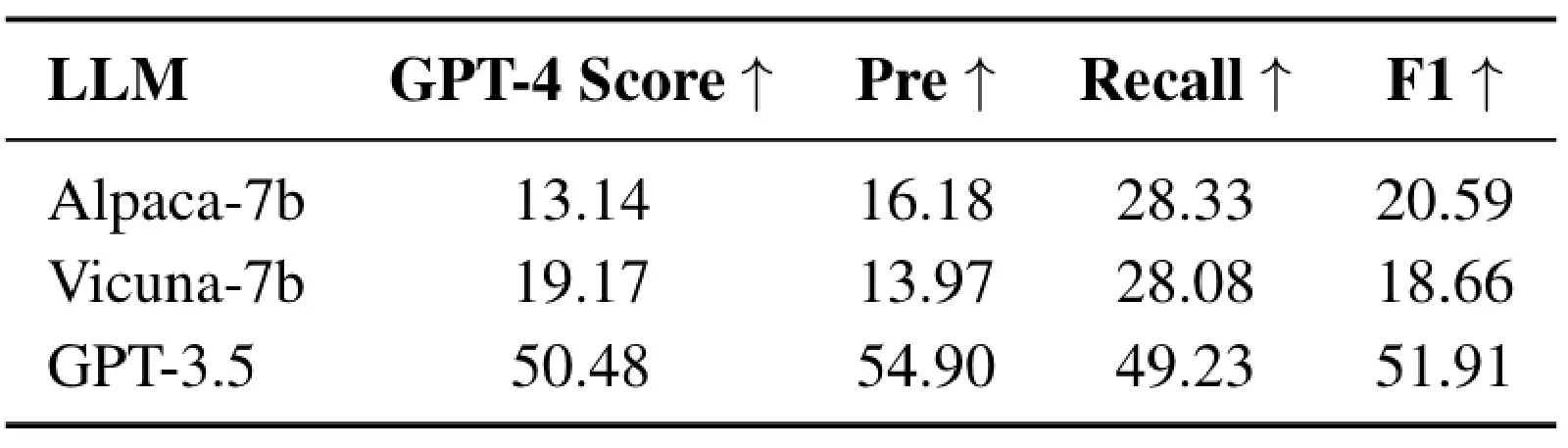
Tables 3, 4, and 5 respectively show HuggingGPT’s performance on these 3 types of Planning Tasks. It is very evident that, at that time, GPT-3.5 completely outperformed other Open-Sourced Models. From the experiments in Tables 3, 4, and 5, it can also be observed that in HuggingGPT’s approach, the Task Planning largely relies solely on the LLM’s own capability. Besides Specification-based Instruction and Demonstration-based Parsing techniques, HuggingGPT did not propose any special method to enhance Task Planning capability.
9 Conclusion
In this article, we introduced a Single Agent method — HuggingGPT (NeurIPS 2023 Poster).
The core concept of HuggingGPT is to use the LLM’s powerful reasoning ability as a Controller/Coordinator for Task Planning, where each Task utilizes a corresponding Model/Tool. Then, through subsequent Model Selection, Task Execution, and Response Generation, the final answer is obtained.
Personally, I think HuggingGPT’s method is not complex, but its contribution lies in proposing a Single Agent Framework (ex. what steps it should include, what the output of each step should look like, how to write the Prompt/Instruction for each step). Moreover, it successfully used the LLM as a Controller/Coordinator for Task Planning and Tool Usage to handle more complex tasks shortly after ChatGPT was released (ChatGPT was released on 2022/11/30, and HuggingGPT was published in 2023/03)!