LangMem 基本概念介紹
1 前言
本篇文章為 DeepLearning.AI 所開設的 Long-Term Agentic Memory with LangGraph 課程筆記。希望讀者能夠透過本篇文章,理解 Agent Memory 的基本概念,以及如何透過 LangMem 實踐 Agent Memory!
2 為什麼 Agent 需要 Memory
了解 Agent 的 Memory 之前,我們先思考這個問題:
為什麼 Agent 需要 Memory ?
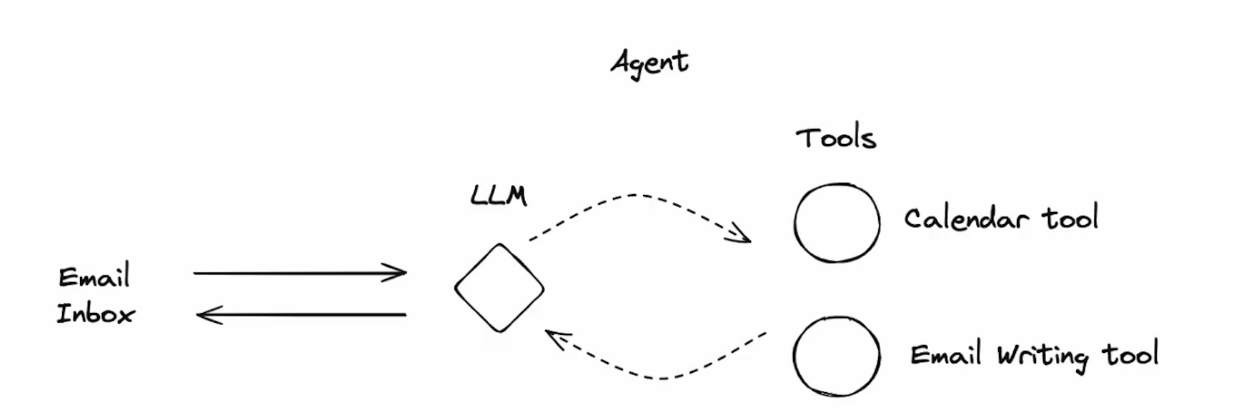
作者舉一個能夠自動回覆 Email 的 Agent 來說明。如下圖示,這個 LLM 需要在讀取信件內容後,透過 Tool Calling 查看收件者的行事曆 (Calendar Tool),再透過 Tool Calling 進行 Email 內容的撰寫 (Email Writing Tool):
在這個過程中,LLM 需要過去的經驗,幫助它克服一些挑戰。如下圖中的紅字所述:
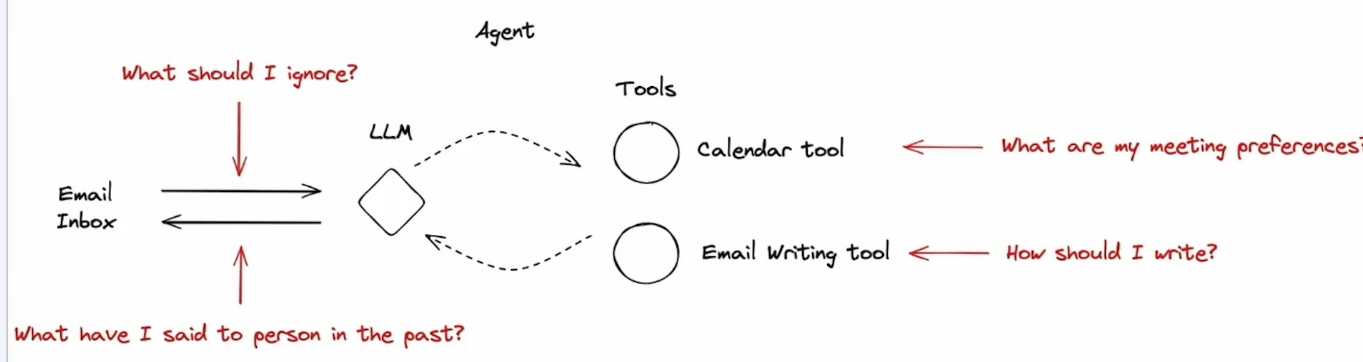
如果 Agent 有記憶能力 (Memory),就能夠參考過去的經驗來處理新的任務。如此一來,Agent 就能夠隨著處理的任務愈多,收集到愈多經驗,而變得更厲害。
3 Memory 的類型以及運作時機
Agent 的 Memory 主要可以分為三種類型:
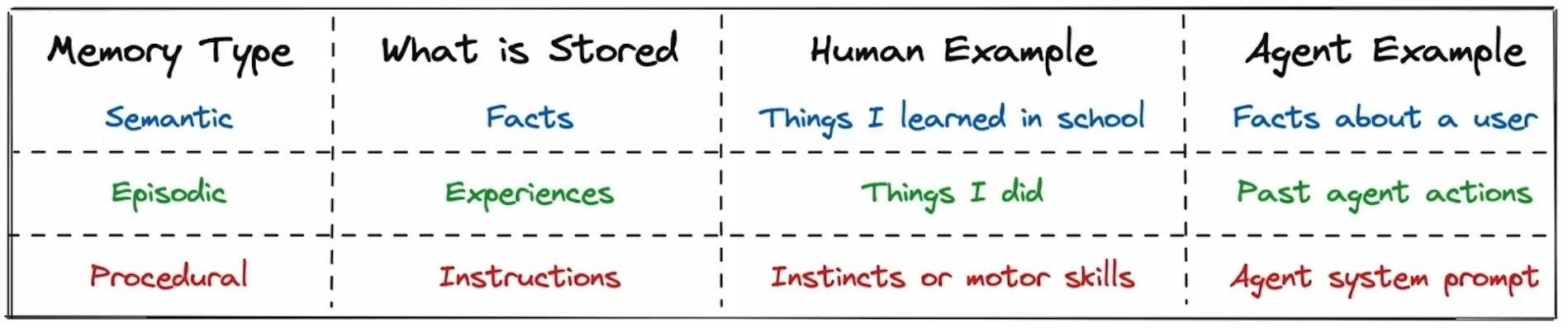
- Semantic Memory: 存放與「事實」相關的內容(我覺得以廣義來說「文件」也可以當成這個類別)
- Episodic Memory: 存放與「經驗」相關的內容(Ex. 放在 Prompt 中的 Few-Shot Examples)
- Procedural Memory: 存放與「指令」相關的內容(Ex. 給 LLM 的 System Prompt)
而 Agent Memory 的運作時機主要有兩種:
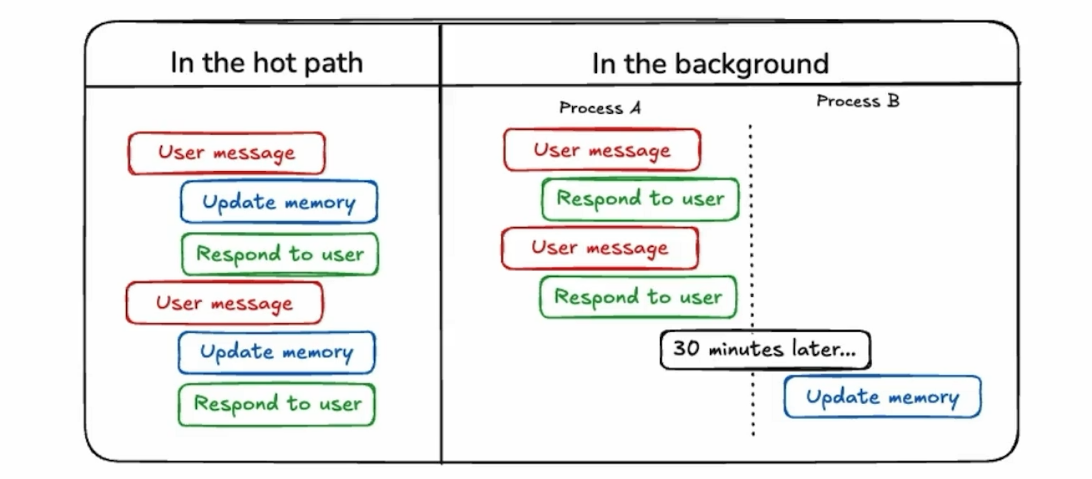
- In the hot path: 在收到 User 的每次 Query 時都會進行 Memory 的讀取與寫入
- In the background: 在 Agent 的運行過程中,會定期進行 Memory 的讀取與寫入
4 Email Agent w/ & w/o Memory
理解了 Agent Memory 的基本概念後,我們來看看在 Email Agent 中,Memory 的運作方式。下圖為一個基本的 Email Agent,沒有使用 Memory 的情況下的 Worflow:
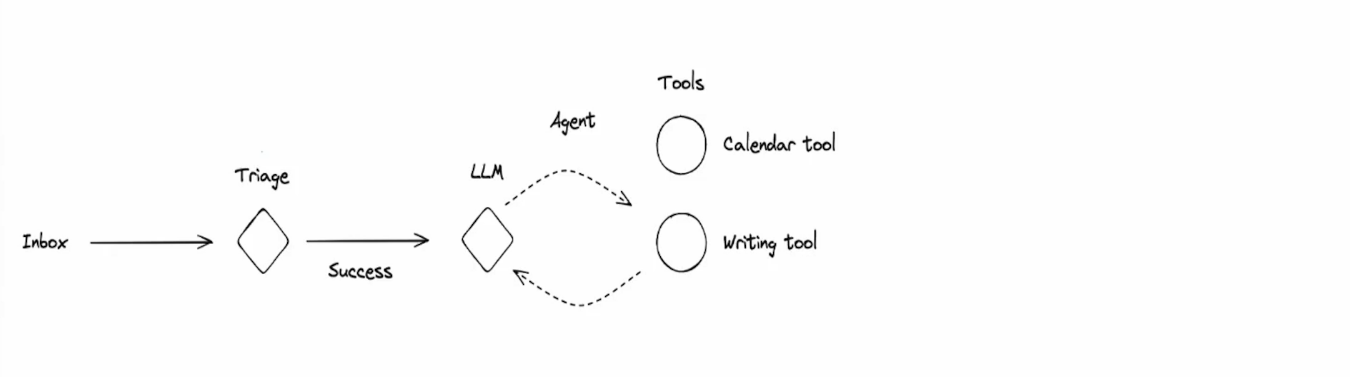
而下圖為一個使用 Memory 的 Email Agent 的 Workflow:
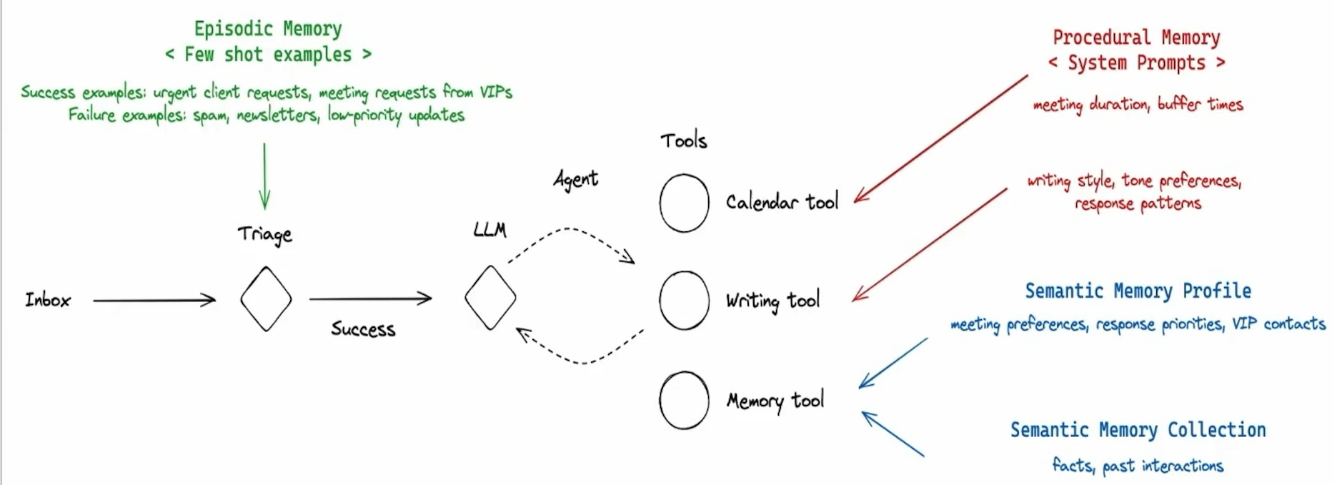
可以發現到:
- Episodic Memory: 其實就是放在 Prompt 中的 Few-Shot Examples,幫助 LLM 判斷這個 Email 是否需要回覆
- Procedural Memory: 其實就是寫在 LLM 的 System Prompt 中的內容,告訴 LLM 如何使用 Calandar Tool 以及 Email Writing Tool
- Semantic Memory: 存放既定的事實 (Ex. Response Preference)
5 Email Agent 的實做 (不具備 Memory)
接著,先實做一個基本的 Email Agent,這個 Agent 不具備 Memory 的功能:
5.1 Triage 的實做
Triage 基本上就是透過 LLM 來對目前的郵件進行分類,分為三類:
- ignore: 忽略這封郵件
- notify: 這封郵件是重要的資訊,但不需要回覆
- respond: 這封郵件需要回覆
from pydantic import BaseModel, Field
from typing_extensions import TypedDict, Literal, Annotated
from langchain.chat_models import init_chat_model
