Beyond Fine-Tuning: How MemRL Enables Self-Evolving AI Agents via Reinforcement Learning

1 Introduction
Recently, while chatting with friends working on Agentic Workflows, I discovered that the biggest headache isn’t usually the LLM’s lack of reasoning power, but rather that “Agents cannot learn from their mistakes.”
Current solutions are often polarized: you either spend a fortune on Fine-tuning, only to encounter “Catastrophic Forgetting” where the model learns new skills but breaks old logic; or you implement a traditional RAG, which only retrieves data based on “semantic similarity,” often pulling out noisy results that look similar but are actually useless.
Is there a way for an Agent to “learn from its mistakes” like a human, without modifying the model weights (Frozen LLM)?
Today, I want to share a paper titled 《MemRL: Self-Evolving Agents via Runtime Reinforcement Learning on Episodic Memory》, which proposes a very elegant solution. It elevates “memory” from simple database retrieval to the level of Reinforcement Learning (RL) decision-making.
- Core Challenge: Solving the “Stability-Plasticity Dilemma” in continuous learning for Agents, avoiding the high cost of Fine-tuning and the low efficiency of RAG.
- Theoretical Innovation: Introducing M-MDP (Memory-Based MDP), treating memory retrieval as a “learnable policy,” and ensuring the process doesn’t lead to performance degradation via GEM theory.
- Two-Phase Mechanism: Combining semantic similarity (Phase A) with Q-Value assessment (Phase B) to ensure retrieved experiences are both “relevant” and “practical.”
- Runtime Evolution: Agents dynamically update the “Utility score” of memories during runtime, achieving true self-evolution.
2 Why are current Agents always “slow learners”?
