Stop LLMs From Blindly Guessing: A Deep Dive into "Clarify When Necessary" (NAACL 2025)

1 Introduction
When developing LLM applications (or simply using ChatGPT), everyone has likely experienced this: You throw out a slightly vague instruction, such as asking, “How is Apple performing lately?” You are thinking about the stock price of the tech giant, but the model seriously replies with this year’s wholesale prices in the fruit market.
This is one of the biggest pain points of current LLMs: They love to “blindly guess” too much.
Most current models are trained to be “obedient students” that must answer every question. Even when faced with ambiguous instructions, they tend to choose the highest probability answer and output it directly. However, in real-world LLM applications, the cost of this “pretending to understand” is high. We want AI to act like a senior consultant—“When I am unsure of your meaning, I should actively stop and ask you, rather than rambling on with a generated response.”
The paper we are discussing today, “Clarify When Necessary” (NAACL 2025), proposes a very elegant solution. The authors not only define when to ask but also propose an algorithm called INTENT-SIM. This allows the model to simulate various user intents in its “mind” to precisely determine whether it is necessary to initiate a dialogue.
- Refusing Blind Guesses: The core capability of interactive AI is not just answering questions, but judging “when to ask questions.”
- Decoupling Uncertainty: Traditional methods that look at Logits (Likelihood) often cannot distinguish between “the model being dumb” and “the question being unclear.” This paper perfectly decouples the two.
- INTENT-SIM Algorithm: By having the model generate a clarifying question and self-simulating multiple possible answers (User Simulator), it calculates the entropy of intents to decide whether to ask.
- Dialogue > Perfect Instruction: Experiments found that clarifying through a “Q&A” process actually performs better than directly providing a “perfect, unambiguous instruction.” This overturns our understanding of Prompt Engineering.
2 Why is “Deciding When to Ask” So Hard?
Before diving into the algorithm, let’s break down the problem. Why can’t we simply set a Threshold and ask whenever the model’s Confidence Score is low?
There are two devilish details here:
2.1 Ambiguity is Not Binary
In the past, academia often treated Ambiguity as a True/False classification problem. But in the real world, language has a “Dominant Interpretation.”
For example, if I say “I am going to Boston,” although there is a Boston in Georgia, 99% of people will assume it is the one in Massachusetts. If your LLM jumps out every time it hears Boston and asks: “Do you mean MA or GA?”, the user experience would absolutely collapse.
Therefore, the system must weigh the trade-off: Accuracy gain from asking vs. Interaction Cost impacting the user.
2.2 Mixed Uncertainty
This is the most technical pain point. When a model outputs a low-confidence answer (High Entropy), there are usually two possibilities:
- Epistemic Uncertainty: The model itself is ignorant. For example, asking it about obscure knowledge it hasn’t seen, or a language it wasn’t trained well on. Asking the user is useless in this case because the model doesn’t even know what it’s talking about.
- Aleatoric Uncertainty: The question itself is vague. The input information contains multiple reasonable interpretations. Only in this case should we ask the user.
Existing SOTA methods (like looking directly at Output Likelihood) cannot distinguish between these two. This leads to systems often asking random questions when they lack knowledge, yet choosing to remain silent when there is genuine ambiguity.
The core contribution of this paper is successfully “decoupling” these two types of uncertainty through INTENT-SIM.
3 Methodology: Teaching Models to “Brainstorm”
The authors propose a Three-Stage Pipeline and the core algorithm INTENT-SIM.
