[論文介紹] AutoMind: Adaptive Knowledgeable Agent for Automated Data Science

1 前言
本篇文章介紹 AutoMind: Adaptive Knowledgeable Agent for Automated Data Science 論文,AutoMind 由 Zhejiang University 與 Ant Group 的研究人員於 2025 年 6 月被發布到 arXiv 上。
AutoMind 論文的目標在於提出一個 LLM-Based Agentic Framework 來處理 Data Science Challenge (e.g. Kaggle Competition)。
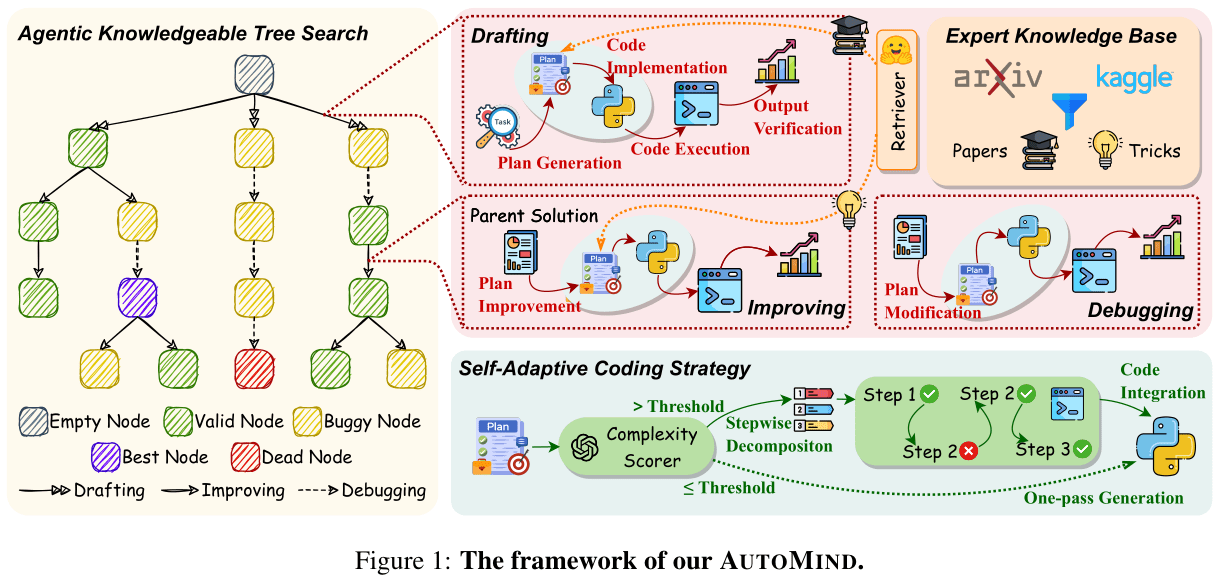
如上圖所示,AutoMind 框架中包含 3 個核心方法:
- Expert Knowledge Base for Data Science: 針對 Data Science Task 建立知識庫
- Agentic Knowledge Tree Search Algorithm: 透過 Tree 來組織 Agent 於 Solution Space 中的探索過程
- Self-Adaptive Coding Strategy: 針對複雜的問題,拆解為多個步驟,單獨針對每個步驟產生程式碼
2 AutoMind 想解決的問題
如同上文所述,AutoMind 的目標在於提出一個 LLM-Based Agentic Framework 來處理 Data Science Task (可以想像 AutoMind 就是一個 Data Science Agent)。作者認為過去的方法 (e.g. AIDE, Data Interpreter, AutoML-Agent) 具有以下兩個缺失,導致這些 Data Science Agent 的表現不夠好:
- LLM 在 Data Science Task 的知識不足: 雖然 LLM 已經被預訓練在大量的 Code-Based Corpus 上,但是在處理 Data Science Task 時所使用的方法(程式碼)大多是人類專家透過反覆的實驗所得到的,LLM 在這部份的知識其實是不夠的
- LLM 生成程式碼的過程缺乏彈性: 過去方法使用缺乏彈性的策略來讓 LLM 生成程式碼,導致 LLM 僅能夠針對一些比較簡單或是經典的任務來生成程式碼
可以很明顯的觀察到,AutoMind 中的第一個 (Expert Knowledge Base for Data Science) 與第二個 (Agentic Knowledge Tree Search Algorithm) 方法,對應到第一個問題,而第三個方法 (Self-Adaptive Coding Strategy) 對應到第二個問題。
3 AutoMind 方法 (1): Expert Knowledge Base
