Beyond HyDE: How ReDE-RF Makes RAG 10x Faster by "Judging" Instead of "Writing"

1 Introduction
Recently, while chatting with many friends working on RAG (Retrieval-Augmented Generation) in the community, the biggest pain point everyone shares is often not that the LLM doesn’t answer well enough, but that “the right data simply cannot be retrieved.”
Especially in niche domains without labeled data (Zero-Shot), people usually first think of using HyDE (Hypothetical Document Embeddings). This approach sounds sexy: let the LLM first “hallucinate” a fake article, and then use this fake article to search for real ones. But anyone who has implemented it knows this method has two fatal flaws: first, it is slow (generating tokens is expensive), and second, it is prone to “speaking nonsense with a straight face” (hallucinations).
Recently, I read a new paper from MIT Lincoln Laboratory and MIT called ReDE-RF. This paper gave me a huge inspiration: If we stop forcing the LLM to “write” and instead let it focus on “being a judge,” can the retrieval system become more accurate and 10 times faster?
In today’s article, we will deeply deconstruct this paper to see how it uses engineering thinking to solve academic problems.
- Paradigm Shift: Unlike HyDE, which relies on LLMs generating fictional documents, ReDE-RF adopts a strategy of “retrieve real documents first, then let the LLM score them.”
- Extreme Performance: It doesn’t let the LLM generate text but directly extracts the probability values (Yes/No) from the Output Logits, avoiding the expensive Decoding Loop and increasing speed by 4-11 times.
- Eliminating Hallucinations: By anchoring on “really existing” documents to correct the Query, accuracy is significantly improved in low-resource fields such as biomedicine and finance.
- Model Distillation: This workflow can even be distilled to smaller models, requiring absolutely no LLM participation when deployed online.
2 Why is HyDE Not Good Enough? (Problem Definition)
Before diving into ReDE-RF, let’s review how the current SOTA—HyDE—works.
Simply put, HyDE is like a “writing contest.” When a user asks a question, HyDE forces the LLM to write an “ideal document” out of thin air. Then, we convert this Hypothetical Document into a Vector to find similar content in the database.
This idea is strong in general domains (like Wikipedia), but it hits a wall in internal enterprise use or specific domains (Domain Specific):
Knowledge Hallucination: Imagine you are searching for internal Legacy Code documentation. The LLM has never seen this code, so the “hypothetical document” it generates will be full of incorrect Function Names and logic. This is called Garbage in, Garbage out; incorrect hallucinations will lead the retriever into a ditch.
High Cost of Generation (High Latency): To make the hallucination look real, the LLM usually needs to generate hundreds of tokens. This means the GPU has to run Autoregressive Decoding hundreds of times. In search scenarios that demand Real-time performance, making the user wait 3-5 seconds just to generate a Search Query results in a failing User Experience.
Thus, ReDE-RF (Real Document Embeddings from Relevance Feedback) proposes a counter-intuitive but extremely reasonable insight:
Instead of forcing the LLM to “generate” content it doesn’t know, it is better to use its powerful reasoning capabilities to “judge” the content right in front of it.
3 The Core Mechanism of ReDE-RF: From “Writing” to “Selection”
The architecture of ReDE-RF is very elegant and can be broken down into a trilogy of “Cast a Net, Filter, then Navigate.”
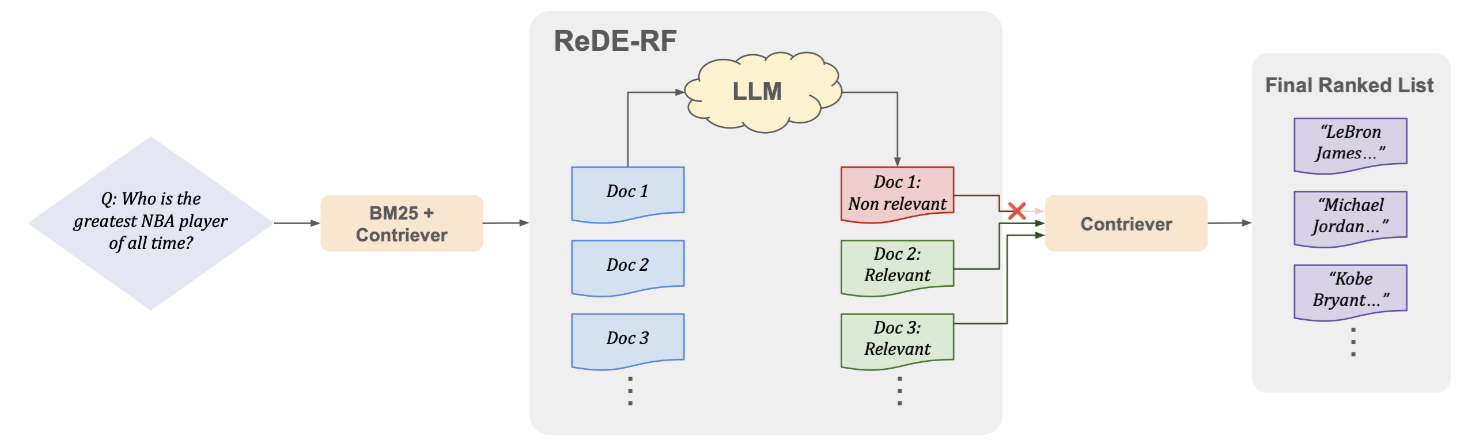
3.1 Step 1: Initial Retrieval — Cast a Net
Since we don’t have Label Data, we first use an off-the-shelf unsupervised retriever (like BM25 or Contriever) to grab the Top- documents. This step doesn’t need to be perfect, as long as we ensure that some correct answers are “mixed in” with this pile of documents.