llm = init_chat_model("openai:gpt-4o-mini")
class Router(BaseModel):
"""Analyze the unread email and route it according to its content."""
reasoning: str = Field(
description="Step-by-step reasoning behind the classification."
)
classification: Literal["ignore", "respond", "notify"] = Field(
description="The classification of an email: 'ignore' for irrelevant emails, "
"'notify' for important information that doesn't need a response, "
"'respond' for emails that need a reply",
)
llm_router = llm.with_structured_output(Router)pydantic 來定義這個 Router 的結構化輸出,這樣的做法可以讓 LLM 的輸出更具結構性,並且能夠更方便地進行後續的處理。除了 LangChain 支援這樣的作法之外,outlines 也是一個讓 LLM 進行 Structured Text Generation 的選擇。llm_router 的實際使用方式如下:
result = llm_router.invoke(
[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
)而 System Prompt 的內容如下:
< Role >
You are John Doe's executive assistant. You are a top-notch executive assistant who cares about John performing as well as possible.
</ Role >
< Background >
Senior software engineer leading a team of 5 developers.
</ Background >
< Instructions >
John gets lots of emails. Your job is to categorize each email into one of three categories:
1. IGNORE - Emails that are not worth responding to or tracking
2. NOTIFY - Important information that John should know about but doesn't require a response
3. RESPOND - Emails that need a direct response from John
Classify the below email into one of these categories.
</ Instructions >
< Rules >
Emails that are not worth responding to:
Marketing newsletters, spam emails, mass company announcements
There are also other things that John should know about, but don't require an email response. For these, you should notify John (using the `notify` response). Examples of this include:
Team member out sick, build system notifications, project status updates
Emails that are worth responding to:
