VideoDR: Bridging the Gap Between Video Understanding and Agentic Search on the Open Web

1 Introduction
In the wave of artificial intelligence research, we have witnessed the rapid development of Video Understanding and Agentic Search. However, a gap has long existed between these two fields. The paper discussed today, “Watching, Reasoning and Searching: A Video Deep Research Benchmark on Open Web for Agentic Video Reasoning” (hereinafter referred to as VideoDR), was born to fill this piece of the puzzle. (arXiv Paper | GitHub)
1.1 One-Minute Summary
This paper defines a brand new task — Video Deep Research. Unlike the closed-ended Q&A of the past where “the answer is in the video,” this task requires AI models to first extract visual clues (Visual Anchors) from the video, convert them into search queries, and perform multi-step retrieval and reasoning on the Open Web to find the final answer. The authors constructed a high-difficulty Benchmark that underwent a rigorous “Double Ablation Test” and compared two mainstream paradigms: Workflow and Agentic, revealing the “Goal Drift” challenge models face when dealing with long-sequence tasks.
1.2 Core Value
Before we dive deep, we must clarify what “pain points” this paper solves.
Breaking the “Closed Evidence” Limitation: Traditional Video LLM evaluations (like Video-MME) assume all answers are inside the video. But in real life, videos are often just an “intro.” For example, seeing a nameless statue in a travel Vlog and wanting to know its historical background. This requires the model to step out of the video and into the web.
Bridging the “Text-Only Search” Gap: Existing Search Agents (like Search-o1) mostly start from text questions. However, visual information is irreplaceable. Often, we cannot precisely describe an object in a video using text and must rely on the model’s understanding and extraction of “multi-frame visual signals.”
A Reality Check for Agent Architectures: The industry has been debating whether to use stable Workflows or flexible Agents. This paper provides a fair arena that lets us see the boundaries of both clearly.
1.3 Guide: Most Surprising Insights
What impressed us most about this paper was not a specific new model architecture, but its profound analysis of the nature of the problem and counter-intuitive experimental results. Here are two core perspectives running through the entire paper:
The most brilliant part of VideoDR lies in its “cleanliness” regarding datasets. The authors filter data through a negative definition:
- If it can be answered by watching the video without going online -> Delete (This is traditional Video QA).
- If it can be answered by going online without watching the video -> Delete (This is Text Search).
What remains are those questions where one must first understand the visual hints (Visual Anchors) in the video to construct effective search strategies.
2 Problem Definition
2.1 Status Quo Fracture: Two Isolated Islands
Before delving into VideoDR, we must understand why the field needs this paper. Before VideoDR appeared, multimodal AI research seemed split into two unconnected islands:
- Island A: Closed Video QA
- Status: Traditional Benchmarks (like Video-MME, MVBench) assume the answer is in the video. The model only needs sufficient visual perception capabilities to extract answers from visuals, subtitles, or narration.
- Pain Point: This is detached from reality. When we finish watching a travel Vlog and want to know “the reservation number for that restaurant in the video” or “the history of that statue,” this information is simply not in the video.
- Island B: Pure Text Deep Search
- Status: Existing Agent evaluations (like GAIA, Search-o1) mostly start from text instructions. Even if they support multimodality, they often only deal with static screenshots.
- Pain Point: They lack perception of the Temporal Dimension. These models cannot understand that “the building appearing at minute 5” and “the interior appearing at minute 10” are the same location, nor can they extract search clues from dynamic visual flows.
2.2 Core Pain Point: The Missing Link
We found that real-world Video Question Answering is often Open-domain Factoid. This means:
- Knowledge is on the Web: Answers are distributed across the massive information on the internet, not within the video.
- Index is in the Video: Search keywords must be generated by understanding visual details (Visual Anchors) in the video.
Past models either “only understood videos but couldn’t go online” or “only understood surfing the web but couldn’t understand time series.” VideoDR’s core insight is to forcibly bind these two, filling the vacuum between “Video Perception” and “Web Search.”
3 Methodology
To test whether models possess this comprehensive “Watch + Search” capability, the authors didn’t propose a new model but carefully designed a set of evaluation tasks and a data construction process. This is the essence of the paper’s methodology, especially its data filtering logic, which is full of design ingenuity.
3.1 Task Definition
First, we use mathematical language to precisely describe this task. VideoDR defines the task as a function :
Where each variable represents a specific constraint:
- (Video): The input video. It is the starting point (Anchor) for all reasoning.
- (Question): A natural language question. This question is designed so it cannot be answered directly by or external common sense alone.
