[論文介紹] Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs

1 前言
今天要和大家分享一篇由紐約大學於 2024 年 6 月所發表的論文:Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs!如同標題所述,本篇論文就是想特別著重在「視覺能力」的角度(Vision-Centric)來研究 Vision-Language Model 應該怎麼訓練最好。
論文中真的徹底的探索(如同標題中的 Explore)了 Vision-Language Model 中各種層面的設計,讀完之後真的覺得收穫滿滿(對於 Vision-Language Model 的設計有很充分的理解),也很敬佩這群學者的研究精神,以及他們對這個 Community 的貢獻!
此外,如同標題中的「Open」所言,這項研究的所有模型與訓練資料集完全開源在 HuggingFace 以及 GitHub 上,真心覺得研究者在 AI 領域中所費不貲所做的研究,最後開源給大家使用,真的很佛心!(雖然有些人說如果沒開源 Paper 上不了頂會,但其實也可以看到很多論文在上了頂會之後,就把 GitHub 上的 Repo 下架或是只放一個 README,因此真的還是懷抱感恩的心,感謝這些願意開源的研究者)
在讀完這篇論文之後,我覺得論文所提出的模型名稱「Cambrian-1」真的很有意思!Cambrian 的中文是「寒武紀」的意思,根據維基百科的解釋:
寒武紀是生物化石開始在地層中被大量發現的地質時期,幾乎所有的現生動物門都出現在被稱為『寒武紀大爆發』的演化輻射事件
簡單來說,在寒武紀以前還沒有太多的生物的活動痕跡,但是在寒武紀開始之後,出現了大量的生物活動的痕跡,這些動物如同雨後春筍般的開始演化成各種不同的動物門。有些學者認為:
寒武紀大爆發是因為這時候的動物們開始有了「視覺能力」,他們開始具有類似眼睛的器官來感知這個世界的光線,來解讀這個世界的畫面,進而推動了動物神經系統的發展以及智慧的形成
這也讓我想到 Stanford University 的李飛飛教授在今年 4 月於 TED 的演講「With spatial intelligence, AI will understand the real world」中也有提到類似的想法(寒武紀大爆發與動物視覺能力開始發展有所關聯),強調電腦視覺對於人工智慧的重要性。對於想徹底研究 Vision-Language Model 中「視覺能力」的此篇研究而言,Cambrian-1 的取名似乎也有同樣的意義呢!
2 Cambrian-1 想解決的問題與目標
Cambrian-1 這篇論文的第一個目的是想全面性的探討 Multimodal LLM(此處為 Vision 和 Language 這兩種 Modality,因此在本文中也會稱其為 Vision-Language Model 或是簡稱 VLM)設計上的各種細節,主要包含以下五個面向:
- Visual Representation:Vision-Language Model 中的 Visual Encoder 應該怎麼設計會比較好
- Connector Design:有些論文稱即為 Projection Layer 或是 Modality Projection,此 Module 的用途就是要將 Visual Feature 和 Text Feature 對齊(Align),這個 Module 應該怎麼設計比較好?
- Instruction Tuning Data:什麼樣的 Instruction Tuning Data 能夠幫助 Vision-Language Model 表現得更好
- Instruction Tuning Recipe:Vision-Language Model 應該要怎麼訓練?一階段?兩階段?
- Benchmarking:如何有效的衡量 Vision-Language Model 的視覺能力?
而過去所提出的 VLM 方法,很少有這麼全面的分析每一個面向!此外,LLM 是 Vision-Language Model 重要的根本,一個能力強的 LLM 經常也會導致 Vision-Language Model 能力很強。
但是這就會導致一個問題,有些研究提出更強的 Vision-Language Model 其實只是使用了更強的 LLM,並不是真的設計出更好的 Visual Representation Learning 的方法。
因此,Cambrian-1 這篇論文的第二個目的是就是希望以 Vision-Centric 的角度出發,透過提升 VLM 的「視覺能力」,來提升 VLM 的表現,而不單單只是使用更大的 LLM!
3 分析 1:哪些 Benchmark 是真的在衡量 VLM 的「視覺能力」
想要探究 VLM 的視覺能力,那第一步當然是先研究 VLM 中的 Visual Encoder。更具體的來說,必須理解什麼樣類型的 Visual Encoder 所得到的 Visual Representation 是比較好的,比較能夠提升 VLM 在 Benchmark 上的表現。
然而,這樣真的合理嗎?這群研究者更謹慎的思考:如果 VLM 在 Benchmark 上表現得好,就代表它的視覺能力(Visual Encoder)好嗎?還是其實是它的語言能力(Large Language Model)能力好?
