UniversalRAG: Mastering Multimodal RAG with Intelligent Routing and Granularity Control

1 Introduction
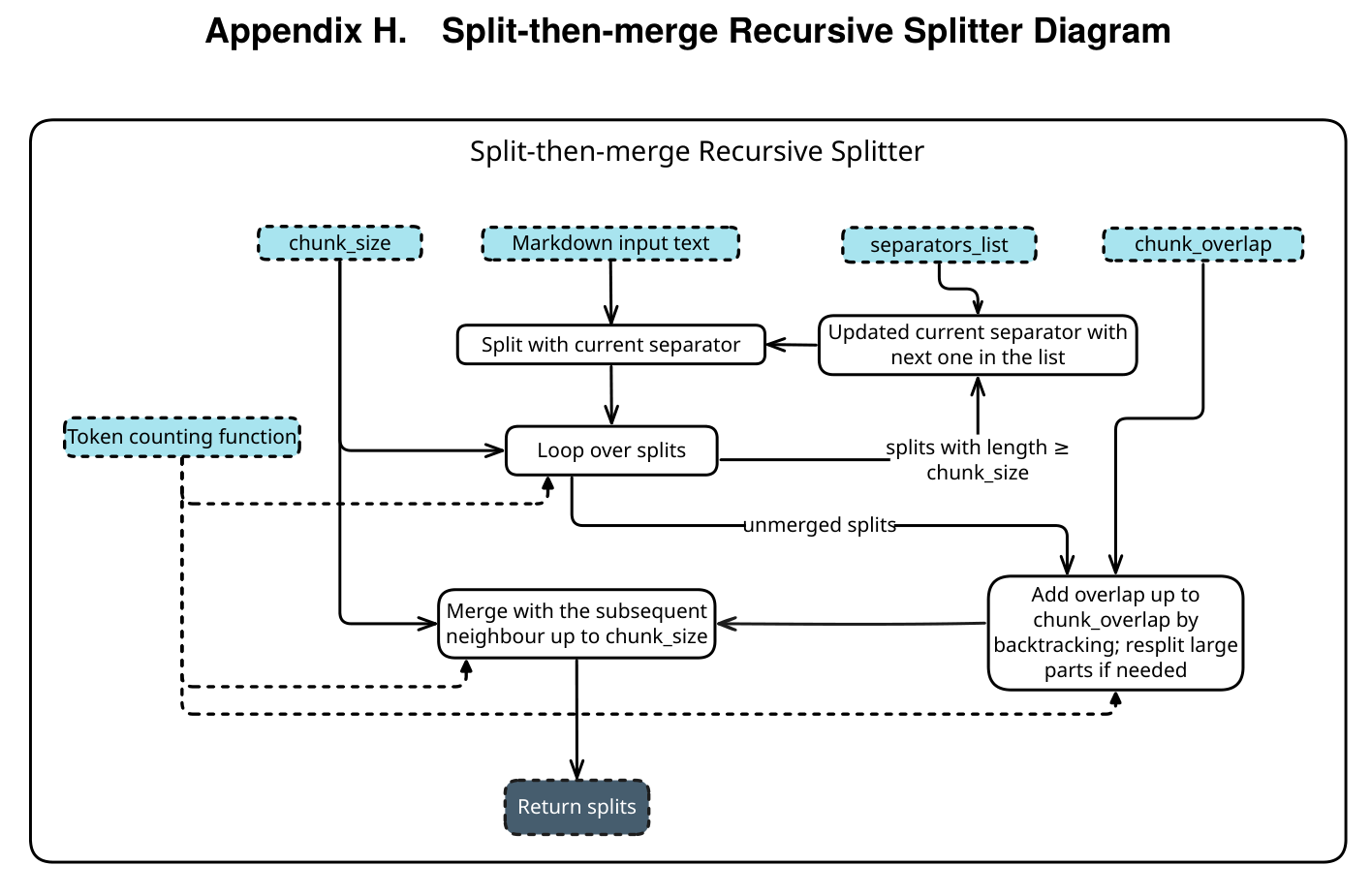
Before diving into the details, let’s get acquainted with this work presented by the KAIST team: UniversalRAG: Retrieval-Augmented Generation over Corpora of Diverse Modalities and Granularities. If you are looking for a more intuitive demo or the code, you can check out their Project Page.
