AI 的下一步:Agentic Context Engineering,讓你的模型學會思考與進化

1 前言
本篇文章和大家分享 Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models 論文,該論文於 2025 年 10 月上傳至 arXiv,目前已經投稿到 ICLR 2026 會議,投稿結果尚未出爐!
本篇論文在方法上,主要是基於 Dynamic Cheatsheet 進行優化,建議讀者在閱讀本篇文章之前,可以先閱讀此篇文章,來對 Dynamic Cheatsheet 方法有基本的理解。
2 Agentic Context Engineering 想解決的問題
在現今基於 LLM 所打造的 AI 系統中,絕大多數都是基於 Context Engineering (Context Adaption) 的概念。整個 AI System 其實就像是一個 Context Scheduler,努力的在每個狀態下提供最適合的 Context 到 LLM 的有限的 Input Context Window 中,使得 LLM 在這個狀態下可以產生正確的輸出。
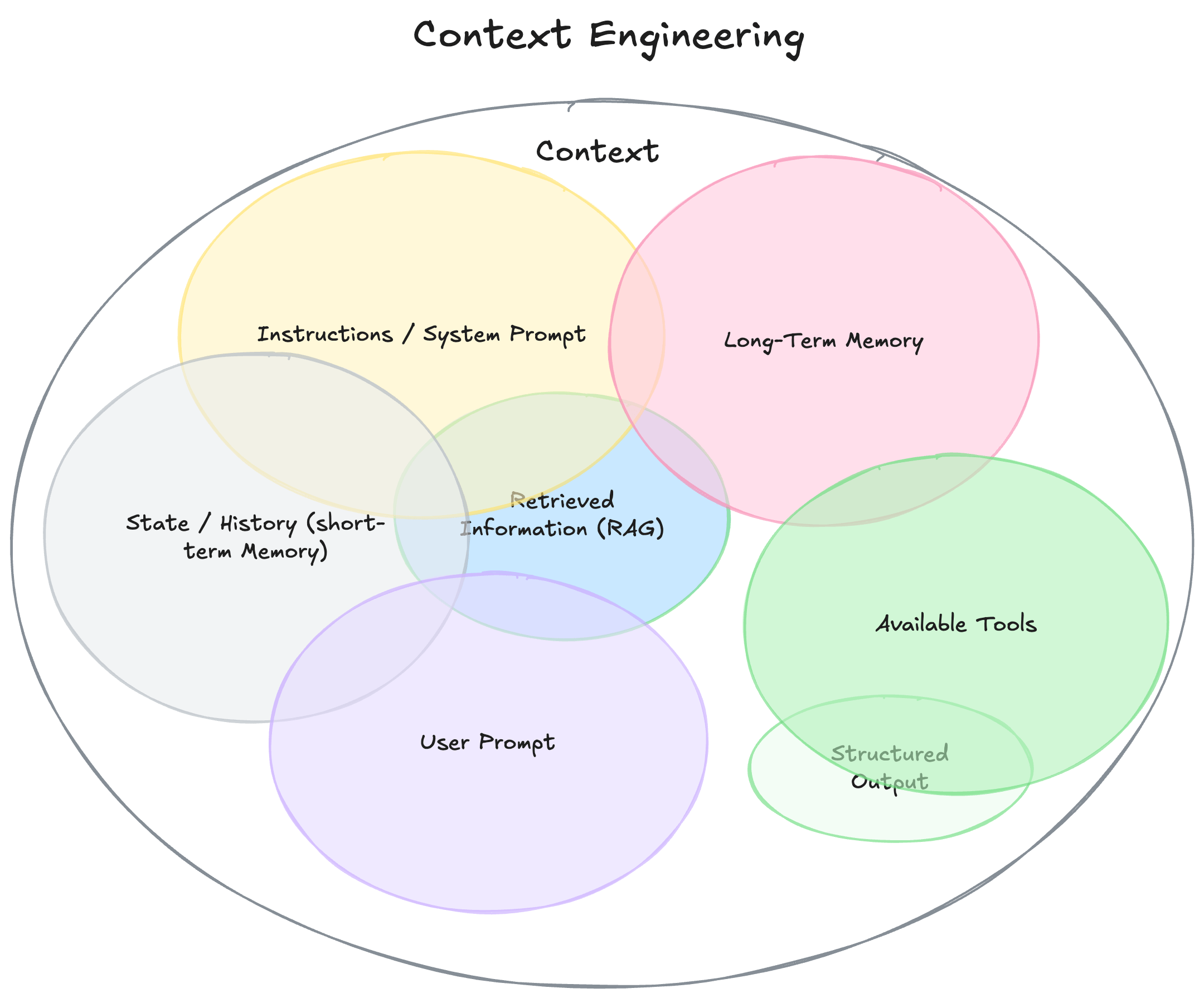
如上圖所示,在 LLM 的 Input Context 中可以放 System Prompt, User Prompt, Long-Term Memory, Short-Term Memory, …, 等多種不同的資訊。而在 Context Engineering 中,我們又可以透過多種不同的方式來優化這些 Context。
舉例來說,在系統的 Offline 階段,我們可以透過 Prompt Optimization 方法來事先優化 System Prompt 與 User Prompt,或是產生更多高品質的 Few-Shot Examples;而在系統的 Online 階段,我們也可以透過 Agentic Memory 的方法讓 LLM 分析每一次的 Inference Trace,並萃取出一些 Feedback 或 Insight 更新進去 Memory。而 Memory 中的資訊也會作為 LLM 下一次 Inference 的 Input Context 使得輸出更正確。