3.1 Three-Stage Pipeline
This is a general decision-making framework that simulates a “limited budget” scenario in the real world:
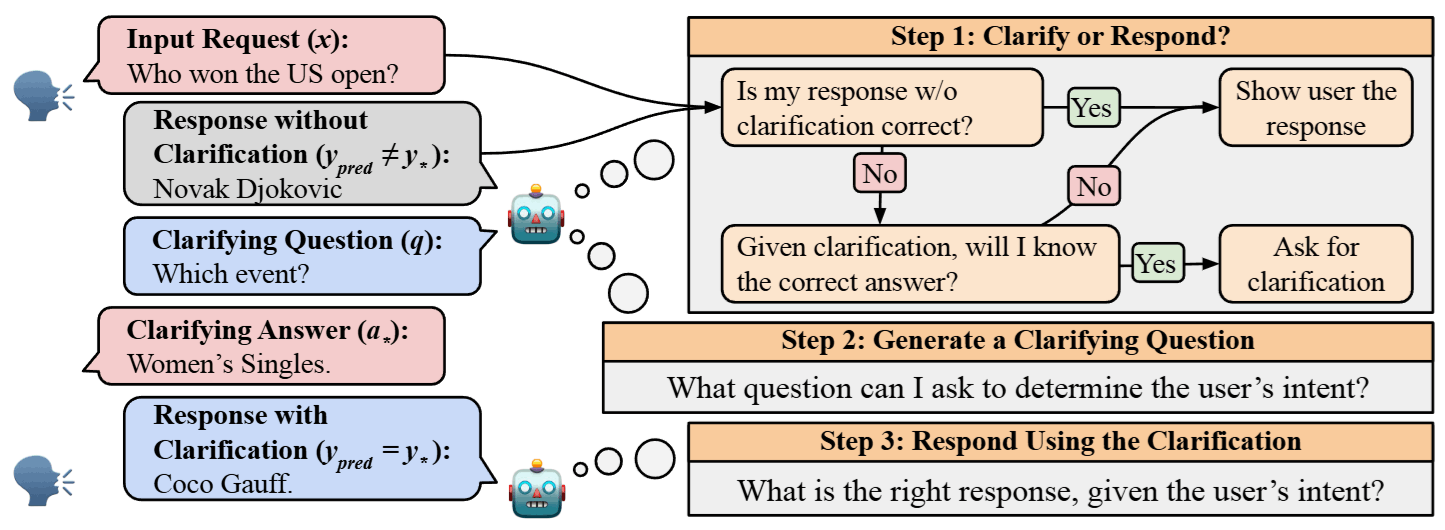
- Decision Stage (Clarify or Respond?): Calculate the uncertainty score . If it exceeds the threshold (e.g., the budget only allows us to ask about the top 10% most ambiguous questions), proceed to Stage 2; otherwise, answer directly.
- Clarification Stage (Generate & Ask): The system generates a question , and the user provides an answer .
- Response Stage (Final Response): Generate the final answer based on or .
3.2 Core Algorithm: INTENT-SIM
This is the soul of the paper. The author’s idea is intuitive: To judge if a question is ambiguous, the best way is to see “If I asked this clarifying question, how many distinctly different answers would the user have?”
This process is divided into four steps:

3.2.1 Let the Model “Self-Ask” (Generate Clarifying Question)
After receiving input , use Few-shot prompting to force the model to generate the clarifying question it thinks is most necessary.
- This step is crucial; it acts like putting a “search for ambiguity” filter on the model, forcing it to focus on the unclear parts of the input.
3.2.2 Simulate User Responses (The “Shadow Clone” Technique)
With the question , the system then plays the role of the “user” to simulate answering this question.
- We increase the temperature parameter () and randomly sample times.
- We get 10 simulated answers . For example, for “trunk,” we might get “Car’s rear storage,” “Elephant’s nose,” “Large box,” etc.
3.2.3 Intent Clustering via NLI
Here we encounter a classic NLP problem: Paraphrasing. “Rear storage” and “The storage space at the back of a car” are literally different, but the Intent is the same. We cannot say there is ambiguity just because the wording is different.
The authors use an NLI (Natural Language Inference) model to solve this:
- Compare the 10 answers in pairs.
- If and entail each other (Entailment), they are considered the same category.
