WebResearcher: Redefining Deep Research through the Art of Iterative State Reconstruction

1 Introduction

1.1 From “Passive Retrieval” to “Active Knowledge Construction”
On the path toward Artificial General Intelligence (AGI), both academia and industry are undergoing a Paradigm Shift. In the past, the core of LLM development revolved around the Scaling Law—accumulating passive knowledge by expanding parameters and data volume, granting models incredible memory and retrieval capabilities.
However, true human intelligence is manifested in “Active Knowledge Construction.” This means AI should not merely recite content from a training set; it must act like a senior researcher: autonomously decomposing complex problems, orchestrating diverse tools (search, computation, code), verifying conflicting information, and ultimately synthesizing a logically rigorous in-depth report. Systems capable of such “long-horizon” tasks represent the current frontier of Deep Research — though as VideoDR points out, this frontier is still mostly text-only, and extending it to video brings its own set of challenges.
1.2 Current Industry Status: Monopoly of Closed-Source Giants vs. the Open-Source Dead End
Currently, the Deep Research field is dominated by closed-source systems like OpenAI Deep Research, Gemini Deep Research, Grok DeepSearch, and Kimi Researcher. While these systems perform exceptionally well on extremely difficult benchmarks like Humanity’s Last Exam (HLE), their underlying architectures remain a “black box” to the outside world.
In contrast, the open-source community (e.g., WebThinker, WebSailor) has attempted to keep pace but has generally fallen into a technical dead end known as the “Mono-contextual Paradigm”:
- The Curse of Linear Accumulation: These agents tend to continuously append all search records, raw HTML, and reasoning processes into a single prompt.
- The Flaw in Technical Intuition: Many developers believe in the “longer context window is always better” myth, assuming that as long as the context is large enough, the model can process infinite information.
1.3 Core Challenge: “Intelligence Degradation” via Information Explosion
The paper pinpointed that this linear accumulation architecture triggers two fatal flaws when handling complex research:
- Cognitive Workspace Suffocation: As search steps increase, the prompt becomes cluttered with low-value noise (e.g., website menus, formatting code). This severely dilutes the focus of Self-Attention, causing the model to “lose focus” during critical decision-making and produce Premature Conclusions.
- Irreversible Noise Contamination: In a context window without a “delete/rewrite” mechanism, early incorrect inferences or false webpage information snowball, affecting every subsequent step and leading to Error Propagation.
1.4 The Core Mission of WebResearcher
Published by Tongyi Lab, WebResearcher was created to break these “linear accumulation” shackles. It proposes a solution: redefining Deep Research as a Markov Decision Process (MDP).
- Instead of keeping a long, redundant history, it uses an IterResearch mechanism to “distill the essence and reconstruct the workspace” in every research round.
- It also developed the WebFrontier data engine to mass-produce high-quality trajectories, solving the problem of scarce training data.
In summary: WebResearcher proves that for an Agent to possess “unbounded” research capabilities, the ability of a model to “gracefully forget noise and precisely distill memory” is just as crucial as the size of the Context Window.
2 Core Pain Point: The “Linear Accumulation” Achilles’ Heel of Traditional Agents
2.1 Mono-contextual Paradigm
Most existing open-source agents (such as early AutoGPT, WebThinker, and WebExplorer) follow an intuitive but inefficient architecture: “Linear Accumulation.”
Under this paradigm, every round of the agent’s output (Thought, Action) and external environment feedback (Observation, HTML source code) is indiscriminately appended to the same context window.
Technical Characteristic: As search steps increase, context length grows linearly at . Developers often hope Long-context LLMs can mine gold from this mountain of information, but reality triggers a severe technical paradox.
2.2 Cognitive Workspace Suffocation
This is a physical limitation determined by the underlying Attention mechanism of the Transformer.
- Attention Dilution: When the context is filled with tens of thousands of tokens of raw webpage data, advertisement text, and irrelevant navigation menus, the attention weights for the “core problem” and “key clues” are drastically diluted. This is not just a length issue; it is a collapse of the Signal-to-Noise Ratio (SNR).
- Lost in the Middle: Research shows models have the strongest perception of the beginning and end of a prompt. In long-horizon research, the most important “initial question” is at the start, and the latest “key evidence” is at the end, while the middle is filled with search noise. This causes the model to forget its original intent from step 1 by the time it reaches step 20.
- Premature Conclusions: When the workspace is stuffed, the model feels immense “cognitive pressure.” To comply with output length limits or avoid further noise, it tends to provide a superficial conclusion before fully exploring the topic. This is why traditional agents often “scratch the surface” of complex problems without going deep.
2.3 Irreversible Noise Contamination
In traditional prompting mechanisms, the context is append-only. This creates a serious path-dependency problem.
- Error Propagation:
If an agent believes a webpage containing false information at step 3, or generates a logically flawed
Thought, that error remains in the context forever as a “factual basis” for all subsequent reasoning. - Lack of “Memory Modification” Capability: Traditional agents cannot perform “Delete” or “Overwrite” operations. Even if the model realizes at step 10 that step 3 was wrong, that erroneous record still interferes with its attention. This noise snowballs, causing the entire reasoning chain to disintegrate in long-horizon tasks.
2.4 Capability Gap
Beyond architectural issues, the paper highlights a key data gap: Passive Recall vs. Active Construction.
- Defects in Existing Data: Most SFT datasets train models to “extract knowledge from within (Passive Recall).”
- Deep Research Requirements: True research requires the model to possess capabilities for “cross-source evidence alignment,” “computational verification,” and “contradiction handling” (Active Construction).
- Because traditional agents lack specialized training in these “PhD-level research trajectories,” they behave like clumsy porters rather than shrewd analysts, regardless of how long their context window is.
