Pre-Act: Multi-Step Planning and Reasoning Improves Acting in LLM Agents

1 Introduction
This article introduces the paper “Pre-Act: Multi-Step Planning and Reasoning Improves Acting in LLM Agents,” published on arXiv in May 2025 by Uniphore.
2 The Problem Pre-Act Aims to Solve
In the ReAct method, the Large Language Model’s (LLM) single-step reasoning (or “thinking”) focuses only on the immediate next action, not on a sequence of future actions. This approach leads to ReAct performing poorly on tasks requiring long-term planning.
3 Pre-Act’s Proposed Solution
Pre-Act enables the LLM to generate a detailed plan during each “thinking” step. This plan primarily includes “steps already executed” and “steps to be executed next.”
For example, given an input task, Pre-Act’s first “thinking” phase generates a plan with N steps. Each step describes what action to take (essentially, which tool to use), and the final step uses the “Final Answer” tool to output the ultimate response. After each “thinking” phase, Pre-Act outputs an action (represented in JSON format). The system executes this action and feeds the resulting observation back into the context.
Subsequently, during its second “thinking” phase, Pre-Act regenerates the plan based on the content in the context (the previous plan, action, and observation). The new plan outlines what previous thinking and actions have accomplished and modifies the subsequent steps accordingly.
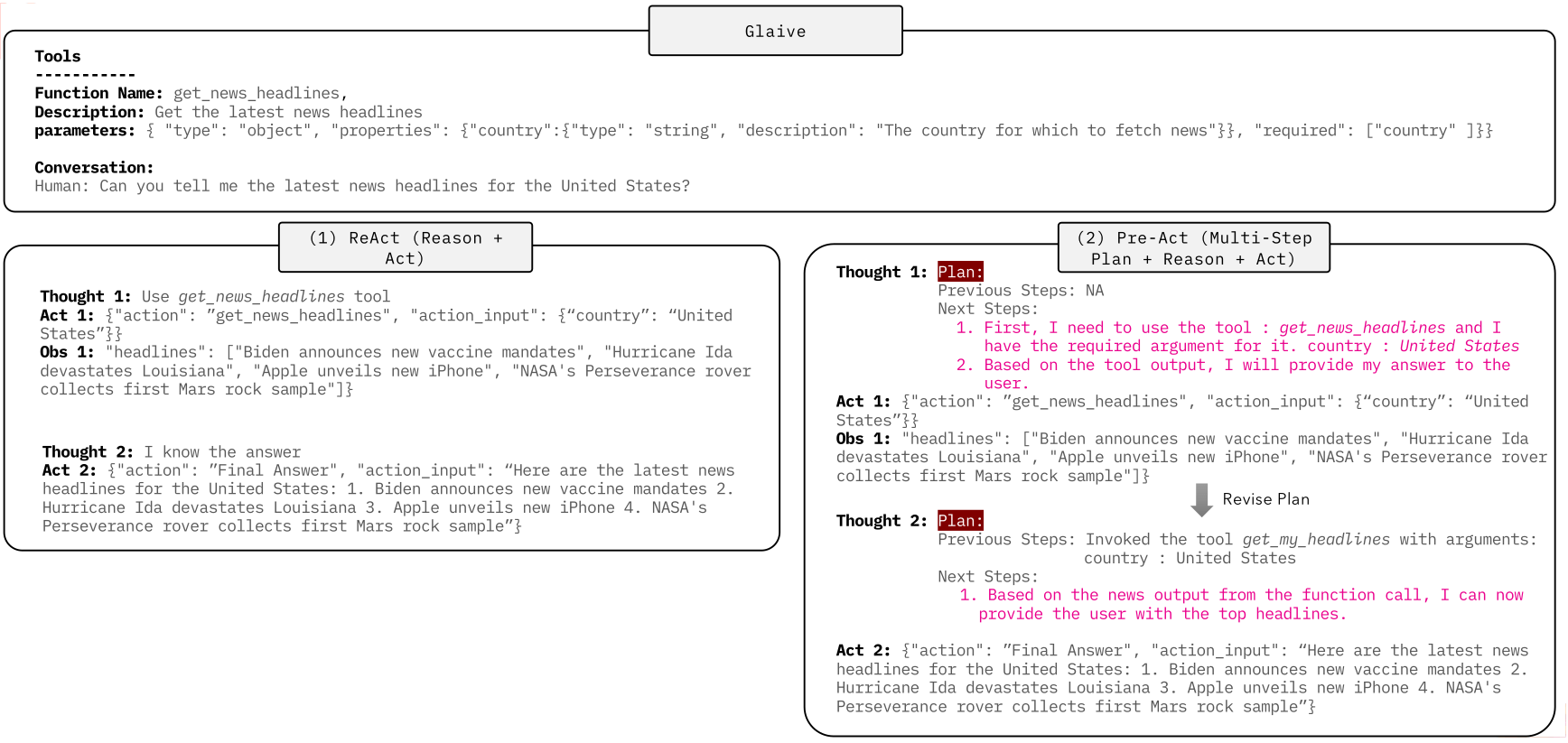
As seen in the example image above, ReAct’s thinking at each step focuses solely on the immediate next action. In contrast, Pre-Act’s thinking at each step includes a description of a global plan.
