MemGPT: Towards LLMs as Operating Systems

1 Introduction
This article introduces the paper “MemGPT: Towards LLMs as Operating Systems”. MemGPT was published on arXiv by researchers from UC Berkeley in October 2023. As of May 14, 2025, it has accumulated 154 citations and is currently included in CoRR 2023.
When discussing perpetual conversation or long-term memory in LLMs, MemGPT is considered a classic work. The open-source project for MemGPT is now called Letta. More than just a project, it feels like it’s evolving into a startup company.
Furthermore, as of May 14, 2025, Letta has already garnered 16.4K stars on GitHub, indicating its significant popularity. When searching for open-source projects related to agent memory online, besides Mem0, Letta is another popular choice, even surpassing LangMem developed by LangChain.
As an AI engineer or researcher, if you’re not yet familiar with the concepts of Mem0 and LangMem, be sure to read these two articles:
This article serves as course notes for “LLMs as Operating Systems: Agent Memory” on DeepLearning.AI. It primarily focuses on introducing the MemGPT methodology itself, without delving into experimental results or other details. Interested readers are encouraged to consult the original paper for more information!
2 The Problem MemGPT Aims to Solve
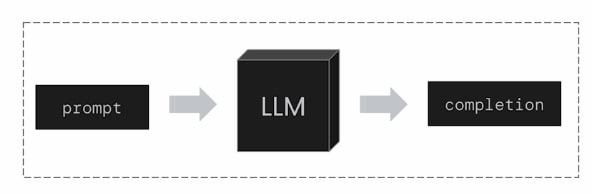
As shown in the image above, based on our prompt, an LLM generates a completion in an auto-regressive manner, essentially “continuing the text.” If this LLM powers a chatbot you’ve developed to solve customer issues, your prompt might include: customer information, chat history between the chatbot and the customer, external data, tools available to the chatbot, reasoning steps the chatbot has already taken, and observations, etc.
As the interaction time between the chatbot and the customer lengthens, it’s conceivable that the prompt can no longer accommodate so much information. Even if you use an LLM with a very large context window, you might find that as more information fills the context window, the LLM seems to start “forgetting” or losing context.
Therefore, a common challenge LLMs face during long-running conversational tasks is how to effectively manage “long-term memory.” This is precisely the problem that methods like Mem0 and LangMem address.
3 Core Concept of MemGPT
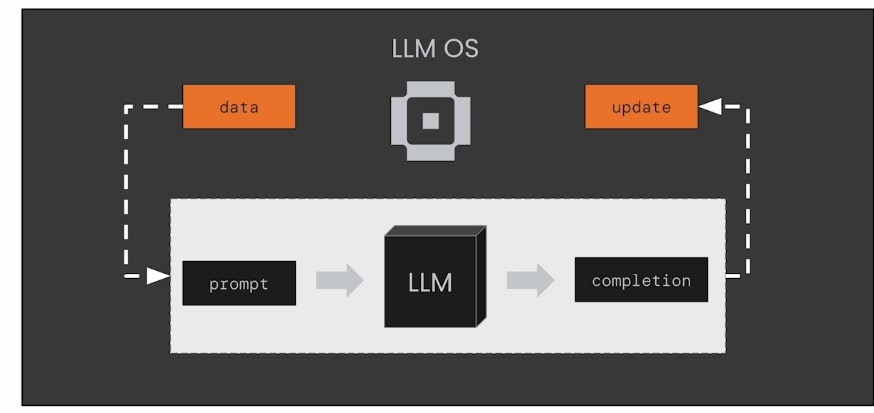
Similarly, MemGPT was created to tackle this issue! As illustrated above, the core idea of MemGPT is to enable an LLM to act like an operating system, managing its own state and deciding what information to place into the prompt.
