突破大模型排行榜迷思:用 AgentOpt 自動尋找性價比最高的 AI Agent 模型組合

1 前言
這篇論文 “AgentOpt v0.1 Technical Report: Client-Side Optimization for LLM-Based Agent” 代表了 AI 優化領域的一個重要轉向。過去,學術界與工業界瘋狂追求的是 「服務端(Server-side)」 的效率(例如:如何讓推論引擎更省油、吞吐量更高);但本論文卻另闢蹊徑,關注的是身為開發者的我們,在 「客戶端(Client-side)」 所擁有的掌控權與優化空間。
1.1 TL;DR
當一個 AI Agent 由多個角色(如規劃者、執行者、評論者)組成時,「如何組合模型」 對最終效能與預算的影響,遠大於單一模型的強弱。
AgentOpt 是第一個專為「客戶端 Agent」設計的開源 Python 框架。它不要求你改寫既有的程式碼,卻能透過聰明的「多臂強盜演算法(MAB)」與「HTTP 攔截技術」,在茫茫的模型組合空間(如 種組合)中,用最少的測試預算(節省高達 67%)幫我們找出「性價比最高」的黃金組合。
1.2 核心架構概覽
它展示了 AgentOpt 是如何將 Agent 工作流視為一個黑盒子,並透過迭代循環來尋找柏拉圖前沿。
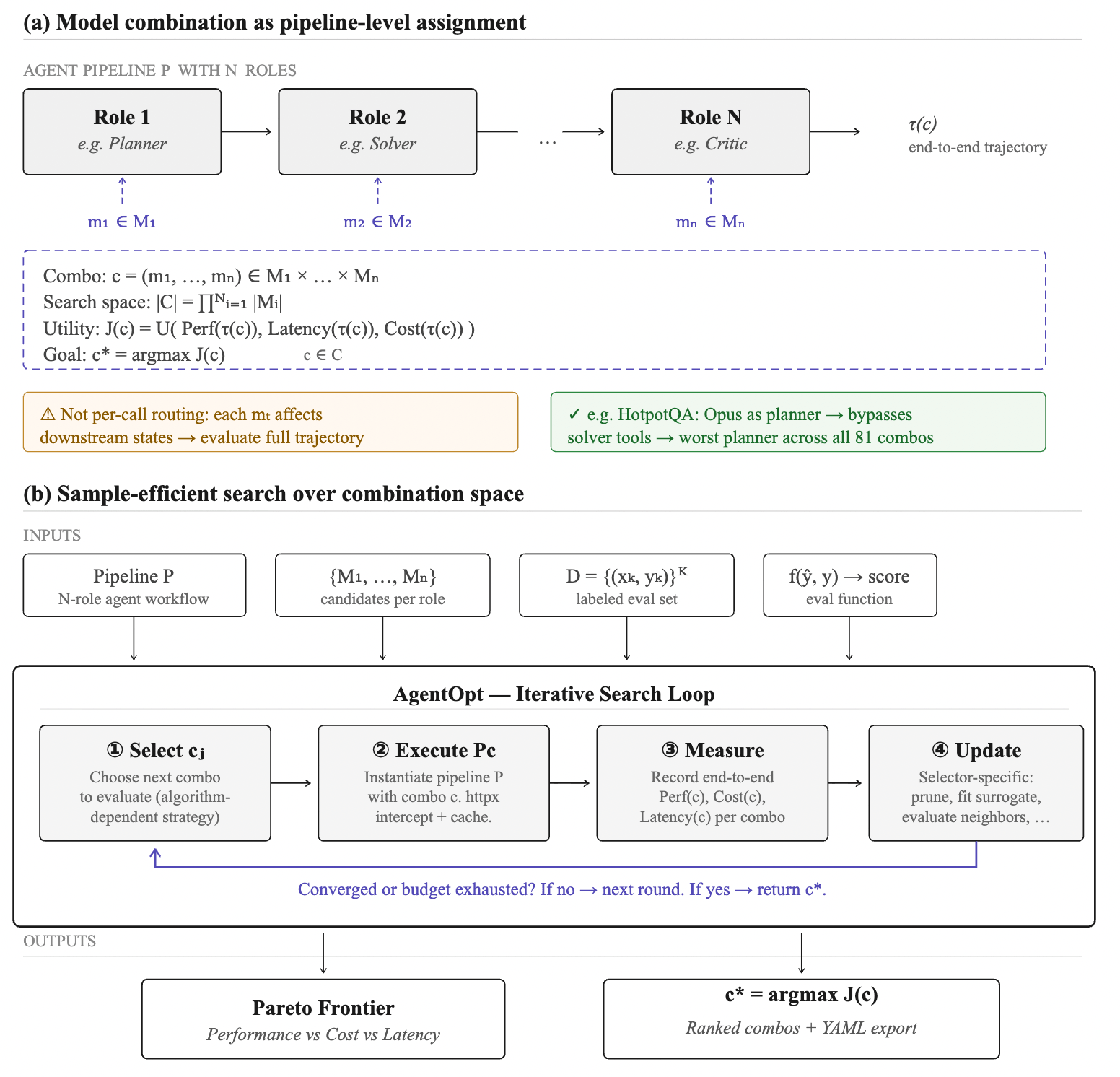
2 問題定義
在進入 AgentOpt 的技術世界前,我們必須先看清現在 AI Agent 開發者的處境。目前的優化領域存在著一個 Gap。
2.1 服務端與客戶端的優化斷層
過去的研究(如 vLLM, SGLang, Autellix)高度集中在 服務端(Server-side)。
- 服務端的邏輯:追求的是 Inference Engine 的極致,例如透過 Request Scheduling、Speculative Execution 或 KV Cache 來降低成本。這是在優化 Infra。
- 客戶端的痛點(我們的視角):身為 Agent Builders,我們面臨的是「如何配置手頭資源」的問題。我們需要決定模型組合、本地工具的使用時機、以及在不同步驟間分配 API 預算。