為了讓 LLM 能夠理解 Data Science Task 所需的知識,AutoMind 建立了一個 Knowledge Base,裡頭主要有兩種類型的知識:
Kaggle Competition Solution: 作者從此網站中篩選出 455 個 Kaggle Competition,並且收集了 3237 篇 Post,每篇 Post 其實就是 Competition 的 Solution
Top Conference Paper: 作者收集了 ICLR, NeurIPS, KDD, ICML, EMNLP 等頂尖會議最近三年的 Paper
建立了 Knowledge Base 後,接著就是要處理 Retrieval 的問題。最直覺的方法,就是透過比較 Task Description 與 Knowledge Base 中 Approach Description 的 Embedding,來進行 Dense Retrieval,但是這樣的作法明顯效果會很差,因為 Task 與 Approach 之間有時候不會有很強的相關性,導致沒辦法取出有幫助的知識。
實際上,這確實也是 Multi-Hop RAG 領域經常遇到的挑戰:針對一個問題,中間需要經過多個步驟的推理(先回答幾個 Intermediate Question)才有辦法得到真正要回答的核心問題,也才有辦法基於這個核心問題,透過 Dense Retrieval 從 Knowledge Base 中取出相關的資料。
如果對於 Multi-Hop RAG 初次認識,不妨閱讀 Demonstrate-Search-Predict 這篇經典論文,或者是另外一篇同樣於 2025 年所發表且方法非常簡單的 NotesWriting。
在 AutoMind 中,針對 Knowledge Retieval 的方法有些暴力,作者會透過 LLM 事先將每個 Kaggle Competition Solution 標上標籤。具體流程是,作者定義了 11 種 Top-Level 的主類別,每種主類別底下又有自己的子類別。讓 LLM 先分辨目前這個 Solution 屬於哪些主類別,再提供相對應的子類別讓 LLM 判斷。作者也透過 Self-Consistency 的方法,確保標籤的選擇是穩定的。
針對 Top Conference Paper,由於 Paper 的內容比 Competition Solution 更為彈性,要給予明確的標籤並不容易,因此作者直接透過 LLM 針對每一篇 Paper 產生 Summary,這個 Summary 包含:Data, Task, Approach 以及 Contribution 等資訊。
實際在 Retrieval 時,AutoMind 一樣會透過 LLM 對 Input Task 進行標籤的分類,然後再針對每個標籤下的 Solution 進行 Retrieval。然而,作者在論文中沒有很清楚的交待清楚實做上是 Dense, Sparse 還是 Hybrid Retrieval。