Direct questions from team members, meeting requests, critical bug reports
</ Rules >
< Few shot examples >
None
</ Few shot examples >而 User Prompt 的內容如下:
Please determine how to handle the below email thread:
From: Alice Smith <alice.smith@company.com>
To: John Doe <john.doe@company.com>
Subject: Quick question about API documentation
Hi John,
I was reviewing the API documentation for the new authentication service and noticed a few endpoints seem to be missing from the specs. Could you help clarify if this was intentional or if we should update the docs?
Specifically, I'm looking at:
- /auth/refresh
- /auth/validate
Thanks!
Alice5.2 Tools 的實做
接著,作者定義了 3 種 Tool 讓 LLM 使用:
from langchain_core.tools import tool
@tool
def write_email(to: str, subject: str, content: str) -> str:
"""Write and send an email."""
# Placeholder response - in real app would send email
return f"Email sent to {to} with subject '{subject}'"
@tool
def schedule_meeting(
attendees: list[str],
subject: str,
duration_minutes: int,
preferred_day: str
) -> str:
"""Schedule a calendar meeting."""
# Placeholder response - in real app would check calendar and schedule
return f"Meeting '{subject}' scheduled for {preferred_day} with {len(attendees)} attendees"
@tool
def check_calendar_availability(day: str) -> str:
"""Check calendar availability for a given day."""
# Placeholder response - in real app would check actual calendar
return f"Available times on {day}: 9:00 AM, 2:00 PM, 4:00 PM"5.3 Main Agent 的實做
Main Agent 的任務是透過使用 Tools 來完成 Email 回覆的任務:
from langgraph.prebuilt import create_react_agent
tools=[write_email, schedule_meeting, check_calendar_availability]
agent = create_react_agent(
"openai:gpt-4o",
tools=tools,
prompt=create_prompt,
)而這邊的 create_prompt 的內容如下:
< Role >
You are John Doe's executive assistant. You are a top-notch executive assistant who cares about John performing as well as possible.