2.2 為什麼「傳統路由」在 Agent 面前無能為力?
論文釐清了一個關鍵點:Agent 的優化絕非傳統的 LLM Routing。
- Agent 的執行是一連串多步驟的軌跡。上一步模型的輸出,會徹底改變下一步模型面對的狀態。
- 單體能力最強的模型,放在整個 Workflow 中可能因為「過度聰明」而跳過關鍵步驟,導致整條流程崩潰。這代表我們無法透過單一模型的排行榜來推測它在 Agent 流程中的表現。
2.3 組合爆炸
假設一個 Agent 有 個角色,每個角色有 個候選模型。這是一個組合爆炸的問題:
- 數學規模:搜索空間大小為 。
- 預算殺手:如果要在所有組合上跑完 200 題測試,光是一個基準測試可能就要噴掉上百美金。
- 直覺失靈:論文實驗證明,即便是最強的大模型,也無法靠直覺「猜」出哪個組合最強。
3 方法介紹
AgentOpt 的設計理念非常純粹:既然我們無法預測組合的表現,那就建立一個 「全自動、超省錢、無侵入」 的黑盒子試車場。
3.1 支柱一:將 Agent 定義為「黑盒子優化」
我們將整個 Agent 流程視為一個不可導的黑盒子。
3.1.1 核心抽象:Combo (組合)
我們定義一個模型組合 為一個原子單位。給定一個查詢題目,這個 Combo 會產生一個End-to-end Trajectory 。
3.1.2 效用函數 (Utility Function)
我們追求的是 的最大化。這是一個多目標優化的權衡:
- 權重參數 :這體現了「個人化優化」。醫療 AI 的開發者會把 設為 0(不計成本追求準確);而即時客服的開發者會把 設很高(追求速度)。
3.2 支柱二:執行引擎的工程黑魔法
為了讓開發者「無痛」使用,AgentOpt 實作了一套極為優雅的攔截機制。
3.2.1 HTTP 傳輸層攔截 (Framework-Agnostic Interception)
這是論文中最精彩的工程細節:
- 為什麼選
httpx? 因為它是現代 AI 框架(OpenAI, Anthropic SDK)底層共通的連線庫。 - 猴子補丁 (Monkey Patching):AgentOpt 在底層攔截了
