Deep Dive into MRAG: Solving Temporal Reasoning in RAG with Symbolic Logic (EMNLP 2025)

1 Introduction
If you’ve worked with RAG (Retrieval-Augmented Generation), you’ve likely encountered this exact scenario:
You ask a ChatBot: “Who was the UK Prime Minister in 2019?” It confidently replies: “Boris Johnson.” That seems correct.
But if you ask: “Who was the Prime Minister before 2019?” It might still retrieve documents containing “2019” and “Boris Johnson” and tell you it was still Johnson. At this point, your User Experience (UX) is completely ruined.
I recently read a paper from EMNLP 2025 (Findings) titled “MRAG: A Modular Retrieval Framework for Time-Sensitive Question Answering”, which strikes right at the heart of this pain point. The biggest takeaway for me wasn’t the use of a new LLM, but rather the fact that it identifies a massive blind spot in current RAG architectures: We rely too heavily on the semantic understanding of embedding models, forgetting that they fundamentally do not understand temporal logic.
In this article, I will give you a hardcore breakdown of this paper and explore how to save your RAG system through “modularity” and “symbolic logic.”
- Pain Point: Existing retrievers (like Contriever, BM25) only perform “keyword matching” and cannot understand temporal logic like .
- Solution: MRAG proposes a training-free modular framework that disentangles “semantic understanding” from “temporal reasoning.”
- Core Technology: Utilizes LLMs for fine-grained evidence summarization combined with Symbolic Algorithms for hybrid ranking.
- Performance: On the new TempRAGEVAL benchmark, it significantly outperforms current SOTA models, proving that “Neural Networks + Symbolic Logic” is the right direction for complex reasoning.
2 Why Does RAG Turn from “Smart” to “Stupid”?
Before diving into the MRAG architecture, let’s discuss why this problem is so difficult to solve.
Existing SOTA retrievers (whether Dense Retrievers or BM25) essentially calculate “similarity.” When you input “Who is the UK PM in 2019?”, the model converts this sentence into a Vector and then searches a Vector DB for the closest documents.
Here lies the “devil in the details”: The model treats “2019” as just another ordinary token, much like “Apple” or “Banana.”
- The String Matching Trap: If a document says “In 2019…”, the model can find it.
- Logical Collapse: If you ask “Who was the PM in May 2021?”, but the correct document only says “Boris Johnson (2019–2022)”, the model gets confused because it doesn’t understand the interval logic of . Instead, it might fetch news containing the string “May 2021” that is completely irrelevant.
Simply put, Neural Networks are great at fuzzy semantic matching (vibes), but very poor at precise numerical logic.
3 MRAG’s Solution: Divide and Conquer
The core insight of MRAG (Modular Retrieval Augmented Generation) is brilliant: Since embedding models can’t learn math, let’s stop forcing them to.
The authors propose a Disentanglement strategy:
- Semantics: Handled by Neural Networks (what they are good at).
- Temporality: Handled by deterministic Symbolic Algorithms.
Here is what the end-to-end process looks like when broken down:
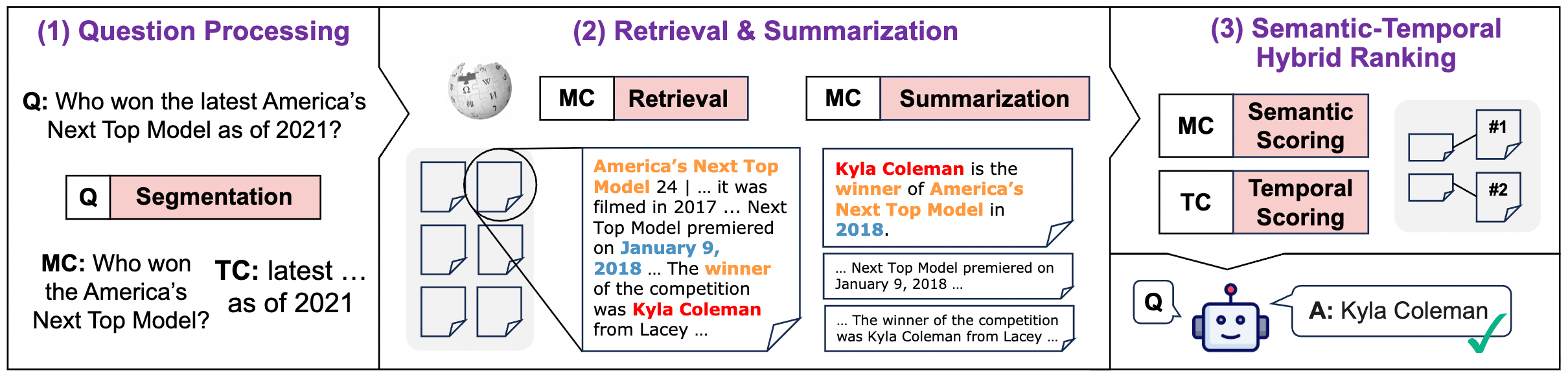
Let’s break down this pipeline step-by-step.
3.1 Phase 1: Question Processing
First, the system does not directly feed the entire question to the retriever. Instead, it decomposes the user’s query into two independent signals:
- Main Content (MC): Removes temporal constraints, keeping only the core entities.
- Query: “Who is the UK PM as of 2019?”
- MC: “Who is the UK PM?”
- Purpose: Retrieve all related entities first, regardless of the time, to ensure high Recall.
- Temporal Constraint (TC): Extracts specific timestamps and relations.
- TC: Relation=“as of”, Timestamp=“2019”.
This step is usually combined with Regex or NLP tools (like spaCy), which are more robust than using an LLM alone, as we want to avoid LLM hallucinations here.
3.2 Phase 2: Fine-grained Evidence Processing (Retrieval & Summarization)
A common mistake in traditional RAG is retrieving an entire “Chunk” (paragraph). A single paragraph might contain decades of history for an entity, leading to Temporal Mixing.
MRAG’s approach is:
- Broad Retrieval: Use the MC to fetch Top-K (e.g., 100) documents.
- Fine-grained Segmentation: This is the key. The system splits documents into “Single Fact Units.”
- The authors recommend using LLM Summarization: Let the LLM read the paragraph and generate a “concentrated sentence” ensuring that this sentence contains only one clear timestamp and fact.
This results in a clean set of evidence pairs, significantly reducing noise.
3.3 Phase 3: Semantic-Temporal Hybrid Ranking (The “Secret Sauce”)
This is the soul of MRAG. The system scores each piece of evidence twice:
- Semantic Score (): Calculated using an Embedding model for similarity.
- Temporal Score (): No neural networks are used. It is based on rule-based Spline Functions.
The authors designed 6 types of mathematical curves to correspond to different temporal intents:
| Intent | Relation | Physical Meaning |
|---|---|---|
| Last (Find newest) | before | Before the cutoff, the closer the better (Recency Bias). |
| First (Find earliest) | after | After the starting point, the closer to the start the better. |

