VIME Explained: Supercharge Your Tabular Models with Self-Supervised Learning

1 Introduction
In this article, we’ll dive into a paper published at NeurIPS 2020: VIME: Extending the Success of Self- and Semi-supervised Learning to Tabular Domain.
If you’re a researcher in the fields of Computer Vision (CV) or Natural Language Processing (NLP), you’re likely no stranger to Self-Supervised Learning. Through Self-Supervised Learning, we can more effectively use unlabeled data to “pre-train” our models, giving them good initial parameters. This leads to better performance when the model is further fine-tuned on a downstream task.
The VIME paper aims to apply the techniques of Self-Supervised Learning to the tabular domain, enabling models to maintain good predictive power even with a small amount of labeled data. Using VIME’s approach, a model can learn high-level representations from unlabeled data, thereby boosting its performance. If you’re looking for a way to apply Self-Supervised Learning to tabular data, VIME could be an excellent starting point!
2 What Problem Does VIME Aim to Solve?
First, let’s understand the problem VIME seeks to address: When you have very little labeled data but an abundance of unlabeled data, training a model solely on the labeled portion can easily lead to overfitting. What can be done in this situation? In such scenarios, how we can effectively leverage the unlabeled data to improve model performance is a critical challenge.
As mentioned earlier, VIME’s goal is to tackle this very problem by applying Self-Supervised Learning techniques to the tabular domain for better model performance. Therefore, if your current project involves tabular data and a shortage of labeled samples, the ideas behind VIME are well worth considering!
3 VIME’s Solution: Self-Supervised and Semi-Supervised Learning
Now that we understand the problem VIME wants to solve, let’s look at its proposed solution. To handle unlabeled data, VIME employs two approaches: Self-Supervised Learning and Semi-Supervised Learning.
Through Self-Supervised Learning, VIME designs two pretext tasks, Feature Vector Estimation and Mask Vector Estimation, which compel the Encoder to learn meaningful information from the original data. This, in turn, generates better representations to aid the Predictor in its predictions.
Additionally, for the Semi-Supervised Learning part, VIME introduces an unsupervised loss, allowing the Predictor to learn from both a supervised loss and this unsupervised loss simultaneously. Specifically, VIME proposes feeding both the original sample and a corrupted version of it to the Predictor and then comparing their outputs to increase the model’s robustness.
In short, VIME’s Self-Supervised and Semi-Supervised Learning methods effectively utilize unlabeled data to improve the model’s prediction accuracy in situations where labeled data is scarce and unlabeled data is plentiful.
4 A Deep Dive into Self-Supervised Learning in VIME
How does Self-Supervised Learning work in VIME? Let’s take a closer look!
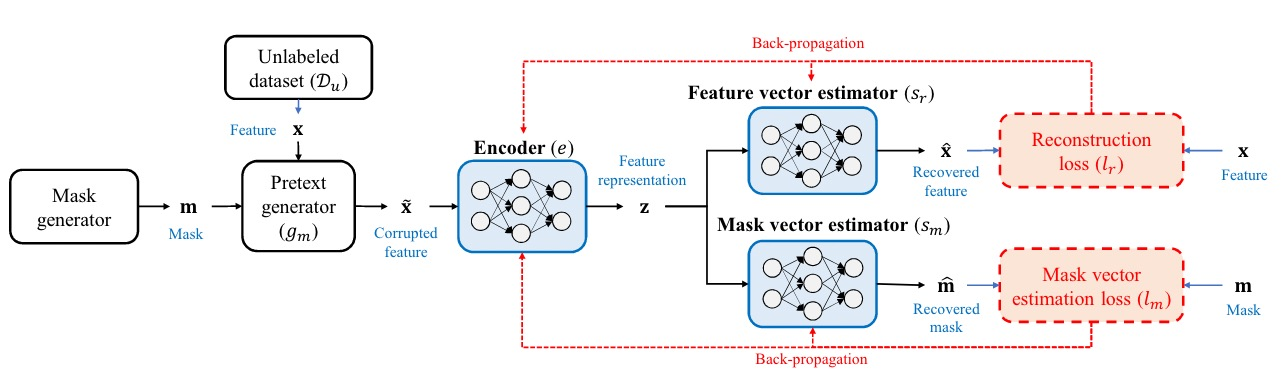
First, a raw sample is taken from the unlabeled dataset. Let’s assume it has 256 dimensions. Next, a Mask Generator randomly creates a Mask Vector of the same dimension. This Mask Vector determines which elements of the sample to keep and which to replace. Then, a Pretext Generator calculates the new values for the elements that are to be replaced.
