Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
1 Introduction
This article introduces the paper “Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory”. Mem0 is an agentic memory method developed by the company mem0.ai. Although this paper was just released on arXiv in April 2025, the first version of Mem0 was already released on GitHub back in July 2023.
Mem0’s main goal is to solve the long-term memory (LTM) problem in Large Language Models (LLMs) and provide a production-ready solution. Visiting Mem0’s GitHub page, you might be surprised to find that as of May 11, 2025, it has garnered over 29K stars. The project’s popularity is truly noteworthy.
This article will focus on introducing the Mem0 paper, understanding its design philosophy, architecture, and experimental results. Detailed usage instructions are available on Mem0’s GitHub under the “Basic Usage” section, so they won’t be repeated here.
2 The Problem Mem0 Aims to Solve

Mem0 primarily aims to address the long-term memory (LTM) issues faced by AI agents. When an agent lacks LTM, it cannot remember past interactions with humans. This prevents it from tailoring responses to human preferences. As shown in Figure 1 (left), if a user states they are vegetarian and want to avoid dairy at the beginning of a conversation, an agent without LTM might later forget this and offer unsuitable suggestions. Conversely, Figure 1 (right) shows an agent with LTM remembering the user’s preferences and providing relevant advice.
Even though the context windows (the amount of recent information an LLM can consider) of current LLMs are constantly expanding, they still can’t fully solve the LTM problem. The authors of Mem0 highlight three reasons:
- As interactions increase, the accumulated conversation history and thought processes will eventually exceed the LLM’s context window, making it impossible for the LLM to remember all information.
- Human-LLM interactions often jump between different topics. This means if a user asks about Topic A, the LLM’s context window might be filled with unrelated information, potentially affecting the quality of its answer for Topic A.
- Most LLMs are based on the Transformer architecture. The self-attention mechanism in Transformers not only increases in computational complexity with a larger context window but its performance can also degrade.
3 A Brief Introduction to the Mem0 Method
Mem0 primarily includes two memory architectures:
- Mem0: Manages memory purely through an LLM and a vector/relational database.
- Mem0g: Builds upon Mem0 by adding a graph-based memory structure.
3.1 Mem0’s Memory Management
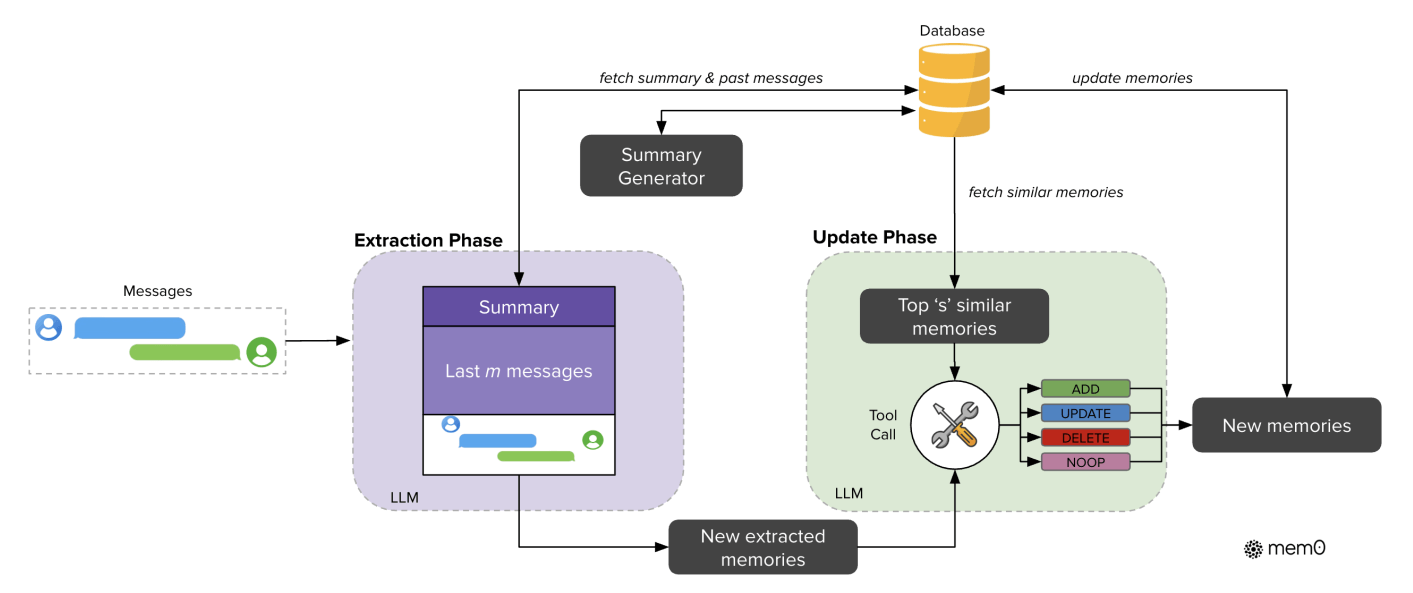
Mem0’s memory management, as shown in Figure 2, is divided into two main phases: the Extraction Phase and the Update Phase.