</ Role >
< Tools >
You have access to the following tools to help manage John's communications and schedule:
1. write_email(to, subject, content) - Send emails to specified recipients
2. schedule_meeting(attendees, subject, duration_minutes, preferred_day) - Schedule calendar meetings
3. check_calendar_availability(day) - Check available time slots for a given day
</ Tools >
< Instructions >
Use these tools when appropriate to help manage John's tasks efficiently.
</ Instructions >而 Main Agent 的使用方式如下:
response = agent.invoke(
{"messages": [{
"role": "user",
"content": "what is my availability for tuesday?"
}]}
)Main Agent 的輸出:
================================== Ai Message ==================================
You have the following available times on Tuesday:
- 9:00 AM
- 2:00 PM
- 4:00 PM
If you need me to schedule anything or make any arrangements, just let me know!5.4 透過 LangGraph 整合為一個 Workflow
最後,將上述的 Triage 與 Main Agent 整合為一個 Workflow。
from langgraph.graph import add_messages
from langgraph.graph import StateGraph, START, END
from langgraph.types import Command
from typing import Literal
class State(TypedDict):
email_input: dict
messages: Annotated[list, add_messages]
def triage_router(state: State) -> Command[
Literal["response_agent", "__end__"]
]:
author = state['email_input']['author']
to = state['email_input']['to']
subject = state['email_input']['subject']
email_thread = state['email_input']['email_thread']
system_prompt = triage_system_prompt.format(
full_name=profile["full_name"],
name=profile["name"],
user_profile_background=profile["user_profile_background"],
triage_no=prompt_instructions["triage_rules"]["ignore"],
triage_notify=prompt_instructions["triage_rules"]["notify"],
triage_email=prompt_instructions["triage_rules"]["respond"],
examples=None
)
user_prompt = triage_user_prompt.format(
author=author,
to=to,
subject=subject,
email_thread=email_thread
)
result = llm_router.invoke(
[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
)
if result.classification == "respond":
print("📧 Classification: RESPOND - This email requires a response")
goto = "response_agent"
update = {
"messages": [
{
"role": "user",
"content": f"Respond to the email {state['email_input']}",
}
]
}
elif result.classification == "ignore":
print("🚫 Classification: IGNORE - This email can be safely ignored")
update = None
goto = END
elif result.classification == "notify":
# If real life, this would do something else
print("🔔 Classification: NOTIFY - This email contains important information")
update = None
goto = END
else:
raise ValueError(f"Invalid classification: {result.classification}")
return Command(goto=goto, update=update)
email_agent = StateGraph(State)
email_agent = email_agent.add_node(triage_router)
email_agent = email_agent.add_node("response_agent", agent)
email_agent = email_agent.add_edge(START, "triage_router")
email_agent = email_agent.compile()Email Agent 的整體 Workflow 如下圖所示:
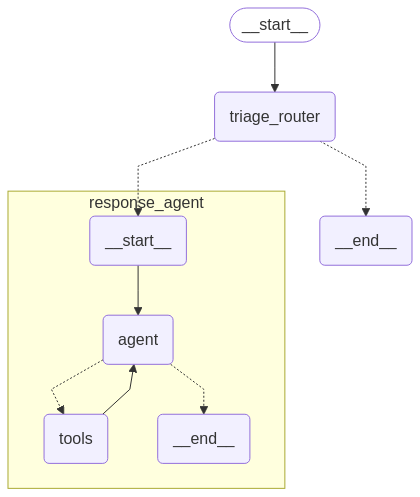
5.5 Email Agent 範例輸入與輸出
範例輸入 1: 不需要回覆的 Email
email_input = { "author": "Marketing Team <marketing@amazingdeals.com>", "to": "John Doe <john.doe@company.com>", "subject": "🔥 EXCLUSIVE OFFER: Limited Time Discount on Developer Tools! 🔥", "email_thread": """Dear Valued Developer, Don't miss out on this INCREDIBLE opportunity! 🚀 For a LIMITED TIME ONLY, get 80% OFF on our Premium Developer Suite! ✨ FEATURES: - Revolutionary AI-powered code completion - Cloud-based development environment - 24/7 customer support - And much more! 💰 Regular Price: $999/month 🎉 YOUR SPECIAL PRICE: Just $199/month! 🕒 Hurry! This offer expires in: 24 HOURS ONLY! Click here to claim your discount: https://amazingdeals.com/special-offer Best regards, Marketing Team --- To unsubscribe, click here """, } response = email_agent.invoke({"email_input": email_input})🚫 Classification: IGNORE - This email can be safely ignored範例輸入 2: 需要回覆的 Email
email_input = { "author": "Alice Smith <alice.smith@company.com>", "to": "John Doe <john.doe@company.com>", "subject": "Quick question about API documentation", "email_thread": """Hi John, I was reviewing the API documentation for the new authentication service and noticed a few endpoints seem to be missing from the specs. Could you help clarify if this was intentional or if we should update the docs? Specifically, I'm looking at: - /auth/refresh - /auth/validate Thanks! Alice""", } response = email_agent.invoke({"email_input": email_input})📧 Classification: RESPOND - This email requires a responsefor m in response["messages"]: m.pretty_print()================================ Human Message ================================= Respond to the email {'author': 'Alice Smith <alice.smith@company.com>', 'to': 'John Doe <john.doe@company.com>', 'subject': 'Quick question about API documentation', 'email_thread': "Hi John,\n\nI was reviewing the API documentation for the new authentication service and noticed a few endpoints seem to be missing from the specs. Could you help clarify if this was intentional or if we should update the docs?\n\nSpecifically, I'm looking at:\n- /auth/refresh\n- /auth/validate\n\nThanks!\nAlice"} ================================== Ai Message ================================== Tool Calls: write_email (call_1ndxzPIinVSvav1pBioakpQR) Call ID: call_1ndxzPIinVSvav1pBioakpQR Args: to: alice.smith@company.com subject: Re: Quick question about API documentation content: Hi Alice, Thank you for reaching out with your question about the API documentation. I can confirm that the endpoints /auth/refresh and /auth/validate should indeed be included in the documentation. It was an oversight, and the documentation needs to be updated. I'll ensure that the team updates the documentation to include these endpoints as soon as possible. Best regards, John Doe ================================= Tool Message ================================= Name: write_email Email sent to alice.smith@company.com with subject 'Re: Quick question about API documentation' ================================== Ai Message ================================== I have responded to Alice's email, clarifying that the endpoints she mentioned should be included in the documentation and that the team will update the documentation accordingly.