因此,想要知道什麼樣的 Visual Encoder 真的能夠提升 VLM 的視覺能力,第一步就必須先找到適合的 Benchmark! 為了了解 Benchmark 是不是真的在衡量 VLM 的視覺能力,作者將一個 VLM 衡量在一個 Benchmark 上時都會看以下三種情況:
- Visual Enabled:正常情況,讓 VLM 回答這個問題時有提供圖像
- Visual Disabled:特殊情況,讓 VLM 回答這個問題時不提供圖像
- Random Guess:直接亂猜答案
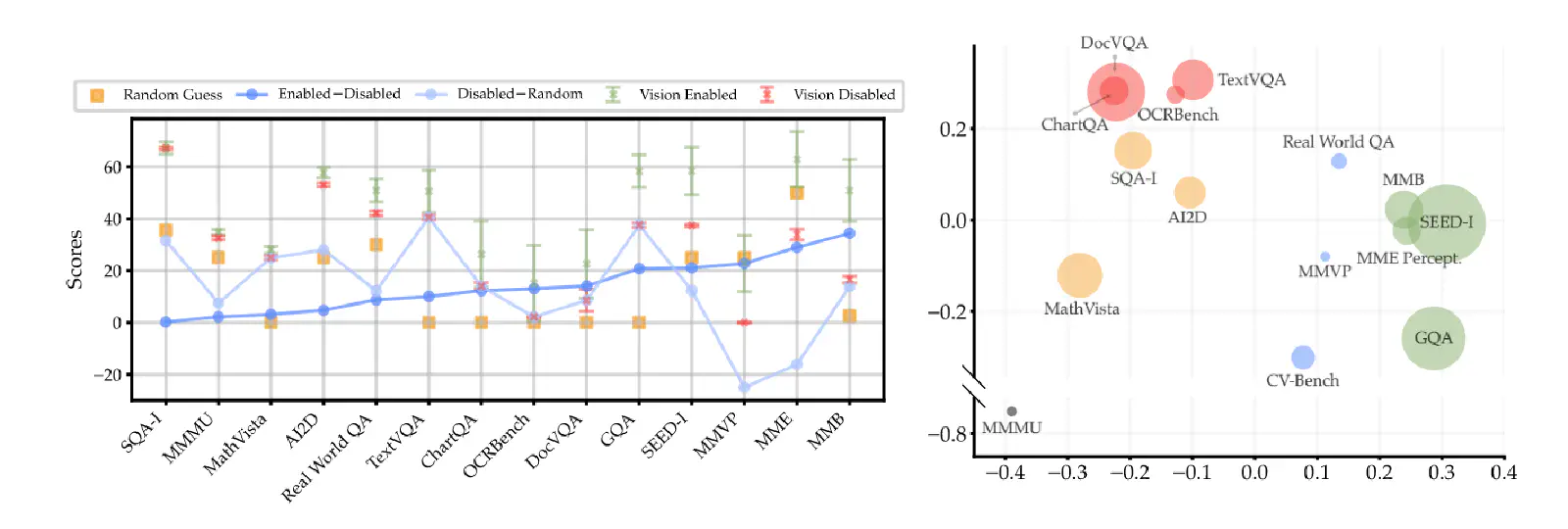
從上圖 Figure 3(左)可以看到:在 SQA-I、MMMU 和 MathVista Bemchmark 上,VLM 在 Visual Enabled 和 Disabled 的情況所得到的分數竟然幾乎一樣。更白話的說,當 VLM 在回答這些 Benchmark 的問題時,有沒有提供圖片給它,沒有太大的影響。
這就表示在這些 Benchmark 上,根本不是在衡量 VLM 的「視覺」能力,而是在衡量「語言」能力。換句話說,VLM 在這些 Benchmark 上表現得愈好,可能其實只是它所使用的 LLM 比較好而已。
在 TextVQA 和 GQA 中,Visual Enabled 和 Disabled 會讓 VLM 的表現有差別,代表這些 Benchmark 確實有在衡量 VLM 的視覺能力。但是神奇的是,在 Visual Disabled 的情況下,VLM 已經看不到圖片,照理說他的回答應該是會跟亂猜沒什麼兩樣,但是從上圖 Figure 3(左)卻可以看到,Visual Disabled 比 Random Guess 好很多。這表示這些 Benchmark 所衡量出來的成績仍然會受到 VLM 中 LLM 的影響。
最後,在 MMVP 和 MME 上,Visual Enabled 和 Disabled 的成績差很多,而且在 Visual Disabled 的情況下表現的還比 Random Guess 差。這表示 MLLM 如果要在這兩個 Benchmark 上做得好,就真的必須要有好的視覺能力,把圖像資訊看得很清楚!從這邊的分析所得到的 Finding:
4 開源 1:CV-Bench — 衡量 VLM 視覺能力的 Benchmark
由於既有的 Benchmark 大部分都沒有真正的在衡量 VLM 的視覺能力(這些 Benchmark 都不是 Vision-Centric 的),因此作者提出了一個新的 Vision-Centric Benchmark 稱為 Cambrian Vision-Centric Benchmark(CV-Bench,裏頭包含了 2638 個樣本。


從上圖 Figure 4 和上表 Table 1 可以發現,CV-Bench 衡量了 VLM 在 2D 的視覺能力(Spatial Relationship 和 Object Count)和 3D 的視覺能力(Depth Order 和 Relative Distance)。此外,作者們也相當用心,CV-Bench 裡面的每一個 Question 都是有人工看過的(根據他們論文中的說法)!
