Tuning LayerNorm in Attention: Towards Efficient Multi-Modal LLM Finetuning

1 Introduction
It has been less than two years since ChatGPT was launched on November 30, 2022, and as of today (July 8, 2024), an incredible number of LLMs have been developed that can rival it (Claude, Gemini… and these are just the ones we hear about often). A quick look at the Arena Leaderboard shows just how fierce the competition among LLMs is, with models dominating the charts for only a few weeks before being dethroned by others.
The Open LLM Leaderboard also reveals that the development in the open-source LLM field is just as impressive!
Single-modality LLMs are no longer a rarity; major tech giants are scrambling to release their own Multimodal Large Language Models. On HuggingFace, there is already an OpenVLM Leaderboard, which shows GPT-4o and Claude 3.5 Sonnet currently holding the first and second spots, making them the world’s most powerful Vision Language Models. Let’s make a special note of today’s date, July 8, 2024, to see how long these two models can hold their thrones!
Today, I want to share a paper related to Multimodal Large Language Models. It’s a Spotlight Paper from ICLR 2024 titled Tuning LayerNorm in Attention: Towards Efficient Multi-Modal LLM Finetuning. This paper is quite easy to read, and I believe you can grasp 80% of its concept just from the title: that’s right! By simply fine-tuning the LayerNorm Layer within the Attention Block, you can train an LLM into a powerful MLLM!
2 The Problem This Paper Aims to Solve
Numerous studies have been published on how to train an LLM into a Multimodal LLM. For example, LLaVA, proposed in the NeurIPS 2023 Oral Paper: Visual Instruction Tuning, and MiniGPT4, proposed in the paper Enhancing Vision-language Understanding with Advanced Large Language Models, have both successfully transformed an LLM (Vicuna) into a Multimodal LLM capable of Zero-Shot Instruction-Following.
The process of training an LLM into an MLLM typically involves two stages:
First Stage: Pre-Training. This stage usually involves training a Connector using a large amount of Image Captioning Data.
The goal of this stage is to train the Connector to align the Image Embeddings from the Visual Encoder with the Language Model’s Word Embedding Space. In other words, it allows the LLM to gain a “preliminary” understanding of the new image modality.
Note 1: In my experience, most MLLMs (like LLaVA and MiniGPT4) use Image Captioning Data for training in this stage. However, Apple’s recent MM1 paper suggests that including other types of training data at this stage can further improve the MLLM’s performance.
Note 2: I use the word “preliminary” because, based on my implementation experience, an MLLM that has only undergone the Pre-Training stage can already understand images. However, it can only perform basic “image description” and is unable to handle instruction-following tasks.
Second Stage: Fine-Tuning. This stage typically uses a large amount of Instruction-Following Data to train the Connector and the LLM.
The purpose of this stage is to train the MLLM to go beyond simple image description and provide different answers based on our prompts. For example, given a picture, we can ask the MLLM, “How many people are in this picture?”
Note 1: There is no consensus on which modules to fine-tune during this stage. LLaVA, for instance, fine-tunes both the Connector and the LLM. In contrast, MiniGPT4 only fine-tunes the Connector at this stage.
Note 2: According to my own training experience, if the LLM is also fine-tuned in this stage (like LLaVA’s approach), the MLLM’s performance tends to be better. However, because the LLM’s parameters are altered, it is prone to Catastrophic Forgetting, meaning the LLM’s original Conversational Ability declines. To prevent Catastrophic Forgetting, it’s necessary to include some Language-Only data in the training set so that the LLM can retain its original conversational skills while being trained into an instruction-following MLLM.
On the other hand, if the LLM is not fine-tuned at this stage (like MiniGPT4’s approach), the problem of Catastrophic Forgetting is avoided, and the LLM’s conversational ability remains strong. However, the MLLM’s responses seem to be less precise.
To improve MLLM performance, we might choose to include the LLM in the second stage of training (the Fine-Tuning stage). However, these LLMs often have a massive number of parameters. The Vicuna model used by LLaVA, mentioned earlier, already has 7B parameters. Fine-tuning these 7B parameters is, I believe, beyond the reach of the average user. Therefore, this paper proposes the method of Tuning LayerNorm in Attention to more efficiently fine-tune the LLM in the second stage!