httpx.Client.send。這意味著:你不需要改動任何 LangChain、AutoGen 或自己的程式碼,系統會自動在 API 發出那一刻「偷天換日」。
import contextvars
import httpx
from agentopt.proxy import LLMTracker
tracker = LLMTracker(cache=True)
_current_data_id = contextvars.ContextVar("data_id", default=None)
_current_combo_id = contextvars.ContextVar("combo_id", default=None)
_original_send = httpx.Client.send
_original_async_send = httpx.AsyncClient.send
def patched_send(self, request, *args, **kwargs):
data_id = _current_data_id.get()
combo_id = _current_combo_id.get()
with tracker.track(data_id=data_id, combo_id=combo_id):
return _original_send(self, request, *args, **kwargs)
async def patched_async_send(self, request, *args, **kwargs):
data_id = _current_data_id.get()
combo_id = _current_combo_id.get()
with tracker.track(data_id=data_id, combo_id=combo_id):
return await _original_async_send(self, request, *args, **kwargs)
httpx.Client.send = patched_send
httpx.AsyncClient.send = patched_async_send在平行測試中,幾百個 API 請求會同時在飛。
contextvars的妙用:確保攔截器抓到的每一個 Token 花費,都能精準歸屬到正確的combo_id與data_id,絕不張冠李戴。
3.2.2 智慧快取與延遲保留 (Latency-Preserving Cache)
- 快取的必要性:如果 Combo A 和 Combo B 的 Planner 是一樣的,那 Planner 的這筆 API 錢就可以省下來。
- 最神細節:傳統快取會讓延遲測量變為 0。但 AgentOpt 的快取會強行保留該請求第一次發送時的真實延遲。這確保了我們在對比各組合的「延遲表現」時,數據依然是絕對公平的。
3.3 支柱三:搜索策略 (Selection Policy)
這解決了「沒錢測完所有組合」的痛點。AgentOpt 引入了 Multi-Armed Bandit, MAB 理論。
3.3.1 MAB 理論的比喻
我們將 81 種 Combo 視為 81 台吃角子老虎機。
- 拉一次搖桿:讓該 Combo 測「一題」資料。
- 獎勵:跑出來的效用分數。
- 核心兩難:我們要在「探索(測還沒測過的組合)」與「利用(把預算留給最強組合)」之間找平衡。
3.3.2 三大 MAB 演算法細節
- Arm Elimination —— 【預設王者】:
- 邏輯:大亂鬥淘汰賽。每一輪計算各組合的信賴區間 。
- 淘汰準則:若挑戰者的「最好潛力 」 < 衛冕者的「保底實力 」,直接踢出選秀。
- 優點:極度穩健,幫我們省下 24% - 67% 的錢,且幾乎不會漏掉冠軍。
- Epsilon-LUCB —— 【極限省錢】:
- 邏輯:只讓「第一名」跟「最強挑戰者」單挑。
- 特點:預算極度集中。在論文實驗中甚至省下了 96% 的費用,但風險是可能會因為測試量太少而選到次優解。
- Threshold SE —— 【商業實務】:
- 邏輯:檢定考。
- 特點:只要確定組合「及格」或「死當」就收工。這非常適合尋找那些「剛好達到門檻但價格最便宜」的組合。