Before diving into MemRL, let’s critique the two existing paths:
- Fine-tuning: This is like performing brain surgery on an employee just to teach them a new tool. Not only is the cost high, but the biggest fear is that they might forget how to walk after the surgery (parameter distribution disruption). This is a nightmare for Agents that need to constantly face new scenarios.
- Traditional RAG (Retrieval-Augmented Generation): This is currently the mainstream approach, but it has a fatal flaw — “Similarity Utility.”
- Imagine you are fixing a water pipe, and RAG pulls out a manual on “How to Fix Electrical Systems” because both are called “System Repair.” This semantic proximity might be completely unhelpful for solving the actual problem.
- Traditional RAG lacks a feedback loop; the system has no idea if the previously retrieved prompt actually helped.
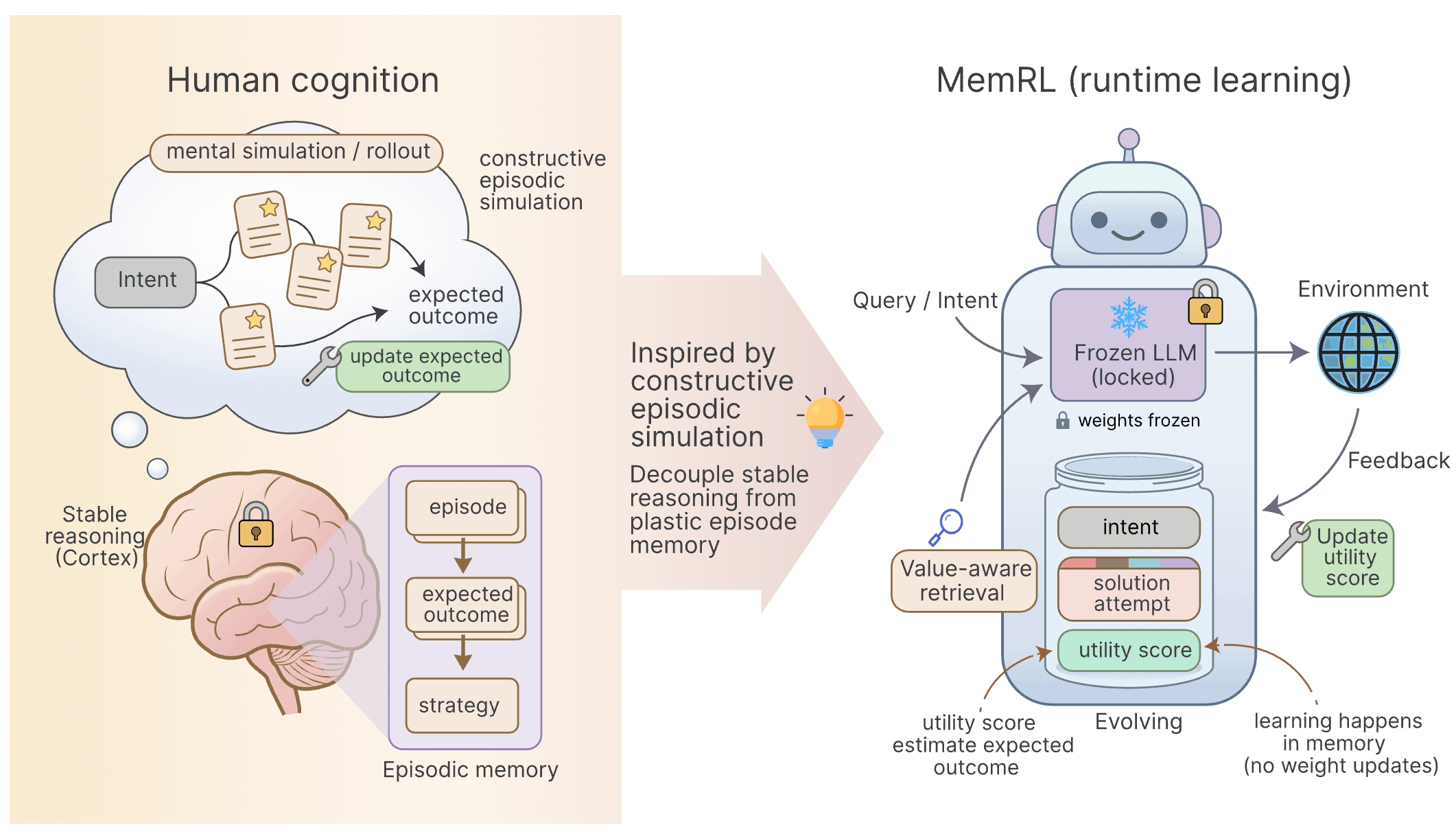
3 The Core Concept of MemRL: Memory as a “Cheat Sheet”
The developers of MemRL proposed an interesting shift: Instead of modifying the brain (LLM), why not give the Agent a notebook that automatically updates “star ratings”?
This notebook is no longer just a Key-Value structure but has been upgraded to an Intent-Experience-Utility Triplet:
- Intent (): What is your problem? (Used as an index)
- Experience (): How was it solved last time? (Specific Prompt or steps)
- Utility (): 🔥 This is the soul of the method. It represents the “expected value of success when using this experience in this context.”
Traditional RAG is like a standard library catalog; it can only tell you “There is a book about cakes here.” The MemRL memory bank is a Michelin Guide:
- : Category is “French Desserts.”
- : A specific recipe.
- : Star Rating (e.g., of the last 100 people who followed it, 95 gave it a positive review).
