告別固定的 Top-k!Adaptive-k 如何在不增加延遲下,為 RAG 動態選出最佳上下文

1 前言
本篇文章和大家分享 Efficient Context Selection for Long-Context QA: No Tuning, No Iteration, Just Adaptive-k 論文,該論文於 2025 年 6 月上傳至 arXiv 並被 EMNLP 2025 (Main) 會議給接受!
論文作者也有開源程式碼於 GitHub,有興趣的讀者可以再自行測試看看!
2 Adaptive-k 方法想解決的問題
在 Retrieval-Augmented Generation (RAG) 的方法中,我們經常透過 “Top-k” 的方式來選擇 k 個與 Query 最相似的 Document Chunks 放入 LLM 的 Context 中,讓 LLM 能夠有效的基於外部知識來生成減少幻覺的回答。
然而,在實務上 Top-k 的作法過於簡單暴力,有時候會取出太多不相關的資訊,反而造成 LLM 產生幻覺或是表現變差;有時候又因為取出的資訊不足,使得 LLM 無法產生正確的答案。因此,在 RAG 領域中,“Top-k” 的 “k” 應該要設定多少一直是一個難題。
為了提升 Retrieval 的彈性,過去也有許多 Adpative RAG 的方法 (e.g. Self-RAG, Adaptive-RAG) 被提出來,讓 LLM 能夠根據問題本身選擇不同的 Retrieval 方法,或是自行決定何時該 Retreve,透過 Iterative 的方式進行多次 Retrieve 來收集到足夠多的資訊。或是針對 Retrieved Documents 進行 Refinment 的作法也不少見,CRAG 就是其中的經典!
然而可以發現到,無論是 Adaptive RAG 或是 Corrective RAG 系列的作法,不外乎都會造成更長的 Inference Latency,進而影響使用者體驗。
因此,這也是本篇論文 (以下簡稱 “Adaptive-k”) 想處理的問題:
如何能夠更動態彈性的決定每次 Retrieval 的 k 值且又不會犧牲 Inference Latency
3 Adaptive-k 方法介紹
用一句話總結 Adaptive-k 方法的精隨:
Adpative-k 方法就是在每一次 Retrieval 結果中,將 Query 與每個 Document Chunks 的 Similarity Score 進行降序排列,然後找到 Similarity Score 下降最大的那個 Gap。僅保留在 Gap 之前 Similarity Score 較高的 Document Chunks。
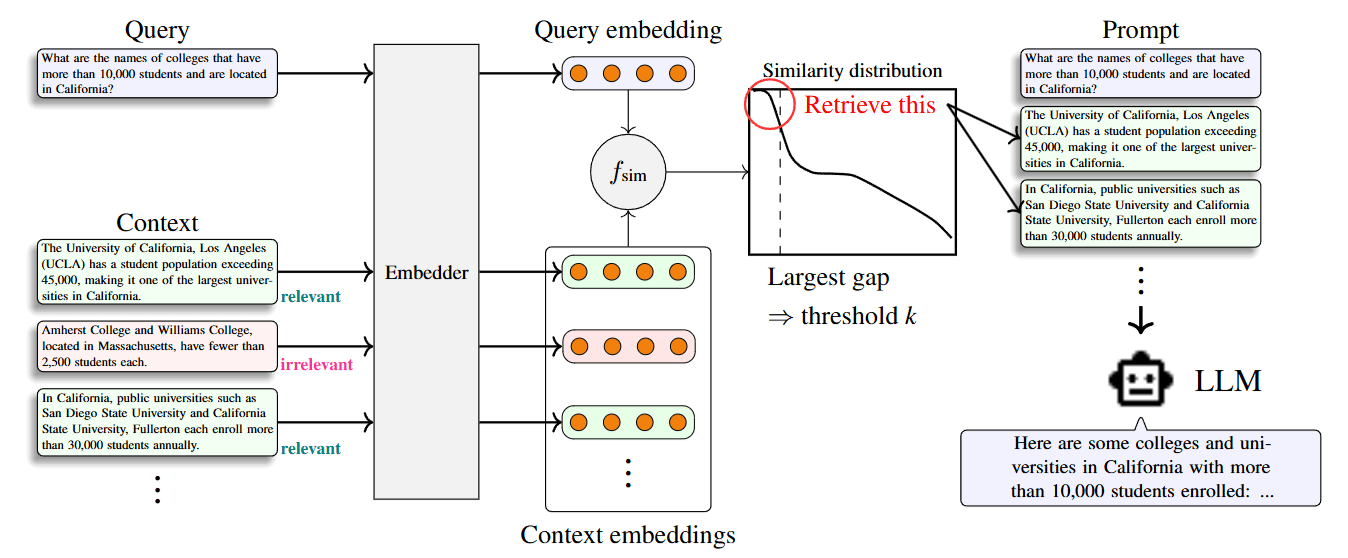
上圖呈現的是 Adaptive-k 方法的示意圖;下圖則是 Adaptive-k 方法的演算法:

在論文中作者有特別提到: 在實務上,如果都只根據 Similarity Score Gap 來選擇前 k 個 Document Chunks 時,可能會導致一些與 Query 相關的 Document Chunks 分布在 Gap 之後而未被選取。因此作者有多設定一個 Buffer Size “B”,最後被取出的 Document Chunks 總數為 “k+B”。(論文中設定 B=5)
4 結語
本篇文章介紹了 Efficient Context Selection for Long-Context QA: No Tuning, No Iteration, Just Adaptive-k 論文,理解其如何透過 Similarity Score 分布的分析,而設計 Adaptive-k Retrieval 的機制,改善傳統 RAG 中 Top-k Retrieval 的缺點。