- Use a graph algorithm (DFS) to find Connected Components, where each component represents an independent User Intent.
3.2.4 Calculate Uncertainty Score (Entropy Calculation)
Finally, calculate the Entropy of the intent distribution.
- High Entropy: The simulated answers are very divergent (saying it’s an elephant’s nose one moment, and a car trunk the next) True Ambiguity, Ask!
- Low Entropy: The simulated answers are highly concentrated (everyone says it’s Boston, MA) Dominant Interpretation, Answer Directly!
Through this flow, if the model is confused due to “lack of knowledge,” it usually cannot generate a specific clarifying question, or the simulated answers will be a pile of meaningless noise (filtered out by NLI), thus successfully avoiding ineffective questioning.
4 Experimental Data: Findings That Slap Intuition in the Face
The authors tested on three tasks: QA (AmbigQA), NLI (AmbiEnt), and Machine Translation (DiscourseMT).
4.1 Is Asking Really Useful?
First, we need to confirm: Does asking an extra sentence actually improve Performance? The authors compared:
- Direct: Blind guessing directly.
- Clarify: The system asks, gets an answer, and then responds.
- Disambig: Directly providing a manually rewritten “perfect unambiguous instruction.”
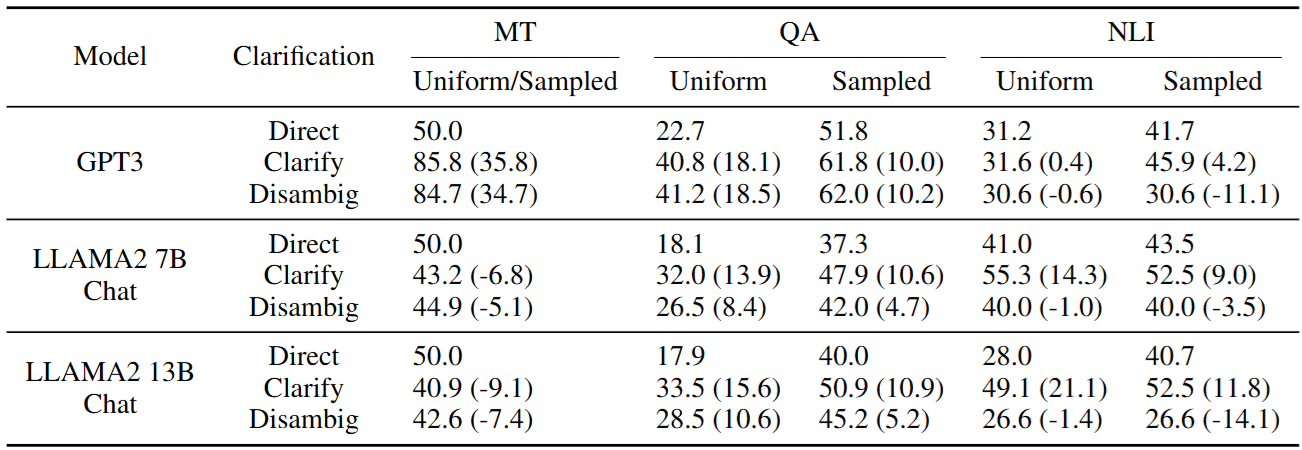
There is a very interesting finding here:
In Table 2, the performance of Clarify (Q&A interaction) is frequently better than Disambig (giving a perfect sentence directly)!
Why? The authors speculate that this is because current Chat models (Instruction Tuned LLMs) have seen massive amounts of dialogue data. Compared to manually rewritten stiff long sentences (Disambig), the “Q&A interaction” format aligns better with the model’s training distribution. This gives us a major inspiration for Prompt Engineering: Sometimes stuffing Context into the conversation history is more effective than writing it in the System Prompt.
4.2 Who Picks the Timing Best?
Under a fixed interaction budget (e.g., only allowed to ask about 20% of the questions), comparing the accuracy (AUROC) of different methods in selecting topics:
- Likelihood: Traditional method, looking at Logits.