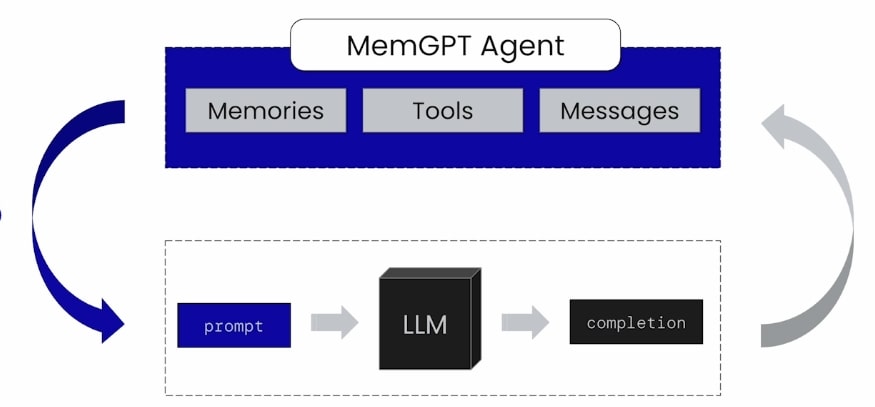
For example, as shown in the image, an agent’s current state can be represented by its memories, available tools, and message history. You can imagine the Agent State as holding all information related to the agent.
The LLM model is what gives the agent its conversational abilities. However, the LLM’s context window has limitations, preventing us from putting the entire Agent State into the prompt.
To empower MemGPT with this capability, it was designed with the following four features:
- Self-Editing Memory: The agent can modify its own memory content through tool calling.
- Inner Thoughts: Before each output, the agent can engage in some thinking, and these thought processes are not shown to the user.
- Every Output as a Tool Call: All outputs from the agent are tool calls (except for inner thoughts). Even when sending a message to the user, it must use the
send_message()tool. - Looping via Heartbeats: Whenever the agent makes a tool call, it can specify the
request_heartbeatparameter to decide whether to invoke itself again with the tool’s execution result to get a new output.
4 MemGPT’s Memory Management Approach
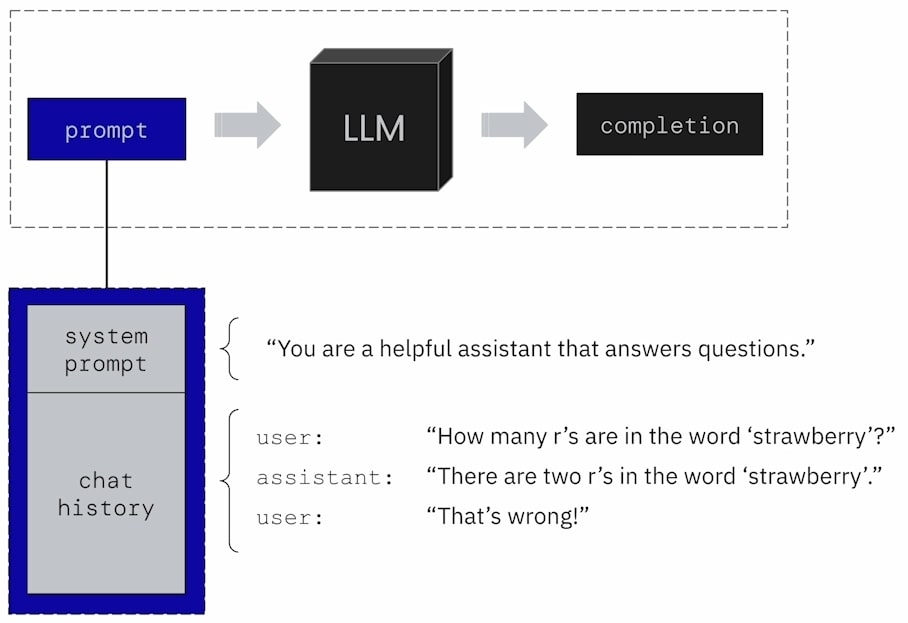
As shown above, in a typical agent, the prompt usually consists of a “System Prompt” plus “Chat History.” In MemGPT, to achieve effective Prompt Compilation, the prompt’s composition is divided into several special reserved sections, each serving to store different types of information.