- Extraction Phase: Extracts information worth remembering from the conversation history.
- Update Phase: Compares this new information with existing memories, then updates or deletes existing memories accordingly.
Specifically, in the Extraction Phase, an LLM extracts “candidate facts” (potential new memories) based on:
- A summary of long-term past conversations: This summary is periodically generated by another LLM based on conversation records stored in the database.
- The last M conversation turns: These represent the most recent interactions and are the source from which the Extraction Phase extracts candidate facts.
In the Update Phase, each candidate fact is compared with existing memories to ensure consistency in the memory database. For every candidate fact, the K most similar “retrieved memories” (based on embedding similarity) are fetched from the database. These retrieved memories are then compared with the candidate fact.
This comparison is done by an LLM using a technique called “function-calling” to decide on one of the following operations:
- ADD: Since the candidate fact is new information, it’s added to the memory database.
- UPDATE: The candidate fact is used to update an existing memory in the database.
- DELETE: An existing memory in the database contradicts the candidate fact, so the existing memory is deleted.
- NOOP: No operation is performed.
In their experiments, the authors set M = 10 for recent conversation turns in the Extraction Phase and K = 10 for retrieved memories in the Update Phase. GPT-4o-mini was used as the LLM for both phases.
3.2 Mem0g’s Memory Management
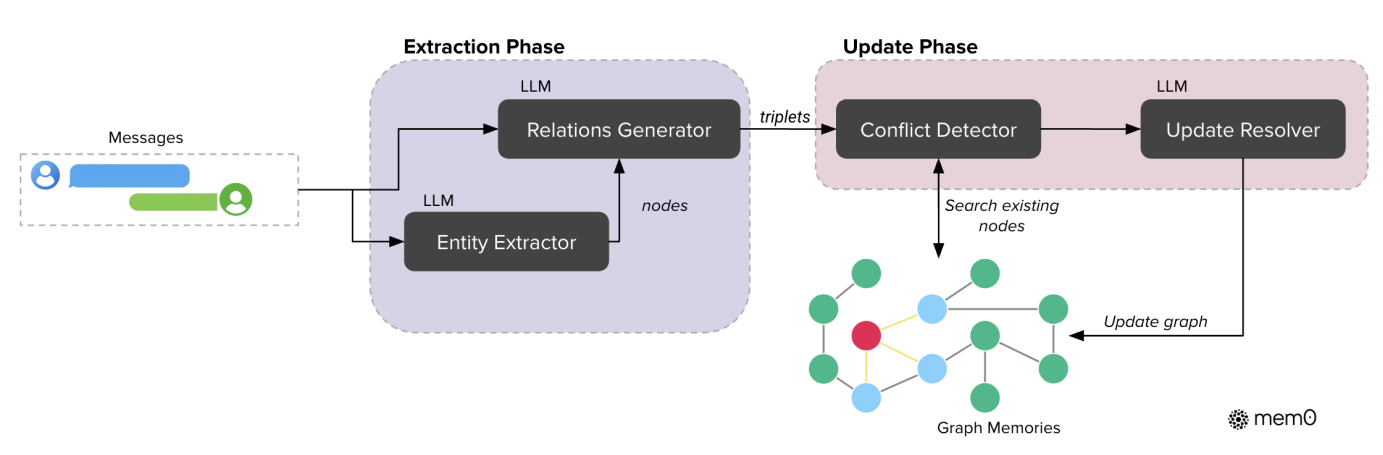
As seen in Figure 3, Mem0g’s memory architecture is quite similar to Mem0’s, featuring both an Extraction Phase and an Update Phase. The key difference is that Mem0g uses a graph-based approach to manage memory, while Mem0 uses vector/relational databases.