而本篇作者認為,現有的方法在進行自動化的 Context Engineering 的過程中,存在以下 2 種缺點:
- Brevity Bias: 在 Context 的優化過程中,LLM 容易將 Context 優化的很簡潔,使得許多 Domain-Specific 的資訊消失,進而導致系統的表現變差 (e.g. GEPA)
- Context Collapse: 在 Context 的優化過程中,當 Context 累積到一定的量時,LLM 傾向大幅的刪減 Context 形成更簡潔的摘要。由於許多資訊從 Context 被移除,導致系統的表現變差 (e.g. Dynamic Cheatsheet)。
如下圖所示,LLM 在第 60 個 Adaption Step 時,突然將 Context 由原本的 18282 個 Token 縮減為 122 個 Token,讓整個系統的表現突然變差:
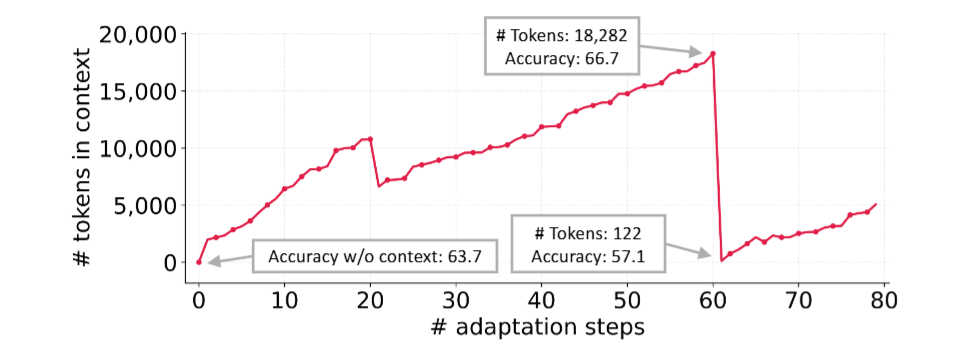
Context Collapse 範例
基於上述兩種缺點,Agentic Context Engineering 方法主張的精神在於:
Context 不應該是一個簡潔的摘要,而應該是一個 (1) 包含許多且全面資訊 (2) 隨著時間不斷更新資訊 的知識庫
3 Agentic Context Engineering 方法介紹
本篇論文所提出的方法稱為 Agentic Context Engineering 簡稱 ACE,同時適用於系統在 Offline (e.g. System Prompt Optimization) 與 Online (e.g. Test-Time Memory Adaptation) 狀態時的優化。
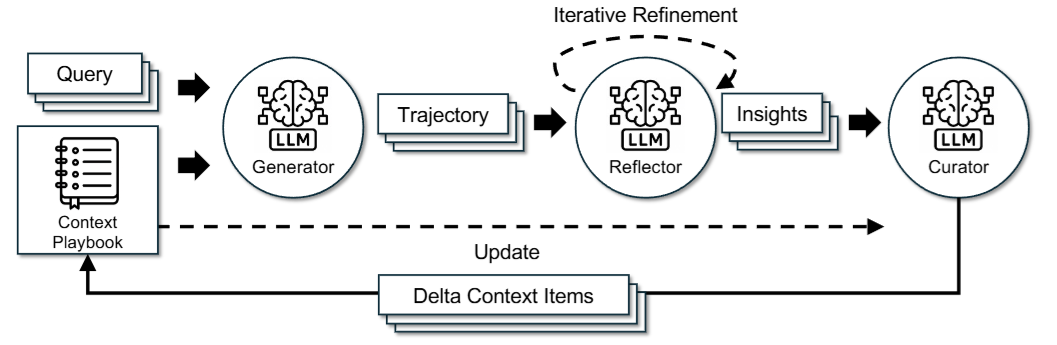
如上圖所示,ACE 方法主要可以拆解為 3 個角色:
- Generator: 負責產生 Reasoning Trajectories
- Reflector: 負責從成功與失敗的 Reasoning Trajectories 中得到一些 Insight
- Curator: 負責將這些 Insight 更新到 LLM 的 Structured Context 中