Why is this paper worth our attention?
Traditional RAG systems are like librarians who can only flip through “textbooks.” Even with the advent of multimodal RAG, they typically operate within a single modality (e.g., searching only images or only text). However, real-world problems are complex; sometimes the answer is hidden in a specific moment of a video, and other times it requires comparing a design blueprint with a technical manual.
The core philosophy of UniversalRAG is: rather than forcing all modalities to align into a single chaotic vector space, it is better to build an intelligent “Router” to achieve precise retrieval through a “diagnosis before prescription” approach.
In this note, we will cover:
- Core Strategy: How to avoid modality bias (Modality Gap) through Modality-aware Routing.
- Granularity Control: How to dynamically determine the size of retrieved information (from short paragraphs to entire videos).
- Implementation Details: Specific approaches for Training-based and Training-free Routers.
- Practical Thinking: Implementation challenges and solutions for enterprise private data (e.g., Table vs. Text).
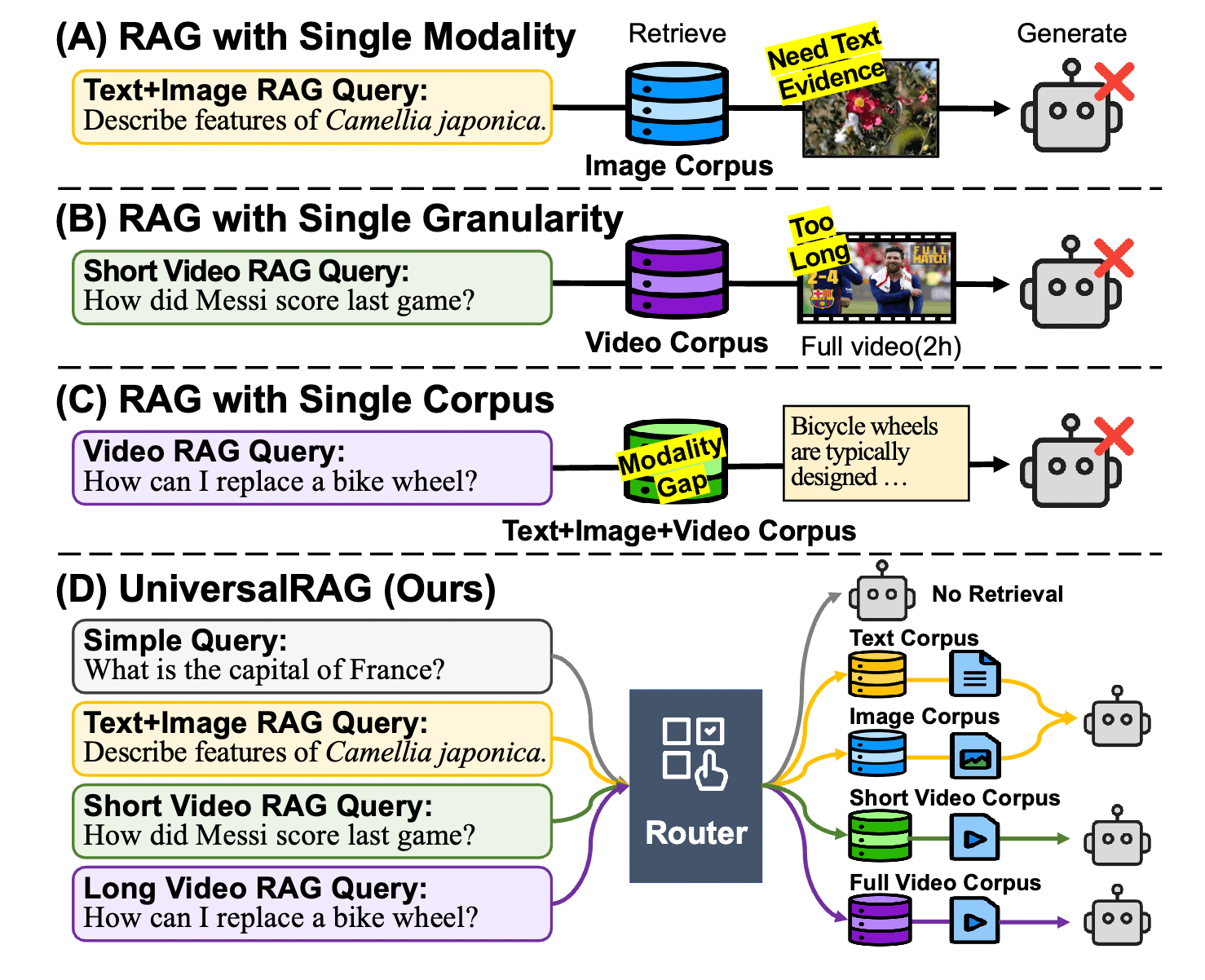
In this paper, the authors precisely identify the three core challenges currently faced by RAG systems on the path toward “universality.” As we mentioned in previous discussions, these issues become even more difficult when dealing with enterprise-level private data.