4 AutoMind 方法 (2): Agentic Knowledgeable Tree Search
4.1 Node Definition
如 Figure 1 所示,在 AutoMind 中,透過一個 Tree 來組織 Agent 在 Solution Space 中的探索。Tree 中的每個節點稱為 Solution Node,每個 Node 都包含以下資訊:
- Plan: 一段文字描述解決目前 Data Science Task 的計畫 (Sequential Stage),Plan 中包含 Data Preprocessing, Feature Engineering, Model Training, Model Validation
- Code: 一段 Python Code 來實做 Plan
- Metric: 從 Code Execution Reuslt 中取出的 Validation Score
- Output: Code Execution 輸出在 Terminal 中的 Output
- Summary: 由 LLM-Based Verifier 針對 Plan, Code, Metric 以及 Output 給予這個 Node 的一個 Summary,同時也判斷這個 Node 是 “Valid Node” 還是 “Buggy Node”
4.2 Search Policy
基於一個 Tree,要如何在這個 Tree 上做搜索,主要由 Search Policy 來決定。Search Policy 的輸入是目前整個 Tree 的狀態,而輸出是一個 Tuple 包含: 選定的 Node 以及要進行的 Action。
在 AutoMind 中,Search Policy 是透過一連串的 Rule-Based 的機率判斷來決定輸出,過程中沒有 LLM 的介入。如下方 Algorithm 所示:

4.3 Action Type
針對每個 Node 可以進行的 Action 以下 3 種,每種 Action 都是讓 LLM 基於不同的輸入來輸出新的 Plan:
- Drafting: 輸入 Task Description 以及從 Knolwedge Base 中取出的相關 Paper,輸出一個 Initial Plan
- Improving: 輸入 Tree 中隨機挑選出來的 Valid Node (Plan, Code, Output) 以及從 Knolwedge Base 中取出的相關 Solution,輸出一個改善過後的 Plan
- Debugging: 輸入 Tree 中隨機挑選出來的 Buggy Node (Plan, Code, Output) ,輸出一個 Debug 過後的 Plan
不管是哪一種 Action 被執行,一旦新的 Plan 被產生出來後,就會基於 Plan 進行 Code Implementation 以及 Code Excution,最後將 (Plan, Code, Metric, Output, Summary) 組成為一個新的 Node 存放回 Tree 中。
