PLAN-AND-ACT: Improving Planning of Agents for Long-Horizon Tasks

1 Introduction
This article introduces the paper PLAN-AND-ACT: Improving Planning of Agents for Long-Horizon Tasks. PLAN-AND-ACT was primarily proposed by researchers from UC Berkeley and published on Arxiv in March 2025.
PLAN-AND-ACT introduces a Planner-Executor framework and a data synthesis method to train Large Language Models (LLMs), enhancing their planning and execution capabilities.
As shown in the diagram below, PLAN-AND-ACT mainly consists of a Planner and an Executor. The Planner first generates a “plan” based on the user’s task. This “plan” is essentially a series of higher-level goals. The Executor then translates this plan into specific actions within the environment.
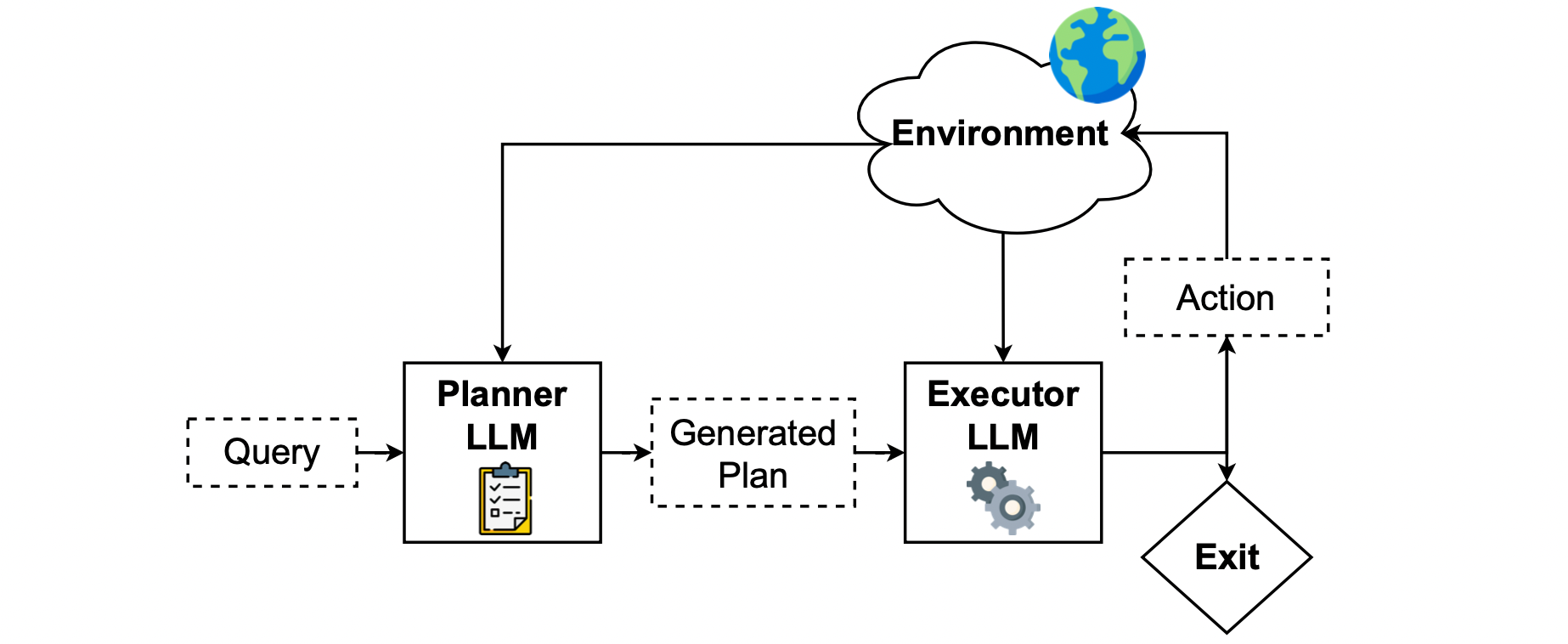
2 The Problem PLAN-AND-ACT Aims to Solve
The core problem PLAN-AND-ACT aims to address is the planning capability of LLMs. Current LLMs face the following challenges in planning:
- LLMs often struggle to break down high-level user goals (e.g., “Book me a flight to New York”) into concrete, actionable plans (e.g., “Open the airline website,” “Enter travel dates,” etc.).