6 Email Agent 的實做 (具備 Memory)
6.1 Sematic Memory 的實做
如同上文所述,Semantic Memory 主要是存放與「事實」相關的內容,這些事實也通常會存放在一個 Long-Term Memory 中。
作者透過 LangGraph 的 InMemoryStore 來模擬 Semantic Memory 的儲存:
from langgraph.store.memory import InMemoryStore
store = InMemoryStore(
index={"embed": "openai:text-embedding-3-small"}
)並且透過建立兩個 Tool 來進行 Semantic Memory 的 Manage 以及 Search:
from langmem import create_manage_memory_tool, create_search_memory_tool
manage_memory_tool = create_manage_memory_tool(
namespace=(
"email_assistant",
"{langgraph_user_id}",
"collection"
)
)
search_memory_tool = create_search_memory_tool(
namespace=(
"email_assistant",
"{langgraph_user_id}",
"collection"
)
)在呼叫 create_manage_memory_tool 以及 create_search_memory_tool 時,都有傳入 namespace,用來區隔不同的 Memory Collection。這邊的 langgraph_user_id 則是會在 LangGraph 被 Invoke 時傳入,如此一來就能夠區隔不同的使用者的 Memory Collection。
舉例來說,User A 的 Memory Collection 為 ("email_assistant", "user_a", "collection"),而 User B 的 Memory Collection 則為 ("email_assistant", "user_b", "collection"),不同的使用者擁有各自獨立的 Memory Collection。
manage_memory_tool 的相關資訊:
- Name:
print(manage_memory_tool.name)manage_memory - Description:
print(manage_memory_tool.description)Create, update, or delete persistent MEMORIES to persist across conversations. Include the MEMORY ID when updating or deleting a MEMORY. Omit when creating a new MEMORY - it will be created for you. Proactively call this tool when you: 1. Identify a new USER preference. 2. Receive an explicit USER request to remember something or otherwise alter your behavior. 3. Are working and want to record important context. 4. Identify that an existing MEMORY is incorrect or outdated. - Arguments:
print(manage_memory_tool.args)可以發現到,這邊的{ 'content': {'anyOf': [{'type': 'string'}, {'type': 'null'}], 'default': None,'title': 'Content'}, 'action': {'default': 'create', 'enum': ['create', 'update', 'delete'], 'title': 'Action', 'type': 'string'}, 'id': {'anyOf': [{'format': 'uuid', 'type': 'string'}, {'type': 'null'}], 'default': None, 'title': 'Id'} }args主要有三個參數:- content: 要儲存的內容
- action: 要進行的動作 (create, update, delete)
- id: 指的是 Memory Block 的 ID,這個 ID 會在 Memory Block 被建立時自動產生,並且會在 Memory Block 被更新或刪除時使用
- Name:
search_memory_tool 的相關資訊:
- Name:
print(search_memory_tool.name)search_memory - Description:
print(search_memory_tool.description)Search your long-term memories for information relevant to your current context. - Arguments:
print(search_memory_tool.args)可以發現 search_memory_tool 主要是傳入 ‘query’ 透過 Emnbedding 計算 Cosine Similarity 來找到最相似的 Memory ,並且回傳這些 Memory 的內容。{ 'query': {'title': 'Query', 'type': 'string'}, 'limit': {'default': 10, 'title': 'Limit', 'type': 'integer'}, 'offset': {'default': 0, 'title': 'Offset', 'type': 'integer'}, 'filter': {'anyOf': [{'type': 'object'}, {'type': 'null'}], 'default': None, 'title': 'Filter'} }
- Name:
6.2 將 Sematic Memory 加入 Main Agent
接著,將 Semantic Memory 加入 Main Agent 的 Workflow 中。類似上文 Main Agent 的定義,這邊改成多將 manage_memory_tool 以及 search_memory_tool 加入到 Main Agent 的 Tools 中:
from langgraph.prebuilt import create_react_agent
tools= [
write_email,
schedule_meeting,
check_calendar_availability,
manage_memory_tool,
search_memory_tool
]
response_agent = create_react_agent(
"anthropic:claude-3-5-sonnet-latest",
tools=tools,
prompt=create_prompt,
# Use this to ensure the store is passed to the agent
store=store
)同時,create_prompt 也要加入 manage_memory_tool 以及 search_memory_tool 的相關資訊:
< Role >
You are John Doe's executive assistant. You are a top-notch executive assistant who cares about John performing as well as possible.
</ Role >
< Tools >
You have access to the following tools to help manage John's communications and schedule:
1. write_email(to, subject, content) - Send emails to specified recipients
2. schedule_meeting(attendees, subject, duration_minutes, preferred_day) - Schedule calendar meetings
3. check_calendar_availability(day) - Check available time slots for a given day
4. manage_memory - Store any relevant information about contacts, actions, discussion, etc. in memory for future reference
5. search_memory - Search for any relevant information that may have been stored in memory
</ Tools >
< Instructions >
Use these tools when appropriate to help manage John's tasks efficiently.