In Mem0g, memory is represented by a graph comprising nodes , edges , and labels . Specifically:
- Nodes : Represent entities (e.g., Alice, San Francisco).
- Edges : Represent relationships between entities (e.g., lives_in).
- Labels : Represent the semantic type of entities (e.g., Alice - Person, San Francisco - City).
Each entity node consists of three components:
- The entity’s category (e.g., Person, Location, Event).
- The entity’s embedding , which captures its semantic meaning.
- The entity’s metadata, including its creation time .
In Mem0g, relationships between nodes are represented by a triplet , where and are the source and target nodes, and is the edge connecting them.
In the Extraction Phase, an LLM performs a two-stage process: Entity Extraction and Relationship Generation.
Entity Extraction involves an Entity Extractor LLM identifying all entities from the conversation history and tagging their types. For example, if the conversation is about travel, entities might include “departure city,” “destination,” and “departure time.” These entities become nodes in the graph and are labeled with categories like “Location” for “departure city” and “Date” for “departure time.”
Relationship Generation uses a Relationship Generator LLM to extract relationships between entities from the conversation history and identify their types. For instance, in a travel discussion, the relationship between “departure city” and “destination” might be “Travel From-To,” while the relationship between “departure time” and “destination” could be “Travel Date.”
In the Update Phase, based on newly created triplets , the embeddings of the source and target nodes are compared with existing nodes in the graph. Nodes similar to these two are retrieved. Then, through Conflict Detection and an Update Resolver, a decision is made whether to add both new nodes to the graph, add only one, or just update existing information in the graph without adding new nodes.
Mem0g employs two memory retrieval methods:
- Entity-Centric Approach: Based on a query, it first analyzes the entities in the query. Then, it retrieves related nodes from the graph and constructs a subgraph from these nodes and their existing relationships. This subgraph represents the relevant contextual information for the query.
- Semantic Triplet Approach: Based on a query, it first converts the query into a dense embedding. This embedding is then compared with the embeddings of the textual encodings of all triplets in the graph. The K most similar triplets are retrieved, representing the relevant contextual information for the query.
In the experimental phase, the authors used Neo4j as the graph database and GPT-4o-mini as both the Entity Extractor LLM and the Relationship Generator LLM.
4 Mem0’s Experimental Results
4.1 Choice of Test Dataset
The authors chose the LOCOMO dataset as a benchmark. LOCOMO is specifically designed to evaluate the long-term memory capabilities of models in conversational systems. It contains 10 conversations, each averaging 600 turns (about 26K tokens). Each conversation has an average of 200 questions with corresponding ground truth answers. These questions are categorized into types: Single-Hop, Multi-Hop, Temporal (time-related), and Open-domain.
4.2 Choice of Evaluation Metrics
In addition to standard metrics like F1 Score (F1) and BLEU-1 (B1), the authors included LLM-as-a-Judge (J) to enhance measurement accuracy. These three metrics assess how closely the LLM’s output matches the ground truth.
Besides these, the authors also incorporated Token Consumption to measure how many tokens, on average, different methods need to retrieve from the memory database for each query (these tokens become LLM input), and Latency to measure the average time different methods take to process each query.