- (Search Tool): Browser search tool. This is the model’s only way to acquire external knowledge .
- (Answer): The final factual output, which must be unique and verifiable.
Two key operational steps are hidden behind this formula, which are also points we repeatedly emphasize in our discussion:
- Visual Anchor Extraction: The model must first “watch” the video and translate vague visual signals (like “that red domed building”) into concrete textual entities (like “St. Paul’s Cathedral”).
- Multi-Hop Reasoning: The model cannot just search once. It usually requires iterative interaction of
Video -> Web -> Video -> Web. For example: First confirm the location (Web), then look back at the video to confirm the route (Video), and finally search for specific shops on that route (Web).
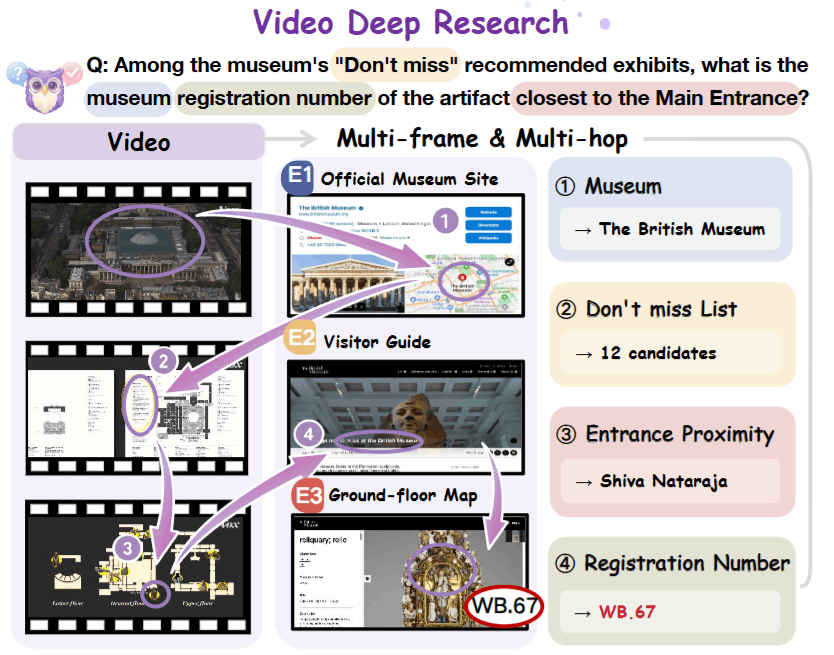
3.2 Data Construction: Funnel Filtering
The most brilliant part of this paper lies in the creation of the dataset. The authors do not pursue quantity (only 100 questions in the end), but rather extreme quality.
3.2.1 Negative Sample Filtering
Before human annotation, “cheating” possibilities are eliminated:
- Exclude Single Scene: Lack of necessity for temporal reasoning.
- Exclude Trending Topics: This is to prevent models from answering directly using world knowledge in their training data (e.g., “Taylor Swift 2024 Concert Location”). We require the model to rely on the current video content.
- Exclude Isolated Content: Videos for which no other information can be found online.
3.2.2 Double Ablation Test
This is the gold standard of VideoDR. Every annotated sample must pass two rigorous tests to survive:
Web-only Test:
- Operation: Give humans only and search tool , without the video .
- Verdict: If it can be answered correctly, it means the question has leaked information (Information Leakage) -> Delete.
- Purpose: Ensure the question has Visual Dependency.
Video-only Test:
- Operation: Give humans only and , without allowing web search.
- Verdict: If it can be answered correctly, it represents traditional Video QA -> Delete.
- Purpose: Ensure the question has External Knowledge Dependency.
Only samples that pass both tests simultaneously possess “Dual Dependency,” which is the unique feature of the VideoDR dataset.