3 IterResearch: Iterative Research Architecture
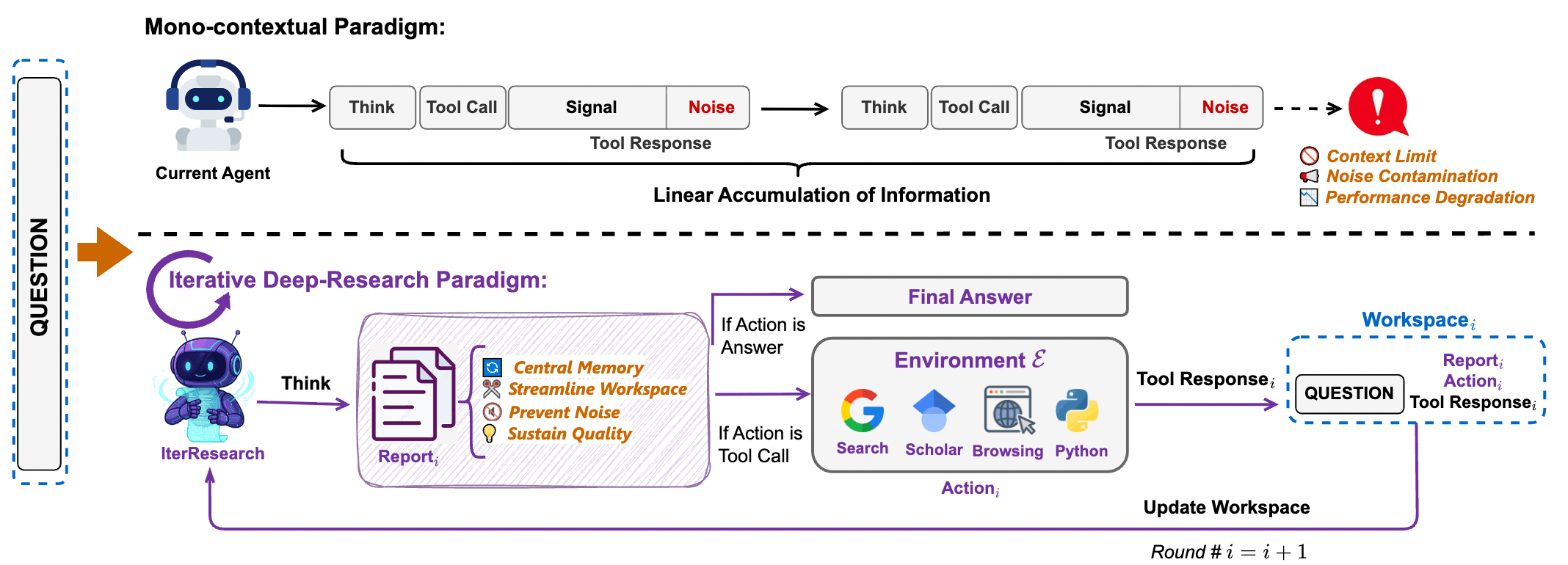
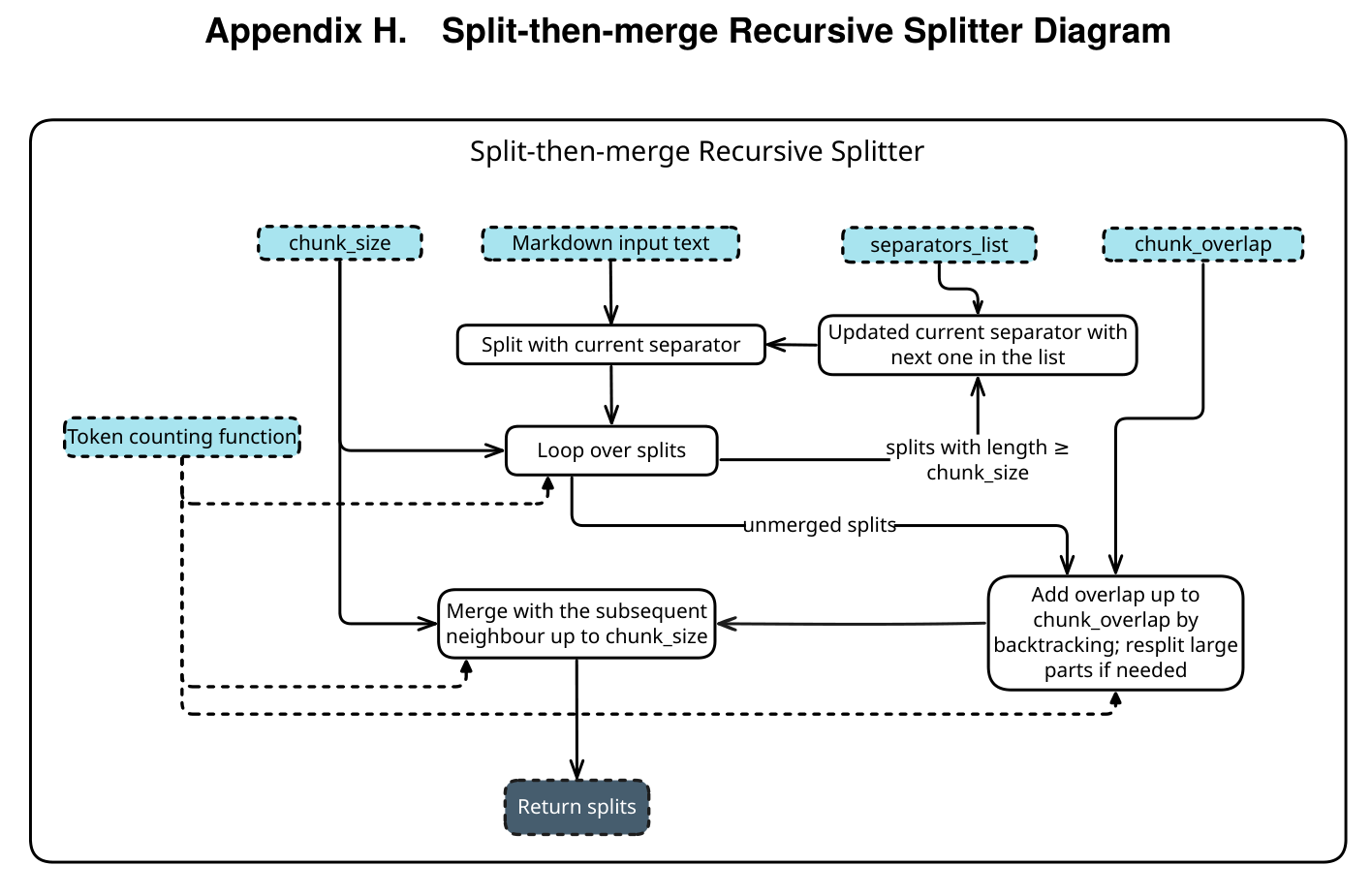
3.1 Core Philosophy: From “Stacking History” to “Reconstructing State”
The most disruptive innovation of WebResearcher is its complete abandonment of the “Append-only” mindset of traditional agents, opting instead to remodel Deep Research tasks as a Markov Decision Process (MDP).
