RAFT: Adapting Language Model to Domain Specific RAG

1 Foreword
Shortly after the LLM craze began, the technology of Retrieval-Augmented Generation (RAG) also became popular. Because through RAG, we can allow LLM to refer to data it hasn’t seen during the Pre-Training or Fine-Tuning stages when answering user questions, thereby improving the quality of LLM’s answers.
In a previous article, we shared REPLUG: Retrieval-Augmented Black-Box Language Models, which is positioned as an RAG method designed for Black-Box LLMs, thus focusing on training the Retriever rather than the LLM itself.
And today’s paper we want to share is RAFT: Adapting Language Model to Domain Specific RAG, a conference paper published at COLM 2024. Quite contrary to REPLUG, since RAFT is positioned to apply RAG to a Specific Domain, RAFT primarily focuses on training the LLM itself.
I believe both RAFT and REPLUG are very simple and easy-to-understand papers. If you are a beginner just entering the field of RAG, I think this article will also be very suitable for you!
2 The Problem RAFT Aims to Solve
The problem RAFT aims to solve is how to apply existing LLMs combined with the RAG method to a Specific Domain. In order to enable the Retrieval-Augmented LLM to understand Domain Knowledge, the authors considered two methods:
- In-Context Learning + RAG: This is essentially standard RAG, where the Retriever retrieves relevant Documents from an External Database based on the Query, and these Documents are placed in the LLM’s Context as Demonstrations, allowing the LLM to answer the Query based on these additional Domain-Specific Documents.
- Supervised Fine-Tuning: Directly training the LLM on a Domain-Specific dataset, which is equivalent to having the LLM memorize this Domain-Specific Knowledge.
However, the authors believe that both of the above methods have some shortcomings, and they use the example of an “exam” to illustrate:
- In-Context Learning + RAG: Like bringing a reference book to an exam and flipping through it on the spot to find answers based on the questions, but without having read the content of the book before the exam.
- Supervised Fine-Tuning: Like having memorized the content of the reference book before the exam, but not bringing any reference book to flip through during the exam.
I actually find this analogy quite interesting! To describe the problem RAFT aims to address more clearly, the authors use “exam” as an example:
- Closed-Book Exam: Like using an LLM without RAG capabilities, where the LLM can only answer the Query based on its internal knowledge and cannot refer to other External Documents.
- Opened-Book Exam: Like adding RAG techniques to the LLM, allowing it to access External Documents.
- Domain-Specific Opened-Book Exam: Refers to an LLM that still has RAG capabilities and can access External Documents, but both the User’s Query and the External Documents are focused on a Specific Domain (e.g., data within an enterprise).
And the method proposed in this paper, RAFT, is also aimed at the task of Domain-Specific Opened-Book Exam!
3 The Method Proposed by RAFT
The concept of RAFT lies in combining the concepts of “In-Context Learning + RAG” and “Supervised Fine-Tuning”, allowing the LLM to learn to find answers from external knowledge based on the question or memorize answers before the exam; and during the exam, it can still obtain external knowledge through RAG technology to find answers from it, or answer questions based on its own memory.
In RAFT, a training sample in the training dataset includes the following elements:
- Question
- A Set of Documents: Can be divided into Golden Document (from which the answer can definitely be derived) or Distractor Document (does not contain information relevant to the answer).
- Answer: Can be obtained from the Golden Document, and the Answer is presented in a Chain-of-Thought Style, meaning it is not just an Answer but also includes the Reasoning process of how to arrive at this Answer.
For P% of the Questions in the training dataset, among their K Documents, there will definitely be one Golden Document, and the rest are Distractor Documents; for the Fraction (1 - P)% of the Questions, all K Documents are Distractor Documents. RAFT uses such a training dataset to train the model through Supervised Fine-Tuning.
Seeing this, my first thought was: “Wow! The RAFT method seems too simple,” but I also found it quite interesting. After all, many RAG methods inherently provide both Golden and Distractor Documents to the LLM simultaneously, allowing the LLM to learn to find important information from so many Documents while not being influenced by other Distractor Documents.
And RAFT goes even more extreme by directly providing only Distractor Documents, without even a single Golden Document!
The authors emphasize that the reason for having a portion of Questions paired entirely with Distractor Documents is to teach the model to “memorize” the answers, rather than finding answers from Documents for all questions. Furthermore, the authors specifically emphasize that in the training dataset, the Answers are provided with a Reasoning process (Chain-of-Thought Style), and also cite some content from the Documents, which can significantly improve the model’s performance. And nowadays, with powerful LLMs, generating these Chain-of-Thought Style Answers is actually not difficult! Finally, the model trained by RAFT follows the standard RAG inference process.
4 RAFT Experimental Results
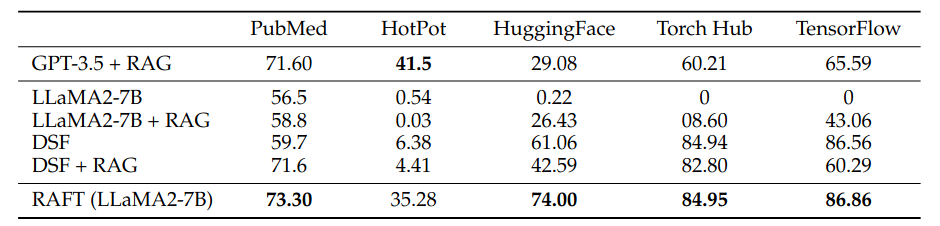
From Table 1, it can be seen that the performance of the original Llama 2-7B, whether using RAG or not (LLaMA2-7B or LLaMA2-7B+RAG), is not very good on some Benchmarks. This is mainly because Llama2-7B’s output cannot align with the format of some Benchmarks. Therefore, after performing Domain-Specific Fine-Tuning on Llama2-7B (DSF or DSF+RAG), its performance significantly improves.
However, it’s somewhat surprising that if the Domain-Specific Fine-tuned Llama2 (DSF) is combined with RAG (DSF+RAG), its performance deteriorates instead. The authors believe this is because during the Fine-Tuning process, the model is directly trained on Domain-Specific Instruction-Following Data, meaning the model learns what Answer it should output upon seeing a particular Question.
In this process, it does not learn to extract useful information from the Context, resulting in the model not extracting valuable information from the Documents during Inference even with RAG added. Such experimental results also tell us that when we want to Adapt the RAG method to a Specific Domain, we should not only train the LLM to learn the Question-Answer Mapping independently, but also include a Retriever, allowing the LLM to learn to extract important information from the Retrieved Documents to answer questions.

