MIRIX: Multi-Agent Memory System for LLM-Based Agents

1 Introduction
This article introduces the paper MIRIX: Multi-Agent Memory System for LLM-Based Agents. As the title suggests, MIRIX is a paper related to LLM Memory, similar to LangMem, Mem0, and MemGPT which we have previously discussed. The MIRIX paper was published on arXiv in July 2025. The authors have open-sourced the code on GitHub, and you can also download the software developed based on this paper directly from the official MIRIX website.
Interestingly, the official MIRIX website not only provides software downloads but also displays the benchmark results of multiple methods on LOCOMO and ScreenshotVQA. It’s clear that the method proposed by MIRIX not only surpasses popular methods like LangMem, Mem0, and Zep but is also one of the few methods that can support images as LLM Memory.
2 The MIRIX Method Design
The design of the MIRIX method can be broadly divided into the following three aspects:
- Memory Component Design
- Memory Update Workflow
- Conversation Workflow
2.1 Memory Component Design
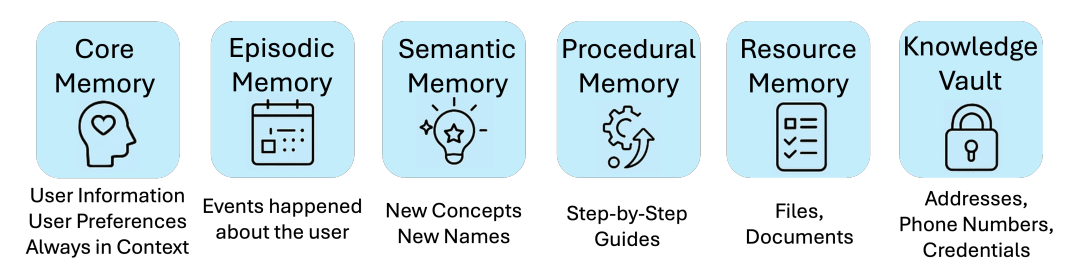
As shown in the figure above, MIRIX defines a total of 6 Memory Components. These components appear to be a synthesis of the memory components designed in LangMem and MemGPT. For instance, LangMem also includes Episodic, Semantic, and Procedural Memory, while Core Memory and Resource Memory correspond to Core Memory and Archival Memory in MemGPT.
Here is a breakdown of the information stored in each Memory Component:
- Core Memory: Stores the most crucial information. Following the approach of MemGPT, Core Memory contains two sections:
personaandhuman. Thepersonasection holds the agent’s identity, tone, and expected behavior, while thehumansection stores information about the user’s identity. - Episodic Memory: Stores timestamped events. Each entry consists of the following:
event_type: e.g.,user_message,inferred_result, orsystem_notificationsummary: A brief description of the eventdetails: A detailed description of the eventactor: The initiator of the event, can beuserorassistanttimestamp: e.g.,2025-03-05 10:15
- Semantic Memory: Stores established facts or general information. For example, “Harry Potter is written by J.K. Rowling” or “John is a friend of the user who enjoys jogging and lives in San Francisco.” Information in Semantic Memory does not expire unless specifically removed or modified. Each entry consists of:
namesummarydetailssource
- Procedural Memory: Stores information that helps the agent solve complex and specific tasks. For example, few-shot demonstrations or step-by-step instructions provided to the agent. Each entry consists of:
entry_type: Can beworkflow,guide, orscriptdescription: A description of the task to be completedsteps: Step-by-step instructions to complete the task
- Resource Memory: Stores all information required by the user that does not fall into any of the above categories. Each entry consists of:
titlesummaryresource_type: e.g.,doc,markdown,pdf_text,image,voice_transcriptfull content/excerpted content
- Knowledge Vault: Stores confidential and sensitive information, such as the user’s address, contact information, and API keys. Each entry consists of:
entry_type: e.g.,credential,bookmark,contact_info,api_keysource: e.g.,user_provided,githubsensitivity:low,medium,highsecret_value
2.2 Memory Update Workflow
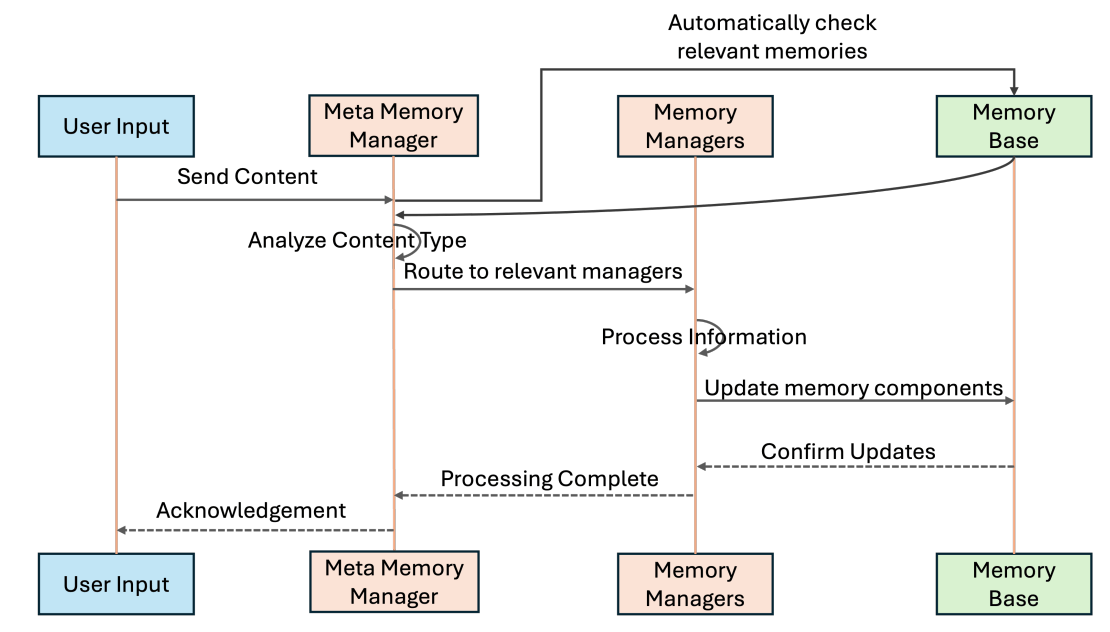
The figure above illustrates how memory is updated in the MIRIX method. Based on the user’s input, relevant information is first retrieved from the 6 Memory Components. The Meta Memory Manager then determines which Memory Component the current user input belongs to and assigns the update task to the corresponding Memory Manager.
2.3 Conversation Workflow
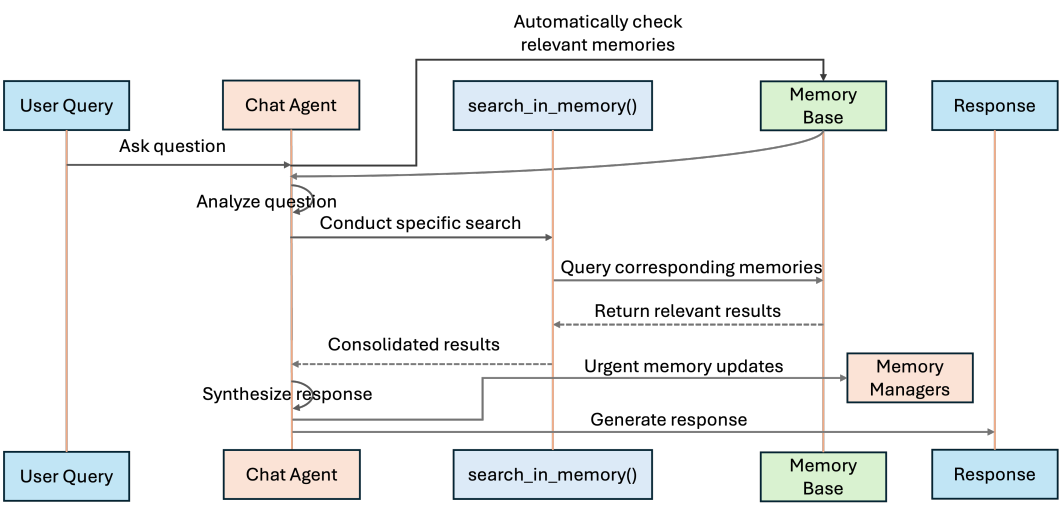
Once the MIRIX Agent has collected sufficient memory, it can begin to answer the user’s questions based on that memory. The actual conversation process of the MIRIX Agent is shown in the figure above. Based on the user’s input, relevant (but concise, not all details) information is first retrieved from the Memory Base across the 6 Memory Components. The Chat Agent then determines which Memory Component should handle the current input and triggers a “Conduct Specific Search” to retrieve more detailed and complete information from that specific component. Finally, it generates the final response based on this retrieved information. If the Chat Agent determines that the user’s input requires a memory update, it can directly trigger the specific Memory Manager to update the relevant Memory Component.