3.2 State Reconstruction: Maintaining Cognitive Pressure
At the beginning of each research round (Round ), the system actively “cleans” the workspace for the model, reconstructing an extremely streamlined Workspace.
- Components of the Workspace (Input State ):
- Original Question (): Ensures the model never loses sight of its original goal.
- Latest Report (): The distilled progress report from the previous round (the only long-term memory).
- Last Tool Response (): The most recent tool call instruction and its raw returned result (e.g., 5 search results or Python execution data).
- Discarded Content:
- All
Thinkprocesses (internal monologues) from previous rounds. - All historical
ActionandObservation(raw webpage data) except for the final round.
- All
This design reduces the growth of the Context Window from to . Whether the research is at step 10 or step 200, the number of tokens the model processes remains within the optimal Attention range.
3.3 Structured Output: The Think-Report-Action Symphony
The model is required to output in a fixed structured format. These three parts each serve a specific role in the agent’s cognitive cycle:
Think(Cognitive Draft / Temporary Memory):- Role: The model’s internal Chain of Thought (CoT).
- Function: Analyzing if the latest
Obssolved the problem? Are there new clues? What should be the next step? - Fate: Destroyed after the current round ends. It serves as a “ladder” for generation—once used, it is removed to prevent useless thought processes from interfering with future judgments.
Report(Central Memory / Persistent State):- Role: A “Live Document” for the research project.
- Function: The model must synthesize new knowledge from
Obswith the oldReport. It performs deduplication, corrects conflicts, supplements data, and distills conclusions. - Value: It is the only “essence” carried into the next round, ensuring High Signal-to-Noise Ratio (High SNR).
- Note: This curated-memory pattern faces the same risk as the “Context Collapse” problem discussed in Agentic Context Engineering and Dynamic Cheatsheet — if the summarization step is too aggressive, valuable detail can be lost along with the noise.
Action(Specific Action / Environmental Interaction):- Role: The executor.
- Function: Deciding the next tool (Search, Scholar, Visit, Python) or providing the Final Answer when evidence is sufficient.
3.4 Technical Logic Comparison: Linear vs. Iterative
# Traditional Mono-contextual (Heavy historical burden)
[Question] -> [T1, A1, O1] -> [T1, A1, O1, T2, A2, O2] -> ... -> [T1...On]
# WebResearcher IterResearch (Always stays sharp)
Round 1: [Question, Empty_Report] -> Output: [T1, R1, A1]
Round 2: [Question, R1, A1, O1] -> Output: [T2, R2, A2] # T1 discarded, O1 absorbed by R2
Round 3: [Question, R2, A2, O2] -> Output: [T3, R3, A3] # T2 discarded, O2 absorbed by R34 WebFrontier Data Engine
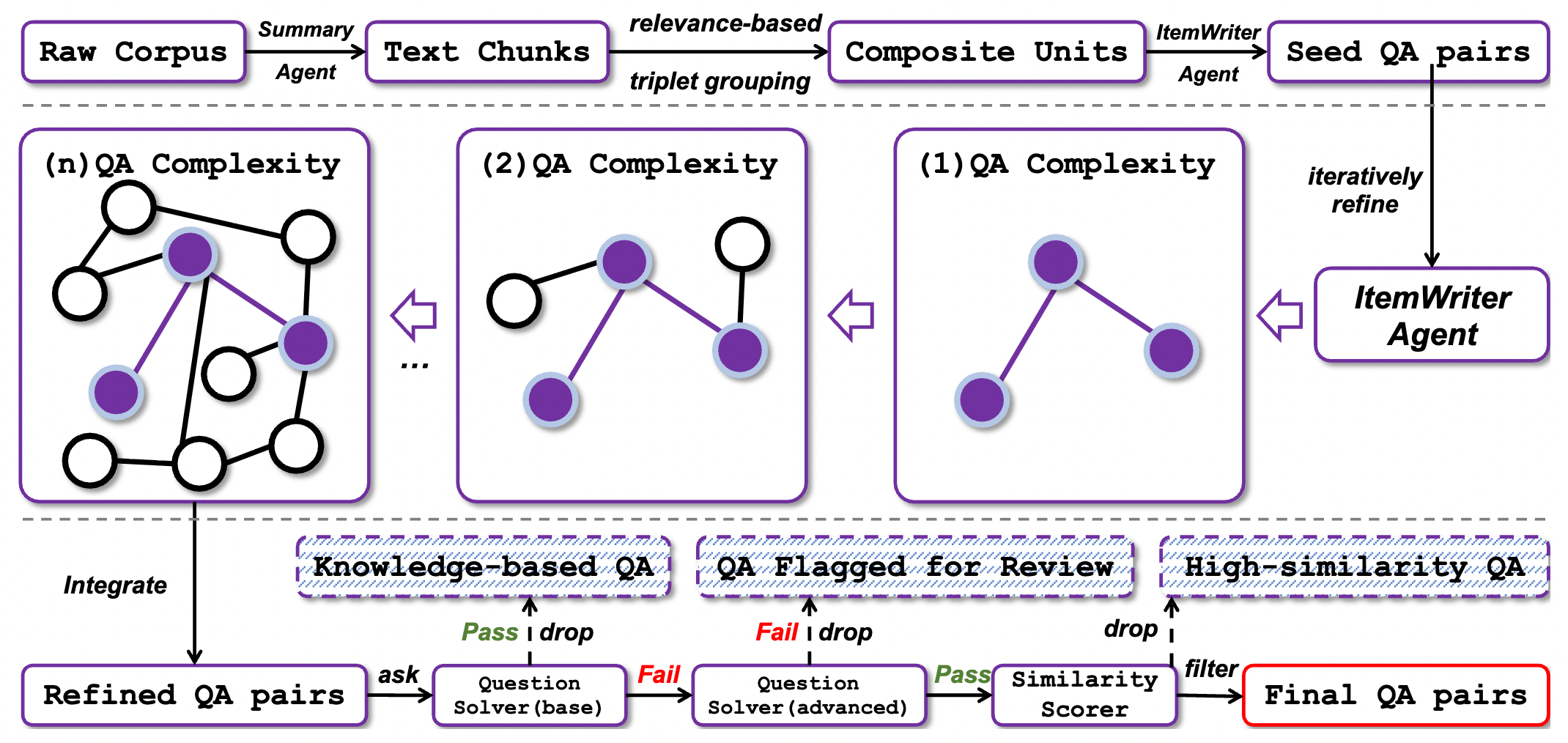
4.1 Core Concept: Solving the Scarcity of Expert Data
In the Agent field, high-quality training trajectories are extremely rare. Most web content consists of “results (articles)” rather than “processes (research paths).”
WebFrontier exists to resolve a core contradiction: How to mass-produce synthetic data while ensuring tasks are “highly difficult” and “Factually Grounded”?
It employs a three-stage Self-bootstrapping pipeline:
4.2 Stage 1: Seed Generation
If you simply ask an LLM to “generate a difficult problem,” it usually produces common-sense questions based on single facts.