- Even if LLMs can generate a plan, as tasks become longer and more complex, the number of steps in the plan increases. This makes it difficult for LLMs to keep track of completed steps and pending ones.
- Even if an LLM can track a long plan, real-world environments are often dynamic, random, and unpredictable. An LLM likely cannot create a perfect plan from the start and follow it through to the end. Instead, it must dynamically adjust the plan based on feedback from the environment.
- Returning to the inherent capabilities of LLMs, due to the lack of high-quality training data related to planning, LLMs are not inherently trained to be planners.
3 The Solutions Proposed by PLAN-AND-ACT
To tackle these four challenges in LLM planning, PLAN-AND-ACT proposes two solutions:
- For problems (1)-(3), it introduces the PLAN-AND-ACT framework, which separates the Planner and Executor. The Planner generates the plan, and the Executor is responsible for carrying it out.
- For problem (4), it proposes a pipeline for generating planning-related synthetic data, regardless of whether ground truth is available. This synthetic data can then be used to train the Planner.
4 The PLAN-AND-ACT Framework
The core idea of the PLAN-AND-ACT framework is to avoid using a single model to handle both planning and execution tasks simultaneously. This is why it features a division of labor between the Planner and Executor. The authors explicitly state in the paper:
The PLAN-AND-ACT framework can theoretically operate in any environment. In the paper, the authors use the Web as an example environment. Because tasks given by users in a web environment are highly varied, and many tasks require multi-step planning, the authors believe the Web environment is well-suited for evaluating an LLM’s planning capabilities.
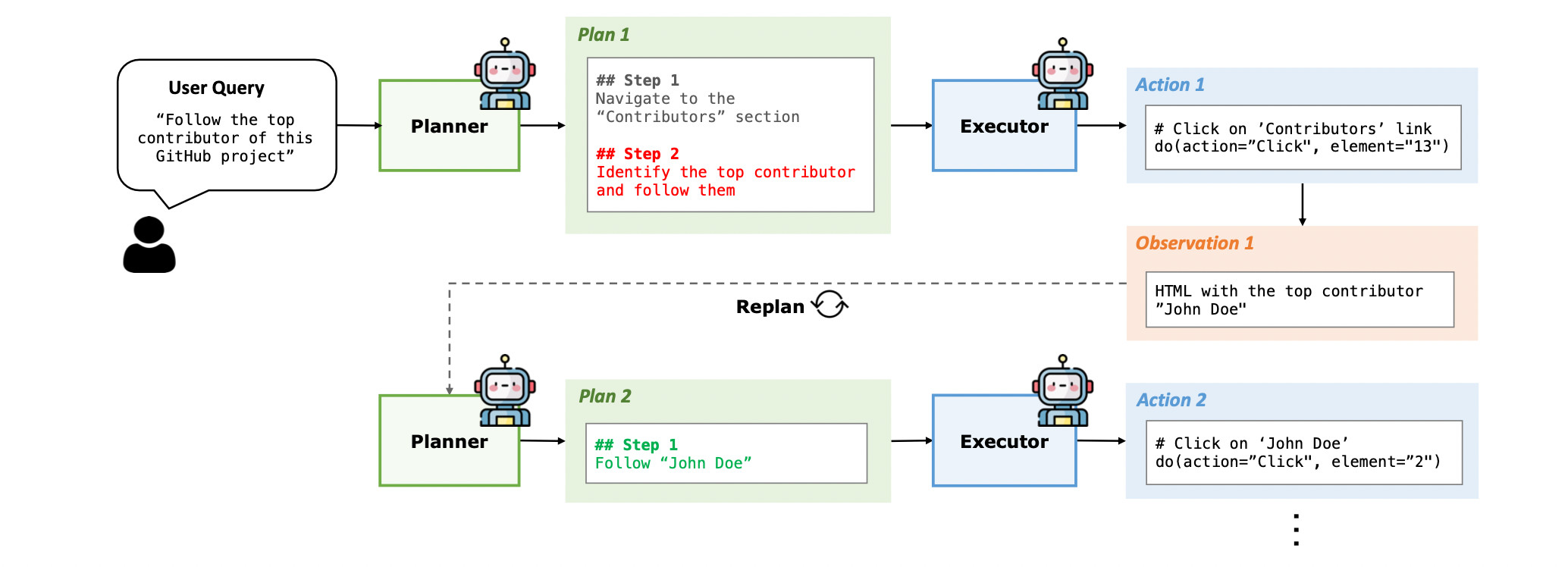
For example, in Figure 2 above, a user might ask, “Follow the top contributor of this GitHub project.” The Planner might then generate the following plan:
- Navigate to the Contributors section.