2 Problem Definition: The Three Major Bottlenecks Facing Existing RAG Systems
While RAG has significantly improved the accuracy of Large Language Models (LLMs), existing solutions typically assume that knowledge sources are single and homogeneous. However, real-world knowledge is fragmented and heterogeneous.
The following are the technical hurdles we must overcome:
2.1 Modality Limitation
Most traditional RAG systems are limited to pure text retrieval. Although some recent studies have extended this to images or videos, they usually operate only on a specific corpus of a single modality.
- Pain Point: User queries are diverse; some require consulting product manuals (text), while others require watching assembly tutorials (video). If the system can only handle a single modality, it cannot answer questions that require “cross-modal evidence.”
2.2 Modality Gap in Embedding Space
To solve multimodal problems, the most intuitive method is to use a multimodal encoder like CLIP to map text, images, and videos into the same vector space for similarity retrieval (Unified Embedding Space). However, this leads to significant modality bias.
- Phenomenon: In a vector space, data points tend to cluster based on “modality” rather than “semantics.” This means the distance between a text query and text data is often closer than its distance to more semantically relevant image data.
- Consequence: When we input a text question, the system prioritizes grabbing text content due to modality proximity, even if the most accurate answer is actually hidden in a picture or video.
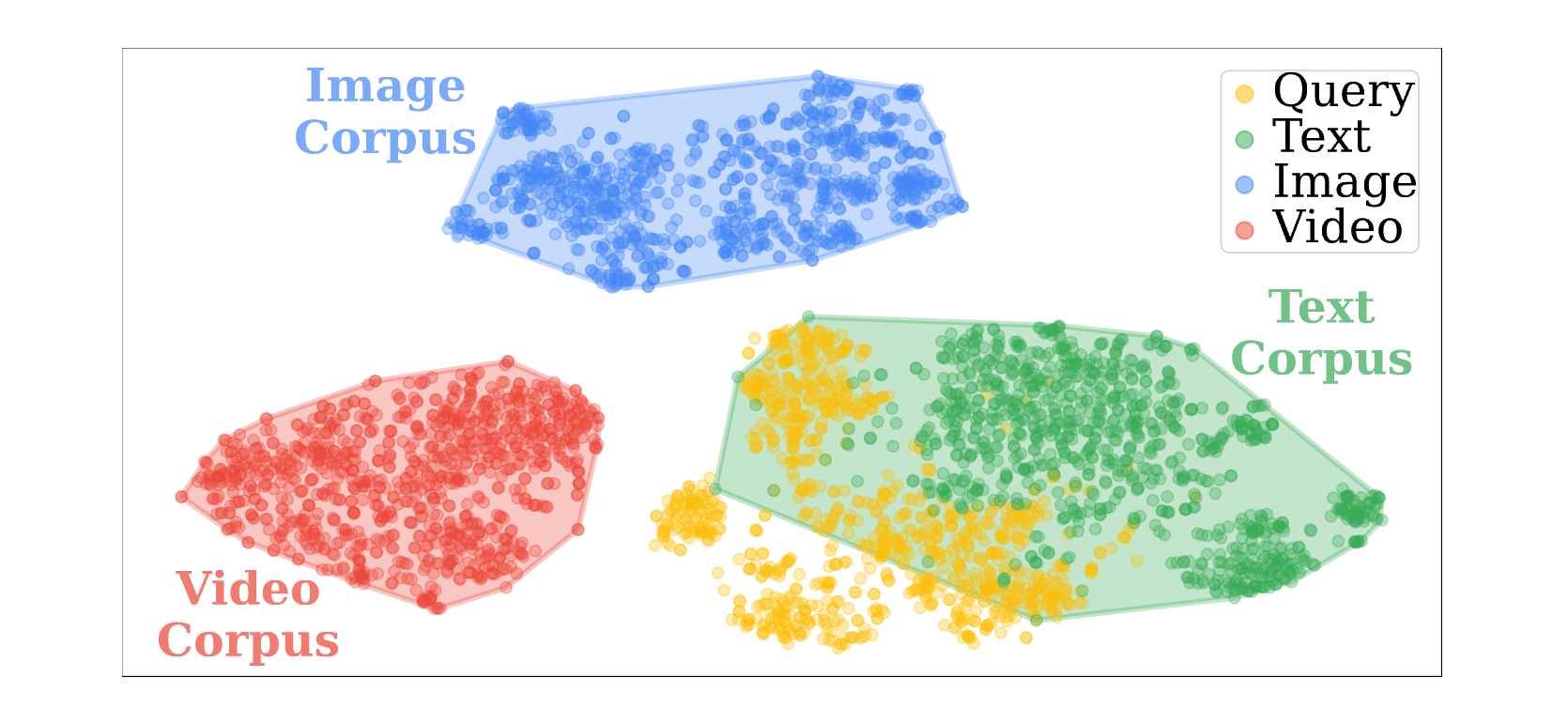
2.3 Granularity Mismatch
The “size” or “length” of data—referred to as retrieval granularity—has a decisive impact on generation quality:
- Too Fine-grained: For example, retrieving an extremely short sentence. While precise, it often lacks the context required to answer complex logical questions.
- Too Coarse-grained: For example, grabbing a full two-hour video to answer a question about a 10-second action. This introduces a large amount of irrelevant noise, interferes with model generation, and is extremely wasteful of computational resources.
Existing RAG systems are usually fixed to a single retrieval unit (such as paragraph-level) and lack the ability to adjust flexibly.