4.3 Experimental Results
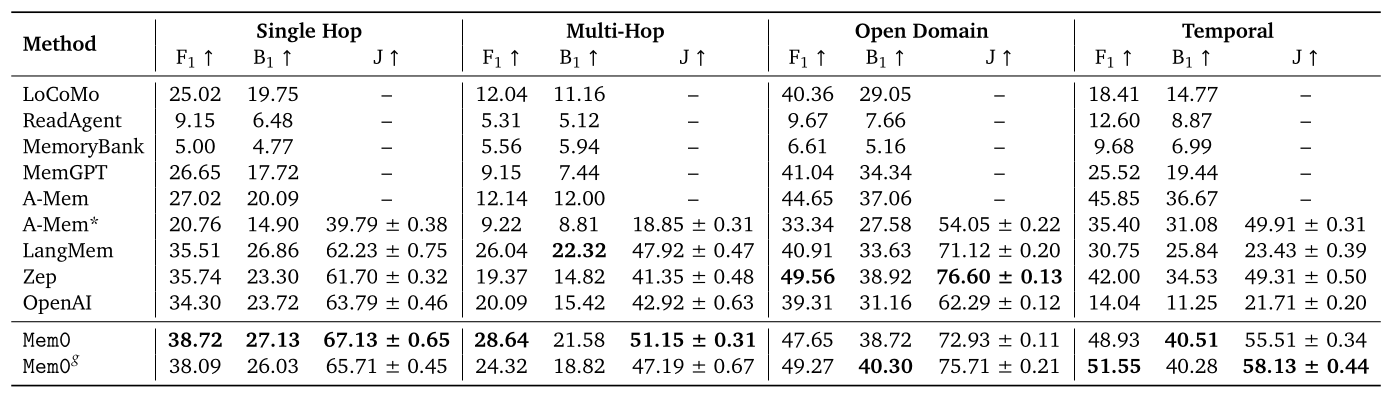
The experimental data in Table 1 is quite surprising. Mem0 not only achieved State-of-the-Art (SOTA) performance in Single-Hop, Multi-Hop, and Temporal categories but also surpassed the second-best method significantly across all three metrics. In the Open-domain category, while not SOTA, it was only slightly behind the top performer.
The validity of the LOCOMO benchmark has been discussed on Reddit. Some argue that the LOCOMO dataset has issues, with slight modifications to experimental setups reportedly allowing Zep to outperform Mem0 by 24%. Others believe that Mem0’s experimental setup was flawed, leading to its significant outperformance over other methods.
Additionally, a second noteworthy point is that Mem0g, despite incorporating a more complex graph-based structure for memory storage and more intricate Extraction and Update Phases compared to Mem0, only performed better than Mem0 in the Open-Domain and Temporal categories. The authors did not provide an in-depth analysis of why this was the case.