5 分析 2:不同類型的 Visual Encoder 如何影響 VLM 的視覺能力
有了可以真正衡量 VLM 的視覺能力的 Benchmark 後,作者採用兩階段(Two Stage)的訓練,來比較不同類型的 Visual Encoder 對於 VLM 在不同 Benchmark 上的表現。所謂兩階段(Two Stage)訓練的意思是:
- 第一階段(Pre-Training Stage):將 VLM 中的 Visual Encoder 和 Large Language Model 的參數都 Freeze,透過 Adapter Data 訓練 Connector
- 第二階段(Fine-Tuning Stage):將 VLM 中的 Visual Encoder 的參數 Freeze,透過 Instruction-Tuning Data 訓練 Connector 和 Large Language Model
換句話說,在這兩階段的訓練方式中,VLM 中的 Visual Encoder 都是被 Freeze 的!
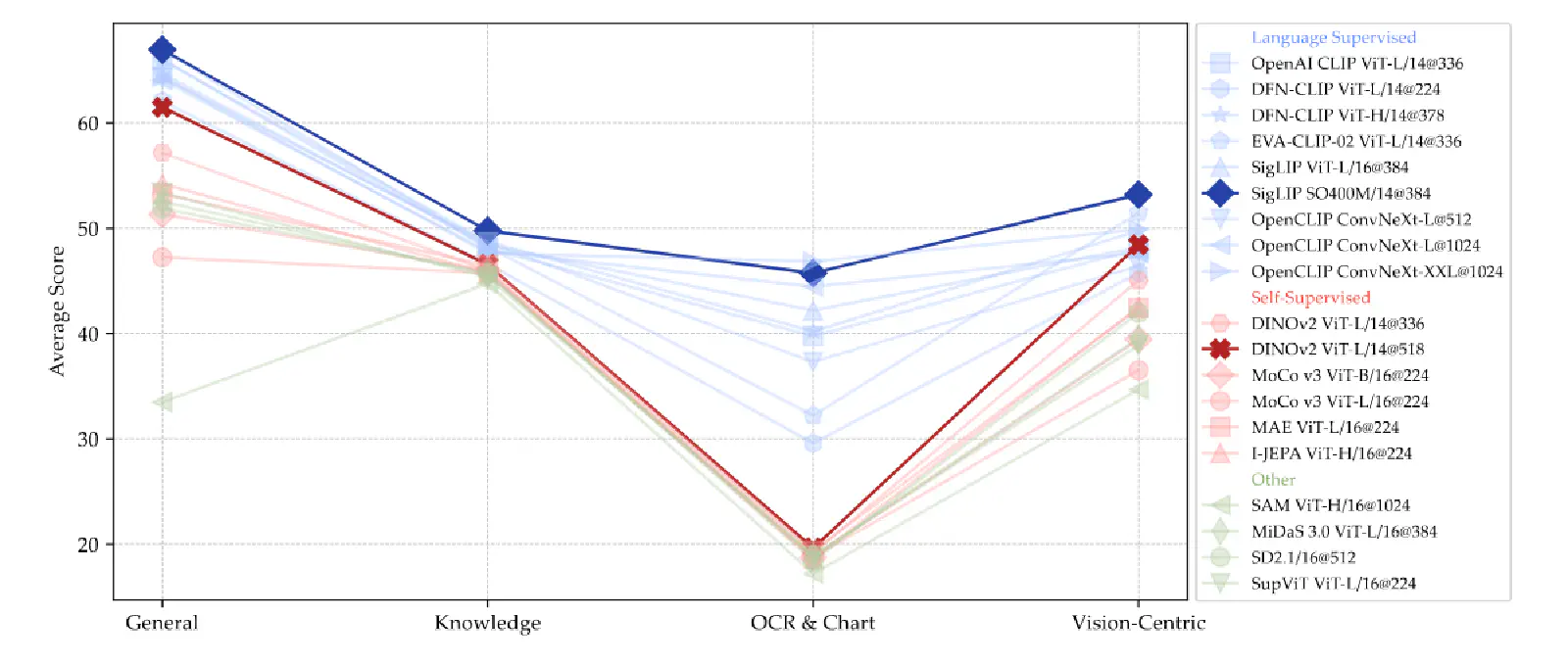
從上圖 Figure 6 可以發現 Language-Supervised Model(ex. CLIP)比 Self-Supervised Model(ex. DINO)表現得更好,且在 Chat 以及 OCR-Related 的問題上有更好的表現。
這主要是因為 CLIP 這種 Language-Supervised Model 在訓練時,就已經會學習到很多圖片和文字的關係,因此更擅長理解圖像中的文字(OCR-Related Task),但是 Self-Supervised Model 在訓練都只有看過圖片的資訊而已。作者也有提到,CLIP-Based Model 之所以可以表現更好,很有可能也是因為它們的訓練資料通常比 Self-Supervised Model 多很多。
