REPLUG: Retrieval-Augmented Black-Box Language Models

1 Introduction
Retrieval-Augmented Generation (RAG) technology has been incredibly popular in recent years because it allows LLMs to answer user queries based on the latest data (not seen during the Pre-Training Stage), reducing the phenomenon of LLM hallucination.
This article aims to introduce a RAG paper from NAACL 2024 — REPLUG: Retrieval-Augmented Black-Box Language Models. This paper was actually published on Arxiv as early as January 2023, so it’s not a very new paper. However, the method proposed in the paper has appeared in many subsequent RAG-related papers, making it still worth studying! Furthermore, the RAG method proposed by REPLUG is quite simple and easy to understand, making it very suitable for readers new to the RAG field!
2 The Problem REPLUG Aims to Solve
A common problem with general LLMs is that when a user asks about knowledge that the LLM has not learned during the Pre-Training or Fine-Tuning stages, the LLM is likely to answer by making things up (Hallucination). It is quite difficult to teach an LLM to know what it doesn’t know. Conversely, through RAG techniques, LLMs can obtain relevant information for the question from an external database, reducing hallucination.
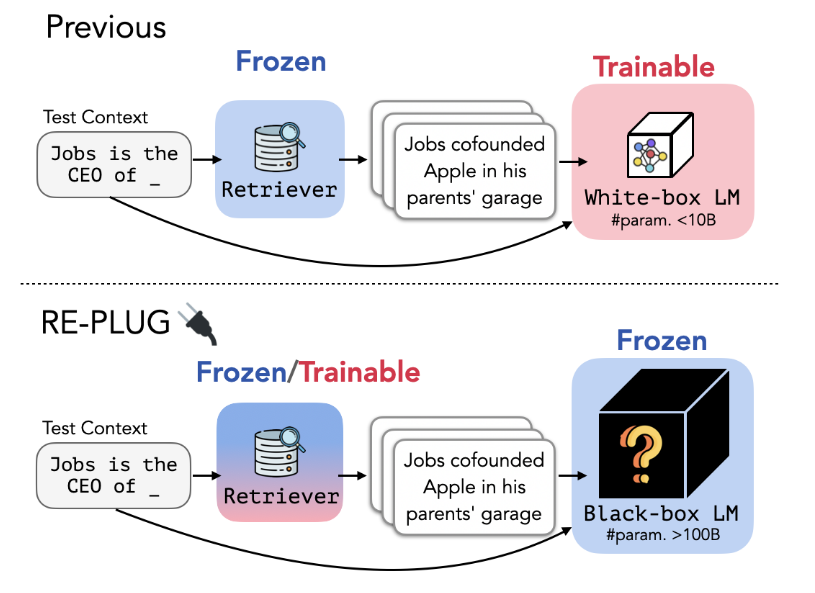
As shown in Figure 1 above, most past RAG methods used a frozen (cannot be trained) Retriever paired with a trainable LLM, allowing the LLM to learn to generate output based on the documents provided by the Retriever. This approach has the following drawbacks:
- The Retriever does not learn how to retrieve good documents.
- Fine-tuning the LLM itself is a high-cost task. To reduce costs, one might have to use a smaller LLM, which in turn reduces performance.
Furthermore, most existing State-Of-The-Art LLMs are Black-Box Models, meaning we can only call them via API, providing input and getting output, let alone fine-tuning them. Therefore, the RAG method proposed in this paper primarily focuses on Block-Box LLMs!
3 The Method Proposed by REPLUG (1): Inference Time
The method proposed by REPLUG can be divided into two parts: Inference Time and Training Time. This section will first introduce how Inference Time can improve the output quality of the LLM through Ensemble techniques.