From Table 2, it is also clearly observable that when training the LLM for QA tasks, including Reasoning Steps in the Answer can further improve the LLM’s performance. This phenomenon has actually been mentioned in many Papers!

And preparing Chain-of-Thought Style Answers is not difficult either! As shown in Figure 3, by providing the Question and Document, Prompting a SOTA LLM to first generate the Reasoning Step and then the Answer. There are also other Papers (ex. LongCite) that only based on the Document, Prompt the LLM to generate the Query and Answer, and can further Prompt the LLM to generate the intermediate Reasoning Step based on the Query, Answer, and Document.
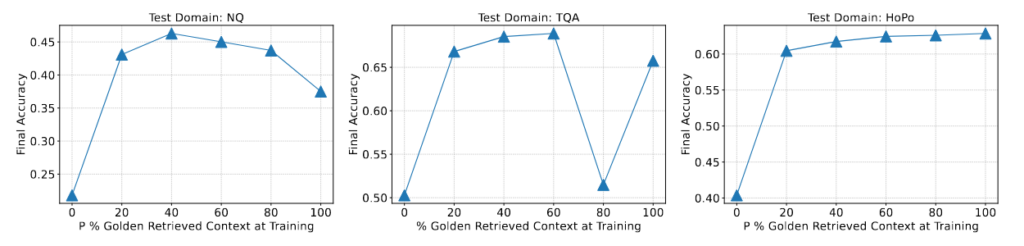
When training the LLM in RAG, intentionally including some Distractor Documents in the Context to teach the LLM not to be affected by Distractor Documents is a common training method (ex. RA-DIT).
However, what’s more interesting in RAFT is that it intentionally pairs a portion of the Questions in the training dataset entirely with Distractor Documents. In other words, when the LLM is learning to answer this Query, its Context does not contain any useful information. And from Figure 5, it can be seen that on some Benchmarks, the model’s best performance is not achieved when 100% of the Questions are paired with Golden Documents, indicating that the authors’ design indeed helps the model learn better.
5 Conclusion
This article shares a paper from COLM 2024 — RAFT: Adapting Language Model to Domain Specific RAG. The RAFT paper is quite simple and easy to read, very suitable for readers new to the RAG field! Below are some insights from the RAFT paper:
- When training the LLM in RAG, the LLM should not only learn the mapping of Question-Answer Pairs, but also be provided with Context, allowing the LLM to learn to find important information from it. This way, the LLM combined with RAG can perform better during Inference Time.
- When training the LLM in RAG, if the provided Answer includes Reasoning Steps and also cites content from the Context, it can further improve the LLM’s performance.
- When training the LLM in RAG, the Documents placed in the Context do not necessarily have to include Golden/Relevant Documents; they can also all be Irrelevant Documents. This not only trains the LLM to memorize the Answer for this Query (instead of learning to find the answer from the Context) but also trains the LLM to avoid being affected by Irrelevant Documents.