此外,不管是 Language-Supervised 或 Self-Supervised 的 Visual Encoder 亦或是 ViT-Based 或是 ConvNet-Based 的 Visual Encoder,提高圖像解析度對 VLM 在 Vision-Centric Benchmark 的表現會更好。我發現到這裡的分析結果,也符合 Apple 於 2024/04 所發表的 MM1 中所提出的觀點!
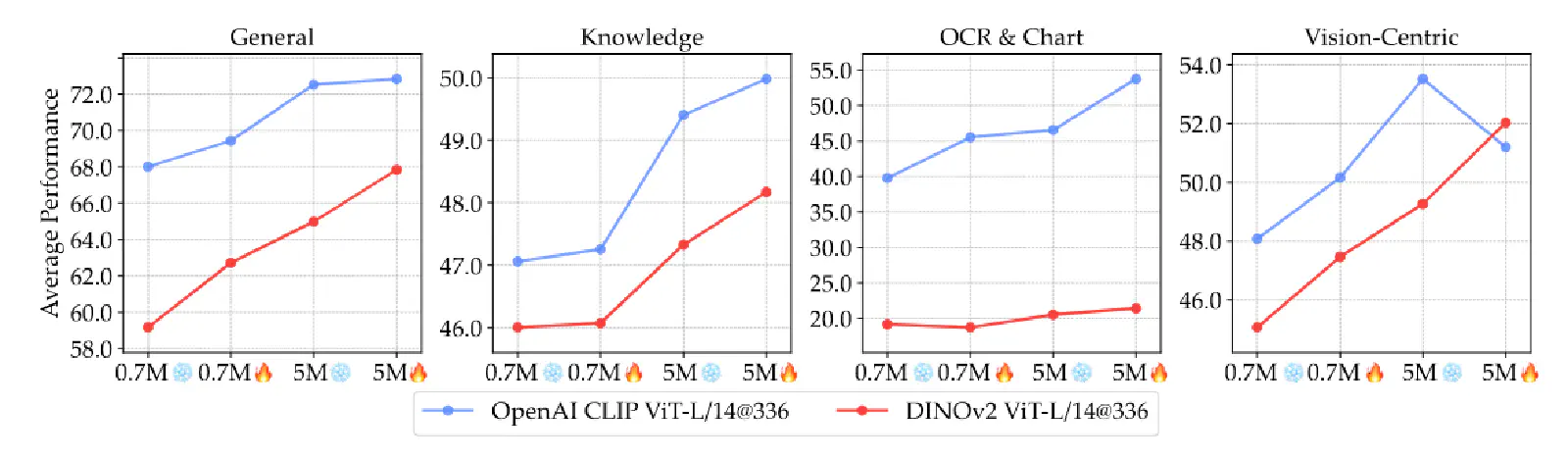
雖然說 Language-Supervised Model(ex. CLIP)在 VLM Benchmark 上的表現普遍勝過 Self-Supervised Model(ex. DINOv2),但是前面有提到這有可能是因為 CLIP 在訓練階段所用的訓練資料量比較多的原因。
因此,作者在上圖 Figure 7 中呈現,以 DINOv2 代表 Self-Supervised Model 作為 VLM 的 Visual Encoder 的話,如果在 Fine-Tuning Stage 將其 Unfreeze,然後使用更多的 Instruction Following Data,就可以縮小 DINOv2-based VLM 和 CLIP-based VLM 的表現差距。
從這邊的分析所得到的 Finding:
6 分析 3:VLM 的訓練方式 — One Stage vs. Two Stage
分析了 VLM 中不同 Visual Encoder 的影響後,作者們接著研究如何有效的訓練 VLM。更具體的來說,VLM 的訓練究竟是一個階段(One Stage)還是兩階段(Two Stage)比較好。