3.3.3 其他失敗的對照組
- Hill Climbing:容易卡在局部最佳解。因為 Agent 角色是高度耦合的,換一個角色變爛,不代表換兩個角色不會變超強。
- 貝葉斯優化 (BO):假設地形是平滑的。但 Agent 的效能地貌充滿斷崖,BO 的「代理模型」容易預測失準。
- LM Proposal:大模型的直覺在複雜系統互動面前,表現得像個外行人(準確率僅 34%)。
4 實驗結果
4.1 實驗場景
- HotpotQA (Multi-Hop 檢索):測試「規劃與搜尋」的協作。
- GPQA Diamond (高難度科學):測試「推理」的極限。
- MathQA (數學推理):測試「解答與評論(Answerer-Critic)」的循環重試機制。
- BFCL v3 (函式呼叫):測試「工具使用」的精準度。
4.2 核心發現一:Opus 悖論與能力的誤區
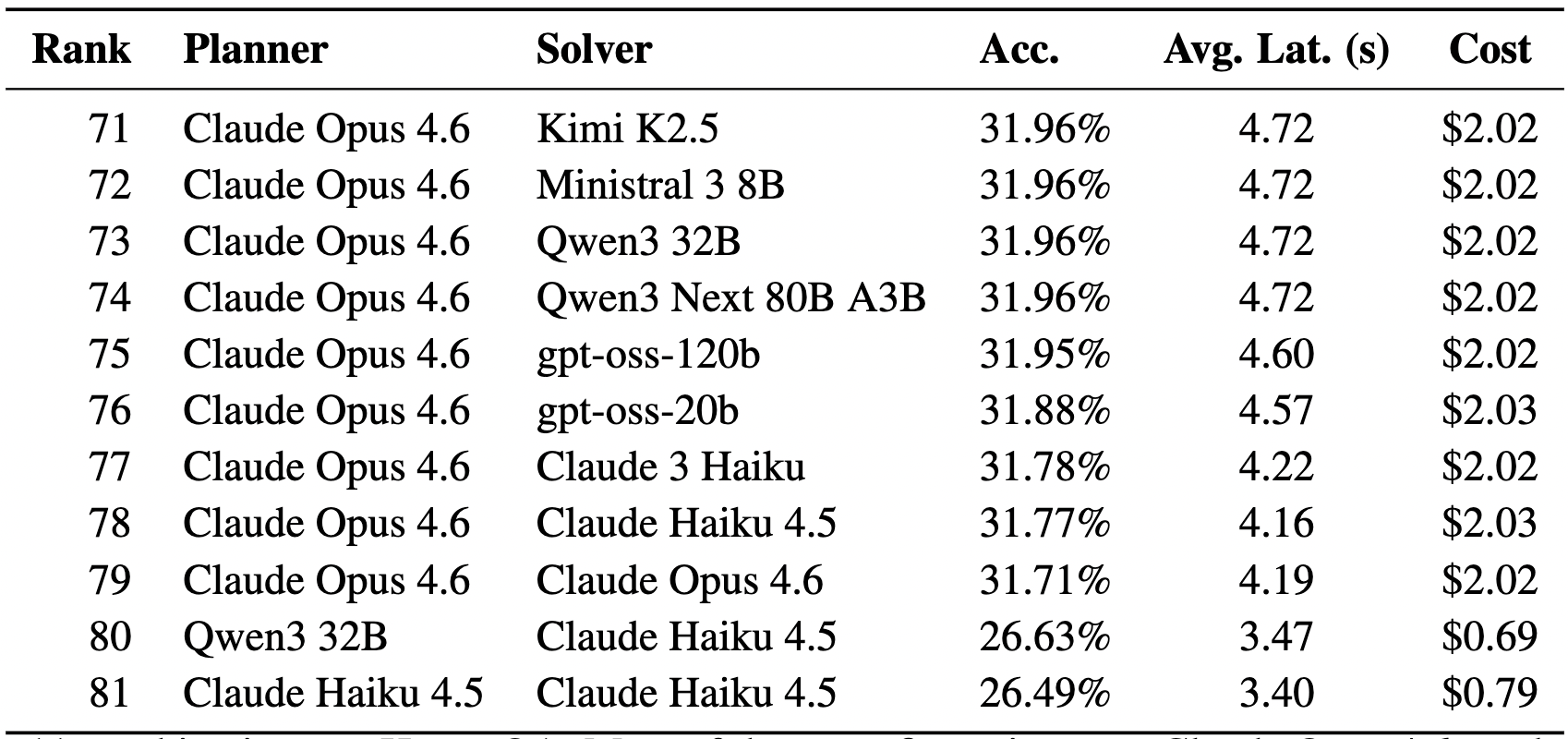
你可以發現排名第 71 到 79 名的『規劃者』通通都是最強模型 Claude Opus 4.6。這證明了:在 Multi-Hop 流程中,模型的能力太強(太自負)反而會導致它跳過必要的工具呼叫,造成系統性失敗。
在 HotpotQA 任務中,最強組合是 (Ministral 3 8B + Opus 4.6)。讓「弱模型」負責規劃,因為它知道自己能力不足,會乖乖地生成搜尋關鍵字;再讓「強模型」負責最終整合。這種「弱主強從」的配置,比「強強聯手」的準確率高出了一倍以上(74.27% vs 31.71%)。
4.3 核心發現二:32 倍的成本鴻溝
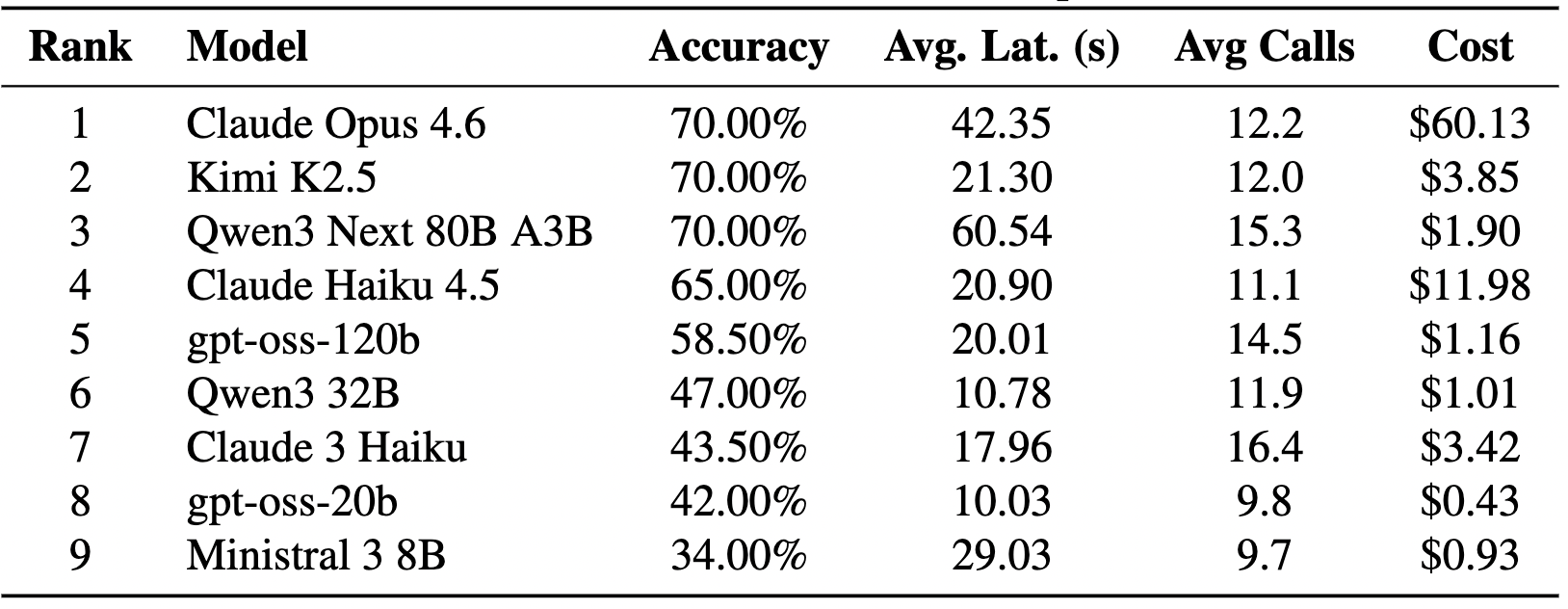
這個結果證明了:Qwen3 Next 80B 與 Claude Opus 4.6 在函式呼叫的準確率上完全持平(均為 70%)。但 Qwen3 的成本僅需 $1.90,而 Opus 卻要 $60.13。這兩者之間存在著 32 倍的恐怖價差。
4.4 演算法對決:為什麼 Arm Elimination 是最後的贏家?