- Self-Ask: Letting the model ask itself “Do I need to ask?”.
- INTENT-SIM (Ours): The method in this paper.
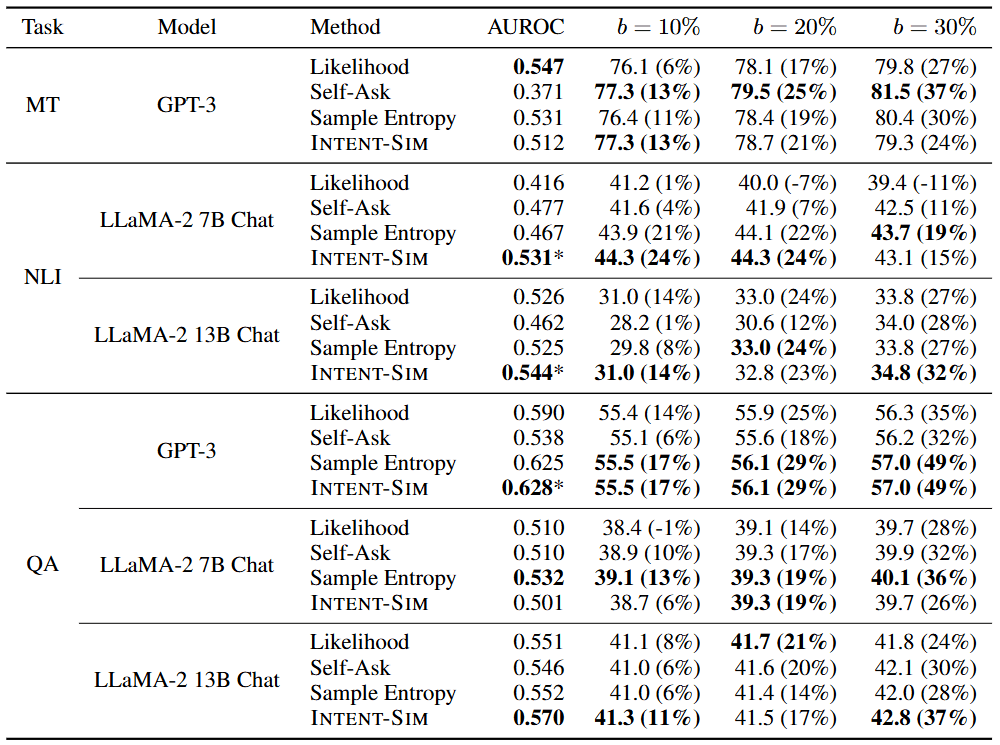
Result Analysis:
- The Failure of Likelihood: On the LLaMA-2 QA task, Likelihood performed even worse than Random. This confirms that “Low Confidence Ambiguity.”
- The Victory of INTENT-SIM: The reason it wins is that it introduces the intermediate variable “Clarifying Question ,” forcing the model to focus its attention on “Ambiguity” rather than “Knowledge Blind Spots.”
5 Conclusion
This paper challenges a default assumption in LLM interaction design—“LLMs should always try to answer directly.” INTENT-SIM demonstrates how to give LLMs Metacognition: Knowing when to shut up and when to speak up.
Although INTENT-SIM is powerful, there are two pitfalls to watch out for when deploying it in products:
Latency: Generating 10 answers and running NLI Clustering at Runtime is absolutely disastrous for real-time conversation.
- Solution: Suggest adopting a Cascade System. First use fast Likelihood to filter out 80% of obviously problem-free cases, and only activate INTENT-SIM for inputs sitting in the “gray area.”
Cost: NLI comparison is expensive.
- Solution: If it’s a large-scale task like news clustering, stick to Embeddings (like NV-Embed). But in this kind of One-shot decision scenario, for the sake of precision, NLI is still the preferred choice.