在上文中我們已經介紹過兩階段訓練,其實就是先在 Pre-Training 階段訓練 Connector,接著在 Fine-Tuning 階段訓練 Connector 和 LLM。然而,是否真的需要先在 Pre-Training 階段訓練 Connector,也有研究提出不同的看法。
因此,在這個小節中所說的一階段(One Stage)訓練,就是沒有特別先透過 Pre-Training 階段訓練 Connector,而是直接進入 Fine-Tuning 階段訓練 Connector 和 LLM。 作者在這部分的實驗中,以 Vicuna-1.5-7B 作為 LLM Backbone,並且搭配下表 Table 9 中所列出的 23 種 Visual Encoder:
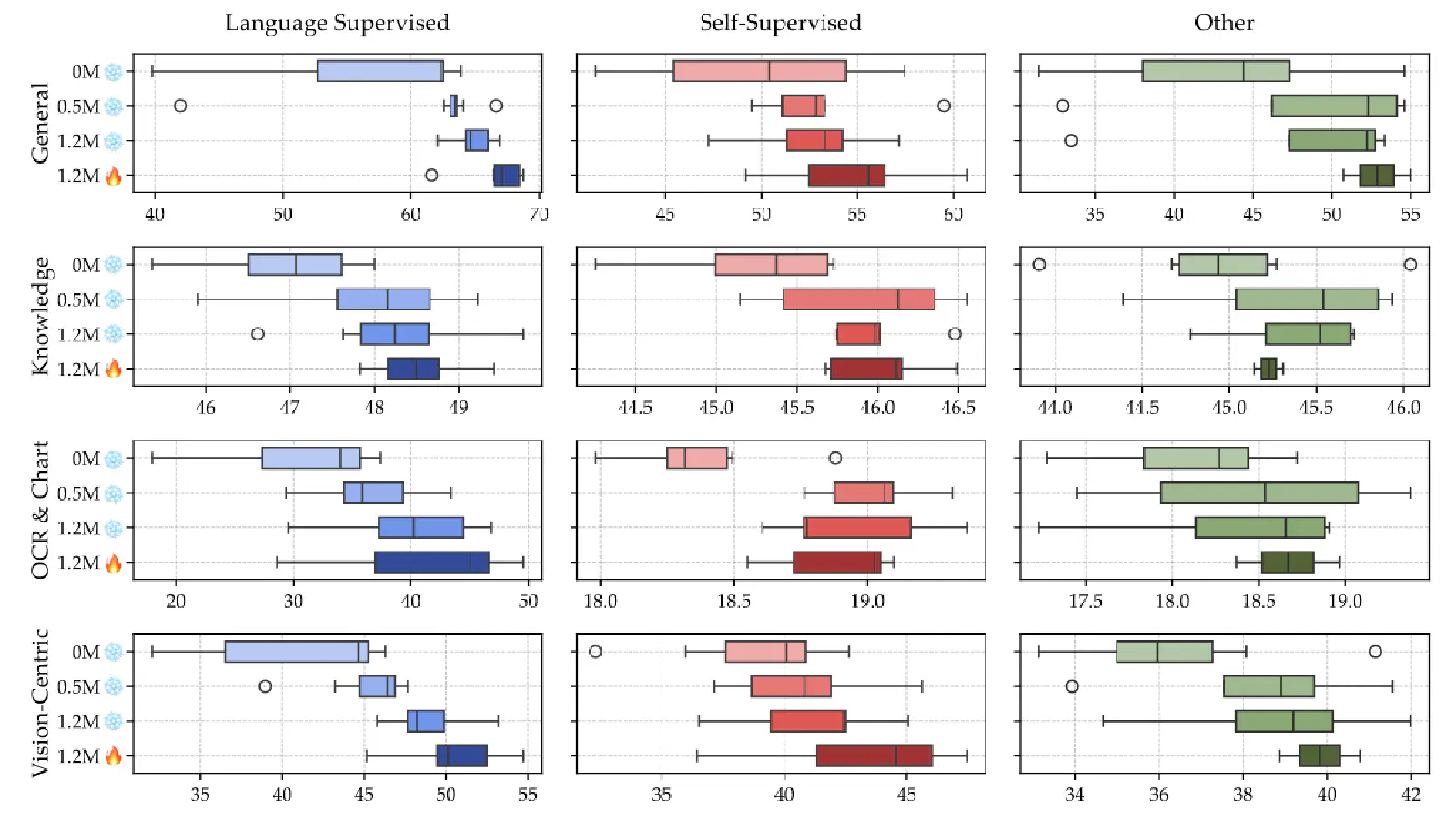
在上圖 Figure 5 中的實驗主要是呈現 3 種類型的 Visual Encoder(Table 9 中呈現)所形成的 VLM,透過 4 種不同的訓練方式(0M_雪花、0.5M_雪花、1.2M_雪花、1.2M_火焰)所得到的 VLM 在 Benchmark 上的表現。其中,以下為每一種訓練方式的意義:
- 0M_雪花:在 Pre-Training 階段中,將 Visual Encoder 的參數 Freeze,並且使用 0M 的 Adapter Data 訓練 Connector。其實就是相當於一階段(One Stage)訓練 — 沒有 Pre-Training 階段,直接進行 Fine-Tuning 階段
- 0.5M_雪花:在 Pre-Training 階段中,將 Visual Encoder 的參數 Freeze,並且使用 0.5M 的 Adapter Data 訓練 Connector。屬於兩階段(Two Stage)訓練