- Identify and follow the top contributor.
Upon receiving this plan, the Executor must take corresponding actions in the environment, such as:
- Clicking specific links.
- Filling in search fields with the correct content.
Since this is a web environment, the observations received by both the Planner and Executor will be HTML-formatted text.
4.1 Planner Prompt
System Prompt
## Goal You are the Global Planner agent, an expert plan generator for web navigation tasks. You will be proivded with the following information: - **User Query**: The web task that you are required to generate a global plan for. - **Initial HTML State**: The initial HTML state of the web page. You are responsible for analyzing the usery query and the initial HTML state to generate a structured, step-by-step global plan that outlines the high-level steps to complete the user query. The global plan that you generate shouldn’t directly describe low-level web actions such as clicks or types (unless necessary for clarity) but outline the high-level steps that encapsulate one or more actions in the action trajectory, meaning each step in your plan will potentially require multiple actions to be completed. Your global plan will then be handed to an Executor agent which will perform low-level web actions on the webpage (click, type, hover, and more) to convert your global plan into a sequence of actions and complete the user query. ## Expected Output Format The global plan you generate should be structured in a numbered list format, starting with ’## Step 1’ and incrementing the step number for each subsequent step. Each step in the plan should be in this exact format: ‘‘‘ ## Step N Reasoning: [Your reasoning here] Step: [Your step here] ‘‘‘ Here is a breakdown of the components you need to include in each step of your global plan as well as their specific instructions: - **Reasoning**: In this section, you should explain your reasoning and thought process behind the step you are proposing. It should provide a high-level justification for why the actions in this step are grouped together and how they contribute to achieving the overall goal. Your reasoning should be based on the information available in the user query (and potentially on the initial HTML state) and should guide the Executor agent in understanding the strategic decision-making process behind your global plan. - **Step**: In this section, you should provide a concise description of the global step being undertaken. Your step should summarize one or more actions as a logical unit. It should be as specific and concentrated as possible. Your step should focus on the logical progression of the task instead of the actual low-level interactions, such as clicks or types. ## Guidelines: - Ensure every action and reasoning aligns with the user query, the webpage at hand, and the global plan, maintaining the strict order of actions. - Minimize the number of steps by clustering related actions into high-level, logical units. Each step should drive task completion and avoid unnecessary granularity or redundancy. Focus on logical progression instead of detailing low-level interactions, such as clicks or UI-specific elements. - Provide clear, specific instructions for each step, ensuring the executor has all the information needed without relying on assumed knowledge. For example, explicitly state, ’Input ’New York’ as the arrival city for the flights,’ instead of vague phrases like ’Input the arrival city.’ - You can potentially output steps that include conditional statements in natural language, such as ’If the search results exceed 100, refine the filters to narrow down the options.’ However, avoid overly complex or ambiguous instructions that could lead to misinterpretation. ## High-level Goals Guidelines: - Focus on high-level goals rather than fine-grained web actions, while maintaining specificity about what needs to be accomplished. Each step should represent a meaningful unit of work that may encompass multiple low-level actions (clicks, types, etc.) that serve a common purpose, but should still be precise about the intended outcome. For example, instead of having separate steps for clicking a search box, typing a query, and clicking search, combine these into a single high-level but specific step like "Search for X product in the search box". - Group related actions together that achieve a common sub-goal. Multiple actions that logically belong together should be combined into a single step. For example, multiple filter-related actions can be grouped into a