[EMNLP 2025] TableRAG Deep Dive: Text is for Reading, Tables are for Querying (via SQL)

1 Introduction
In current enterprise-grade RAG applications, the biggest pain point we face is often not “unable to find documents,” but “unable to understand the structured data within documents.” When a financial report or specification sheet contains both lengthy textual descriptions and precise data tables, traditional RAG often loses sight of one while attending to the other.
This paper, published in EMNLP 2025 and titled TableRAG, was born to solve this real-world puzzle. It proposes an elegant solution: Do not try to read tables as text; instead, let them return to the essence of data.
TableRAG is a RAG framework designed specifically for “Heterogeneous Documents” (i.e., a mix of text and tables). It abandons the traditional approach of “flattening” tables into text for vector retrieval and instead adopts a Dual-Track strategy:
- Unstructured Text: Continues to use Vector Search for semantic understanding.
- Structured Tables: Introduces SQL as a Symbolic Execution engine to ensure the precision of data queries and calculations.
Through an Online Iterative Reasoning loop, TableRAG can peel back the layers like an onion to decompose complex Multi-hop questions, ultimately combining results from text retrieval and SQL queries to provide precise answers.
The value of this paper lies in its “acknowledgment of LLM limitations.” The authors do not force the LLM to perform mathematical operations or full-table scans—tasks it is not good at—but instead let the LLM act as a “commander” and “programmer,” outsourcing heavy data operations to the SQL database, which excels at these tasks. This “division of labor” system design thinking is key to building reliable AI applications.
2 Problem Definition
Before diving into TableRAG’s architecture, we must first understand the background of its inception: Tables and Natural Language (Text) are fundamentally different.
2.1 Three Major Pain Points of Existing RAG
Traditional RAG technology performs excellently when dealing with pure text documents. However, when facing “Heterogeneous Documents” (documents mixed with text and tables) common in enterprises, we find that mainstream practices (converting tables to Markdown text and chunking them) lead to three fatal defects:
Structural Information Loss
- Status Quo: To make data digestible for vector databases, we usually “flatten” two-dimensional tables into one-dimensional Markdown text, and then slice them into multiple Chunks like a cake.
- Consequence: The strong logical connection between Rows and Columns is broken. For example, the header might be in the first Chunk, while the data is in the second. During retrieval, the model often grabs the data but loses the header definition, causing the LLM to look at numbers without knowing if they represent “Revenue” or “Cost.”
Lack of Global View
- Status Quo: The gold standard for RAG is “Top-N Retrieval.”
- Consequence: This is effective for finding single facts, but it is disastrous for “Global Queries” requiring overall statistics.
- Case Review: If we ask, “What is the average price of all products in 2023?”, RAG might only retrieve the top 5 rows of the table (Top-N). The LLM can only calculate the average based on these 5 rows, so the answer is guaranteed to be wrong because it never saw the “whole table.”
Reasoning Limitations
- Status Quo: We force LLMs to do things they are not good at—large number calculations and multi-step logic.
- Consequence: Although LLMs can write poetry, when asked to calculate a weighted average for a 50-row table, they easily produce Hallucinations. Even GPT-4 is inferior to a simple calculator when dealing with dispersed data in long texts.
2.2 Core Insight
The authors of TableRAG realized that to solve these problems, we can no longer treat tables as text. Their solution goes straight to the essence:
Text is for Reading, Tables are for Querying.
Therefore, TableRAG proposes a Hybrid reasoning path: retain vector retrieval to handle text semantics, but introduce SQL as the “exclusive language” for tables. This solves not only the view problem (SQL can SELECT *) but also the calculation problem (SQL’s AVG() is absolutely accurate).
3 Methodology
TableRAG is not a single model, but a carefully designed system framework. We can divide its operation process into two phases: “Offline Construction” and “Online Reasoning.”