5 AutoMind 方法 (3): Self-Adpative Coding Strategy
為了提昇 Code Implementation 的正確性,AutoMind 透過 LLM-as-a-Judge 的方法,針對 Plan 產生一個分數,代表這個 Plan 的複雜度。如果分數低於事先設定好的門檻,則直接讓 LLM 產生完整的 Code;反之,如果高於門檻,則表示 Plan 蠻複雜的,就會讓 LLM 先將 Plan 拆解為多個 Sub-Step,然後依序針對每個 Sub-Step 進行 Code Implementation。
在針對每個 Sub-Step 進行 Code Implementation 時,會先讓 Code 經過 Abstract Syntax Tree 的檢查再執行,並將執行結果作為 Execution Feeback,讓 LLM 繼續進行下一個 Sub-Step 的 Code Implementation。
6 AutoMind 實驗結果
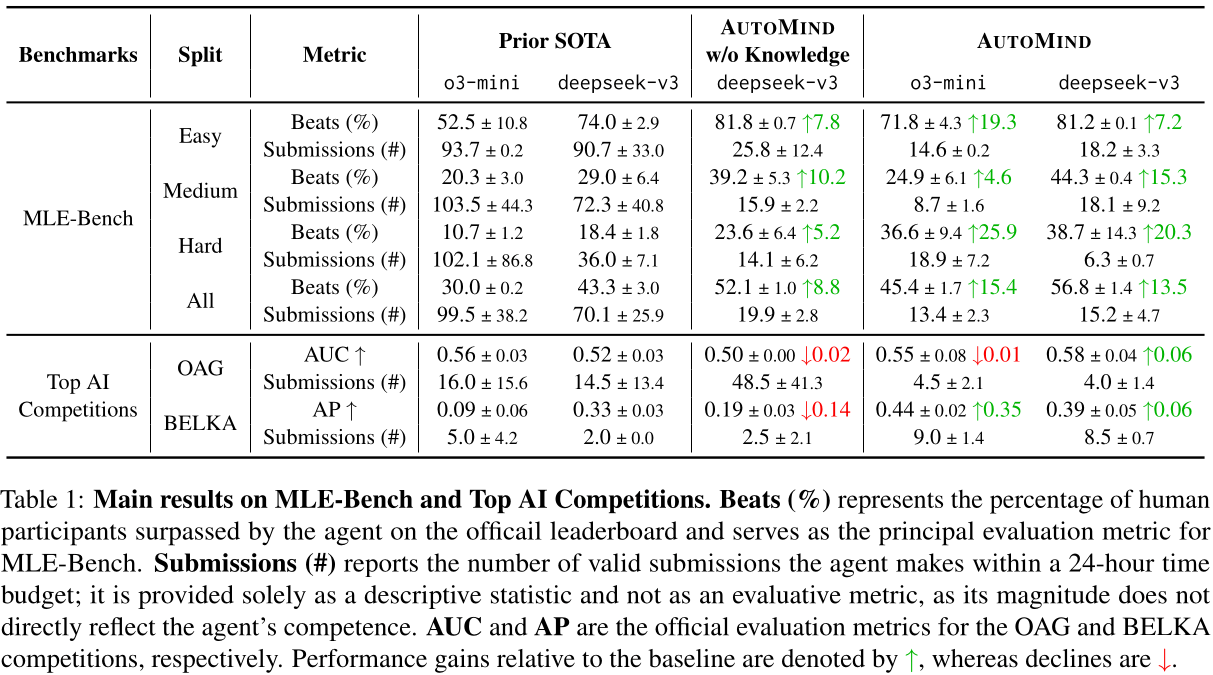
從上表 Table 1 可以發現到 AutoMind 在 MLE-Bench 以及 TOP AI Competitions 上,都透過相對更少的 Submission 次數,達到接近或是比 Baseline 方法更好的表現。
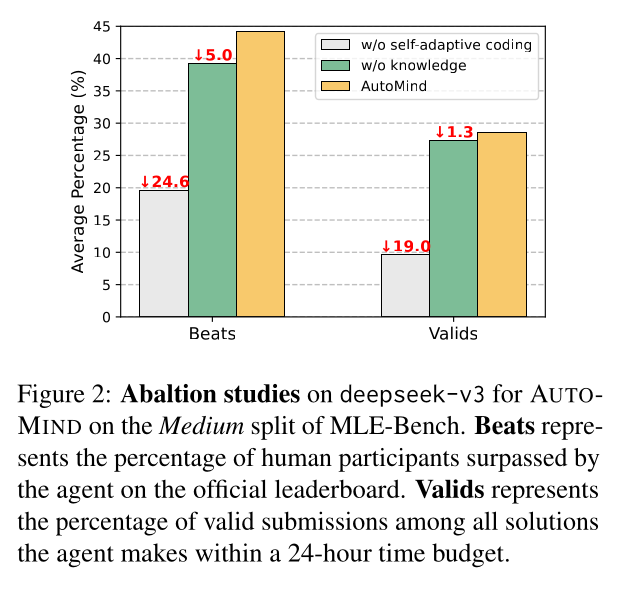
有趣的是,我原本以為 AutoMind 之所以可以有這麼好的表現,很大一部份應該來自於作者特別建立了一個 Data Science Expert Knowledge Base。然而,從上圖的 Abalaton 實驗可以發現到,如果將 Expert Knowledge Base 移除的話,表現雖然會下降但是不多;如果把 Self-Adpative Coding Strategy 移除 (所有 Plan 都透過 One-Pass Generation 產生 Code),對於 AutoMind 的影響非常大。
7 結語
在本篇文章中,我們介紹了 AutoMind: Adaptive Knowledgeable Agent for Automated Data Science 論文,理解如何透過 Large Reasoning Model (e.g. 論文中使用的 o3-mini, deepseek-v3) 建立一個 Agentic Framework 來處理 Data Science Task。
AutoMind 核心方法在於 (1) Expert Knowledge Base (2) Agentic Knowledgeable Tree Search 以及 (3) Self-Adpative Coding Strategy,使其在 MLE-Bench 以及 Top AI Competitions 兩個 Benchmark 上表現的過去的 SOTA 方法更好。