- 1.2M_雪花:在 Pre-Training 階段中,將 Visual Encoder 的參數 Freeze,並且使用 1.2M 的 Adapter Data 訓練 Connector。屬於兩階段(Two Stage)訓練
- 1.2M_火焰:在 Pre-Training 階段中,將 Visual Encoder 的參數 Unfreeze,並且使用 1.2M 的 Adapter Data 訓練 Connector。屬於兩階段(Two Stage)訓練
從上圖 Figure 5 可以發現,不管哪一種 Visual Encoder 以及 Benchmark,“0M_雪花” 這種訓練方式的表現相對其他而言較差,代表兩階段(Two Stage)的訓練確實可以幫助 VLM 表現得更好。
此外,在 Pre-Training 階段中,將 Visual Encoder 的參數 Freeze(雪花)的情況下,使用更多 Adapter Data(0M ⭢ 0.5M ⭢ 1.2M),VLM 的表現也會愈好。
最後,比較 “1.2M_雪花” 與 “1.2M_火焰” 可以發現後者有較好的表現,說明了如果在 Pre-Training 階段中,將 Visual Encoder 的參數 Unfreeze 也可以進一步提升VLM 的表現!
從這邊的分析所得到的 Finding:
7 分析 4:VLM 中 Visual Encoder 的數量 — 一個 Visual Encoder vs. 多個 Visual Encoder
從 Figure 6 的實驗中可以看到不同類型的 Visual Encoder(Language-Supervised、Self-Supervised、Other)在不同的 Benchmark 上會有不太一樣的表現,代表它們可能擅長從圖像中汲取不同的特徵。作者們就思考那有沒有可能將多個 Visual Encoder 結合在一起,來得到圖像中不同的特徵,進而提升 VLM 在所有 Benchmark 上的整體表現呢?