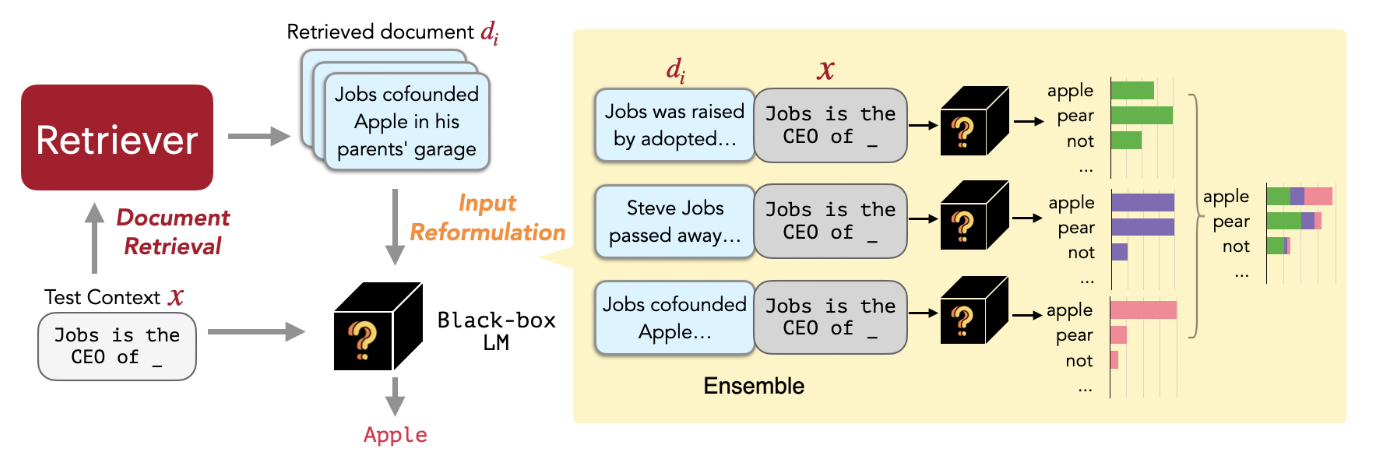
As shown in Figure 2 above, given a Query (hoping the LLM answers “Job is the CEO of ???”), the Retriever will retrieve the documents most similar to this Query from the External Database. The specific method here is actually the standard RAG approach: pass both the Query and all Documents in the External Database individually through a Sentence Embedding Model to get their Embeddings. Then, calculate the Cosine Similarity between the Query’s Embedding and all Document Embeddings. Select the Top-K most similar Documents!
With K documents related to the Query, a simple approach is to use all these documents as Context and input them along with the Query into the LLM. However, this approach might cause the input sequence length to exceed the LLM’s Context Window Size.
Therefore, this paper proposes an Ensemble method: Concatenate each document individually with the Query and input them separately into the LLM. Each time, a Next Token Distribution is obtained. Finally, these K Next Token Distributions are Ensembled together.
During the Ensemble process, each Distribution must be assigned a Weight, and this Weight is calculated from the Similarity between that document and the Query.
In other words, if a document is more similar to the Query, its Weight will be higher. Through this method, the LLM’s output no longer relies on just one document but can refer to multiple documents simultaneously without needing to provide a large context at once.
4 The Method Proposed by REPLUG (2): Training Time
The second method proposed by REPLUG is to train the Retriever during the Training Stage. In other words, because the focus is on Block-Box LLM, it’s impossible to train the LLM, but the question is how to train the Retriever to retrieve documents that improve the output quality of the LLM.
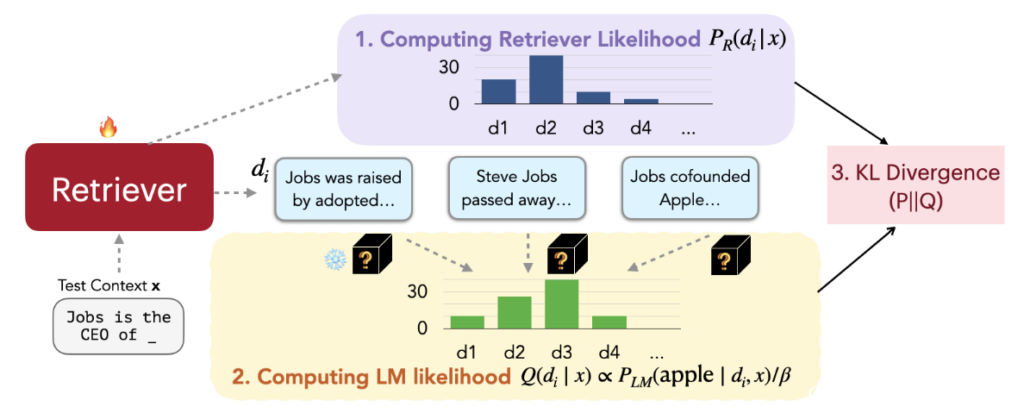
As seen in Figure 3 above, following the general RAG approach, first, based on the current Query (“Job is the CEO of ???”), the Retriever can retrieve K documents from the External Database. Through the Similarity between these K documents and the Query, the probability values of these K documents being selected can be calculated, which is called Retrieval Likelihood. The specific method is simply to apply Softmax to these K Similarities.