Pre-Act helps the LLM achieve the aforementioned reasoning process through the design of the following system prompt (provided in the paper). (To be honest, I find the system prompt quite disorganized.):
<system> You are an intelligent assistant and your task is to respond to the human as helpfully and
accurately as possible. You would be provided with a conversation (along with some steps if present)
and you need to provide your response as Final Answer or use the following tools (if required):
Instructions:
------------------------------------------------------------------------------------------
{instructions}
Functions/Tools:
------------------------------------------------------------------------------------------
{tools}
===============
Use a json blob to specify a tool by providing an action key (tool name) and an action_input key
(tool input).
Valid "action" values: "Final Answer" or {tool_names}
In case of final answer:
Next Steps (Plan):
1. I will now proceed with the final answer because ... (explanation)
Follow this format (flow):
Question: input question to answer
Thought: consider previous and subsequent steps and conversation. Summary for what you did previously (ONLY IF
function calls were made for the last user request) and create the multi-step plan.
Action:
```
$JSON_BLOB
```
Observation: action result
... (repeat Thought/Action/Observation N times)
Thought: First provide the summary of previous steps (ONLY IF function calls were made for the last user request)
and then the plan consisting of only 1 step i.e. proceed with the final answer because ... explanation for it
Action:```
{
"action": "Final Answer",
"action_input": "Final response to human”
}
Definition of Multi-Step Plan:
For each request you will create a multi-step plan consisting of actions that needs to be taken until the final
answer along with the reasoning for the immediate action.
E.g.
Next Steps (Plan):
1. I will first do ... (action1) with the detailed reasoning.
2. I will do ... (action2) with the detailed reasoning.
k. I will do ... (actionk) with the detailed reasoning.
k+1. I will now proceed with the final answer because ... (explanation)
Example Output: When responding to human, please output a response only in one of two formats
(strictly follow it):
**Option 1:**
If function calls were made for the last human message in the conversation request, include Previous Steps: ... +
Next Steps: multi-step plan (provide an explanation or detailed reasoning)." Otherwise, provide Previous Steps:
NA and Next Steps: ..
Action:
```
{
"action": "string, \ The action to take. Must be one of {tool_names}",
"action_input": dict of parameters of the tool predicted
}
```
**Option #2:**
In case of you know the final answer or feel you need to respond to the user for clarification,
etc. Output = Thought: If function calls were made for the last human message in the conversation
request, include Previous Steps: ... + Next Steps: Let's proceed with the final answer because ...
(provide an explanation)." Otherwise, provide Previous Steps: NA and Next Steps: ..
Action:
```
{
"action": "Final Answer",
"action_input": "string \ You should put what you want to return to use here"
}
```
Begin! Reminder to ALWAYS respond with a valid json blob of a single action. Use tools if necessary
and parameters values for the tool should be deduced from the conversation directly or indirectly.
Respond directly if appropriate. Format is Thought:\nAction:```$JSON_BLOB```then Observation <user>
Conversation:
{conversation}The Pre-Act paper also discusses finetuning Llama-3.1-8B and Llama-3.1-70B models to output in the Pre-Act style of thinking. Interested readers can refer to the original paper for more details, which won’t be elaborated here.