對比了 8 種演算法,結果顯示 Arm Elimination (AE) 是真正的全能型選手。
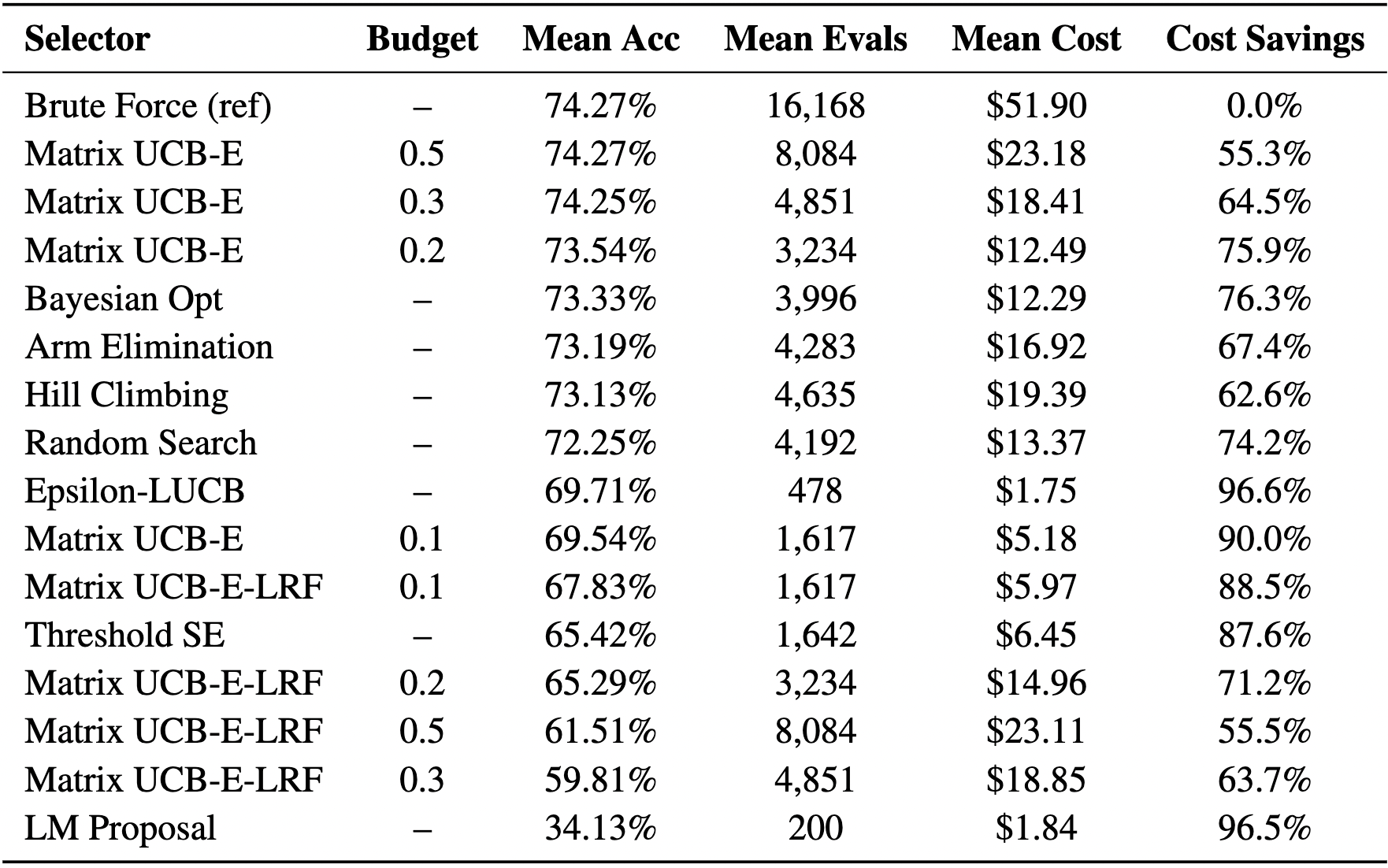
這張 HotpotQA 演算法對比表證明了:AE (Arm Elimination) 僅用了 4,283 次評估就找到了準確率 73.19% 的組合,相較於暴力搜索的 16,168 次,它在幾乎無損準確率的情況下節省了 76.3% 的測試成本。
- AE vs. BO (貝葉斯優化):在 MathQA 中,AE 的準確率顯著超越了 BO。這是因為 Agent 的效能地貌(Landscape)並非 BO 假設的平滑山丘,而是充滿斷崖。AE 這種「不假設、只看數據」的淘汰機制,比試圖預測規律的 BO 更能應付破碎的地形。
- AE vs. Epsilon-LUCB:雖然 LUCB 在某些任務中省下了 96% 的預算(極致省錢),但它的準確率往往會掉個 2~4%。
5 結論
5.1 總結與核心貢獻
這篇論文為我們補齊了 Agent 優化的一塊拼圖:Client-Side 資源配置。
- 問題定義:將模型選擇定義為一個「離散空間的黑盒子優化問題」,打破了單模型排名的迷思。
- 方法論:推出了
AgentOpt框架。利用 HTTP 傳輸層攔截 實現了框架無關的無痛監測;利用 Multi-Armed Bandit 實現了樣本效率極高的模型組合搜索。 - 實證:證明了「組合」才是 Agent 的靈魂,並挖掘出 32 倍成本縮減與「弱規劃、強執行」等極具實戰價值的洞察。