</ Instructions >實際 Invoke 一次 Main Agent:
config = {"configurable": {"langgraph_user_id": "lance"}}
response = response_agent.invoke(
{"messages": [{"role": "user", "content": "Jim is my friend"}]},
config=config
)
for m in response["messages"]:
m.pretty_print()================================ Human Message =================================
Jim is my friend
================================== Ai Message ==================================
[{'text': "I'll help you store this information about Jim in the memory system for future reference.", 'type': 'text'}, {'id': 'toolu_018NRmLraq49m8KVCuDHm6NT', 'input': {'content': "Jim is John Doe's friend"}, 'name': 'manage_memory', 'type': 'tool_use'}]
Tool Calls:
manage_memory (toolu_018NRmLraq49m8KVCuDHm6NT)
Call ID: toolu_018NRmLraq49m8KVCuDHm6NT
Args:
content: Jim is John Doe's friend
================================= Tool Message =================================
Name: manage_memory
created memory 4fd406ea-ba98-4ed0-92f3-838ea73e8a24
================================== Ai Message ==================================
I've recorded that Jim is your friend in my memory. This will help me better assist you with any future interactions or tasks involving Jim. Is there anything specific about Jim that you'd like me to know or help you with?可以發現到,Main Agent 在收到 User 的輸入後,會透過 manage_memory_tool 將這個資訊儲存到 Semantic Memory 中。接著,當 User 再次詢問關於 Jim 的問題時,Main Agent 就能夠從 Semantic Memory 中找到相關的資訊,並且進行回覆:
response = response_agent.invoke(
{"messages": [{"role": "user", "content": "who is jim?"}]},
config=config
)
for m in response["messages"]:
m.pretty_print()================================ Human Message =================================
who is jim?
================================== Ai Message ==================================
[{'text': 'Let me search through my memories to see if I have any information about Jim.', 'type': 'text'}, {'id': 'toolu_01EEwQF4pLwxnZ1uoseND1jK', 'input': {'query': 'Jim'}, 'name': 'search_memory', 'type': 'tool_use'}]
Tool Calls:
search_memory (toolu_01EEwQF4pLwxnZ1uoseND1jK)
Call ID: toolu_01EEwQF4pLwxnZ1uoseND1jK
Args:
query: Jim
================================= Tool Message =================================
Name: search_memory
[{"namespace": ["email_assistant", "lance", "collection"], "key": "4fd406ea-ba98-4ed0-92f3-838ea73e8a24", "value": {"content": "Jim is John Doe's friend"}, "created_at": "2025-05-06T11:51:31.045122+00:00", "updated_at": "2025-05-06T11:51:31.045130+00:00", "score": 0.38053805045337047}]
================================== Ai Message ==================================
Based on the stored memory, Jim is John Doe's friend. However, this is fairly basic information. If you need more specific details about Jim or have a particular question about him, please let me know and I'll try to help further.6.3 Episodic Memory 的實做
Episodic Memory 主要是存放與「經驗」相關的內容,這些經驗通常會在 LLM 的 Prompt 中進行 Few-Shot Learning。在這個 Email Agent 的例子中,Episodic Memory 主要是用來幫助 LLM 判斷這封 Email 是否需要回覆。這些經驗一樣也可以透過一個 Long-Term Memory 來儲存。作者這邊使用 InMemoryStore 來模擬 Episodic Memory 的儲存:
from langgraph.store.memory import InMemoryStore
store = InMemoryStore(
index={"embed": "openai:text-embedding-3-small"}
)存放一個過去的經驗:
import uuid
email = {
"author": "Alice Smith <alice.smith@company.com>",
"to": "John Doe <john.doe@company.com>",
"subject": "Quick question about API documentation",
"email_thread": """Hi John,
I was reviewing the API documentation for the new authentication service and noticed a few endpoints seem to be missing from the specs. Could you help clarify if this was intentional or if we should update the docs?
Specifically, I'm looking at:
- /auth/refresh
- /auth/validate
Thanks!
Alice""",
}
data = {
"email": email,
# This is to start changing the behavior of the agent
"label": "respond"
}
store.put(
("email_assistant", "lance", "examples"),
str(uuid.uuid4()),
data
)存放另外一個過去的經驗:
data = {
"email": {
"author": "Sarah Chen <sarah.chen@company.com>",
"to": "John Doe <john.doe@company.com>",
"subject": "Update: Backend API Changes Deployed to Staging",
"email_thread": """Hi John,
Just wanted to let you know that I've deployed the new authentication endpoints we discussed to the staging environment. Key changes include:
- Implemented JWT refresh token rotation
- Added rate limiting for login attempts
- Updated API documentation with new endpoints
All tests are passing and the changes are ready for review. You can test it out at staging-api.company.com/auth/*
No immediate action needed from your side - just keeping you in the loop since this affects the systems you're working on.
Best regards,
Sarah
""",
},
"label": "ignore"
}
store.put(
("email_assistant", "lance", "examples"),
str(uuid.uuid4()),
data
)當今天收到一封 Email 時,Episodic Memory 會透過 search Method 計算新的 Email 與過去經驗的 Embedding 的 Cosine Similarity,並且回傳最相似的經驗。這邊的 search Method 會傳入 limit 參數,來限制回傳的經驗數量:
# Template for formating an example to put in prompt
template = """Email Subject: {subject}
Email From: {from_email}
Email To: {to_email}
Email Content:
{content}
> Triage Result: {result}"""
# Format list of few shots
def format_few_shot_examples(examples):
strs = ["Here are some previous examples:"]
for eg in examples:
strs.append(
template.format(
subject=eg.value["email"]["subject"],
to_email=eg.value["email"]["to"],
from_email=eg.value["email"]["author"],
content=eg.value["email"]["email_thread"][:400],
result=eg.value["label"],
)
)
return "\n\n------------\n\n".join(strs)
email_data = {
"author": "Sarah Chen <sarah.chen@company.com>",
"to": "John Doe <john.doe@company.com>",
"subject": "Update: Backend API Changes Deployed to Staging",
"email_thread": """Hi John,
Wanted to let you know that I've deployed the new authentication endpoints we discussed to the staging environment. Key changes include:
- Implemented JWT refresh token rotation
- Added rate limiting for login attempts
- Updated API documentation with new endpoints
All tests are passing and the changes are ready for review. You can test it out at staging-api.company.com/auth/*
No immediate action needed from your side - just keeping you in the loop since this affects the systems you're working on.