single step like "Apply price range filters between $100-$200 and select 5-star rating". The key is to identify actions that work together to accomplish a specific objective while being explicit about the criteria and parameters involved. - Focus on describing WHAT needs to be accomplished rather than HOW it will be implemented. Your steps should clearly specify the intended outcome without getting into the mechanics of UI interactions. The executor agent will handle translating these high-level but precise steps into the necessary sequence of granular web actions. ## Initial HTML State Guidelines: - Use the initial HTML of the webpage as a reference to provide context for your plan. Since this is just the initial HTML, possibly only a few of the initial actions are going to be taken on this state and the subsequent ones are going to be taken on later states of the webpage; however, this initial HTML should help you ground the plan you are going to generate (both the reasoning behind individual steps and the overall plan) in the context of the webpage at hand. This initial HTML should also help you ground the task description and the trajectory of actions in the context of the webpage, making it easier to understand the task. - You MUST provide an observation of the initial HTML state in your reasoning for the first step of your global plan, including the elements, their properties, and their possible interactions. Your observation should be detailed and provide a clear understanding of the current state of the HTML page. ## Formatting Guidelines: - Start your response with the ’## Step 1’ header and follow the format provided in the examples. - Ensure that each step is clearly separated and labeled with the ’## Step N’ header, where N is the step number. - Include the ’Reasoning’ and ’Step’ sections in each step.User Message
## User Query {user_query} ## Initial HTML State {initial_html_state} You MUST start with the ’## Step 1’ header and follow the format provided in the examples.
4.2 Executor Prompt
System Prompt
# Goal You are the Executor Agent, a powerful assistant can complete complex web navigation tasks by issuing web actions such as clicking, typing, selecting, and more. You will be provided with the following information: - **Task Instruction**: The web task that you are required to complete. - **Global Plan**: A high-level plan that guides you to complete the web tasks. - **Previous action trajectory**: A sequence of previous actions that you have taken in the past rounds. - **Current HTML**: The current HTML of the web page. Your goal is to use the Global Plan, the previous action trajectory, and the current observation to output the next immediate action to take in order to progress toward completing the given task. # Task Instruction: {intent} # Global Plan The Global Plan is a structured, step-by-step plan that provides you with a roadmap to complete the web task. Each step in the Global Plan (denoted as ’## Step X’ where X is the step number) contains a reasoning and a high-level action that you need to take. Since this Global Plan encapsulates the entire task flow, you should identify where you are in the plan by referring to the previous action trajectory and the current observation, and then decide on the next action to take. Here is the Global Plan for the your task: {global_plan}
4.3 Dynamic Planning
To make plans more adaptable to environmental changes, PLAN-AND-ACT incorporates a dynamic planning phase. As shown in Figure 2, whenever the Executor performs an action, the Planner will replan based on the original plan, the Executor’s action, and the observation provided by the environment.
I find this mechanism to be quite an intuitive approach in LLM planning methods, as real-world environments are certainly dynamic (e.g., a new ad window suddenly popping up on a webpage). If the Planner only generates a plan once and the Executor follows it to the end, errors are very likely to occur during the process.
In PLAN-AND-ACT, the Planner replans every time the Executor performs an action. While this approach keeps the plan up-to-date, it also incurs significant computational costs, greatly increasing the time it takes for the user to receive a response.
5 LLM-Based Synthetic Data Generation Pipeline
As stated in the paper (quoted above), the authors clearly mention that simply relying on prompting is far from sufficient to improve the planning and execution capabilities of LLMs (Planner & Executor) in a web environment. Fine-tuning the Planner and Executor is necessary!