The final score formula is:
This multiplication formula is simple but effective, providing a “Veto Power”:
- If the time is completely wrong (), even if the semantics are highly relevant (e.g., a perfect keyword match), the total score remains 0.
- This directly solves the classic RAG problem of “keyword match but wrong year.”
4 Experimental Results: A Dominant Lead
To verify this architecture, the authors created a new benchmark called TempRAGEVAL. They did something quite challenging: they introduced Temporal Perturbations.
For example, changing “Who was PM in 2019?” to “Who was PM before 2020?”.
The results were telling:

- Traditional Methods Collapse: Even powerful models like GEMMA (an LLM-based Reranker) saw a significant drop in performance when facing perturbations, confirming they are merely performing advanced keyword matching.
- MRAG Thrives: MRAG not only withstood the perturbations but achieved an Evidence Recall (ER@5) of 59.2%, far exceeding GEMMA’s 45.3%.
Interestingly, on the TimeQA dataset (which contains more niche, long-tail knowledge), MRAG’s advantage was even greater. This suggests that when an LLM cannot rely on “memorizing” training data to answer, precise retrieval logic becomes the only lifeline.
5 Conclusion
- Don’t Idolize End-to-End: In the LLM era, it’s easy to get lazy and throw everything into the Context Window for the model to learn. But MRAG proves that for precise logic (math, time, code execution), stripping it away from the neural network and handing it to a deterministic Symbolic System often yields better results. UniversalRAG applies a similar “disentanglement” philosophy to a different axis of the retrieval problem — modality and granularity instead of time.
- Architecture Design > Model Size: This paper didn’t train a massive model with hundreds of billions of parameters; instead, it solved the problem through elegant Pipeline design. This is where engineers provide real value.
- Neuro-Symbolic AI is the Future: This hybrid architecture—where the neural network handles semantics and symbolic logic handles reasoning—will likely be the mainstream direction for building complex Agents in the future.
If you are struggling with “hallucinations” or “logical errors” in your RAG system, consider MRAG’s approach and try disentangling your problem.