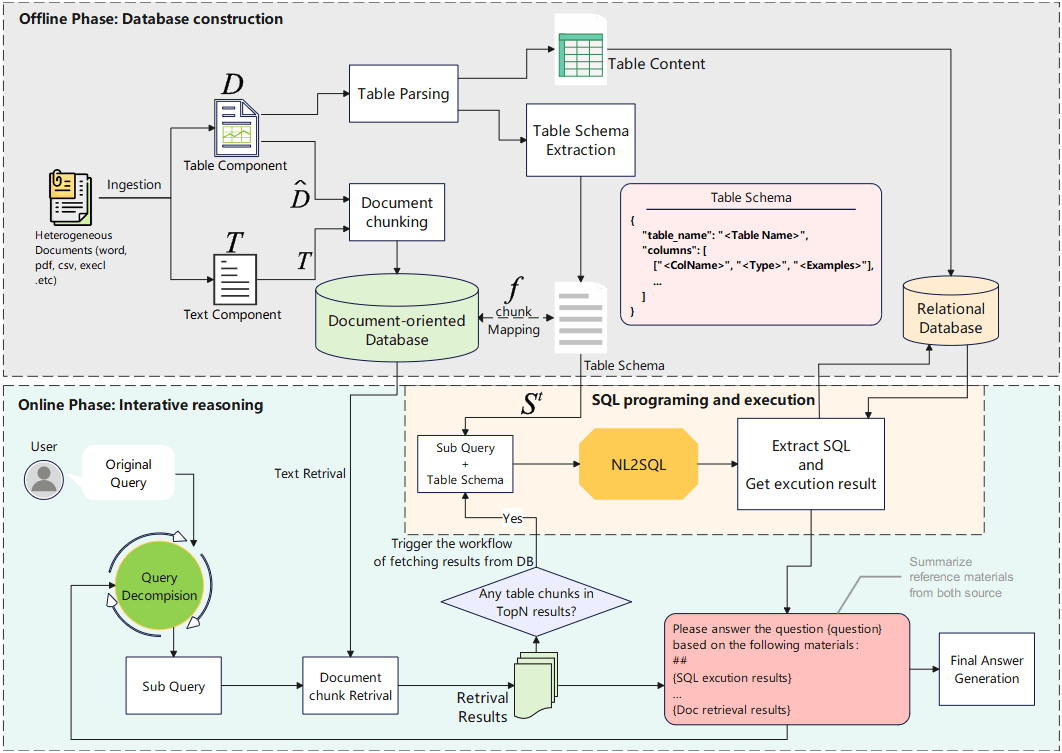
3.1 Offline Database Construction
In our previous discussions, we summarized this stage as a “One Source, Three Stores” strategy. To allow the system to both “read” and “execute,” TableRAG processes the same table into three forms:
3.1.1 Textual Knowledge Base — For Retrieval
This is so the Vector Embedding Model can find the table.
- Method: Convert the table to Markdown format; if the table is too large, perform Chunking.
- Purpose: When a user asks about “2012 Australian movies…”, the system can use semantic similarity to first retrieve these Markdown fragments as “index cards.” These fragments are denoted as .
3.1.2 Tabular Schema Database — For Understanding Structure
This is the bridge connecting “fuzzy semantics” and “precise execution.”
- Method: Extract a standardized structure description for each table , including table name, column names, and data types.
- Key Mechanism: Mapping Function This is a crucial mapping function: It means: When we retrieve the -th Markdown fragment , the system can immediately look up the complete Table Schema behind it through this function. This allows the LLM to instantly grasp the full picture even if it only sees a corner of the table.
3.1.3 Relational Database — For Execution
- Method: Import original data into a standard SQL database (like MySQL).
- Purpose: This is where the SQL code actually runs, ensuring absolute precision in calculations.
This is what we call “Divide and Conquer.”
- Markdown Chunks are “bait” used to be retrieved.
- Schema is the “map,” telling the LLM what the table looks like.
- MySQL is the “engine,” responsible for executing heavy data calculations.
3.2 Online Iterative Reasoning
Once the database is ready, TableRAG enters online reasoning mode. This is a Loop where the system continuously repeats the following four steps until the user’s problem is solved.
3.2.1 Context-Sensitive Query Decomposition
This is the brain of the system. Facing complex problems (e.g., Multi-Hop Question), the LLM needs to decide “what to do next.”
- Why call it “Context-Sensitive”? This step does not happen in a vacuum. Before decomposing the problem, the system performs a retrieval so the LLM sees relevant Markdown fragments (i.e., Schema information).