為了解決 Brevity Bias 與 Context Collapse 的問題,ACE 提出了兩種更新 Context 的方法:
- Incremental Delta Updates
- Grow-and-Refine
3.1 Incremental Delta Updates
ACE 認為 Context 是由許多結構化的 Item 所組成的,而不只是單純的一大串 Prompt。每個 Item 由 Metadata 與 Content 組成。在 Metadata 中記錄著這個 Item 被使用的次數,象徵這個 Item 的有用程度;而 Content 則是一段文字,描述一個可以重複被使用的策略、領域知識或是常見的錯誤。
當 Generator 在處理新的問題時,也會針對這些 Item 提供一些 Feedback,讓 Reflector 可以基於這些 Feedback 得到更多修正 Context 的 Insight。Reflector 會再進一步將這些 Insight 整理為多個 Candidate Item,而 Curator 就可以將這些 Item 整合到 Structured Context 中。
ACE 方法特別強調,由於 Context 本身是 Strcutred 的,因此在更新 Context 時可以只針對需要被修改的 Item 進行更新,或是只新增新的 Item,而不是直接讓 LLM 重寫整份 Context。
3.2 Grow-and-Refine
在 ACE 中為了避免 Context 中出現重複的資訊,會辨識目前要更新 Item 是否已經存在於 Context 中。如果已經存在,則將其與既有的 Item 整合;如不存在,才會新增新的 Item 到 Context 中。此外,也會透過 Semantic Embedding 來比較兩個 Item 的相似度,如果相似度過高則會將重複的 Item 移除。
3.3 Agentic Context Engineering 與 Dynamic Cheatsheet 比較
我們總結 ACE 方法主要有以下 3 個特點,並與 Dynamic Cheatsheet 方法進行比較:
- Reflector: 在 ACE 中,明確的分成 Reflector 與 Curator 兩種角色;而在 Dynamic Cheatsheet 中,則是由同一個 LLM 同時完成這兩件事情
- Incremental Delta Updates: 在 ACE 中,基於 Structured Context 以 Item 為單位來更新 Context;而在 Dynamic Cheatsheet 中,則是讓 LLM 每次都重寫整份 Context
- Grow-and-Refine: 在 ACE 中,會特別避免 Context 中出現重複的資訊;而在 Dynamic Cheatsheet 中,沒有特別提及
4 Agentic Context Engineering 實驗結果
ACE 在實驗階段使用以下 2 種類型的 Benchmark:
- Agent Benchmark: LLM Agent: AppWorld
- Domain-Specific Benchmark (Financial Analysis): FiNER 與 Formula
所有 Benchmark 都遵循原來的 Train/Validation/Test Split 的切割方法。針對 Offline 的 Context Engineering 情境,所有方法都先基於 Train Split 進行優化,再於 Test Split 上透過 Pass@1 指標進行評估。針對 Online 的 Context Engineering 情境,所有方法都是直接測試在 Test Split 上,每進行一次 Inference 就會更新一次 Context,因此理論上愈後面的 Test Sample 會得到愈正確的輸出。
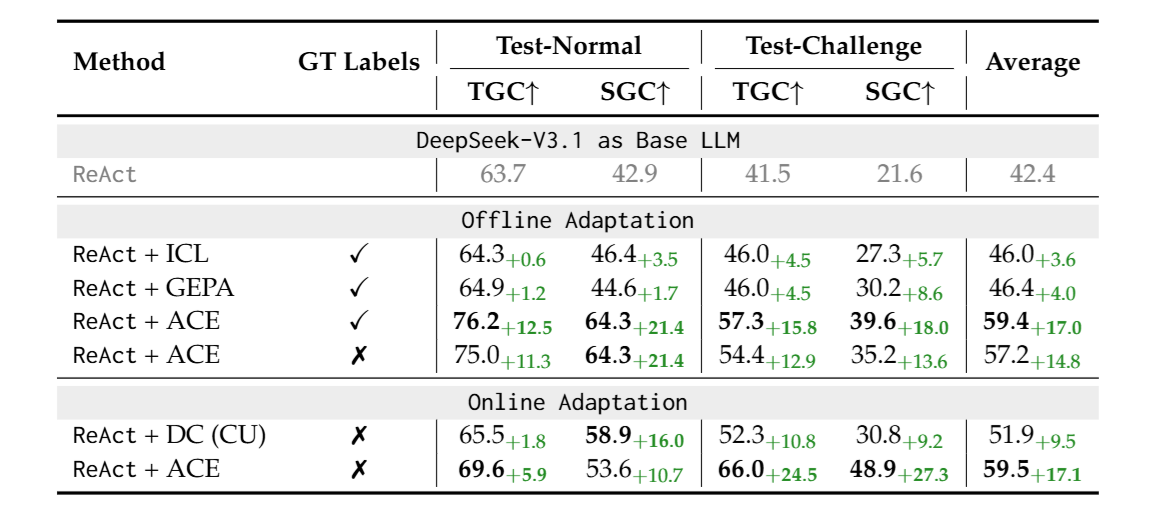
上表 Table 1 呈現的是 ACE 與 Baseline 方法在 AppWorld Agent Benchmark 上的表現,其中 “GT labels” 表示 Reflector 在從 Inference Trace 中萃取出 Insight 的過程中,可不可以看到 Groundtruth Label。從 Table 1 可以發現到不管在 Offline 與 Online 情境下,ACE 的表現都勝過其他 Baseline 方法!