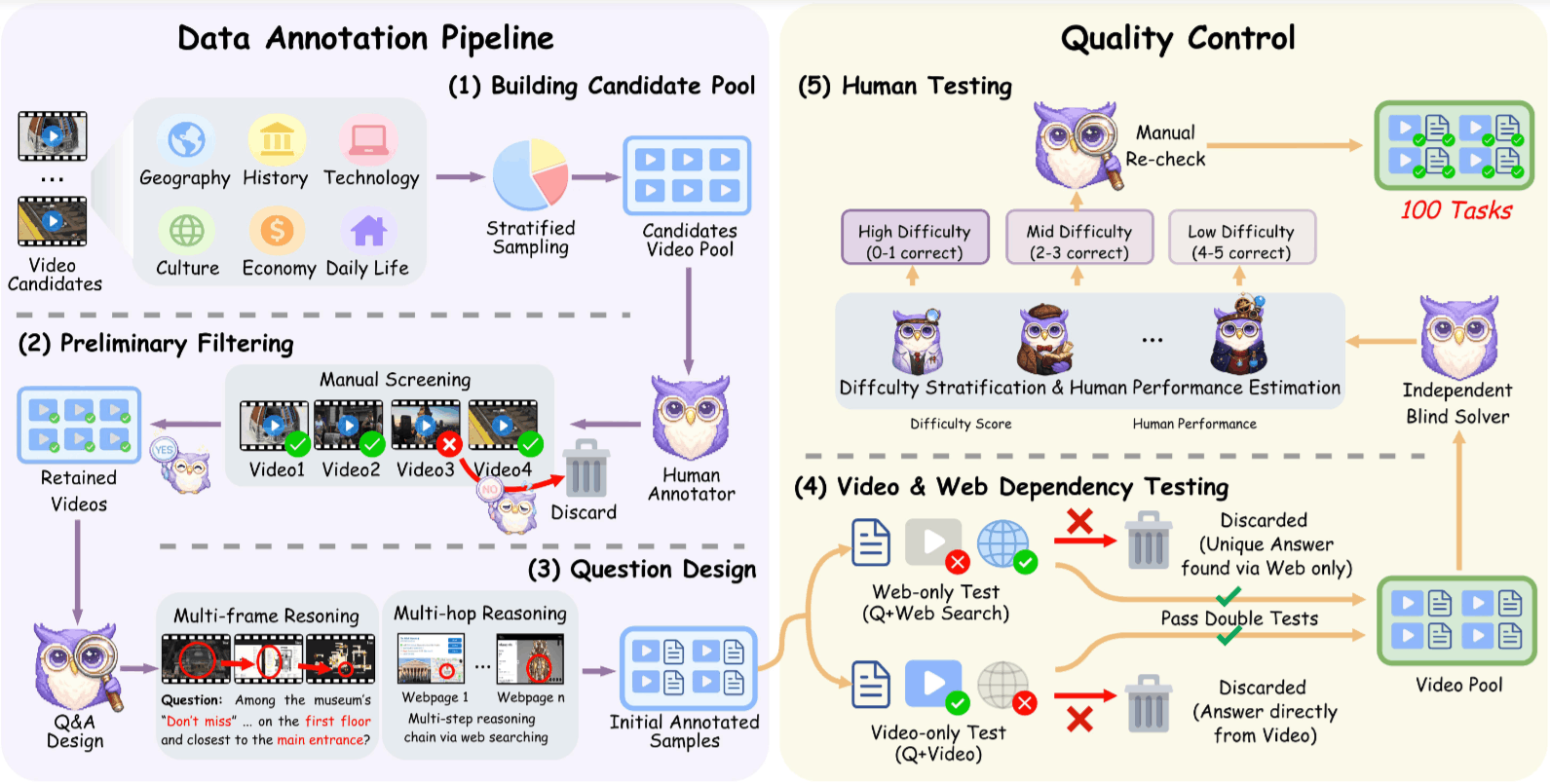
3.3 Evaluation Paradigms: Workflow vs. Agent
The authors standardized two problem-solving strategies in the experiment:
3.3.1 Paradigm A: Workflow
This is a “Note first, search later” strategy.
- Perception Phase:
- The model reads video (converted to Visual Tokens).
- Based on question , it generates a detailed structured intermediate text describing key visual clues in the video.
- Key Operation: After generating the text, discard the original video .
- Reasoning Phase:
- The model uses only the generated text above and question , utilizing the search tool to find the answer.
- Implementation Detail: This stage does not use RAG to retrieve video frames but relies on the Long Context capability of MLLMs to read and summarize the video in one go.
3.3.2 Paradigm B: Agent
This is a “Continuous conversation with memory” strategy.
- Initialization: Put the Visual Tokens of video at the beginning of the Context.
- ReAct Loop: The model enters a
Whileloop:- Observe Context (containing original video tokens).
- Generate Thought and Action.
- Execute search, Append Observation (web summaries) to the end of the Context.
- Decision: The model autonomously decides when to stop searching and output the answer.
- Implementation Hazard: The Context structure is
[Video Tokens] + [History] + [Search Results]. As the number of searches increases, more and more text accumulates at the end of the Context, diluting the model’s attention to the initial Visual Tokens, leading to the Goal Drift phenomenon we observed.