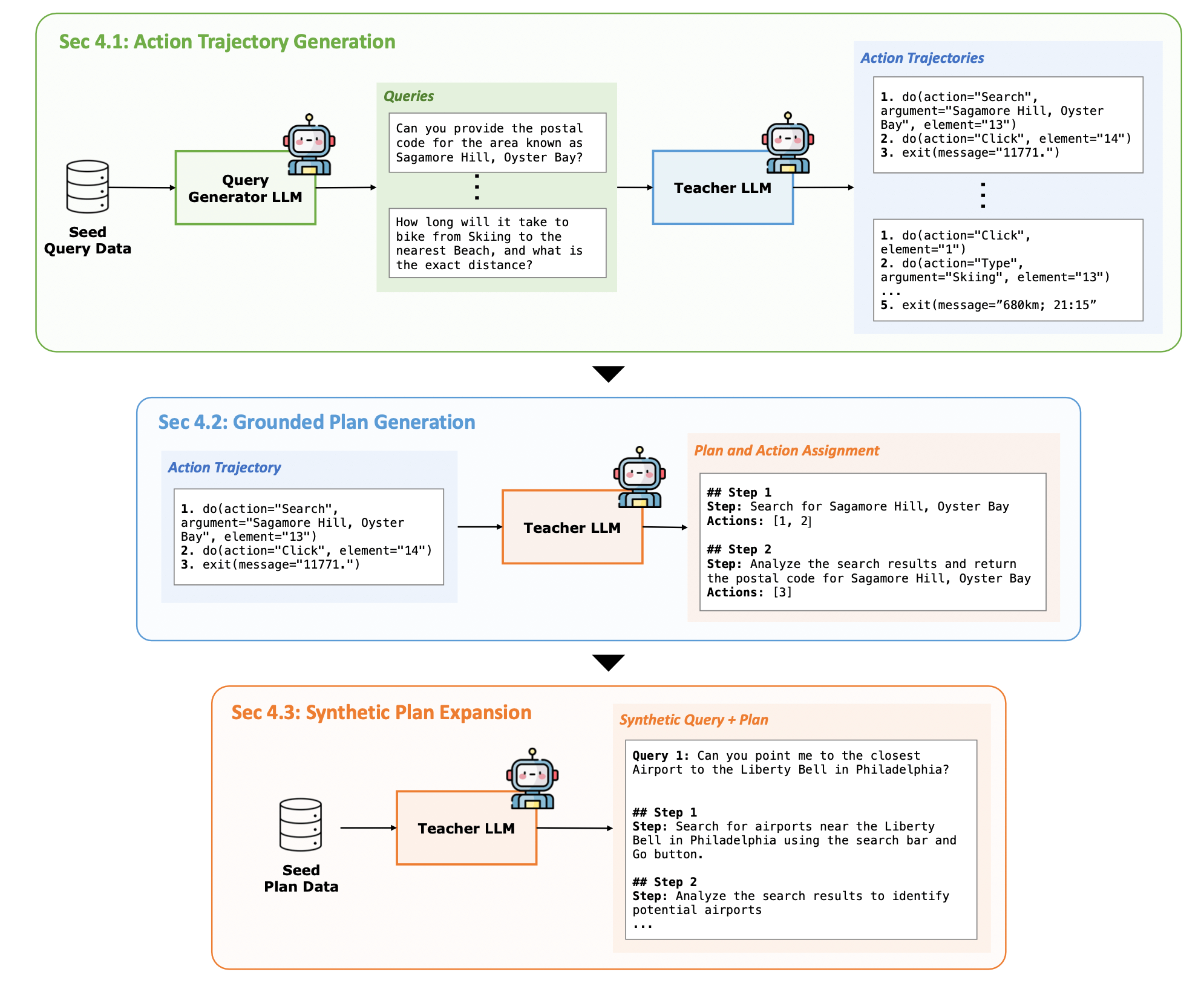
As shown in Figure 3 above, to fine-tune the Planner, the authors proposed a Synthetic Data Generation method to create training data for both the Planner and the Executor.
5.1 Generating Executor Training Data: Action Trajectory Generation
The authors built upon the method from WebRL (ICLR 2025 Poster). They randomly sample queries from training data as seed prompts and use an LLM to generate new, similar queries. Then, another LLM filters out queries that cannot be completed.