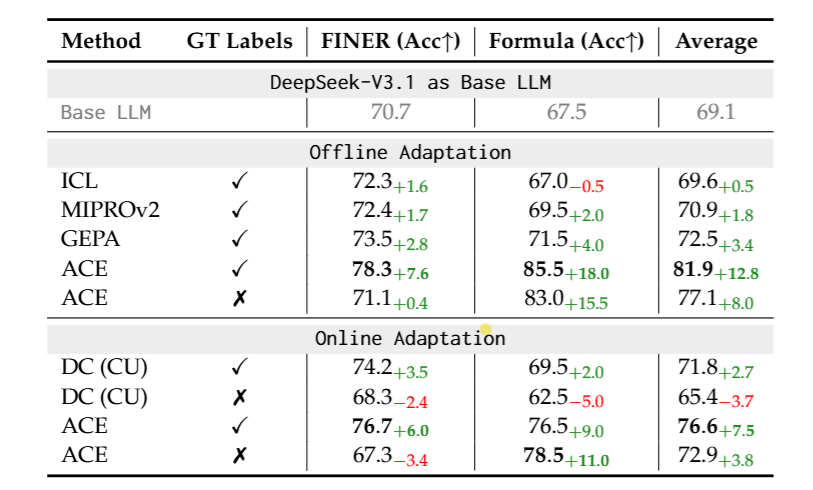
從上表 Table 2 也可以看到 ACE 方法在兩種情境設定下,都表現得比 Baseline 方法更好。
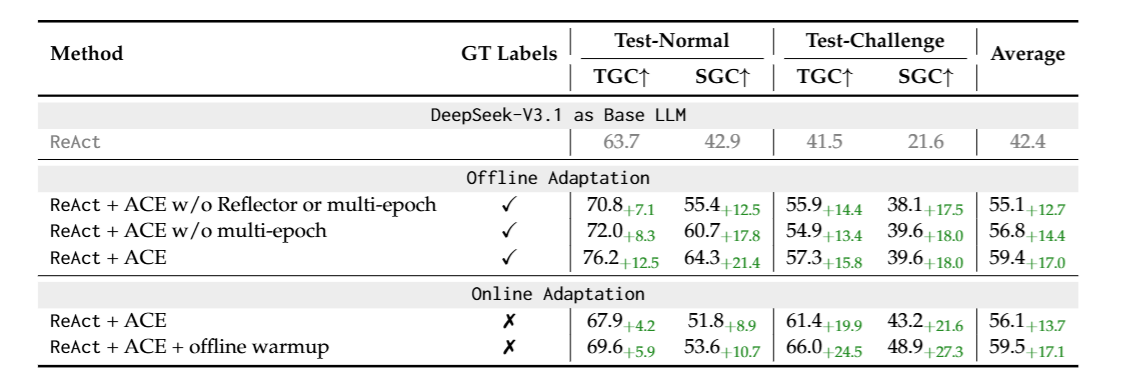
從上表 Table 3 可以發現到,在 Offline 的情境下,如果把 ACE 中的 Multi-Epoch 機制拿掉,其實表現會變差一些。這說明了在 Offline 情境下,在優化 Context 的過程中,一個 Training Sample 如果看更多次其實是可以帶來效益的!
這其實就好像我們真的訓練模型的參數那樣,訓練了一個 Epoch 後,模型的參數被改變,使得模型來到 Loss Surface 上的不同位置。在下一個 Epoch 中,模型針對相同的樣本會得到不同的預測結果,透過不同的預測結果計算出新的 Gradient,再利用這個 Gradient 更新模型的參數,使得模型又來到 Loss Surface 上更低的位置。
同理,在 ACE 的 Multi-Epoch 中,基於 Agentic Workflow 目前的 Context 來對訓練樣本進行預測,可以得到一種 Insight,透過這個 Insight 來更新 Agentic Workflow 的 Context。在下一個 Epoch 中,由於 Workflow 的 Context 已經改變,相同的訓練樣本也可能得到不同的結果,導致得到不同的 Insight,進而對 Workflow 的 Context 進行不同面向的更新。
最後,從 Table 3 的 Online 情境下也可以看到,透過事先的 Offline Warmup (也就是先透過 Offline 的方式優化 Context,並將這個優化過後的 Context 作為 Online 情境的初始化 Context),也可以提升 Workflow 在 Online 情境中的表現。
5 結語
本篇文章介紹了 Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models 理解 ACE 如何透過 Reflector, Incremental Delta Updates 以及 Grow-and-Refine 來實現 Agentic Workflow 的 Self-Evolve。
讀完整篇論文,覺得此篇論文雖然在問題定義上交代得很清楚,在實驗結果也呈現亮眼的成績,但是總感覺在方法設計上除了強調是基於 Dynamic Cheatsheet 上進行優化的之外,還有許多細節沒有提到。目前也還沒有找到相關的 GitHub 連結,這是比較可惜的部分!