4 Experimental Results
The experimental part of this paper is not to prove “a certain new model is SOTA,” but to answer a more fundamental question: “When dealing with video tasks requiring long-time reasoning, should we convert the video to text (Workflow) or let the large model handle it end-to-end (Agent)?”
The authors selected current mainstream closed-source models (GPT-4o, Gemini-1.5 Pro) and open-source models (Qwen2-VL, MiniCPM-V, etc.) for a “duel” under both Workflow and Agent paradigms.
4.1 Agent is Not a Panacea
This is probably the most surprising discovery in the experiment. Intuitively, we think letting the model decide when to watch and when to search (Agent) should be stronger than rigid steps (Workflow), but the data tells a different story.
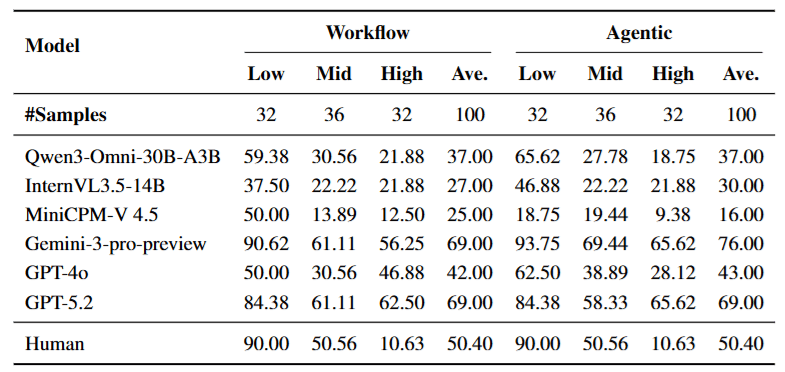
- The Strong Get Stronger: For models with ultra-long Context Windows and powerful reasoning capabilities like Gemini-1.5 Pro, switching to Agent mode brought significant improvement (accuracy rose from 69% to 76%). It can effectively navigate complex interaction loops.
- The Weak Collapse: For capable but weaker or open-source models (like MiniCPM-V 4.5), after switching to Agent mode, performance actually plummeted (from 25% to 16%).
- The Story Behind the Data: This proves that Agent is a double-edged sword. For weaker models, the “structured intermediate text” produced by Workflow, although losing some details, provides a Stable Anchor. Once this anchor is removed and the weak model directly faces massive search results and original Video Tokens, its attention mechanism gets “lost.”
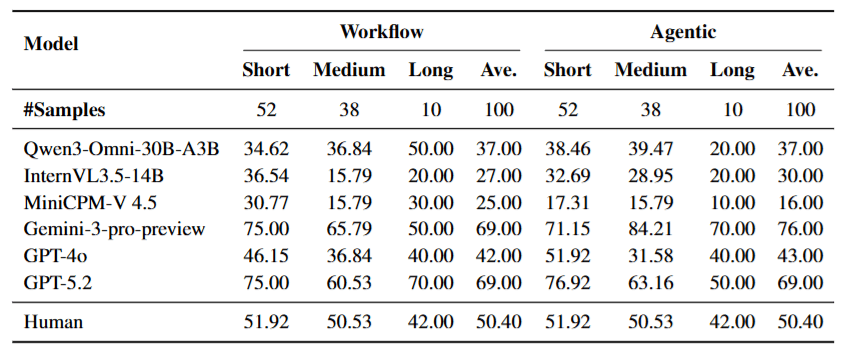
4.2 Goal Drift: The Curse of Long Videos
To delve deeper into “why Agents fail,” the authors analyzed the results stratified by video duration.
4.3 Error Analysis: The Loss of Visual Anchors
The authors further analyzed error types, and the data again corroborated the above view.