- Composite Units Mechanism:
- Extract text chunks from massive corpora (webpages, papers).
- Key Innovation: The system deliberately binds 2–3 chunks that are topically related but from different sources.
- An
ItemWriter Agentis tasked with producing original questions based on this “fragmented information.”
- Effect: Ensures the problem requires multi-source information integration.
4.3 Stage 2: Complexity Escalation
This is the soul of WebFrontier, elevating “undergraduate-level questions” to “PhD-level difficulty.” This isn’t a single prompt call but an Agentic Workflow equipped with tools (Search, Scholar, Python).
The Four Core Operations:
- Knowledge Expansion: Calling search to expand the question scope from A to A+B, forcing the model to perform broader retrieval.
- Conceptual Abstraction: Distilling specific data into underlying principles. (e.g., Changing “find revenue” to “analyze the correlation between market competition and financial report transparency.”)
- Factual Grounding: The most important “anti-hallucination” mechanism. When upgrading a problem, the agent must personally conduct the research online to ensure the upgraded question is “solvable” and “verifiable” in the real world.
- Computational Formulation: Deliberately introducing conditions requiring quantitative analysis, forcing the model to call Python for calculations and increasing the depth of the logical chain.
This implementation involves multi-round interactions. An agent might run 5–10 API calls just to “refine” one high-quality difficult problem. This “compute-for-data” approach is expensive upfront but yields extremely high ROI (Return on Investment).
4.4 Stage 3: Quality Control
Once super-difficult problems are generated, how do we select those best suited for training? WebFrontier designs a “rigorous two-way elimination process” to find the Capability Gap:
- Filter “Too Simple” (Baseline Mode): The model answers without internet access. If it gets it right, it means the question can be solved with internal knowledge alone and doesn’t require “research” capability—discarded.
- Filter “Unsolvable/Too Hard” (Advanced Mode): The model attempts to solve the problem fully equipped with tools. If even the strongest tool-using model cannot solve it, the question might be flawed or data missing—discarded.
- Locking in the “Golden Samples”: Only those problems that “cannot be solved by the brain alone but can be solved with tools” are the perfect nutrients for training IterResearch.
4.5 Data Synthesis Loop
for seed_qa in corpus:
# Stage 2: Multi-round tool interaction to maximize difficulty
complex_qa = agent.refine_with_tools(seed_qa)
# Stage 3: Double verification
can_solve_without_tools = base_model.solve(complex_qa.question)
can_solve_with_tools = expert_model_with_tools.solve(complex_qa.question)
# Looking for the Capability Gap
if not can_solve_without_tools and can_solve_with_tools:
# Record the [Think, Report, Action] trajectory of the expert model
final_dataset.add(expert_model_with_tools.trajectory) 5 Training Algorithms: RFT and GSPO Reinforcement Learning
5.1 Training Philosophy: From “Mimicking Experts” to “Surpassing Experts”
Even with high-quality data from WebFrontier, standard SFT (Supervised Fine-Tuning) is insufficient for extremely long-horizon research tasks. The paper adopts a two-stage training strategy:
- RFT (Stage 1): Filtering the purest reasoning paths via “Rejection Sampling” to establish the model’s formatting and logical foundation.