4.1 MemGPT’s Core Memory
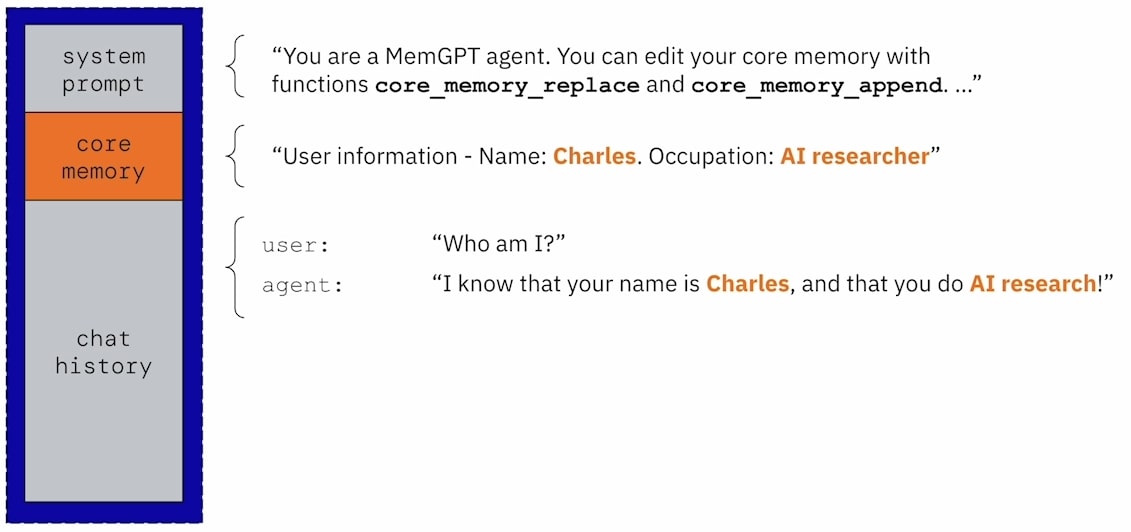
MemGPT designates a Core Memory section within the prompt to store a small amount of the most crucial information. Core Memory can be divided into multiple blocks, each storing different information (e.g., user information, the agent’s persona, etc.).
To make the LLM aware of this section, information about Core Memory is included in the System Prompt. This includes that Core Memory can be modified using tools (e.g., core_memory_replace, core_memory_append).
Upon receiving user input, MemGPT first performs an inner thought process before generating an output. As mentioned earlier, all of MemGPT’s outputs are tool calls. Therefore, if MemGPT deems certain information worthy of being recorded in Core Memory during its inner thought, that output will be a core_memory_append tool call to save this information to Core Memory.
4.2 MemGPT’s Chat History
As shown in the image above, besides Core Memory, MemGPT also allocates a section in the prompt for Chat History. This Chat History is the multi-turn conversation between MemGPT and the user.
When the conversation content exceeds the size limit of the Chat History section, MemGPT will use the LLM to summarize a chunk of the Chat History, and this Chat Summary will replace the original chunk.
The size of this chunk can be controlled by desired_memory_token_pressure (letta/letta/settings.py). The calculate_summarizer_cutoff function (letta/letta/llm_api/helpers.py) uses this parameter to calculate how many tokens need to be summarized.
In MemGPT, the Chat Summary generated by the LLM is actually a Recursive Summary, because when the LLM generates a summary for a chunk, the chunk itself might contain a previous Chat Summary.