2.4 Efficiency & Scalability
When we attempt to build a “super index” containing all modalities and all granularities, retrieval latency grows linearly or logarithmically with the amount of data . When processing enterprise data at the scale of tens of millions or more, search cost and speed become unavoidable burdens.
Addressing the aforementioned challenges, UniversalRAG proposes an intelligent architecture based on “diagnose first, then prescribe.” We don’t need a universal vector space to accommodate all data; instead, we need a universal Command Center (Router) to decide where to look for data.
Below, we will delve into the logic and implementation details behind this design.
3 Methodology: The Core Architecture of UniversalRAG
The core design of UniversalRAG lies in transforming the retrieval process from a “single-space search” into “dynamic path selection.” The entire workflow can be divided into three stages: Routing, Targeted Retrieval, and Generation.
3.1 Hierarchical Organization of Modalities and Granularities
To achieve precise retrieval, we cannot simply throw data together. UniversalRAG suggests “decoupling” the database according to modality and granularity:
- Text Modality: Divided into
Paragraph(paragraph-level) andDocument(document-level, suitable for multi-hop reasoning). - Table Modality: Independent
Tableindex, specialized for structured data. - Image Modality:
Imageindex, preserving original visual features. - Video Modality: Divided into
Clip(short segments, locating specific actions) andVideo(entire video, understanding long-term temporal plots).
This organization ensures that each database can use the encoder most suitable for that modality, avoiding the modality gap caused by forced alignment.
3.2 The Router
The Router’s task is to analyze the intent of the Query and select the best combination from 7 Pathways.
3.2.1 Router’s Label Space
The Router does not perform a single-choice selection but rather a multi-label selection. It chooses from the following set of Modality-Granularity Pairs:
None: Answer directly, no retrieval needed.Paragraph: Text - Fine-grained.Document: Text - Coarse-grained.Table: Structured Table.Image: Static Image.Clip: Video - Fine-grained.Video: Video - Coarse-grained.