- Operational Logic:
The LLM is like ordering from a menu. It only generates a sub-question to “Calculate Profit” after seeing
RevenueandCostcolumns in the retrieved Schema. This prevents the LLM from fantasizing about non-existent columns (Hallucination). - Prompt Implementation Details: Although the Prompt Template in the paper looks static, it is actually a ReAct Agent. The output (Thought/Action) and execution result (Observation) of each round are dynamically added to the conversation history, letting the LLM know “I have checked A, now I should check B.”
3.2.2 Text Retrieval
For the sub-question generated in Step 1, the system performs retrieval:
- Recall: Use vector retrieval to fetch Top-N relevant fragments.
- Rerank: Use a Cross-Encoder to select Top-k fragments ().
- Key Point: The retrieval results here mix “pure text” and “table Markdown fragments.”
3.2.3 SQL Programming and Execution
This is TableRAG’s killer feature.
- Trigger Condition: The system checks if the Top-k results from Step 2 contain table fragments.
- If no: Skip this step (degrades to traditional RAG).
- If yes: Activate the SQL engine.
- Execution Flow:
- Use the Mapping Function to obtain the complete Schema.
- The LLM generates a SQL statement based on the sub-question and Schema (e.g.,
SELECT AVG(score) FROM students). - Send the SQL to MySQL for execution to get the precise result .
3.2.4 Compositional Intermediate Answer Generation
Now, the LLM holds two pieces of evidence:
- Retrieved Text (may contain context or qualitative descriptions).
- SQL Execution Results (precise quantitative data).
- Conflict Resolution & Adaptive Weighting:
There is no mathematical formula here, but rather “soft weighting” achieved through ingenious Prompt Engineering:
- If SQL execution fails (syntax error), the Prompt instructs the LLM to ignore SQL and rely entirely on text.
- If both match, output directly.
- If they conflict, the LLM is instructed to perform Cross-Examination, usually prioritizing SQL data results but referring to the text’s contextual explanation.
3.3 Iteration & Termination
After generating the intermediate answer , the system returns to Step 1 to evaluate if the original question has been resolved.
- Resolved: Output the final answer .
- Unresolved: Use as new context to generate the next sub-question and continue the loop.
4 Experimental Results
To verify TableRAG’s performance, the authors conducted extremely rigorous tests. We need to look not only at how much it won but also under what scenarios it demonstrated absolute dominance.
4.1 Experimental Setup: Covering Three Dimensions of Challenge
The experiment used three Datasets, representing different difficulty dimensions:
- WikiTQ: Focuses on complex table operations (like aggregation, comparison), testing SQL precision.
- HybridQA: A standard mixed dataset of text and tables, testing integration capabilities.
- HeteQA (Proposed in this paper): Specifically designed for Multi-hop Heterogeneous Reasoning. This is the dataset closest to real-world scenarios and the most difficult.