3 Tuning LayerNorm in Attention
Thus, the method proposed in this paper is: during the second stage of training, simply fine-tuning the LayerNorm in the Attention Block is enough to help the LLM become a decent MLLM. The authors came up with this idea because they view the process of training an LLM into an MLLM as a form of Domain Adaptation—shifting from the original Text Domain to a Multi-Modal Domain.
Furthermore, past research has indicated that adjusting normalization layers is an effective way to help a model adapt to a domain shift. Therefore, in terms of implementation, there isn’t much to say about this paper—you just need to set the requires_grad of the LayerNorm parameters in the LLM to True during the second training stage.
4 Experimental Results
When comparing different fine-tuning methods, the authors first pre-train the MLLM’s Connector for 3 epochs before proceeding to fine-tune the MLLM. In short, everyone uses the same pre-training method to see whose fine-tuning method is better!
In the experimental phase, the authors compared a total of 6 fine-tuning methods:
- Finetune: Fine-tunes all parameters in the LLM.
- LoRA: Adds a LoRA component (Rank = 32) to the linear structures in the LLM and fine-tunes these components.
- Attn. QV Proj.: Fine-tunes the Q and V linear projections in the Attention Block.
- Attn. MLP: Fine-tunes the MLP in the Attention Block.
- LayerNorm: Fine-tunes the Input and Post LayerNorm in the Attention Block.
Note: During the fine-tuning stage, the (Vision-Language) Connector, LLM Word Embedding, and LLM Output Head are also fine-tuned! From Table 1 below, we can see that among all fine-tuning methods, tuning only the LayerNorm can achieve surprisingly good performance:
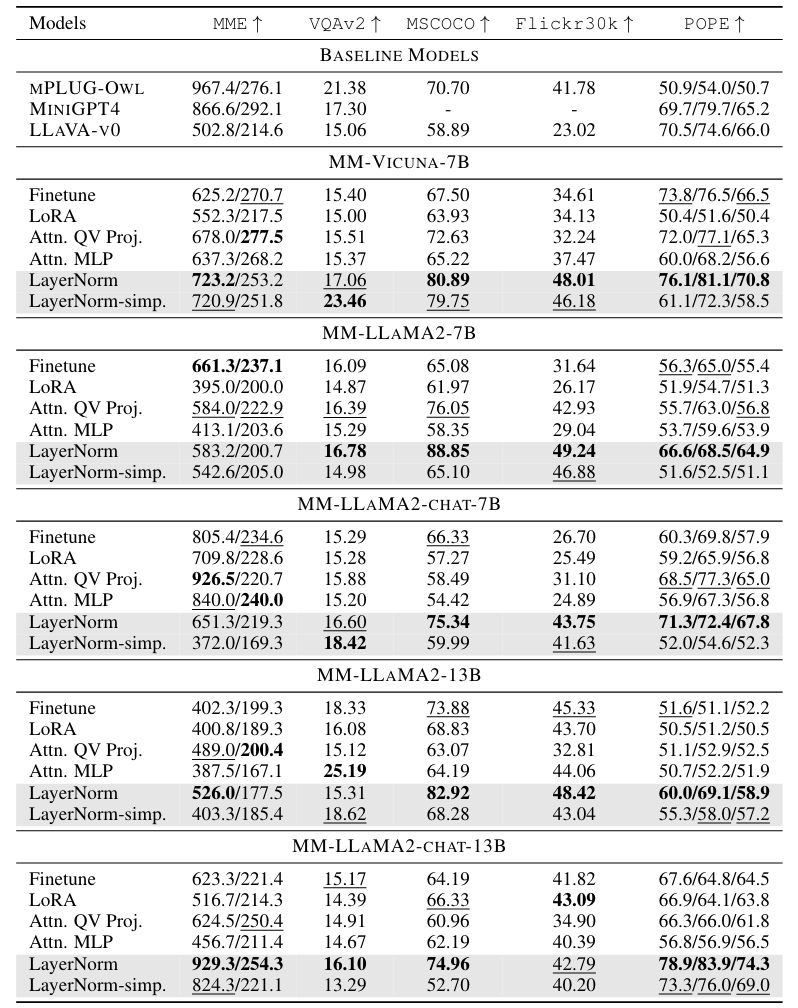
The parameters actually fine-tuned in the “LayerNorm” setting in Table 1 include not only the LayerNorm in the Attention Block but also:
- Vision-Language Connector
- LLM Word Embedding
- LLM Output Head
But can we just fine-tune LayerNorm alone and leave the other three untouched? In other words, the authors wanted to confirm if “truly, just fine-tuning the LayerNorm in the LLM can yield good performance.” The “LayerNorm-simp.” row in Table 1 represents the results of this setup, and it can be seen that the results are still quite good: on some benchmarks, its performance is as good as or even better than Full Fine-Tuning.