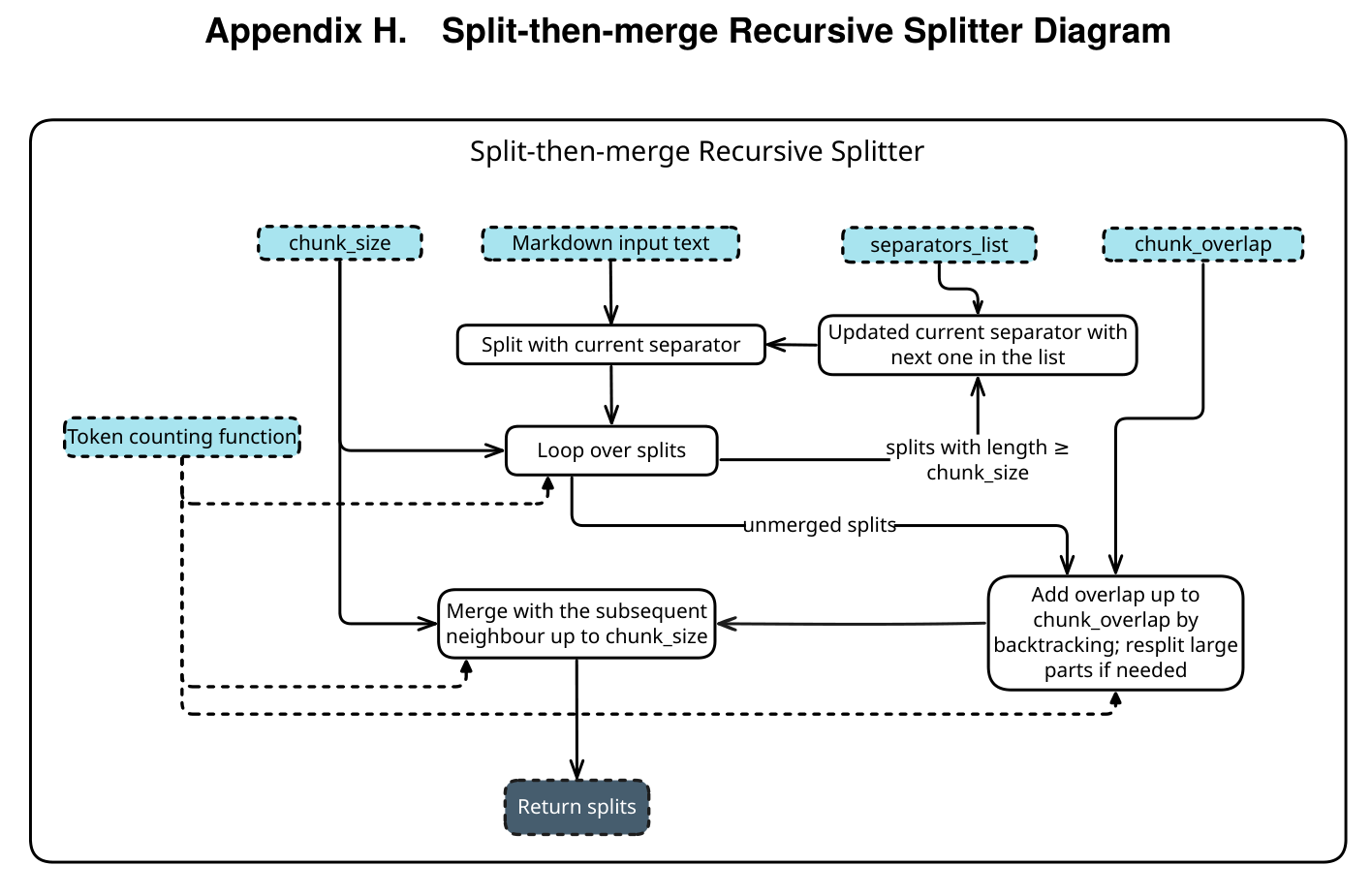
4 Technical Details: How Does MemRL Work?
The operation of MemRL can be broken down into two key steps: How to find (Retrieval) and How to learn (Update).
4.1 Two-Phase Retrieval: Not Just Similar, but Useful
To balance retrieval efficiency and quality, MemRL uses a funnel-like screening process:
Phase A: Similarity-Based Recall First, standard Embedding similarity is used to pluck the top 20% most relevant memories from the pool. This step ensures we don’t use “plumbing” experience to solve a “Python coding” problem.
Phase B: Value-Aware Selection This is the main event. The system performs Re-ranking on the candidate memories using the following scoring formula:
Z-Score Normalization is used here. Why? Because similarity usually stays between 0.7~0.9, while Q-values might range from 0~1. Without normalization, Q-values could easily be overwhelmed. Through this formula, we can select those “golden experiences” that might have slightly lower similarity but a very high historical success rate.
4.2 Runtime Utility Update: Learning from Experience
Once the Agent completes a task, it updates its memory based on the Reward () provided by the environment.
- Updating Old Memories: Using the Q-Learning concept: . If it succeeded, the “star rating” of this experience goes up; if it failed, it goes down.
- Writing New Memories: The Agent compresses the current execution process into a concise experience.
5 Mathematical Guarantees: Will it “Learn Bad Habits”?
Many worry that a self-updating mechanism might lead to model collapse. The authors introduced the GEM (Generalized Expectation-Maximization) theory to prove that as long as Phase A provides semantic constraints (serving as a Trust Region), the Agent’s expected return will be Monotonically Non-Decreasing. Simply put, it is mathematically guaranteed to only get smarter, not dumber.