4.2 Key Achievements: Why does TableRAG dominate?
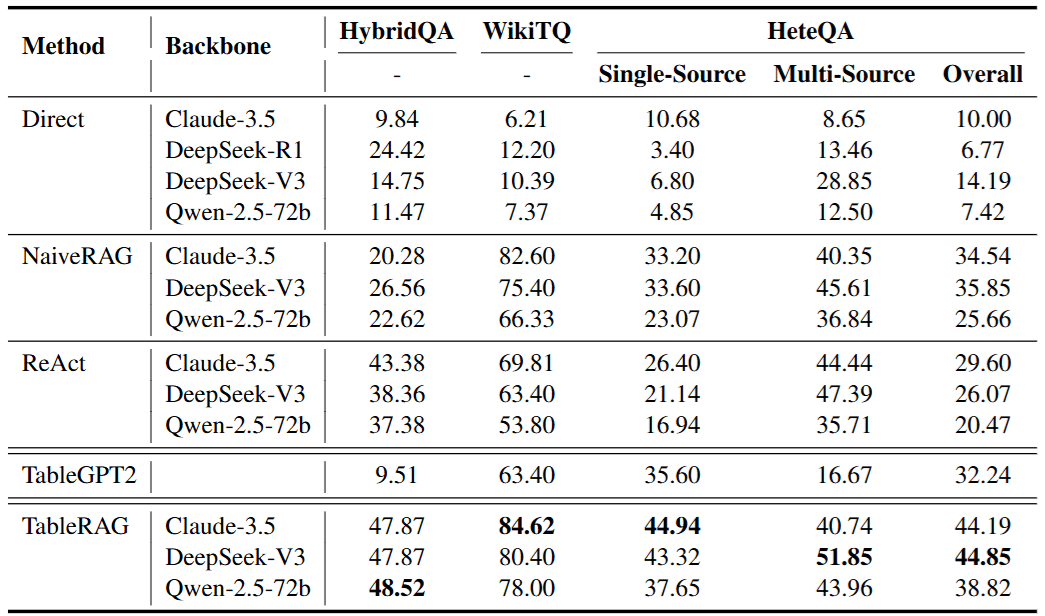
From the data in Table 1, we can read several key stories:
- Complete Victory over NaiveRAG: NaiveRAG (linearizing tables) performs extremely poorly in scenarios like WikiTQ that require precise calculation. This proves that “reading tables as text” has a ceiling; once operations are involved, vector retrieval fails.
- The Key to Surpassing ReAct is “Not Fragmenting”: Although ReAct also uses iterative reasoning, it performs worse than TableRAG in HeteQA’s Multi-source scenarios. The reason is that ReAct tends to break problems down “too finely,” causing the reasoning chain to become too long and collapse; whereas TableRAG collapses complex table operations into a single precise execution via SQL, significantly improving stability.
- TableGPT2’s Fatal Flaw: Although TableGPT2 excels at writing Python/Pandas, its performance drops significantly in HeteQA (containing a lot of text info). This proves that “table skills alone are not enough.” Systems lacking text retrieval capabilities cannot handle complex documents in the real world.
4.3 Ablation Studies: Deconstructing “Dual-Track” Contribution
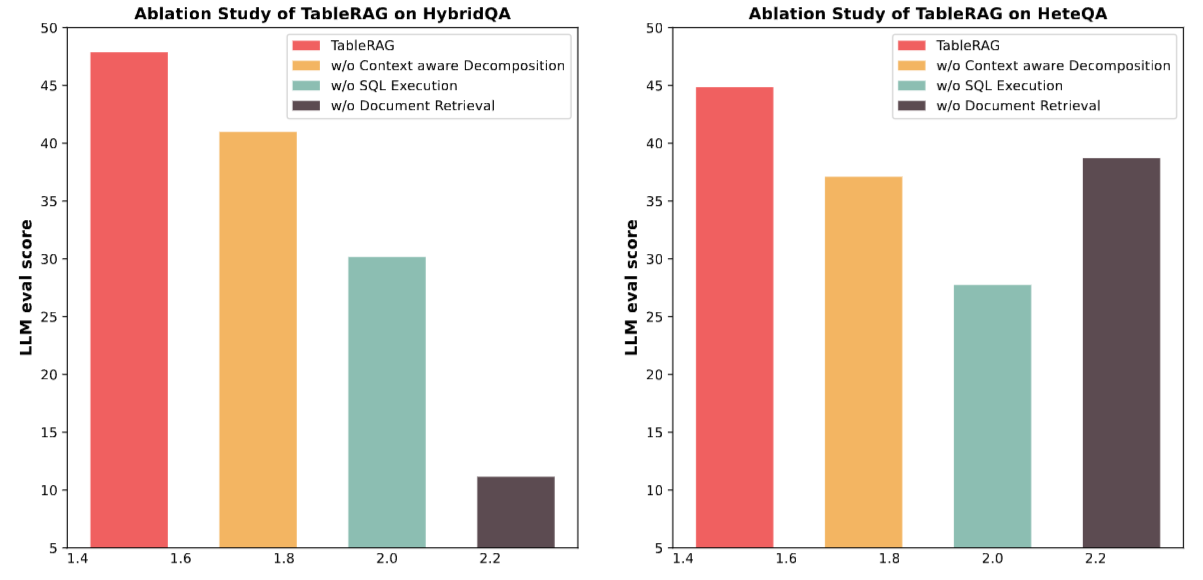
We made an important discovery when analyzing Figure 4:
- Removing SQL (w/o SQL Execution): Performance on HeteQA drops sharply. This illustrates that when a problem involves multiple table steps, retrieval based on Markdown table fragments alone is completely inadequate.