- GSPO (Stage 2): Strengthening the model’s decision-making and synthesis capabilities in uncertain environments through “Group Sequence Policy Optimization.”
5.2 Stage 1: Rejection Sampling Fine-Tuning (RFT)
The core of RFT is “strict outcome-oriented filtering.”
Trajectory Generation and Filtering: For each question , the model generates multiple research paths. The system implements a veto system: only trajectories where the final answer matches the reference answer exactly (Exactly Match) enter the training set.
Markov Training Objective:
- Core Intuition: We force the model to learn “given the current streamlined state , produce the best structured response (Think-Report-Action).”
- Key Detail (Gradient Isolation): When calculating gradients, Loss is only calculated for tokens generated by the model (). The tool-returned (Observation) is treated only as context. This ensures the model learns “how to think and summarize” rather than memorizing search engine outputs.
5.3 Stage 2: Group Sequence Policy Optimization (GSPO)
This is the key to WebResearcher’s performance explosion. GSPO is an advanced refinement of DeepSeek’s GRPO, specifically designed for Multi-round Sequence scenarios.
5.3.1 Evolution from GRPO to GSPO
- GRPO: Generates multiple answers for a single prompt for peer review.
- GSPO: Generates multiple trajectories for a single question, unfolding all rounds across the entire trajectory and treating them as a collective “Group” for scoring.
5.3.2 Advantage Calculation
Reward Inheritance: If a trajectory eventually succeeds, all rounds ( to ) on that path receive .
Group Normalization: Suppose there are 8 trajectories for a question, totaling 80 rounds. GSPO calculates the average reward () and standard deviation () of these 80 rounds.
Calculate Advantage :
- Intuition: As long as the team (trajectory) your step (round) belongs to wins, your score will be higher than the group average, and the model will reinforce the behavior of that step.
5.4 Why does IterResearch train faster?
- Inefficiency of Traditional Architectures: A 20-step trajectory in linear accumulation is “one ultra-long sample,” placing a heavy burden on the model with weak learning signals.
- Efficiency of IterResearch: The same 20-step trajectory is broken down into 20 independent, high-SNR state transition pairs.
- Result: While the physical volume of training data remains the same, the number of “Effective Samples” increases dozens of times. Furthermore, the input length for each sample is a streamlined , significantly improving convergence speed and GPU utilization.
5.5 Minimal-loss Downsampling
To execute GSPO stably across multi-GPU environments, the paper solves the batch size misalignment issue:
- Problem: Different questions have different numbers of steps, leading to an inconsistent number of rounds per GPU.
- Solution: Find the largest integer smaller than the total samples that is divisible by the number of GPUs (), and randomly discard a tiny fraction of samples (usually ). This ensures that during Full Sync training, no GPU remains idle (Stall) waiting for others.
6 Test-time Scaling (Inference Optimization)
6.1 Inference Philosophy: Trading “Reasoning Compute” for “Decision Boundaries”
In long-horizon research tasks, a single inference () is often limited by search engine randomness, fragmented web content, or a model’s judgmental bias at a certain step.
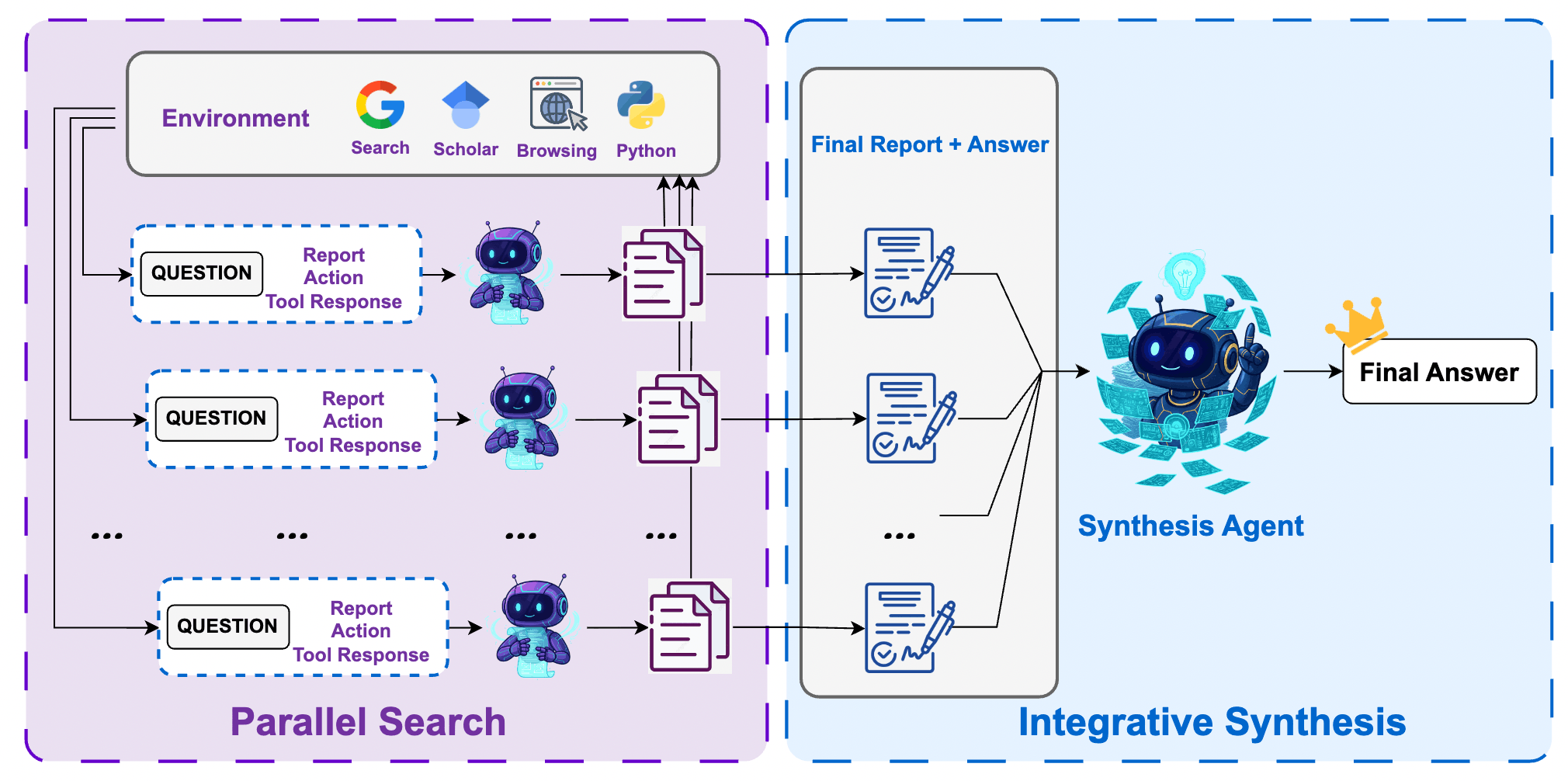
WebResearcher proposes an elegant Research-Synthesis Framework. The core logic is: “Instead of relying on one agent to solve a problem perfectly, let a group of experts conduct research separately, and have a Chief Scientist integrate the intelligence.”