4.3 MemGPT’s Recall Memory
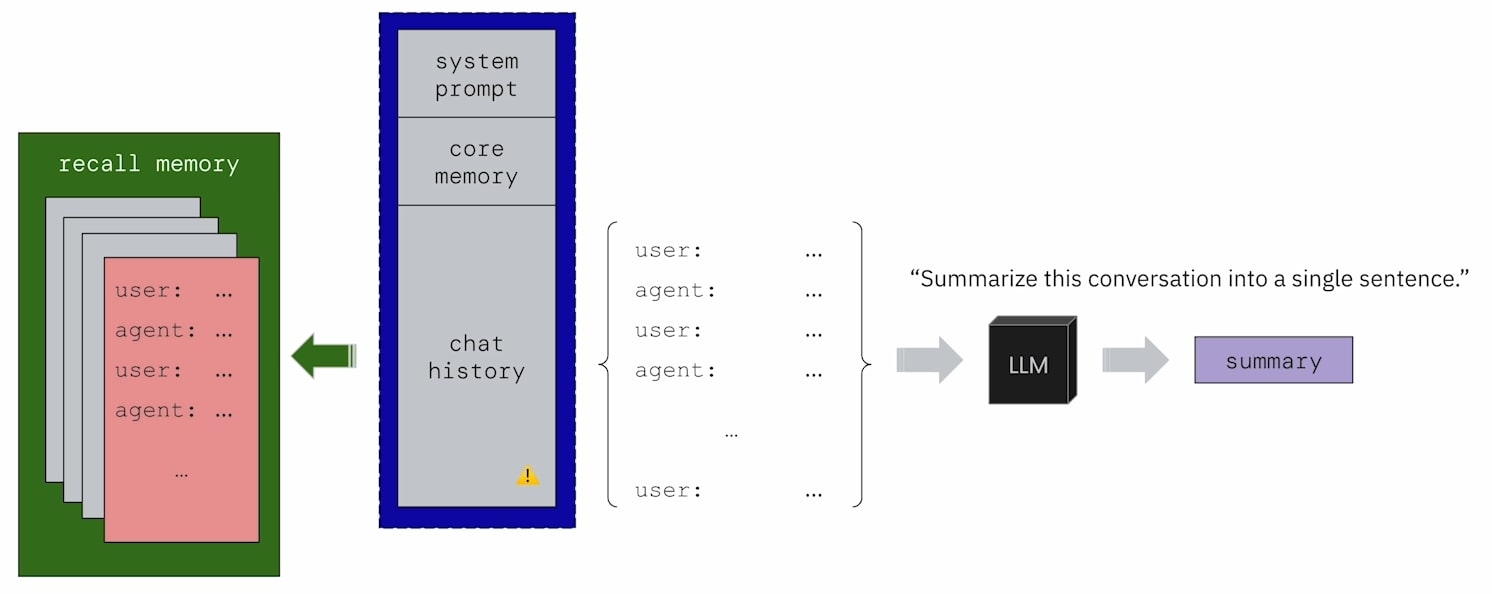
Continuing from MemGPT’s Chat History, summarized chunks are not discarded but are stored in an external database called Recall Memory. In other words, no part of MemGPT’s conversation history with the user is lost; it’s all preserved in Recall Memory.
Since it’s a type of memory, it must be searchable. Correct! MemGPT’s System Prompt also informs the LLM that it can use the conversation_search tool to retrieve information from Recall Memory.
4.4 MemGPT’s Archival Memory

Just as Chat History has its external database, Recall Memory, to store information that doesn’t fit, Core Memory also has its own external database for overflow. This is called Archival Memory.
During MemGPT’s interaction with a user, if it decides a piece of information (e.g., user preferences) needs to be remembered, but Core Memory (e.g., the “User” block in Core Memory) is full, MemGPT can take one of two actions based on the importance of the information:
- The new information is very important: Move existing content from Core Memory to Archival Memory, then store the new important information in Core Memory.
- The new information is not as important: Store the new information directly into Archival Memory.
Besides serving as extra external storage for Core Memory, Archival Memory is also where external data for RAG (Retrieval-Augmented Generation) applications is stored. That is, if a user wants MemGPT to answer questions based on a PDF document, that PDF will be stored in Archival Memory.