Table 2 below shows the memory consumption of various fine-tuning methods:
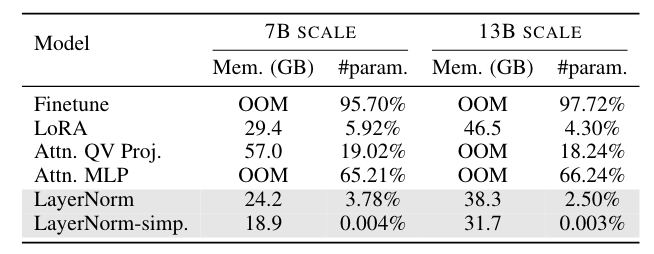
It is evident that the “LayerNorm” and “LayerNorm-simp.” fine-tuning methods place a much smaller burden on GPU memory.
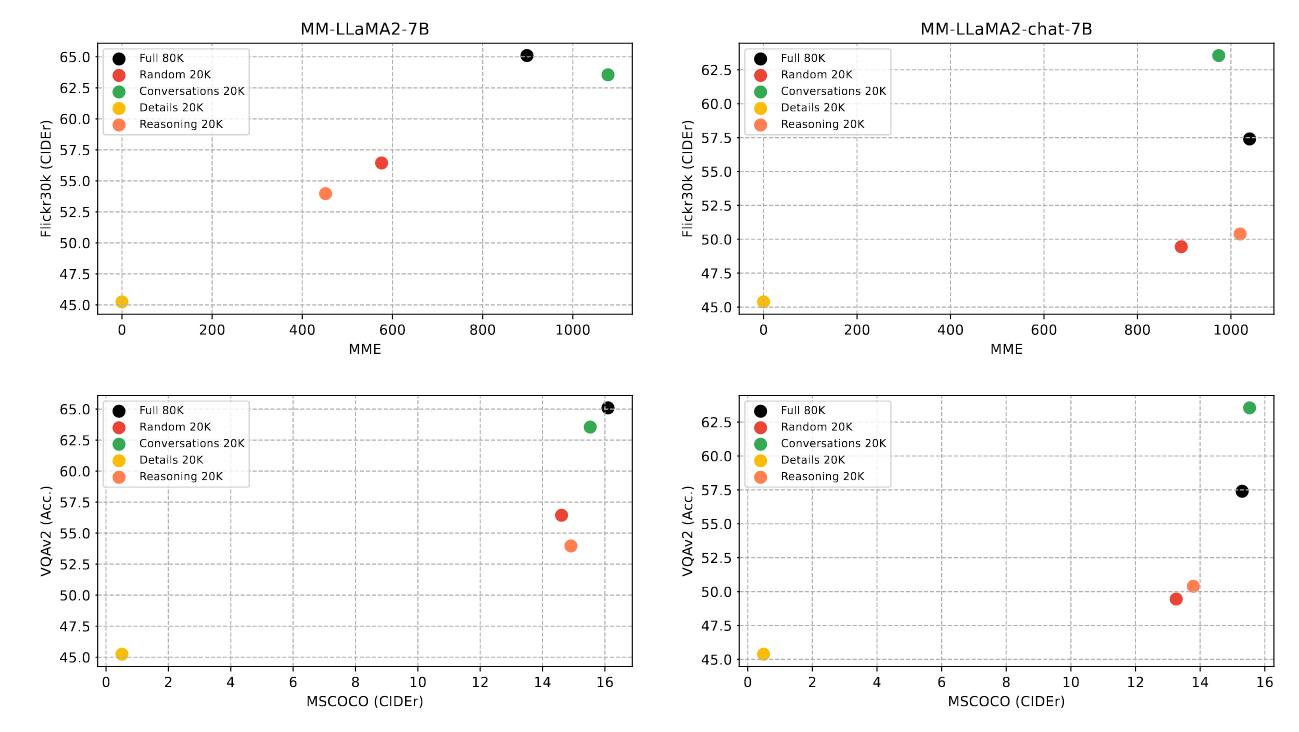
Additionally, the authors analyzed the contribution of different types of training datasets used in the fine-tuning stage to the MLLM’s capabilities. The instruction-following data used in the fine-tuning stage can be mainly divided into three types:
- image-grounded conversation
- image detail descriptions
- image-based complex reasoning
From Figure 2 above, it can be observed that image-grounded conversation is a more efficient data type. For the same amount of data, it can more effectively improve the MLLM’s performance.