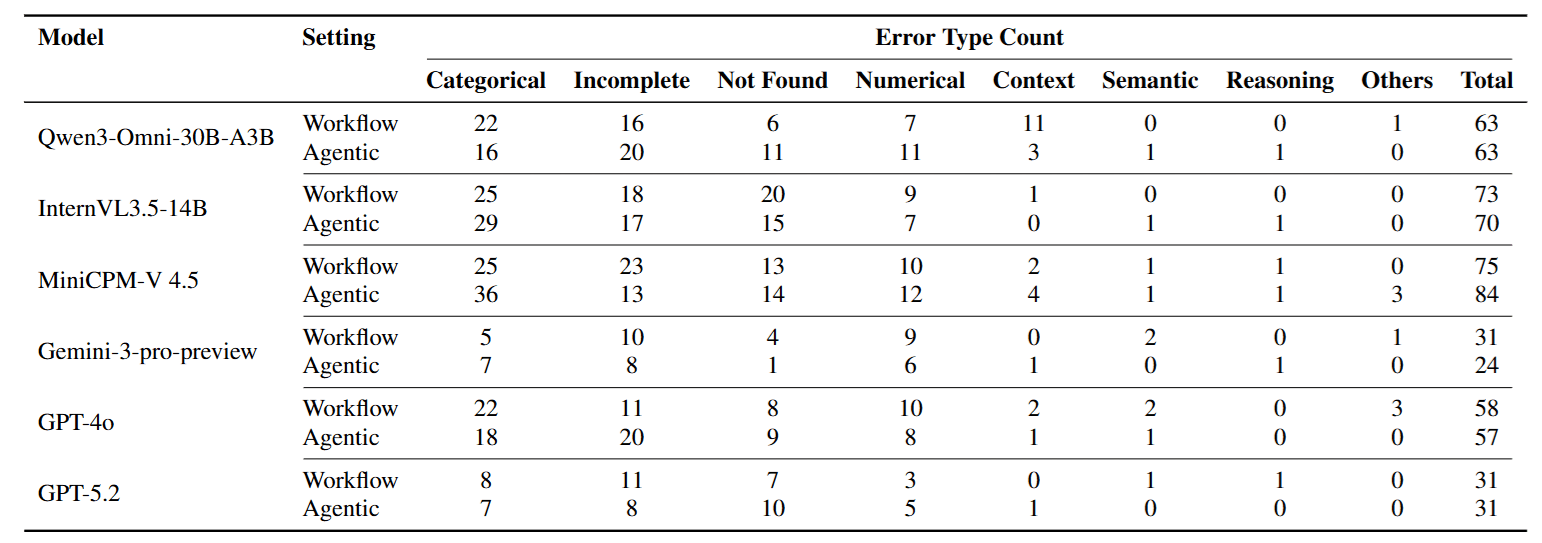
- Categorical Error has the highest proportion.
- This means the model didn’t “miscalculate a value” or have a “logic error,” but looked for the wrong object from the start (e.g., question asked about Museum A, model went to search for Museum B).
- This directly proves that after multi-round searching, the model lost the Visual Anchor extracted from the video. Once the initial visual lock fails, subsequent reasoning, no matter how strong, is futile.
4.4 Efficiency Analysis: Busy Does Not Mean Effective
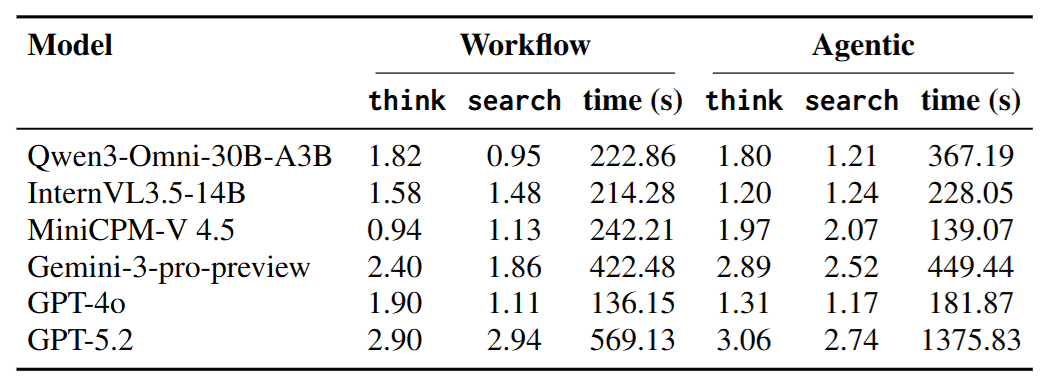
- Ineffective Retrieval: Some open-source models saw a surge in search counts in Agent mode, but accuracy did not rise; it fell. This indicates they are conducting ineffective “spray and pray” tactics.
- Effective Reflection: Gemini, which performed best, had significantly more Thinking Steps. This tells us that in Video Deep Research, “Stopping to Reflect” (e.g., reflecting: “Does the information I found match the image in the video?”) is more critical than blind searching.
5 Conclusion
This paper successfully fills the gap between Video QA and Deep Research.
- Problem: Solved the pain point where “visual perception” and “external search” are disconnected in existing evaluations.
- Method: Proposed the VideoDR task, using rigorous “Double Ablation Filtering” to construct a dataset that must rely on both video anchors and web evidence simultaneously.
- Discovery: Through comparative experiments of Workflow and Agent, revealed that Long-horizon Consistency and Goal Drift are the biggest bottlenecks for current multimodal Agents.