6.2 The Collapse of Traditional Majority Vote
In simple math or logic problems, we can run the model 10 times and vote. In Deep Research, this fails:
- Information Complementarity: Agent A finds clue 1, Agent B finds clue 2. Neither can derive the answer alone (voting fails). Only by “integrating” evidence from both can the problem be solved.
- Context Explosion: If you try to feed all search histories (including hundreds of raw webpages) from 8 agents into one model for summarization, the context would exceed hundreds of thousands of tokens, leading to severe noise interference and loss of focus.
6.3 The Solution: Research-Synthesis Framework
6.3.1 Phase 1: Parallel Research
- Approach: Simultaneously launch independent WebResearcher Agents.
- Feature: Due to the randomness of LLM sampling, these agents will collect different webpages.
- Output: Each agent eventually produces a Final Report and a Predicted Answer.
- Advantage: These reports have been highly distilled by IterResearch, removing 95% of web noise and retaining only core evidence.
6.3.2 Phase 2: Integrative Synthesis
- Role: Employ the strongest model (e.g., Qwen3-235B) as the Synthesis Agent.
- Input: Combine all Final Reports and answers.
- Action: The synthesis brain no longer visits the web personally; instead, it reads the expert reports. It performs “Evidence Alignment,” identifies contradictions, and provides a final answer based on the strength of cross-validation.
6.4 Dimensionality Reduction of Context
Why can this framework scale? Because it physically solves the challenge of information density:
- Traditional Architecture: Context Requirement = (all raw HTML + all thought processes) Infinitely large, unprocessable.
- WebResearcher: Context Requirement = (distilled Final Reports) Linearly controllable, maintaining High SNR.
This design allows the Synthesis Agent to process several times more “effective evidence” than competitors within a limited Context Window.
7 Experimental Results
7.1 HLE (Humanity’s Last Exam)
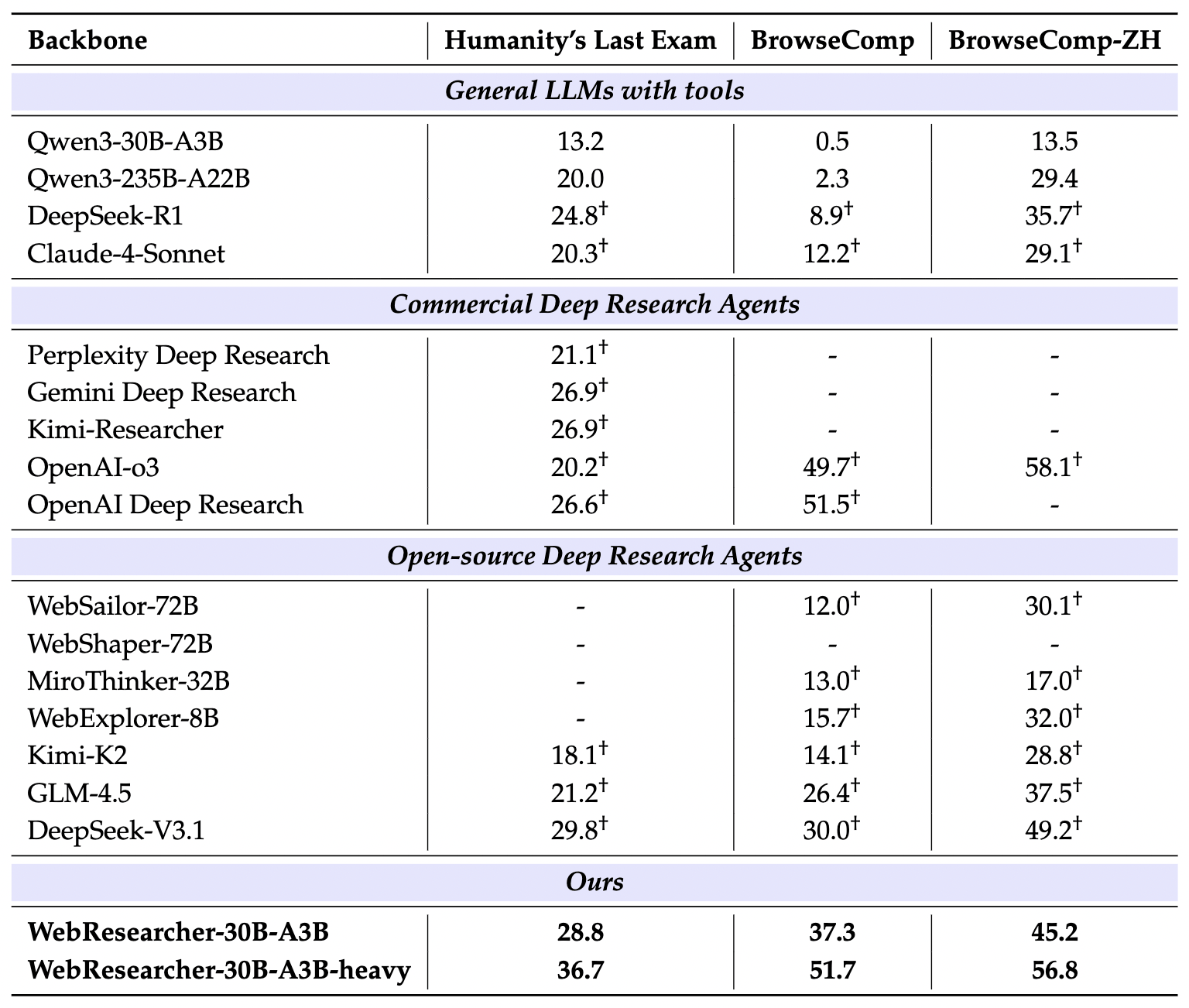
HLE is widely recognized as the most difficult “PhD-level” benchmark in the AI field. The questions cover a vast array of disciplines and are designed specifically so that models cannot easily find answers via simple retrieval.