Best regards,
Sarah
""",
}
results = store.search(
("email_assistant", "lance", "examples"),
query=str({"email": email_data}),
limit=1)
print(format_few_shot_examples(results))Here are some previous examples:
------------
Email Subject: Update: Backend API Changes Deployed to Staging
Email From: Sarah Chen <sarah.chen@company.com>
Email To: John Doe <john.doe@company.com>
Email Content:
Hi John,
Just wanted to let you know that I've deployed the new authentication endpoints we discussed to the staging environment. Key changes include:
- Implemented JWT refresh token rotation
- Added rate limiting for login attempts
- Updated API documentation with new endpoints
All tests are passing and the changes are ready for review. You can test it out at st
> Triage Result: ignore6.4 Procedural Memory 的實做
Procedural Memory 主要是存放與「指令」相關的內容,這些指令其實就是 LLM 在進行不同任務時所需要的 System Prompt。這些 System Prompt 一樣也可以透過一個 Long-Term Memory 來儲存。作者這邊一樣使用 InMemoryStore 來模擬 Procedural Memory 的儲存:
from langgraph.store.memory import InMemoryStore
store = InMemoryStore(
index={"embed": "openai:text-embedding-3-small"}
)目前的 Email Agent 主要是由兩個 System Prompt 來進行定義:
- Triage System Prompt: 用來判斷這封 Email 是否需要回覆
- Main Agent System Prompt: 用來定義 LLM 在進行 Email 回覆時的行為
我們可以將這兩個 System Prompt 儲存到 Procedural Memory 中,並且在 LLM 進行 Triage 以及 Email 回覆時,透過 search Method 來取得這些 System Prompt 的內容。以下加入 Episodic Memory 以及 Procedural Memory 後的 Triage 的實做:
def triage_router(state: State, config, store) -> Command[
Literal["response_agent", "__end__"]
]:
author = state['email_input']['author']
to = state['email_input']['to']
subject = state['email_input']['subject']
email_thread = state['email_input']['email_thread']
namespace = (
"email_assistant",
config['configurable']['langgraph_user_id'],
"examples"
)
examples = store.search(
namespace,
query=str({"email": state['email_input']})
)
examples=format_few_shot_examples(examples)
langgraph_user_id = config['configurable']['langgraph_user_id']
namespace = (langgraph_user_id, )
result = store.get(namespace, "triage_ignore")
if result is None:
store.put(
namespace,
"triage_ignore",
{"prompt": prompt_instructions["triage_rules"]["ignore"]}
)
ignore_prompt = prompt_instructions["triage_rules"]["ignore"]
else:
ignore_prompt = result.value['prompt']
result = store.get(namespace, "triage_notify")
if result is None:
store.put(
namespace,
"triage_notify",
{"prompt": prompt_instructions["triage_rules"]["notify"]}
)
notify_prompt = prompt_instructions["triage_rules"]["notify"]
else:
notify_prompt = result.value['prompt']
result = store.get(namespace, "triage_respond")
if result is None:
store.put(
namespace,
"triage_respond",
{"prompt": prompt_instructions["triage_rules"]["respond"]}
)
respond_prompt = prompt_instructions["triage_rules"]["respond"]
else:
respond_prompt = result.value['prompt']
system_prompt = triage_system_prompt.format(
full_name=profile["full_name"],
name=profile["name"],
user_profile_background=profile["user_profile_background"],
triage_no=ignore_prompt,
triage_notify=notify_prompt,
triage_email=respond_prompt,
examples=examples
)
user_prompt = triage_user_prompt.format(
author=author,
to=to,
subject=subject,
email_thread=email_thread
)
result = llm_router.invoke(
[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
)
if result.classification == "respond":
print("📧 Classification: RESPOND - This email requires a response")
goto = "response_agent"
update = {
"messages": [
{
"role": "user",
"content": f"Respond to the email {state['email_input']}",
}
]
}
elif result.classification == "ignore":
print("🚫 Classification: IGNORE - This email can be safely ignored")
update = None
goto = END
elif result.classification == "notify":
# If real life, this would do something else
print("🔔 Classification: NOTIFY - This email contains important information")
update = None
goto = END
else:
raise ValueError(f"Invalid classification: {result.classification}")
return Command(goto=goto, update=update)可以發現到,組成 Triage System Prompt 的內容,除了 triage_system_prompt 之外,還有 ignore_prompt、notify_prompt 以及 respond_prompt。這些內容都是從 Procedural Memory 中取得的。
此外,在 Main Agent 的 system Prompt 部份,原本的 create_prompt 如下所示:
def create_prompt(state):
return [
{
"role": "system",
"content": agent_system_prompt_memory.format(
instructions=prompt_instructions["agent_instructions"],
**profile
)
}
] + state['messages']在加入 Procedural Memory 之後:
def create_prompt(state, config, store):
langgraph_user_id = config['configurable']['langgraph_user_id']
namespace = (langgraph_user_id, )
result = store.get(namespace, "agent_instructions")
if result is None:
store.put(
namespace,
"agent_instructions",
{"prompt": prompt_instructions["agent_instructions"]}
)
prompt = prompt_instructions["agent_instructions"]
else:
prompt = result.value['prompt']
return [
{
"role": "system",
"content": agent_system_prompt_memory.format(
instructions=prompt,
**profile
)
}
] + state['messages']可以發現到,這邊的 agent_system_prompt_memory 中的 instructions 參數,不再只是讀去固定的值,而是會從 Procedural Memory 中取得。
總結來說,這邊的 Triage System Prompt 會從 Procedural Memory 中取得 triage_ignore、triage_notify 以及 triage_respond 的內容,而 Main Agent 則是會從 Procedural Memory 中取得 agent_instructions 的內容。
以下是這 4 個 Instruction 在 Procedural Memory 中的內容:
store.get(("lance",), "agent_instructions").value['prompt']