3.2 Step 2: LLM as Judge (Logits Over Generation)
This is the engineering detail in the paper that impressed me the most.
The traditional approach is to let the LLM read the article and then generate “Yes” or “No”. But the authors of ReDE-RF thought this was too slow. They adopted the Logits Judgment Method:
- Feed the Prompt and the document to the LLM.
- Perform only one Forward Pass (do not enter the generation loop).
- Directly check the Logits scores representing “1” (Relevant) and “0” (Not Relevant) in the Output Layer.
- Calculate the probability using Softmax:
This is a design with immense Engineering Sense:
- Speed: It saves the time of generating text, cutting Latency to the floor.
- Stability: No need to write Regular Expressions to parse wordy LLM answers like “I think it is highly likely…”, as the numerical values are the most honest.
- Truncation: The authors even boldly truncate input documents to 128 tokens, sacrificing a little detail in exchange for several times the throughput.
3.3 Step 3: Updating Query Representation
Now we have a set of “Real Documents” certified by the LLM. We use the vectors of these documents to pull the original Query Vector towards the correct semantic space:
There is a devilish detail here: represents the real document vectors already in the database. What does this mean? It means we do not need to recalculate vectors during inference! These vectors are already stored in the Vector DB; we just need to perform extremely fast Lookup operations. Compared to HyDE, which requires embedding new hypothetical documents every time, the computational difference is night and day.
4 Experimental Data: The Real World Doesn’t Believe in Hallucinations
The experimental results directly slap generative methods in the face, especially in the Low-Resource Domains we care about most.
4.1 1. Who is more accurate in niche domains?
The authors tested on the BEIR Benchmark (which includes datasets for biomedicine, finance, scientific fact-checking, etc.):
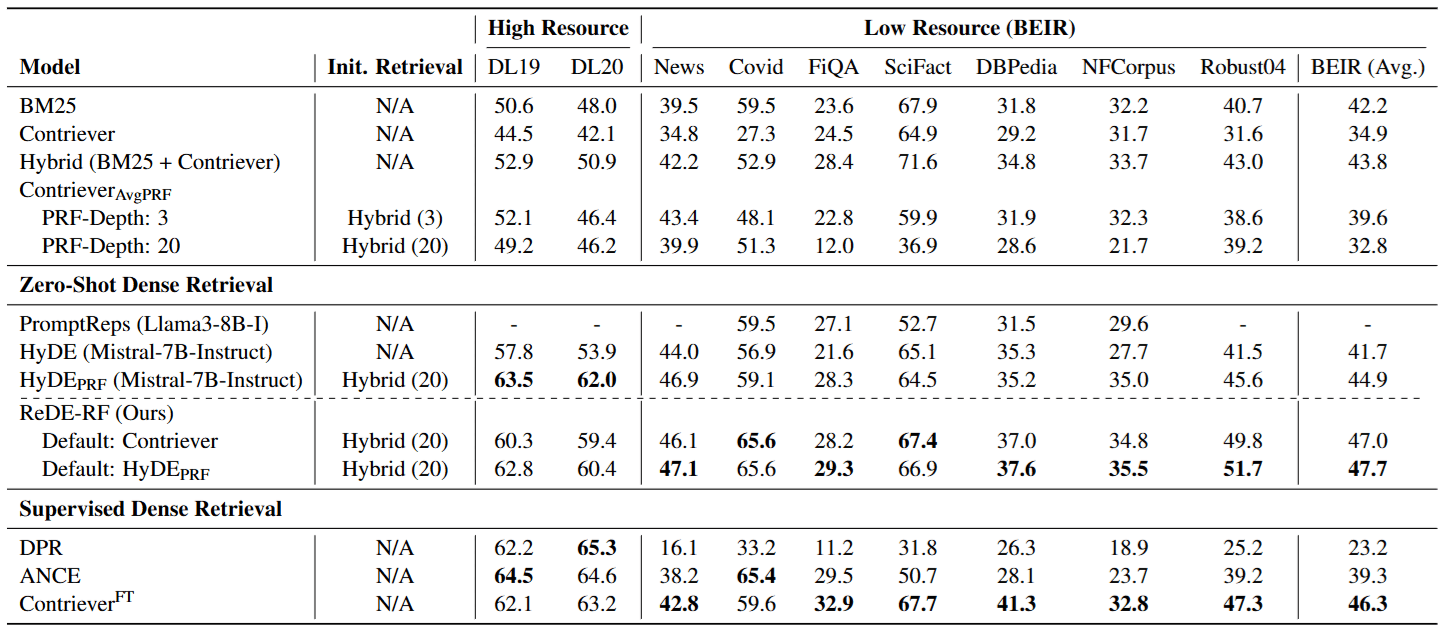
- Failure of HyDE: In these fields, because the LLM doesn’t understand the jargon, the hypothetical documents generated are full of misleading keywords.