6 Experimental Results: Not Just Theory, Strong in Practice
The authors tested the system on ALFWorld, BigCodeBench, and the highly difficult HLE, comparing it against static memory frameworks such as Mem0 as baselines.
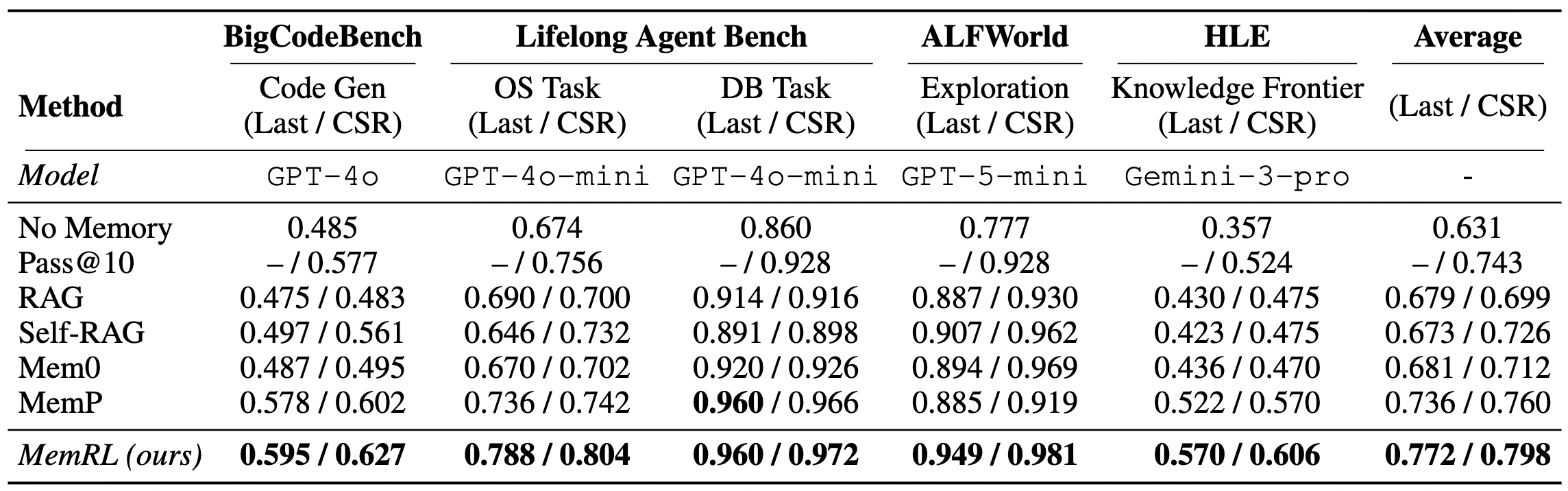
A few interesting observations:
- Excellent Long-term Task Performance: In ALFWorld and OS Tasks that require multi-step planning, MemRL showed the most significant improvements. This proves that “remembering successful paths” is extremely helpful for complex decision-making.
- Strong Resistance to Forgetting: Experiments showed that MemRL’s Forgetting Rate is extremely low and stable. This solves the “getting worse with use” problem that often plagues long-running Agents.
- Surprising Findings in HLE: Even in HLE tests where there is almost no similarity between questions, MemRL’s performance improved significantly. This means the system learned “precise memorization” — for extremely difficult problems, the Agent used the Q-value mechanism to “hardcode” the correct answer, which is very powerful for handling specific edge cases.
7 Conclusion
After reading this paper, my biggest takeaway is that it “redefines the value of failure.”
In traditional development thinking, we always try to filter out errors. But in the MemRL framework, errors are permitted and transformed into assets. A seasoned engineer is great not just because they know how to do things right, but because they remember where they tripped up before.
Through an elegant mathematical framework (M-MDP + GEM), MemRL grants Agents this “seasoned” wisdom without changing LLM weights. If you are developing an Agent system that needs to run long-term and evolve continuously, MemRL’s “non-parametric reinforcement learning” approach is highly worth referencing.