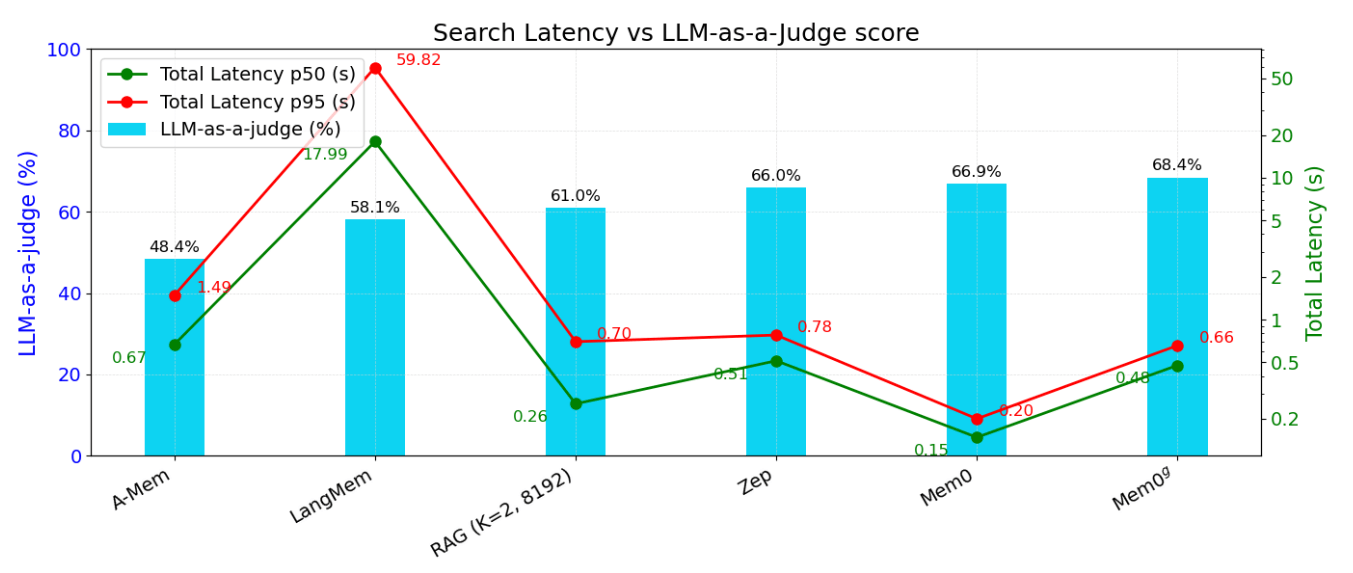
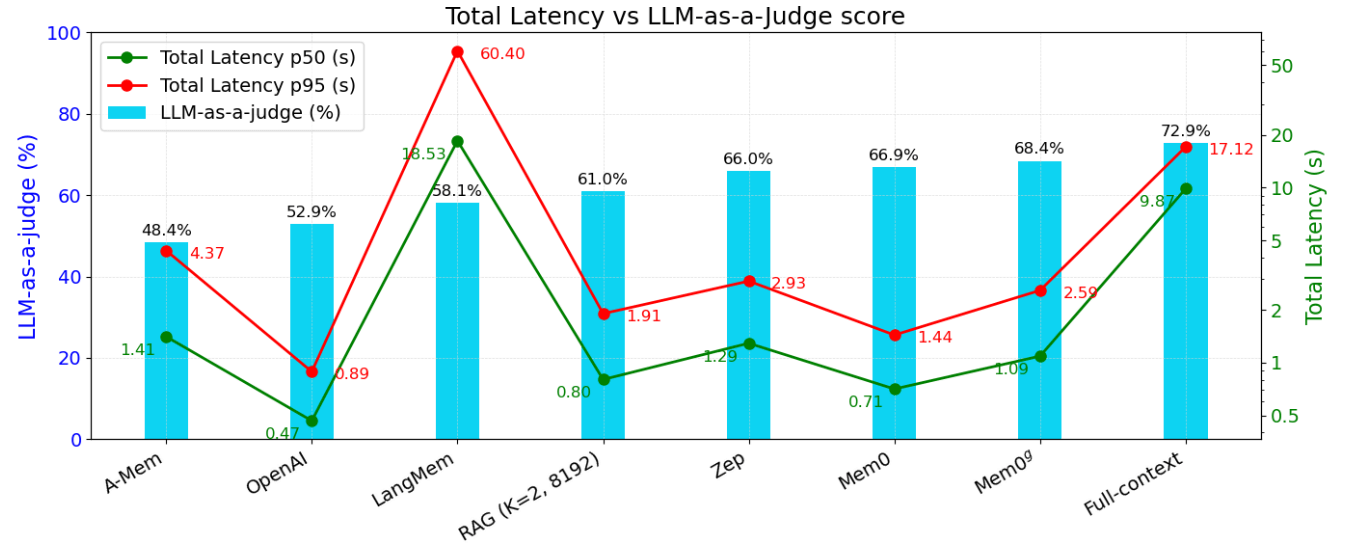
Figures 4a and 4b above show the LLM-as-a-Judge Score, Search Latency, and Total Response Latency for different methods across the entire LOCOMO dataset. It’s evident that Mem0 and Mem0g demonstrate a strong advantage in terms of latency and LLM-as-a-Judge scores.
5 Conclusion
This article introduced the paper “Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory”, explaining how Mem0 and Mem0g manage long-term memory by processing raw conversation logs through Extraction and Update Phases, and how Mem0g utilizes a graph-based structure to store memories.
On the LOCOMO test dataset chosen by the authors, we observed that Mem0 and Mem0g outperformed baseline methods in multiple aspects like Single-Hop and Multi-Hop tasks. We also saw their latency advantages compared to other methods.
The paper does not detail the prompts used in Mem0 and Mem0g. However, two prompt files can be found on GitHub for interested readers to explore:
- Mem0: mem0/configs/prompts.py
- Mem0g: mem0/graphs/utils.py