This processed raw sample now becomes a Corrupted Sample. It is fed into an Encoder to generate a feature representation, which is then passed to two different MLPs (with different parameters): the Feature Vector Estimator and the Mask Vector Estimator.
The Feature Vector Estimator performs Feature Vector Estimation, where it must reconstruct the original raw sample from the feature representation. Meanwhile, the Mask Vector Estimator performs Mask Vector Estimation, aiming to reconstruct the Mask Vector from the same feature representation.
Through this Self-Supervised Learning process, the Encoder can learn the interactions between features within a sample and generate a high-quality representation that contains key information, such as:
- Which elements were masked and which were not: This helps the Mask Vector Estimator with its predictions.
- The relationship between the masked and unmasked elements: This helps the Feature Vector Estimator reconstruct the original sample.
Through this pretext task training, VIME achieves its goal of effectively utilizing unlabeled data.
5 A Deep Dive into Semi-Supervised Learning in VIME
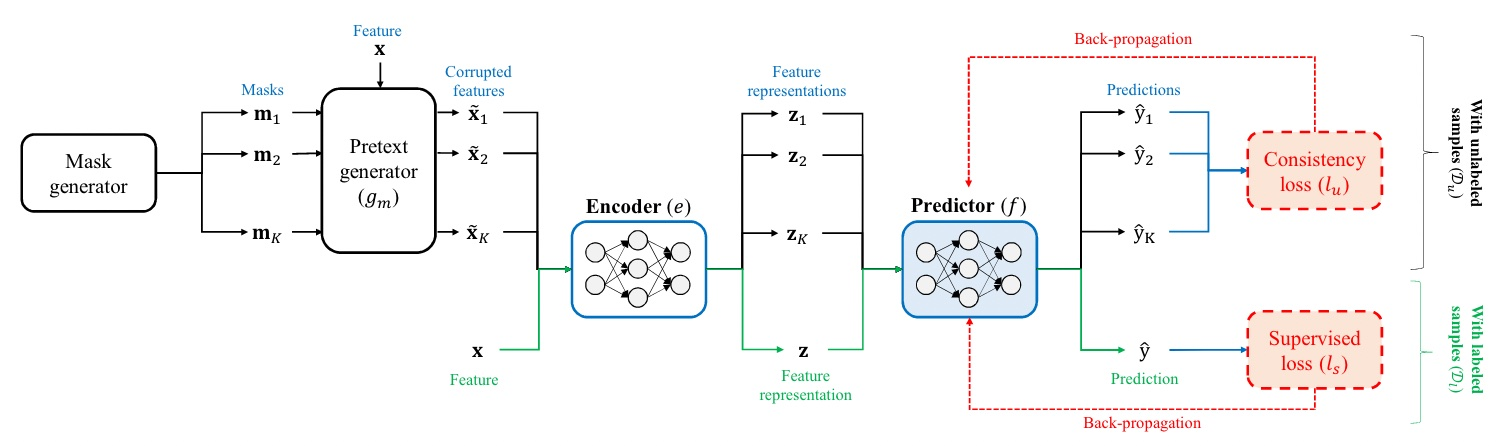
Finally, let’s understand how Semi-Supervised Learning works in VIME! In VIME, Semi-Supervised Learning is primarily used to train the Predictor. The Predictor learns not only from a Supervised Loss but also from a Consistency (Unsupervised) Loss. The raw sample is passed through the Encoder to produce a “good” feature representation, which the Predictor then uses to make a prediction. The goal is to make this output as close to the true label as possible.
Since the amount of labeled data is very small, training the Predictor on it alone would lead to overfitting. This is where the Consistency (Unsupervised) Loss comes in handy: the raw sample is processed by the Mask Generator and Pretext Generator to become a Corrupted Sample.
It’s worth noting that for each raw sample, K different Mask Vectors are used to generate K corrupted samples. These K corrupted samples are each fed into the Encoder to produce K feature representations. The Predictor then makes K predictions. The Unsupervised Loss is calculated based on the difference between these K predictions and the original prediction. The Predictor’s task is to learn to produce similar prediction results even from the feature representations of corrupted samples. This is how Semi-Supervised Learning in VIME enhances the model’s generalization ability using only a small amount of labeled data.
6 Conclusion
VIME applies Self-Supervised and Semi-Supervised Learning to the tabular data domain to make more effective use of unlabeled data.
In its Self-Supervised Learning component, VIME designs two pretext tasks: Feature Vector Estimation and Mask Vector Estimation. A Mask Generator and a Pretext Generator process the unlabeled data to create corrupted samples, which are then used by an Encoder to extract crucial feature representations.
In its Semi-Supervised Learning component, VIME designs an unsupervised loss that allows the Predictor to learn from corrupted samples, preventing it from overfitting on the small set of labeled data.