3.2.2 Training-based Router
When fixed hardware resources are available and high speed is required, a lightweight model (such as Qwen3-VL-2B) is fine-tuned.
- Automated Label Generation: Since real-world data lacks labels, the authors utilized inductive bias. For example, questions from
WebQAare automatically labeled asParagraph+Image. - Loss Function: This is a multi-label classification problem. We apply a Sigmoid transformation to the logic value for each category output by the model to obtain the probability : Then, Binary Cross-Entropy (BCE) is used to calculate the total loss: . Where is the ground truth label (0 or 1). During inference, a pathway is activated as long as the probability exceeds a threshold .
3.2.3 Training-free Router
This is particularly effective for the enterprise private data (OOD) scenarios we discussed. We use Prompt Engineering to let a powerful LLM (like GPT-4o) make the decision directly.

The design logic of this Prompt lies in “Intent Recognition”:
- If the question involves “comparison, summation, numerical values,” guide to
Table. - If it involves “appearance, color, structure,” guide to
Image. - Teach the model to handle complex intents (e.g.,
Paragraph+Clip) through few-shot examples.
3.3 Generation
Once the Router determines the path (e.g., Paragraph+Image), the system will:
- Parallel Retrieval: Simultaneously search for the most relevant Top-K evidence in the text paragraph library and the image library.
- Evidence Integration: Feed the retrieved text fragments and image features simultaneously into a Multimodal Large Language Model (LVLM).
- Answer Generation: The model performs comprehensive reasoning based on multimodal evidence to provide the final answer.