Next, these newly generated queries are given to a Teacher LLM to attempt, and the trajectory of each attempt is collected. Finally, an Outcome-Supervised Reward Model (ORM) scores these trajectories to filter out successful and failed ones.
Through this process, many trajectories that successfully solve tasks can be collected, serving as training data for the Executor.
5.2 Generating Planner Training Data: Grounded Plan Generation
An intuitive approach to generate training data for the Planner is to directly have a Teacher LLM generate a plan based on the user’s query.
However, this approach has clear drawbacks. Since the Teacher LLM doesn’t actually interact with the environment, the plans it generates may not align with the execution results provided by the environment. Furthermore, the Teacher LLM itself may not have been specifically pre-trained for such tasks, leading to poor quality plans.
The authors propose a simple solution, as shown in the second row of Figure 3. They prompt a Teacher LLM to act as a “Reverse Engineer,” converting already generated Execution Trajectories into structured plans.
To ensure that the generated plan truly corresponds to the actions in the trajectory, the Teacher LLM is required to associate each step in the plan with its corresponding action(s).
5.3 Generating More Planner Training Data: Synthetic Plan Expansion
Grounded Plan Generation is not a very efficient method. First, training data for the Executor (Query-Trajectory pairs) needs to be generated, and then these trajectories are reverse-engineered into plans.
The problem is that during the generation of training data for the Executor, the Teacher LLM often produces many failed trajectories, which impacts the final number of usable trajectories.
Moreover, for a successful trajectory with, say, 8 steps, this translates to 8 training samples for the Executor. However, for the Planner, it’s only 1 training sample (representing just 1 plan).
To generate Planner training data on a larger scale, the authors randomly sample some Query-Plan pairs from the already generated Planner training data to serve as seed prompts. They then use GPT-4o to generate more Query-Plan pairs based on these examples.
5.4 Increasing the Difficulty of Planner Training Data: Targeted Plan Augmentation
To increase the difficulty of the Planner’s training data, the authors set aside a portion of the training data as a validation set and test the Planner’s performance on it.
For failed samples where the Planner performs poorly, the authors use an LLM to classify training data samples and find those similar to these failed samples. These training samples, similar to the failed ones, are then used as seed prompts for an LLM to generate more similar samples.
6 PLAN-AND-ACT Experiments
6.1 Environment (Benchmark) Selection
- WebArena
- WebArena-Lite
- WebVoyager
6.2 Model Selection
- PLAN-AND-ACT Framework
- Planner and Executor: Fine-tuned separately based on the LLaMA-3.3-70B-Instruct model.
- Dynamic Replanning: Fine-tuned using LoRA on the LLaMA-3.3-70B-Instruct model.
- Synthetic Data Generation Pipeline
- User Query Generator (in Action Trajectory Generation), Grounded Plan Generation, Synthetic Plan Expansion: Used GPT-4o.
- Action Trajectory Generation: Used WebRL-Llama-3.1-70B as the Actor Model and ORM-Llama-3.1-8B as the Reward Model.
- Chain of Thought Reasoning for Planner and Executor: Used DeepSeek-R1-Distill-Llama-70B as the Teacher LLM.