# "Use these tools when appropriate to help manage John's tasks efficiently."
store.get(("lance",), "triage_respond").value['prompt']
# 'Direct questions from team members, meeting requests, critical bug reports'
store.get(("lance",), "triage_ignore").value['prompt']
# 'Marketing newsletters, spam emails, mass company announcements'
store.get(("lance",), "triage_notify").value['prompt']
# 'Team member out sick, build system notifications, project status updates'接著,我們希望 Email Agent 在與 User 互動的過程中,能夠根據 User 提供的 Feedback 來調整這些 Instruction 的內容。作者這邊透過 langmem 的 create_multi_prompt_optimizer 來建立一個 Prompt Optimizer。
from langmem import create_multi_prompt_optimizer
optimizer = create_multi_prompt_optimizer(
"anthropic:claude-3-5-sonnet-latest",
kind="prompt_memory",
)接著,模擬 User 提供的 Feedback:
conversations = [
(
response['messages'],
"Always sign your emails `John Doe`"
)
]其中 response['messages'] 是指 User 與 Email Agent 互動的過程:
================================ Human Message =================================
Respond to the email {'author': 'Alice Jones <alice.jones@bar.com>', 'to': 'John Doe <john.doe@company.com>', 'subject': 'Quick question about API documentation', 'email_thread': 'Hi John,\n\nUrgent issue - your service is down. Is there a reason why'}
================================== Ai Message ==================================
Tool Calls:
write_email (call_GuYrnvmS6n9ihfRQm6rlHpfX)
Call ID: call_GuYrnvmS6n9ihfRQm6rlHpfX
Args:
to: alice.jones@bar.com
subject: Re: Quick question about API documentation
content: Hi Alice,
I apologize for the inconvenience. I'm currently looking into the issue and will get back to you with an update as soon as possible.
Best regards,
John Doe
================================= Tool Message =================================
Name: write_email
Email sent to alice.jones@bar.com with subject 'Re: Quick question about API documentation'
================================== Ai Message ==================================
I've responded to Alice Jones regarding the urgent issue with the service being down, and I've assured her that the issue is being looked into.因此,User 在這整段的對話中,給予的 Feedback 是「Always sign your emails John Doe」。
除了 User 的 Feedback 之外,還需要告訴 Prompt Optimizer “when_to_update” 以及進行更新時的 “update_instruction”:
prompts = [
{
"name": "main_agent",
"prompt": store.get(("lance",), "agent_instructions").value['prompt'],
"update_instructions": "keep the instructions short and to the point",
"when_to_update": "Update this prompt whenever there is feedback on how the agent should write emails or schedule events"
},
{
"name": "triage-ignore",
"prompt": store.get(("lance",), "triage_ignore").value['prompt'],
"update_instructions": "keep the instructions short and to the point",
"when_to_update": "Update this prompt whenever there is feedback on which emails should be ignored"
},
{
"name": "triage-notify",
"prompt": store.get(("lance",), "triage_notify").value['prompt'],
"update_instructions": "keep the instructions short and to the point",
"when_to_update": "Update this prompt whenever there is feedback on which emails the user should be notified of"
},
{
"name": "triage-respond",
"prompt": store.get(("lance",), "triage_respond").value['prompt'],
"update_instructions": "keep the instructions short and to the point",
"when_to_update": "Update this prompt whenever there is feedback on which emails should be responded to"
},
]最後,將這些資訊傳入 optimizer 中,讓 Prompt Optimizer 根據 User 的 Feedback 以及 “when_to_update” 的標準,來判斷哪一個 Prompt 需要進行更新,並且根據 “update_instruction” 的內容來進行更新:
updated = optimizer.invoke(
{"trajectories": conversations, "prompts": prompts}
)最後更新完後的 Prompt 如下所示:
print(updated)[
{
"name": "main_agent",
"prompt": "Use these tools when appropriate to help manage John's tasks efficiently. When sending emails, always sign them as \"John Doe\".",
"update_instructions": "keep the instructions short and to the point",
"when_to_update": "Update this prompt whenever there is feedback on how the agent should write emails or schedule events"
},
{
"name": "triage-ignore",
"prompt": "Marketing newsletters, spam emails, mass company announcements",
"update_instructions": "keep the instructions short and to the point",
"when_to_update": "Update this prompt whenever there is feedback on which emails should be ignored"
},
{
"name": "triage-notify",
"prompt": "Team member out sick, build system notifications, project status updates",
"update_instructions": "keep the instructions short and to the point",
"when_to_update": "Update this prompt whenever there is feedback on which emails the user should be notified of"
},
{
"name": "triage-respond",
"prompt": "Direct questions from team members, meeting requests, critical bug reports",
"update_instructions": "keep the instructions short and to the point",
"when_to_update": "Update this prompt whenever there is feedback on which emails should be responded to"
}
]可以發現到,main_agent 的 Prompt 已經被更新為「Use these tools when appropriate to help manage John’s tasks efficiently. When sending emails, always sign them as “John Doe”。」。這樣的話,當 Email Agent 在進行 Email 回覆時,就會自動將簽名改成 John Doe。
7 結語
本篇文章介紹了 Agent Memory 的基本概念,並且透過一個 Email Agent 的範例來說明如何透過 LangMem 實現 Semantic Memory, Episodic Memory 以及 Procedural Memory。
本篇文章為 DeepLearning.AI 所開設的 Long-Term Agentic Memory with LangGraph 課程筆記,完整的範例程式碼可以參考 Building a Memory-Enhanced Email Agent with LangGraph。