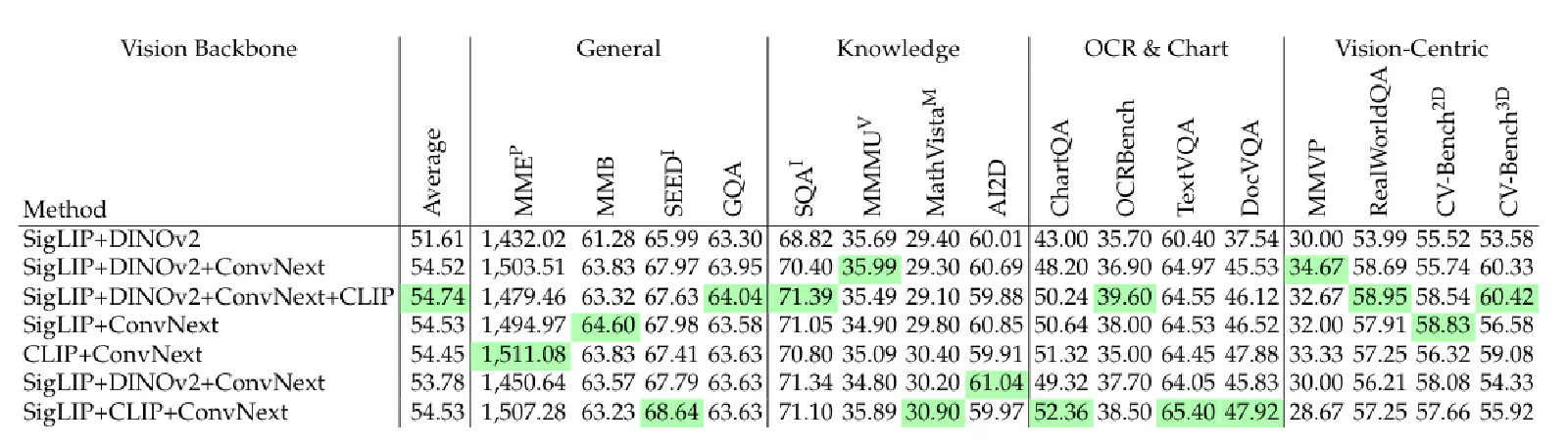
從上表 Table 3 就可以發現:
8 分析 5:VLM 中新的 Connector Design — Spatial Vision Aggregator (SVA)
在上一個小節(分析 4)中,已經知道把多個不同類型的 Visual Encoder 的資訊結合在一起,可以提升 VLM 的表現。然而,由於每個 Visual Encoder 的輸入圖像解析度不同,導致輸出的 Token 數量也不一致。
如果要將這些不同的 Visual Encoder 的輸出結合在一起,作者在上一個小節(分析 4)中採取最 Naive 的做法:將所有 Visual Encoder 的輸出 Token 透過 Interpolation 方式變成 576 個 Token,然後在 Feature 的維度上將這些 Token Concatenate 在一起。
然而,在 Interpolation 的過程中,就會造成資訊的流失;此外,直接將不同 Visual Encoder 的輸出直接 Concatenate 在一起,也相當於以「相同」的重要性來看待不同 Visual Encoder 的輸出。因此,在這個小節中介紹作者所設計的 Connector,來將多個 Visual Encoder 的輸出更有效率的結合(Aggregate)在一起,以提升 VLM 的視覺能力。
我認為本篇論文所提出的 Connector 設計的味道上就很類似 BLIP-2 中 Q-Former 那樣的操作:設定一個 Fixed-Sized & Learnable 的 Query Token,然後把 Visual Encoder 的輸出 Token 當作 Key Token 和 Value Token,進行 Cross-Attention 的運算,讓 Query Token 可以 Attend 到不同的 Visual Encoder 所輸出的圖像資訊。
這樣的好處很明顯,由於 Query Token 是 Learnable 的,模型可以自己學習從多個 Visual Encoder 中取出資訊,給予不同的 Visual Encoder 的輸出不同的重要性;此外,由於 Query Token 是 Fixed-Sized 的,也可以避免因為 Visual Encoder 數量變多,而使得最後 Concatenate 出來的 Tensor 的維度也變大。

上圖 Figure 8(左圖)呈現的是本篇論文所設計的 Connector。Connector 中會有一個 L x L 的 Fixed-Size & Learnable Query Token Sequence(X)。這個 Sequence 中總共有 L x L 個 Query,每一個 Query 都是 C Dimension。
此外,Figure 8(左圖)中也有 N 個 Visual Encoder,每一個 Visual Encoder 都會輸出一個 J x J 的 Visual Tokens。 如同前文所述,為了要讓 Query 可以從不同的 Visual Encoder 上取得圖像的特徵資訊,我們需要讓 Query 與 Visual Token(代表 Key 和 Value)進行 Cross-Attention。