- Experimental Result: WebResearcher-heavy achieved 36.7% accuracy.
- Comparative Analysis:
- OpenAI Deep Research: 26.6%
- DeepSeek-V3.1 (R1-based): 29.8%
- Gemini Deep Research: 26.9%
In high-difficulty tasks like HLE, WebResearcher leads its closest competitor by nearly 7 percentage points. This proves that for tasks requiring “Deep Synthesis” rather than “Simple Retrieval,” IterResearch’s report iteration mechanism significantly enhances decision precision.
7.2 Data vs. Architecture
This is the most persuasive experiment in the paper, answering a core question: “Is it the data (WebFrontier) or the architecture (IterResearch) that is powerful?”
| Mode (Agent) | HLE Accuracy | BrowseComp (EN) |
|---|---|---|
| Mono-Agent (Traditional) | 18.7% | 25.4% |
| Mono-Agent + Iter Data (Good data, old architecture) | 25.4% | 30.1% |
| WebResearcher (Full: Architecture + Data) | 28.8% | 37.3% |
- Analysis of the two jumps:
- First Jump (18.7% → 25.4%): Proves that the high-difficulty trajectories synthesized by WebFrontier can effectively improve the reasoning ability of any model (even without architectural changes).
- Second Jump (25.4% → 28.8%): This is the most important! It proves that with identical data, “Iterative Reconstruction (MDP)” itself acts as a performance multiplier. This validates that “Linear Accumulation” does indeed have a capacity ceiling, and IterResearch breaks through it.
7.3 Diminishing Returns Curve of Test-time Scaling
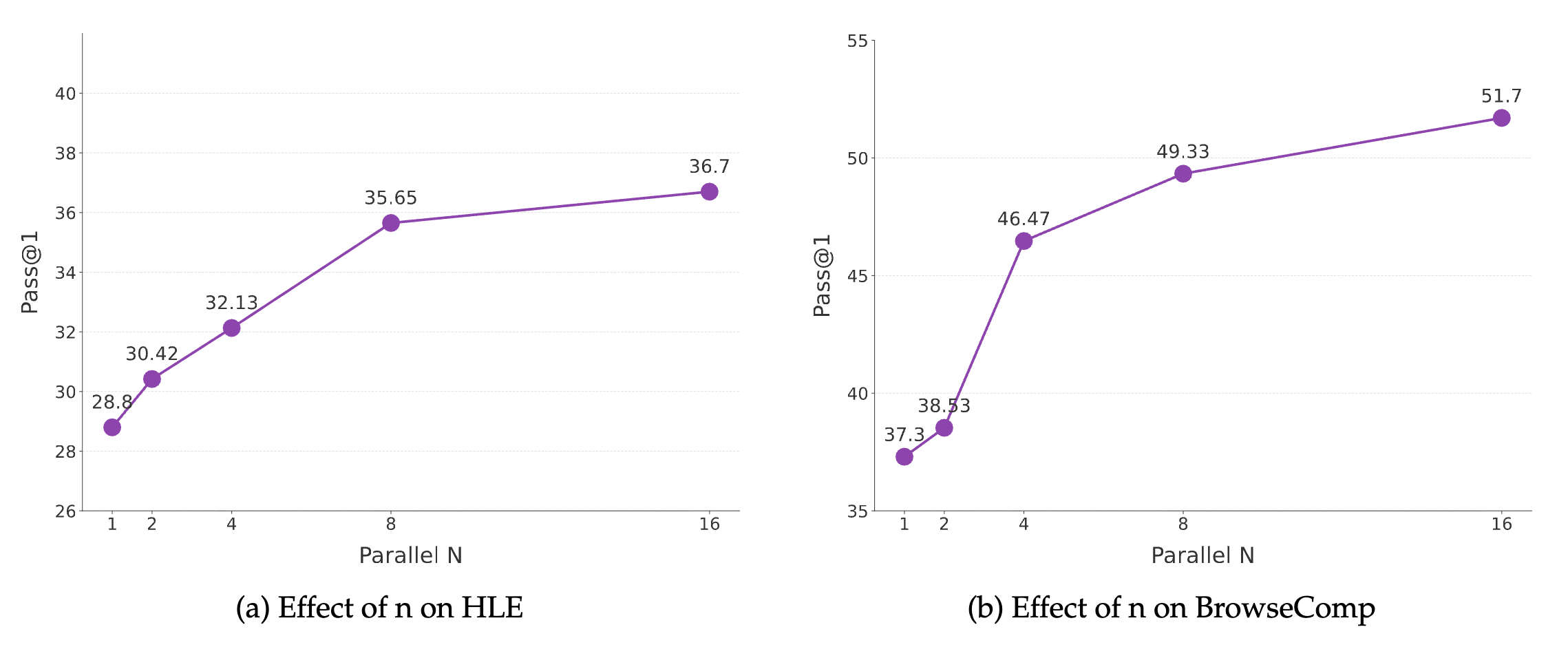
Can inference compute really be traded for IQ?