- Removing Text Retrieval (w/o Text Retrieval): On datasets like HybridQA that rely heavily on contextual information, performance almost collapses.
- Conclusion: This confirms our core insight—Text and Tables are complementary. SQL provides precision, while retrieval provides context.
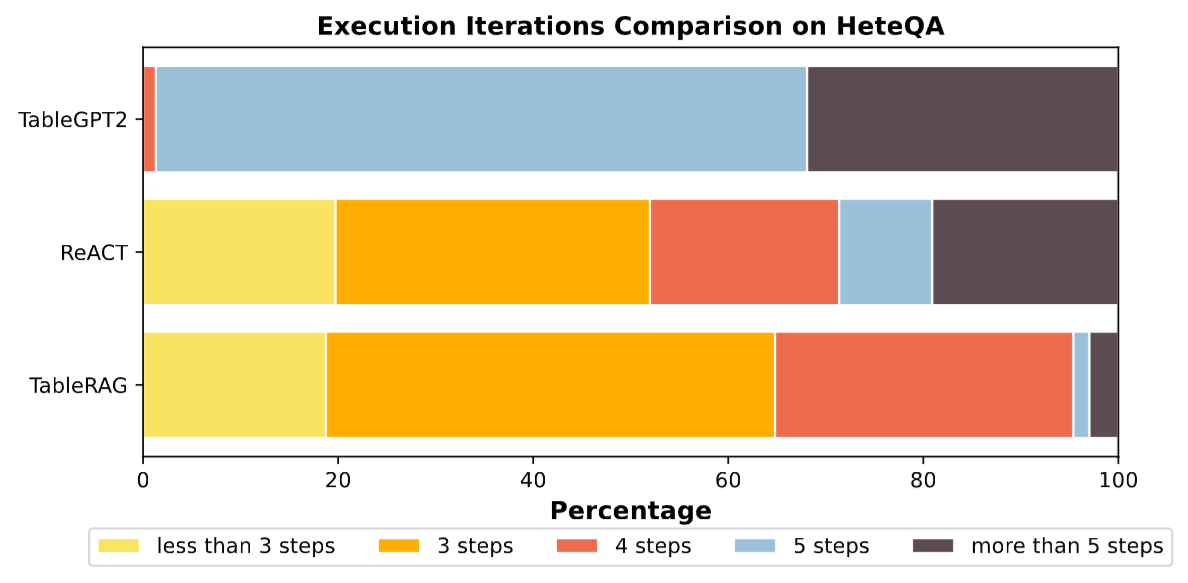
4.4 Efficiency Analysis: Faster, More Accurate, More Economical
5 Conclusion
5.1 Summary
This paper accurately captures the sense of powerlessness in existing RAG systems when dealing with “Heterogeneous Documents.”
- Challenge: Flattening tables leads to structural loss, and Top-N retrieval prevents global calculation.
- Strategy: Proposes the TableRAG framework, achieving dual-track parallel operation through “Offline One-Source-Three-Stores” and “Online Iterative Reasoning.”
- Result: Achieved SOTA on multiple benchmark datasets and proved that SQL-based symbolic execution can significantly improve the accuracy and efficiency of complex reasoning.
5.2 Limitations and Outlook
Although TableRAG is very powerful, we must also clearly see its limitations:
- Model Dependency: Its performance is highly dependent on the Text-to-SQL capability and logical decomposition ability of the underlying LLM (such as Claude-3.5 or DeepSeek-V3). If a weaker small model is used, system performance will degrade significantly.
- Lack of Cross-Language Capabilities: Current tests and Benchmarks (HeteQA) are limited to English.
- SQL Fault Tolerance: Although there is a conflict resolution mechanism, if SQL generation has logical errors (rather than syntax errors), the system still risks misleading the LLM. Future improvements could introduce multiple SQL candidates for self-verification.