3.4 Why is this method effective?
The elegance of UniversalRAG lies in its solution to “Modality Bias.”
Past methods calculated similarity by putting questions and images together, but text questions are inherently more “friendly” to text data. UniversalRAG’s routing mechanism makes decisions at the “semantic level.” When the Router says, “this question requires looking at a picture,” the system only searches the image library, completely cutting off the mutual interference between modalities.
After understanding the design blueprint of UniversalRAG, we must use data to verify whether this “Command Center” strategy is truly superior to traditional approaches. The experimental results not only prove the improvement in accuracy but also reveal its efficiency advantages when processing large-scale data.
4 Experimental Results
The authors conducted extensive evaluations across 10 benchmarks covering different modalities and granularities. Below are a few key findings we believe are most noteworthy:
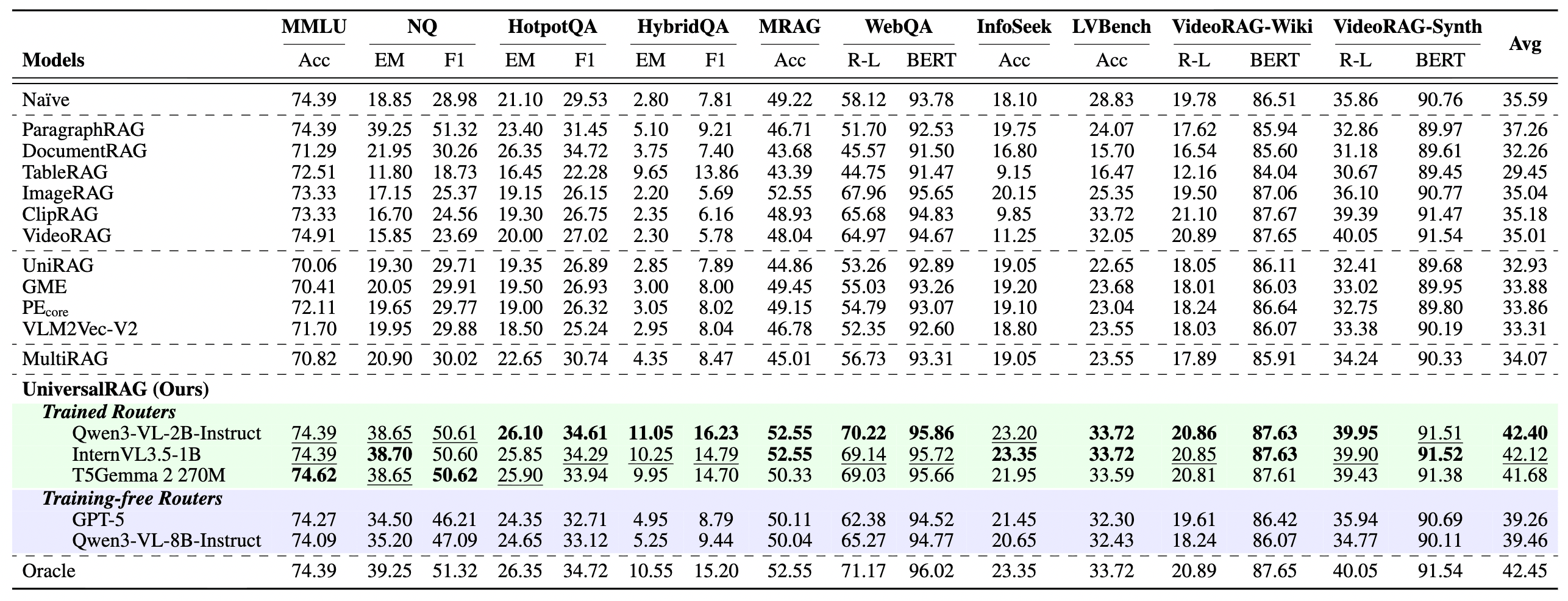
4.1 All-around Performance Leadership
Across a variety of RAG tasks, UniversalRAG demonstrated powerful dominance. Whether it was simple text queries, text-image combinations, or complex video analysis, UniversalRAG significantly outperformed single-modality RAG and traditional unified embedding space methods.
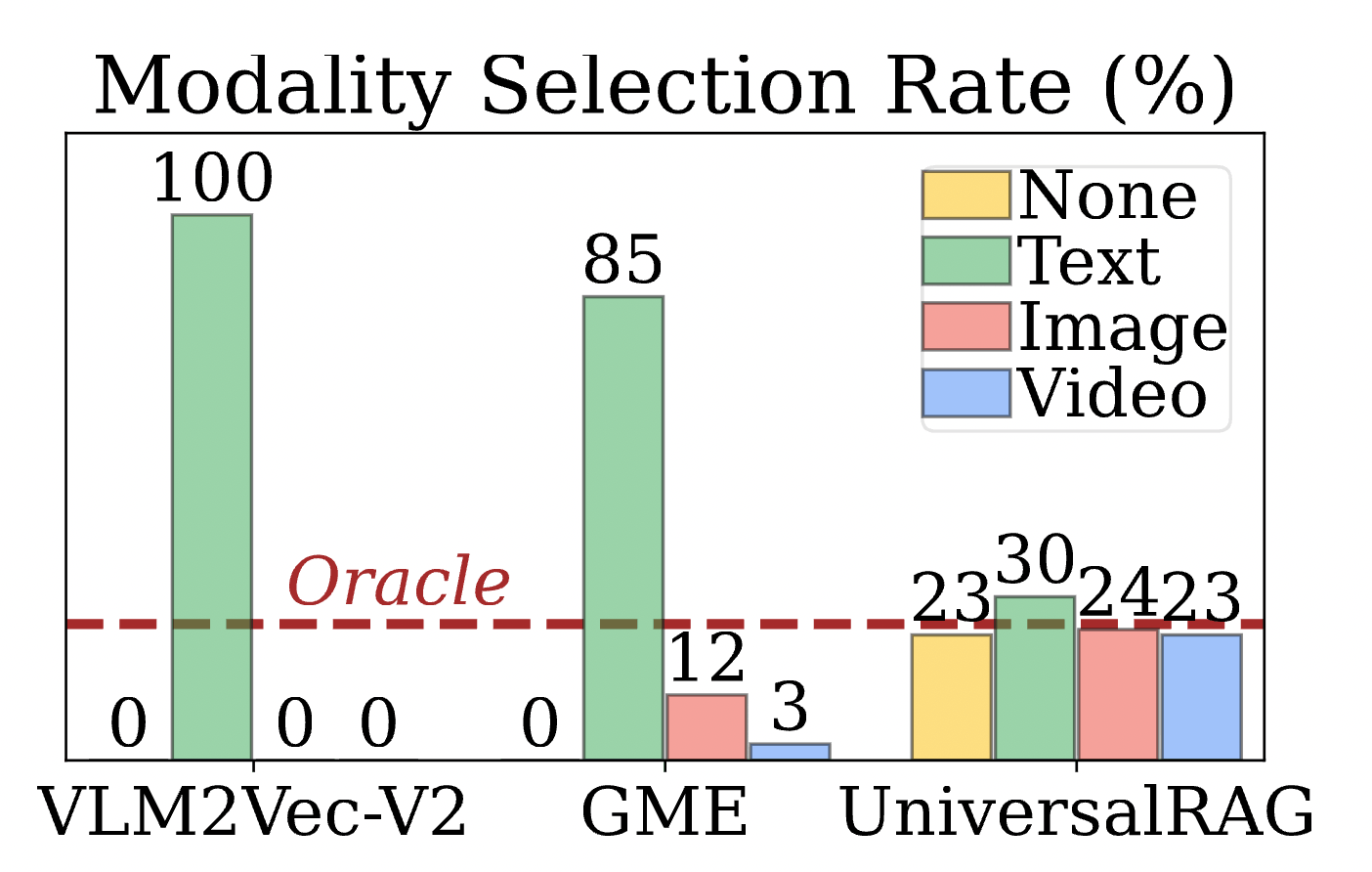
4.2 Successfully Bridging the Modality Gap
This is the core argument of our discussion: is traditional Unified Embedding truly biased? The experiment gives an affirmative answer.