3 Experimental Results
In the experimental phase, the MIRIX paper used two datasets—ScreenshotVQA and LOCOMO.
ScreenshotVQA is a multimodal LLM memory dataset created for this paper. This benchmark includes 5886, 18178, and 5349 screen captures collected from 3 users over 1 day, 20 days, and 1 month, respectively, along with 11, 21, and 55 corresponding questions. LOCOMO, on the other hand, is a text-only LLM memory dataset, containing 600 conversations, with each conversation averaging 26K tokens and 200 corresponding questions.
For the evaluation metric, the authors designed an LLM-as-a-Judge method based on GPT-4.1. Additionally, the MIRIX Agent used gemini-2.5-flash-preview-04-17 and gpt-4.1-mini as its backbone models for the ScreenshotVQA and LOCOMO datasets, respectively.

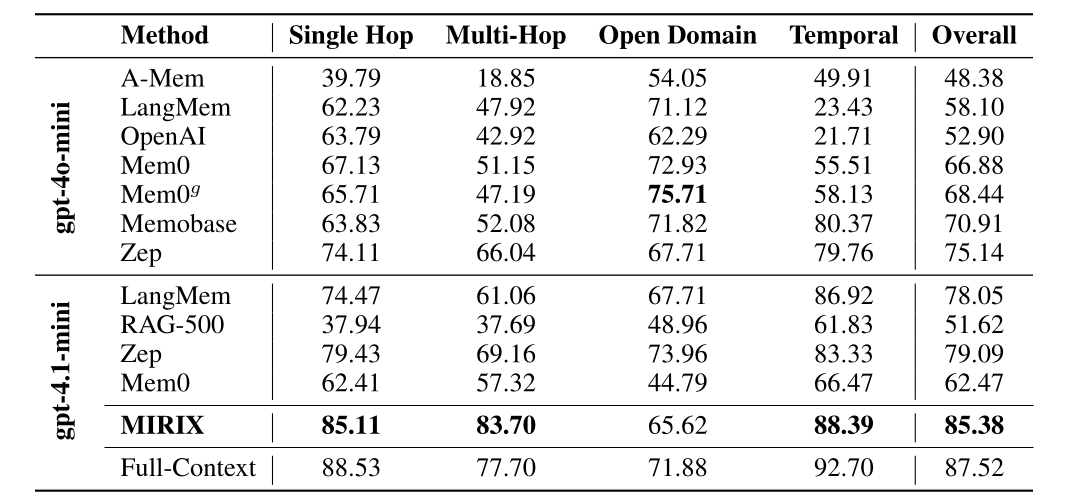
From the experimental results above, it is clear that the MIRIX Agent achieved outstanding performance on both datasets!
4 Conclusion
This article has introduced the LLM Memory method proposed in the MIRIX paper. After reading this paper, what impressed me the most was the 6 Memory Components defined in MIRIX. They cover almost every conceivable usage scenario and address the shortcomings in memory component design found in LangMem, Mem0, and MemGPT. As for the Memory Update Workflow and Conversation Workflow, I found them to be less novel. However, MIRIX’s approach of designing a specific Memory Agent for each component has led to better performance than other baseline methods, suggesting that its prompt design is likely worth studying.