- Experimental Observation: As the number of parallel research agents increases from 1 to 8, scores rise exponentially.
- Saturation Point: After , returns begin to diminish.
- Key Conclusion: Proves the power of the Synthesis Agent. Even if each individual Research Agent is only 30B in size, provided with enough parallel perspectives, the quality of the final conclusion can surpass that of a single giant closed-source model.
8 Deployment Challenges and Reflections
8.1 Three Major Engineering Bottlenecks for Deployment
Even though WebResearcher scores impressively on benchmarks, we face the following real-world challenges when moving toward commercialization (e.g., corporate AI think tanks, automated research report systems):
- Extreme Latency Challenges:
- Computational Accumulation: Every step requires generating
ThinkandReport, meaning the token generation volume is much higher than traditional agents. - Sequential Blocking: Deep Research tasks usually require 20–60 steps. Even with parallel research, the final Synthesis must wait for all agents to finish. For consumer products seeking “instant replies,” this minute-level wait time is a poor experience.
- Computational Accumulation: Every step requires generating
- Exploding Inference Costs:
- Token Consumption: Every round requires re-inputting the
QuestionandReport. As research deepens, the Report thickens. While cheaper than linear accumulation, it is still much more expensive than simple RAG. - Compute Budget: To reach SOTA, one must use Test-time Scaling (n=8) combined with a 235B model for synthesis. This compute ratio significantly compresses profit margins during large-scale commercial rollout.
- Token Consumption: Every round requires re-inputting the
- Infrastructure Robustness:
- Browser Clusters: Maintaining a browser cluster that can stably crawl JavaScript-rendered pages, handle CAPTCHAs, and avoid being blocked is an engineering feat as difficult as developing the model itself.
- Python Sandbox Security: Frequently executing model-generated code requires extremely strict isolation mechanisms.
8.2 The Markovian Curse
IterResearch is elegant, but it hides a fatal risk: The “Irretrievability” of missed information.
- Information Bottleneck:
The success or failure of the system is 100% dependent on the model’s ability to “distill the Report.” If the model deems a URL or a small data point unimportant in Round 3 and fails to write it into the
Report, that Observation is discarded forever in Round 4. - Risk: Once such an omission occurs, the agent becomes like a detective who has lost a key clue; no matter how strong it is later, it cannot recover the truth from a history that has already vanished. This is why the paper must use powerful WebFrontier data to specifically train “summarization skills.”
8.3 Over-reliance on the Synthesis Agent
- The final decision quality depends heavily on the “Chief Scientist” (the 235B model used in the paper).
- If the Synthesis Agent lacks sufficient reasoning power, it might become confused by conflicting reports or even be misled by a report containing hallucinations. This means the framework currently cannot be “fully downsized” and must rely on a giant brain to oversee the process.
9 Conclusion
9.1 WebResearcher: A Paradigm Shift from “Long Text” to “Long Logic”
The success of WebResearcher marks a pivotal paradigm shift in the history of AI Agents. It proves a profound truth to researchers worldwide: To grant a model “Unbounded Reasoning,” the key is not to give it an infinitely large Context Window, but to give it an elegant “State Distillation Mechanism.”
The core contributions of this paper can be summarized in three technical dimensions:
- Architecture: By modeling Deep Research as a Markov Decision Process (MDP), IterResearch solves the cognitive suffocation and noise contamination caused by “linear accumulation.” It proves that “structured iteration” releases higher-order intelligence better than “brute-force stacking,” allowing a context length of to support complex research exceeding 200 rounds.
- Data: The WebFrontier data engine breaks the deadlock of expert data scarcity. Through “tool-augmented difficulty escalation” and “capability gap filtering,” it mass-produces high-quality, factually aligned “PhD-level research trajectories.” This engine not only trained WebResearcher’s brain but also set a new benchmark for synthetic expert data in the open-source community.
- Optimization: GSPO Reinforcement Learning solves the problem of reward allocation in long sequences, teaching the model to be responsible for “every summary”; meanwhile, the Research-Synthesis framework validates the massive potential of “Test-time Scaling” in complex decision-making.
9.2 Technical Benchmark: The Deep Significance of 36.7% HLE
The 36.7% score achieved by WebResearcher-heavy on the HLE leaderboard is not just a number. It represents that open-source medium-sized models (30B), combined with the correct architecture and compute strategy, are capable of surpassing top-tier closed-source models (OpenAI, Gemini) in specific domains. This provides a clear direction for companies and research teams with limited compute: Optimizing cognitive processes is often more effective than blindly chasing parameter scale.
9.3 Future Outlook: The Next Stop for Agents
While WebResearcher is already powerful, it leaves room for future exploration:
- Cost Reduction: How to achieve near-peak performance without relying on Test-time Scaling (n=8)?
- Stronger Self-Correction: Can more sophisticated “Reflexion mechanisms” be introduced to make Report distillation even more lossless?
- Multimodal Research: Expanding into more complex web environments involving images, tables, and video.