- Finding: As shown in Figure 4, models like GME or VLM2Vec that squeeze all modalities together exhibit a strong “text bias” during retrieval—even when the question requires image or video evidence, they still tend to grab text.
- Comparison: UniversalRAG’s router can accurately allocate retrieval paths based on question intent. This proves that “routing before retrieval” can effectively bypass the modality gap, allowing the correct evidence to be recalled.
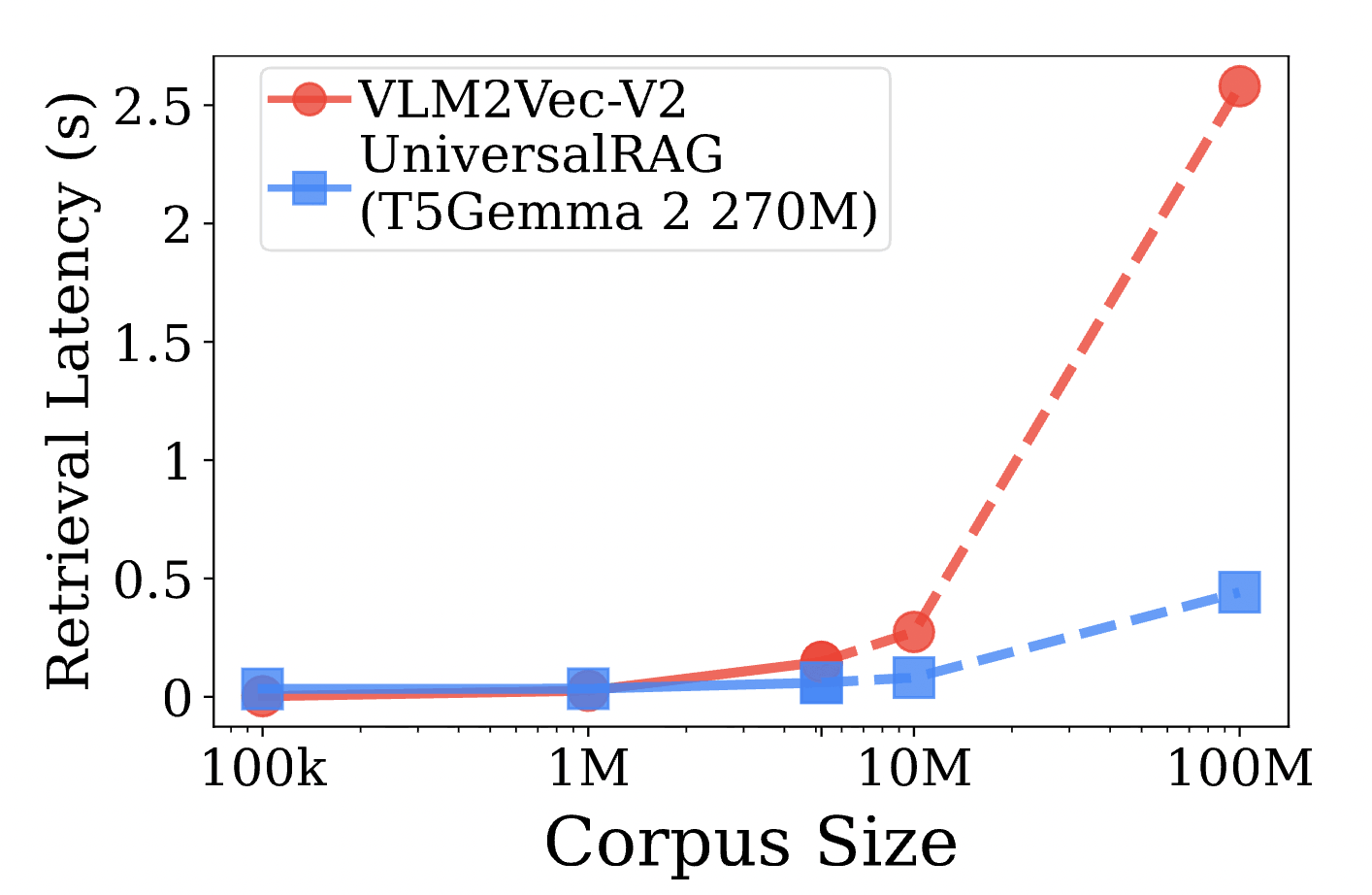
4.3 Scalability
For the enterprise-level large-scale data applications we were concerned about, Figure 5 provides very strong support.
- Sub-linear Latency: In traditional RAG, search time typically grows linearly or logarithmically as the database increases. However, in UniversalRAG, because the router filters out irrelevant libraries beforehand, the actual search range is narrowed down to .
- Big Data Advantage: When the data scale reaches tens of millions (10M) or even hundreds of millions, the latency of UniversalRAG is far lower than that of unified retrieval methods. This means the overhead of the router is completely worth it in large-scale scenarios.
After the introduction, problem analysis, methodology details, and experimental verification, we have finally reached the end of this note. This paper does not just propose a new SOTA model; more importantly, it provides us with a brand-new way of thinking about processing “heterogeneous knowledge.”
5 Conclusion
The emergence of UniversalRAG marks a significant step for RAG technology from “single corpus” toward “all-around knowledge retrieval.” Through this paper and our deep discussion, we can summarize the following three core insights:
5.1 Routing is the Silver Bullet for Modality Gaps