6.3 Experimental Results
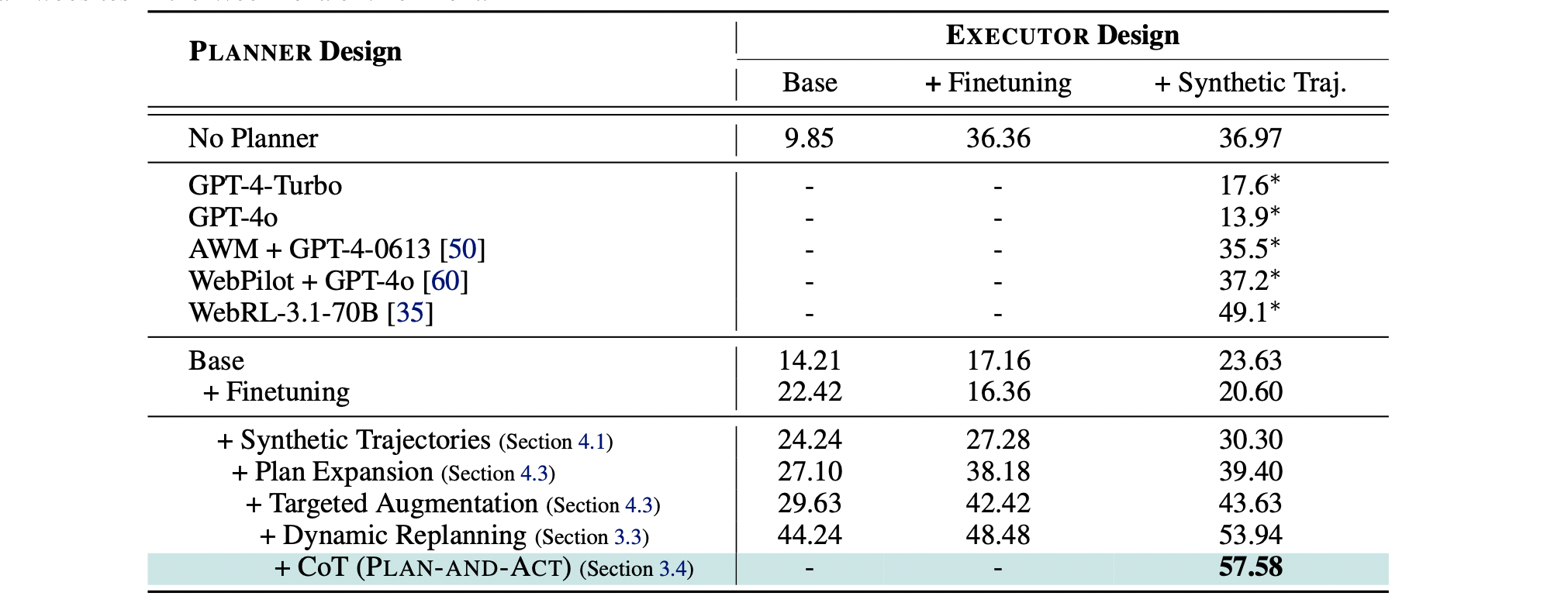
Regarding Executor Design:
- Base: LLaMA-3.3-70B-Instruct without fine-tuning.
- +Finetuning: LLaMA-3.3-70B-Instruct trained on the 1113 training samples provided by the WebArena-lite Environment.
- +Synthetic Traj.: LLaMA-3.3-70B-Instruct trained on the 1113 training samples from the WebArena-lite Environment + 923 synthetic samples.
From the No Planner results, it’s evident that even with training the Executor or increasing its training samples, performance remains poor. This highlights the necessity of the Planner.
Adding a Base Planner (LLaMA-3.3-70B-Instruct) does improve overall performance when the Executor is not trained (from 9.85 to 14.21). However, surprisingly, it performs poorly when the Executor is trained (e.g., dropping from 36.36 to 17.16 and from 36.97 to 23.63). This phenomenon is primarily because the fine-tuned Executor is misaligned with the non-fine-tuned Planner. In other words, the fine-tuned Executor now prefers a specific form of plan rather than the original type of plan.
Interestingly, even after Base Planner + Finetuning, the overall performance didn’t improve much. The authors believe this is because the Planner was only fine-tuned on the 1113 training samples provided by the WebArena-lite Environment, leading to overfitting.
Finally, when the Planner was trained on Synthetic Data, and Dynamic Replanning along with CoT Reasoning were added, the overall performance significantly improved.
7 Conclusion
This article introduced the PLAN-AND-ACT: Improving Planning of Agents for Long-Horizon Tasks paper, explaining how to design a collaborative Planner and Executor framework for LLM planning tasks. More importantly, it detailed how a Synthetic Data Generation Pipeline can be used to create training data for both the Planner and Executor, and how training them can further enhance performance.