4 Pre-Act Experimental Results
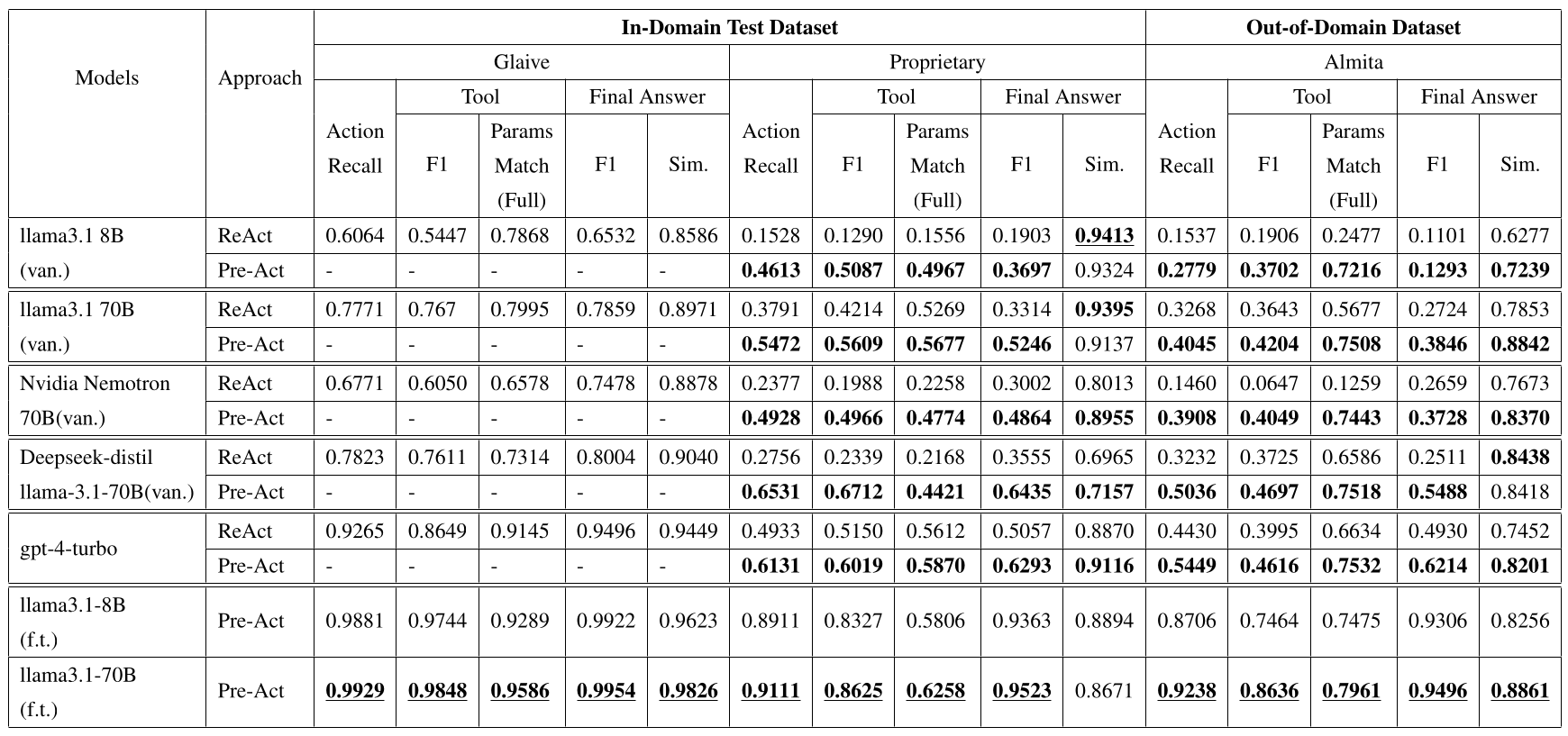
The experimental results above are from Table 2 in the paper, representing Pre-Act’s main experiments. The first 5 rows in the table represent models without finetuning (‘van’ for ‘vanilla’), comparing ReAct and Pre-Act performance using different system prompts. The last 2 rows show the performance of finetuned models (‘f.t.’ for ‘finetune’).
Observations from both experimental setups include:
- Models achieve significantly better Pre-Act-based reasoning performance than ReAct-based reasoning simply by modifying the system prompt.
- If models are specifically finetuned for Pre-Act-based reasoning, their performance can be even better than those relying solely on system prompt modifications.
5 Conclusion
This article provided a quick overview of the “Pre-Act: Multi-Step Planning and Reasoning Improves Acting in LLM Agents” paper:
Pre-Act enhances traditional ReAct-based reasoning by generating and modifying a plan at each reasoning step. This addresses the limitation of ReAct’s single-step thinking, which only focuses on the immediate next action, thereby enabling LLMs to perform better on long-term planning tasks.
Unfortunately, the paper only compares Pre-Act against ReAct as a baseline and uses only one public benchmark. While ReAct is a foundational paper in the LLM Agent field, many subsequent methods have been proposed. The limited number of benchmarks makes it somewhat difficult to definitively gauge Pre-Act’s overall effectiveness. Nevertheless, this paper highlights the benefits of “generating a plan” and “modifying a plan” for LLM task processing.