Naturally, MemGPT’s System Prompt will also tell the LLM it can use the archival_memory_search tool to find information in Archival Memory.
4.5 MemGPT’s A/R Stats
So far, we’ve learned that MemGPT has two external databases: Archival Memory and Recall Memory, serving as additional storage for Core Memory and Chat History, respectively.
However, since the information in these two external storage spaces is not directly in MemGPT’s context, how does MemGPT know their status?
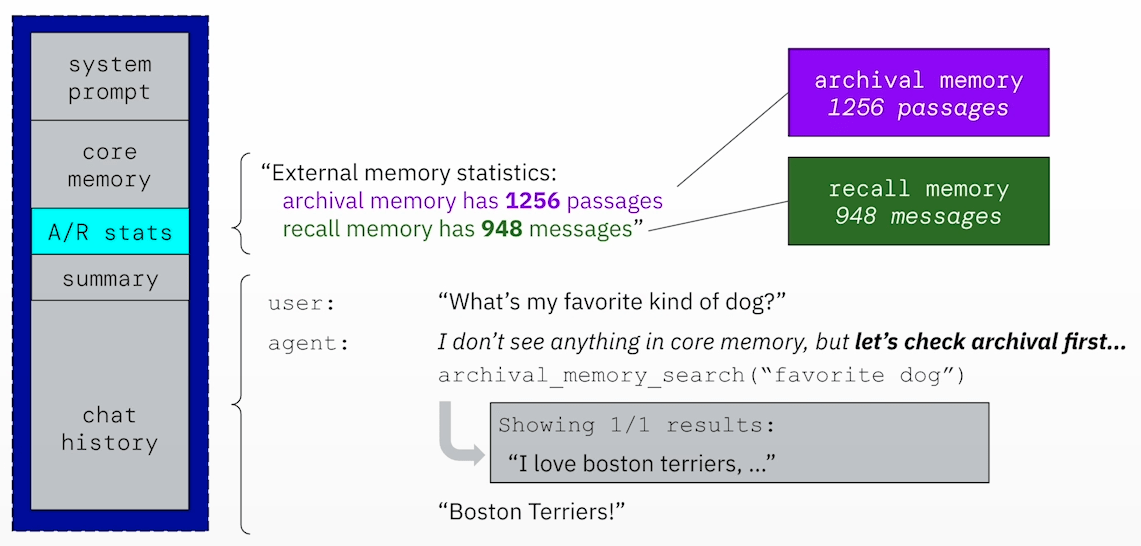
In MemGPT, an A/R Stats section is included in the context. This section records the current amount of information in Archival and Recall Memory, allowing MemGPT to determine if it should search these two memories.
For example, when Archival and Recall Memory contain some information, A/R Stats lets MemGPT know it can search them:
5 Conclusion
This article introduced the paper “MemGPT: Towards LLMs as Operating Systems,” with content primarily based on notes from the “LLMs as Operating Systems: Agent Memory” course on DeepLearning.AI.
The challenge MemGPT aims to address is Prompt Compilation: how to distill large amounts of information from the Agent State into the prompt so that the LLM can successfully generate accurate output based on that prompt.
To overcome this challenge, MemGPT divides the LLM’s context window (Short-Term Memory) into multiple sections, including System Prompt, Core Memory, A/R Stats, Chat Summary, and Chat History. It also designs two types of Long-Term Memory: Archival Memory and Recall Memory, serving as additional storage for Core Memory and Chat History, respectively.
Furthermore, MemGPT enables the LLM to operate as a ReAct-Based Agent, using a continuous loop of Thinking, Action (Tool Calling), Thinking, Action (Tool Calling)…, to search and refine information from different memory stores.
Finally, from a Long/Short-Term Memory perspective, MemGPT is similar to LangMem and Mem0 in that they all propose their own methods for Long-Term Memory. However, MemGPT uniquely places more emphasis on the design and content of Short-Term Memory (the LLM’s context window).