Next, concatenate these K documents separately with the Query and input them into the LLM. From the LLM’s Output Distribution, extract the probability value of the correct Token. For example, according to the current Query, the correct Token the LLM should output next is “Apple”.
In this step, we can obtain the probability of the LLM predicting the token “Apple” after reading each different document. If connecting Document #2 with the Query results in the highest probability for the LLM predicting the token “Apple”, then we can imagine that Document #2 is the most suitable for the current Query!
Through this method, we can calculate the probability value of each document for the correct Token, called LM Likelihood. Our ultimate goal is to make the Retrieval Likelihood as close as possible to the LM Likelihood, so the KL Divergence between these two Likelihoods can be used as the Loss to update the Retriever.
Once the Retriever is updated, the Embeddings of all documents that we pre-calculated and stored in the External Database will become outdated. Therefore, the authors chose to update the Embeddings of all documents in the External Database after updating the Retriever T times!
5 REPLUG Experimental Results
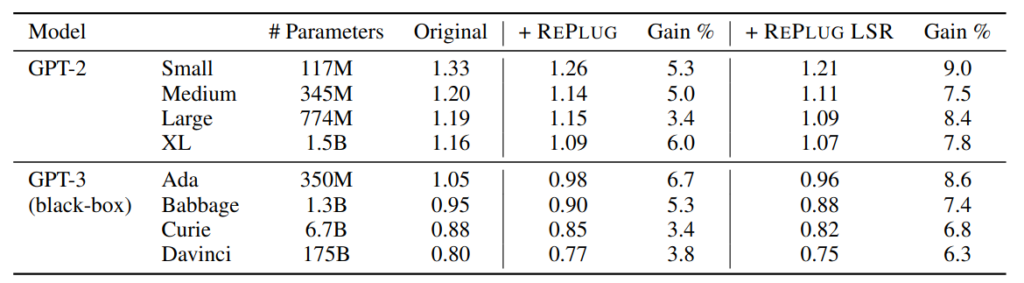
From the experimental results in Table 1, it can be seen that regardless of which version of GPT2 or GPT3 is used, their performance improves when combined with REPLUG’s Inference Time technique (+ REPLUG). If the Retriever is further trained, the performance improves even more (+ REPLUG LSR).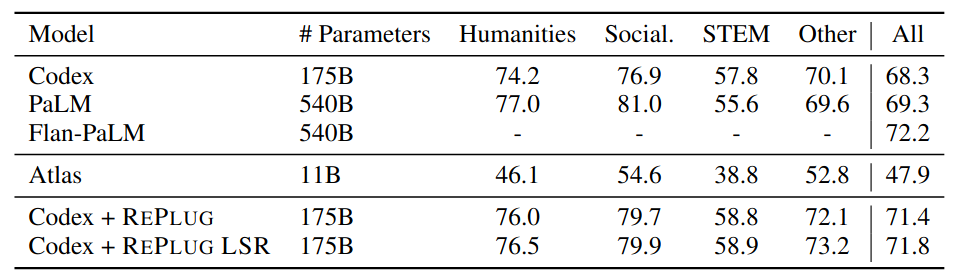
In the experiment shown in Table 2, the authors used the MMLU Dataset, which is divided into 4 categories. Among them, Codex, PaLM, and Flan-PaLM are the three Baselines with the best performance on the MMLU Dataset Leaderboard. Atlas is used as a RAG method Baseline. It can be seen that adding the techniques proposed in this paper to Codex improves its performance.
6 Conclusion
This article briefly introduced the NAACL 2024 RAG paper — REPLUG: Retrieval-Augmented Black-Box Language Models. It mainly focuses on improving the output quality of Block-box LLMs by using the Ensemble Output Distribution technique during the Inference Stage, allowing the LLM’s output to consider multiple different documents simultaneously. It also proposes an LLM-Supervised method during the Training Stage to train the Retriever to retrieve documents suitable for the LLM, thus improving the LLM’s output quality.