SENSE Explained: How Strong and Weak LLMs Achieve State-of-the-Art Text-to-SQL (ACL 2024)

1 Introduction
This article introduces the paper SENSE: Synthesizing Text-to-SQL Data from Weak and Strong LLMs. Published in ACL 2024, the core objective of this paper is to train a powerful Text-to-SQL model through Supervised Fine-Tuning (SFT).
This paper approaches the problem from a Data perspective, proposing a method that utilizes both weak and strong LLMs to generate different types of Text-to-SQL synthetic data, thereby enhancing the performance of open-source models after fine-tuning.
The final fine-tuned model is named SENSE. Although a GitHub repository is available, the author had not yet pushed the code and model at the time of this writing.
2 The Problem SENSE Aims to Solve
SENSE’s goal is to improve the Text-to-SQL performance of open-source models through SFT. The primary challenge with SFT is the preparation of training data. To prepare this data more efficiently, SENSE adopts the method of Synthetic Data Generation.
Therefore, the problem SENSE addresses is:
What kind of Synthetic Data should be generated to improve a model’s Text-to-SQL capabilities after Fine-Tuning?
3 SENSE’s Proposed Method
The authors argue that good Text-to-SQL training data needs to teach the model two things:
- The model needs sufficient generalization ability to generate correct SQL even for table schemas not seen in the training data.
- The model needs to recognize common incorrect SQL patterns to avoid making the same mistakes.
Based on these two points, SENSE’s method is divided into two stages:
- First Stage
- Goal: To equip the model with sufficient Text-to-SQL generalization capabilities.
- Method: Use a Strong LLM to generate high-quality data (Strong Data), and then train the model on this Strong Data using SFT.
- Second Stage
- Goal: To teach the model to recognize common errors in SQL.
- Method: Use a Weak LLM to generate common incorrect SQL syntax (Weak Data), and then train the model on this Weak Data using DPO.
3.1 Strong Data: Supervised Fine-tuning
For the preparation of Strong Data, the authors use Prompting with GPT-4 to generate synthetic data. Below is the prompt used by the authors:
Your task is to generate one additional data point at the {the_level} difficulty level, in alignment with the format of the two provided data points.
1. **Domain**: Avoid domains that have been over-represented in our repository. Do not opt for themes like Education/Universities, Healthcare/Medical, Travel/Airlines, or Entertainment/Media.
2. **Schema**: Post your domain selection, craft an associated set of tables. These should feature logical columns, appropriate data types, and clear relationships.
3. **Question Difficulty** - {the_level}
- **Easy**: Simple queries focusing on a single table.
- **Medium**: More comprehensive queries involving joins or aggregate functions across multiple tables.
- **Hard**: Complex queries demanding deep comprehension, with answers that use multiple advanced features.
4. **Answer**: Formulate the SQL query that accurately addresses your question and is syntactically correct.**Additional Guidelines**:
- Venture into diverse topics or areas for your questions.
- Ensure the SQL engages multiple tables and utilizes advanced constructs, especially for higher difficulty levels.
Ensure your submission only contains the Domain, Schema, Question, and Answer. Refrain from adding unrelatedcontent or remarks.
(...examples and generations goes here...)In each generation instance, the authors randomly select two samples from the Spider training dataset to serve as Few-Shot Examples in the prompt above.
Once the synthetic Strong Data is ready, the model undergoes the first stage of training via SFT, which involves minimizing the following Loss Function:
Here, represents the parameters of the language model, and is the conditional probability of the model generating the target SQL code given the input prompt . is the total sequence length of , and is the auto-regressive decoding step.
3.2 Weak Data: Preference Learning
For the preparation of Weak Data, the authors use a smaller and weaker model for synthetic data generation:
- Based on a natural language question, a Weak LLM is used to generate SQL code.
- The generated SQL code is executed by a SQL Executor.
- If the execution result from the SQL Executor matches the ground truth, the generated SQL code is labeled as a Positive Sample ; otherwise, it is labeled as a Negative Sample .
After creating the preference dataset, the model is further trained using DPO, which involves maximizing the following Objective Function:
4 SENSE Experimental Results
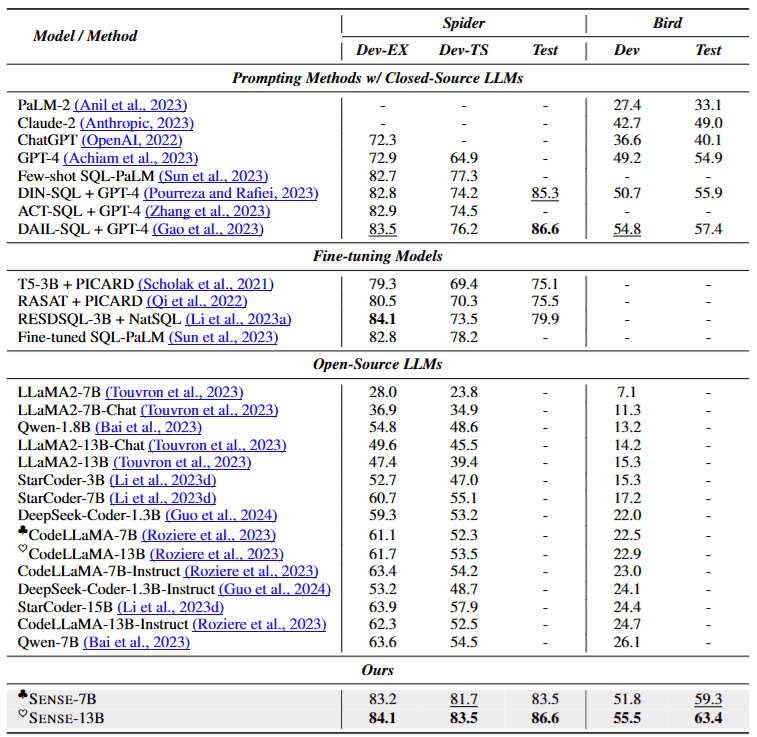
The experimental results in the table above show that closed-source models are remarkably powerful, achieving near state-of-the-art (SOTA) performance through simple prompting. In contrast, the performance of open-source models is quite poor.
The last two rows show that SENSE-7B and SENSE-13B, trained on CodeLLaMA-7B and CodeLLaMA-13B respectively, achieve SOTA performance!
5 Conclusion
In this article, we discussed the ACL 2024 paper - SENSE: Synthesizing Text-to-SQL Data from Weak and Strong LLMs. From this paper, we learned a simple method to create a synthetic Text-to-SQL dataset using weak and strong LLMs. We also saw how a two-stage training process involving SFT and DPO can significantly boost the Text-to-SQL performance of open-source models.