As mentioned earlier, the Vision-Language Connector is allowed to be fine-tuned by default for all different fine-tuning methods in the fine-tuning stage. Could it be that the Vision-Language Connector is actually the key to adapting the model from the Text Domain (LLM) to the Multi-Modal Domain (MLLM)?
From Table 4 below, we can see that fine-tuning both LayerNorm and the Connector yields better overall performance. However, if only the Connector is fine-tuned, the performance drops significantly. If only LayerNorm is fine-tuned, the MLLM’s performance also decreases, but the drop is not as severe:
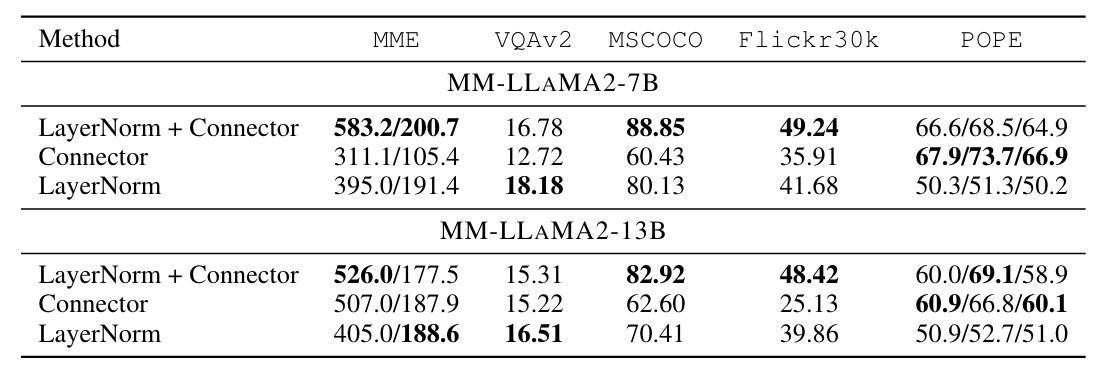
By now, you should understand that during the process of training an LLM into an MLLM, if you only fine-tune the LayerNorm within the LLM instead of the entire LLM in the second stage, you can still efficiently achieve good performance in the final MLLM.
But why? What makes LayerNorm such a magical module?
To understand why fine-tuning only LayerNorm yields better results than fine-tuning the entire model, the authors analyzed the similarity of representations across all layers of the model.
Table 6 below shows the average similarity between all layer representations for three different models trained with two different fine-tuning methods. It can be observed that the similarity is lower when only LayerNorm is fine-tuned:
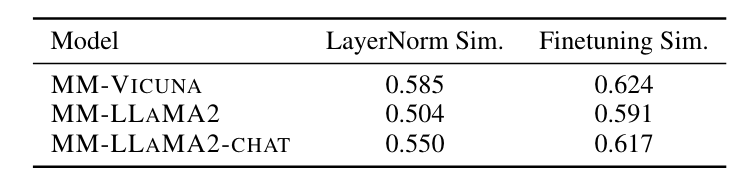
When the similarity between a model’s layers is low, it indicates that the model has stronger expressive power and can capture more patterns within the data. This is one of the reasons proposed by the authors. They also attempted to explain it from the perspective of gradient variance during the training process. If you are interested, you can read the paper for more details.
5 Conclusion
In this article, we’ve explored many concepts related to training LLMs into Multimodal LLMs (Pre-Training & Fine-Tuning). Through the ICLR 2024 paper Tuning LayerNorm in Attention: Towards Efficient Multi-Modal LLM Finetuning, we’ve shared a more efficient fine-tuning method:
During the second stage of training, simply fine-tuning the LayerNorm within the Attention Block can help an LLM become a high-performing MLLM. Experiments have shown that this fine-tuning method is indeed effective, with its performance on some benchmarks being as good as or even better than Full Fine-Tuning.
Finally, the authors also explained why fine-tuning only the LayerNorm in the LLM can lead to such impressive MLLM performance, using perspectives like Layer Representation Similarity and Gradient Variance