We used to strive for a universal “aligned vector space,” hoping that text, images, and videos could coexist in the same dimension. But UniversalRAG tells us: forced alignment brings bias. By routing at the semantic level and allowing each type of data to retain its most original and specialized representation, more fair and accurate retrieval results can be obtained. This idea of “Decoupling” is the key to solving complex multimodal problems. Interestingly, the same philosophy shows up when disentangling temporal reasoning from semantic search in MRAG, just applied to a different axis of heterogeneity.
5.2 A Win-Win for Efficiency and Accuracy
When processing large-scale data, we often worry about the system becoming bloated. UniversalRAG proves, through a “diagnosis before prescription” strategy, that adding a lightweight router (even just a scale model) will not slow down the system. Instead, it achieves “sub-linear” latency growth in large-scale corpora. This provides substantial confidence for us to deploy ultra-large-scale RAG systems in the industry.
5.3 Translation from Research to Practice
Although the paper performs excellently on benchmarks, when facing internal enterprise private data, we have summarized a more practical implementation strategy:
- Initial Phase (Cold Start): Adopt a “Prompt-based Router” combined with “Hybrid Search” to ensure system stability and recall rate.
- Middle Phase (Accumulation): Use a Teacher LLM to automatically label real User Logs, distinguishing the boundaries of Table, Text, and Image usage.
- Final Phase (Optimization): Train a lightweight router specific to the enterprise environment to achieve the true form of “UniversalRAG.”