- Victory of ReDE-RF: Because it corrects the Query based on real documents, it never “makes things up.” The features it captures are all truly existing in the database.
4.2 2. Speed Revolution
This chart should excite anyone who designs system architectures:
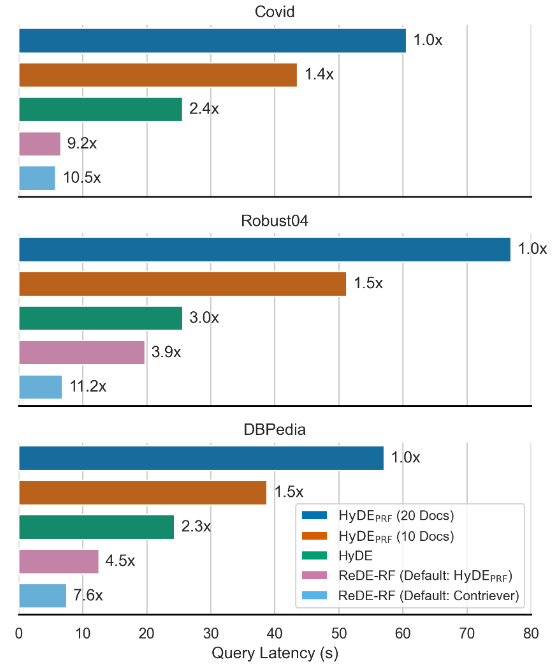
The data shows that ReDE-RF is about 4 times faster than standard HyDE and 7 to 11 times faster than HyDE-PRF. This proves the massive advantage of “Logits Judgment” in engineering implementation.
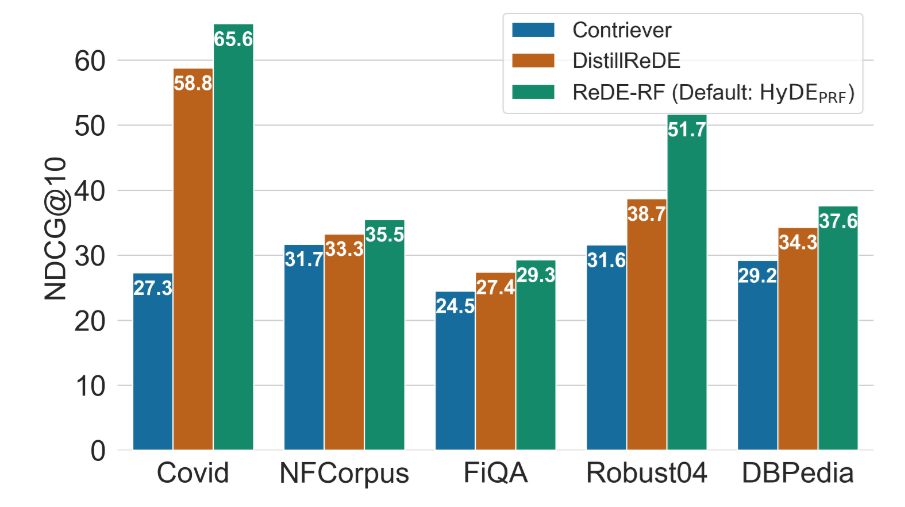
4.3 3. Can it be Distilled?
What if I don’t want to run even that single Forward Pass of the LLM? The paper proposes DistillReDE: Using the results produced by ReDE-RF as a Teacher to train a small Contriever model. The results show that this small model retains the vast majority of performance gains (see the orange Bar below), and requires absolutely no LLM when online.
5 Conclusion and Inspiration: Grounding on Reality
After reading this paper, I believe the greatest inspiration it gives us is not just algorithmic, but a shift in mindset.
Over the past year, everyone has been too superstitious about the creativity of Generative AI, always thinking about letting LLMs generate various Intermediate Steps to assist tasks. But ReDE-RF tells us: In AI applications, “Judgment” is often cheaper, more accurate, and more controllable than “Generation”.
Instead of letting an LLM that doesn’t understand medicine “write” a medical paper to create search keywords (HyDE), it is better to first grab a few real medical papers and let the LLM be responsible for “picking” which ones look real (ReDE-RF).
“Grounding on Reality” — correction based on real data is always more reliable than correction based on imagination. This is perhaps the point most worth pondering when we design the next generation of Agents or RAG systems.