但是有趣的是,作者在進行 Cross-Attention 時,希望保留原來圖像特徵在空間****上(Spatial)的相對關係,因此一個 Query Token 只會和特定的一些 Key/Value Tokens 進行 Cross-Attention。
舉例來說,X 中的藍色框框(其中一個 Query Token),就只會和 F 中的紅色框框(Key、Value Token)進行 Cross-Attention。紅色框框的位置算法也很簡單,就是看那一個 Visual Encoder 的 Output Sequence 是 Query Sequence 的幾倍大就可以知道。
舉例來說,假設 Fk 的尺寸是 X 的 mk 倍,那麼 X 中位於 (i, j) 的 Query Token,就會對應到 Fk 中以下範圍的 Visual Token(Key、Value Token):
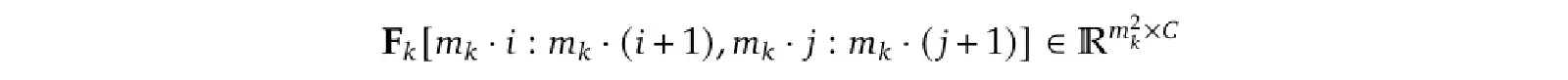
Query 和 Key、Value 進行 Cross-Attention 時,運算過程如下方 Equation (1) 所示。X 會有一個 Query Weight Matrix,每一個 Visual Encoder 都會有自己的 Key Weight Matrix 和 Value Weight Matrix,分別將 Visual Token 轉為 Key 與 Value:
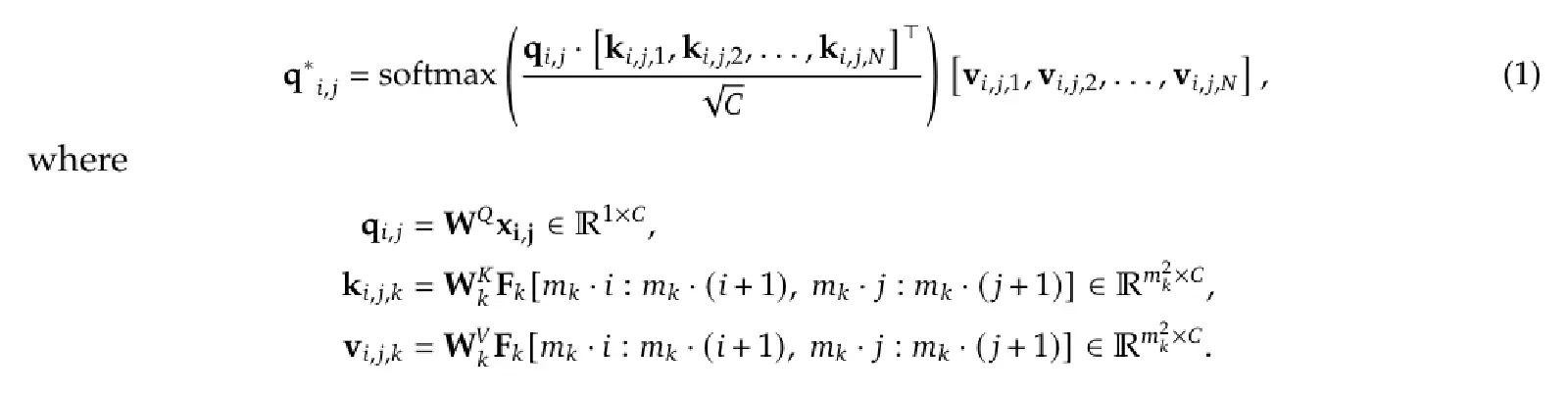
到目前為止,我們已經介紹完本篇論文所提出的 Spatial Vision Aggregator (SVA) 的概念!然而,可以發現 Query Sequence 中的一個 Query 其實需要去 Attend 到很多 Visual Tokens。
換句話說,一個 Query Token 需要記載的資訊量偏多。如果上述的 Cross-Attention 運算「只進行一次」的話,也有可能會導致得到的 Query Sequence 沒有辦法消化不同 Visual Encoder 輸出的所有資訊,造成圖像資訊的流失。
為了解決這個問題,如 Figure 8(右圖)所示,作者把這個 Connector 不只放在 LLM 一開始的地方,也放在 LLM 中的每一層。讓每次 Query Token 都還可以去跟這些 Visual Encoder 的輸出進行 Cross-Attention。
從這邊的分析所得到的 Finding:
9 開源 2:High-Quality Instruction-Tuning Data — Cambrian-7M
當我們把 LLM 訓練成 VLM 時,會將 LLM Fine-Tune 在 Vision-Language 的 Instruction Following Data 上,但是這會導致 LLM 的對話能力降低(也就是發生了 Catastrophic Forgetting),常見的做法是在 Instruction Following Data 中加入一些 Language-Only 的 Instruction-Following Data。
本篇論文收集了所有公開的 Instruction-Tuning Dataset,並透過一些 Data Engine & Prompting 的方法得到更多 Vision Question-Answer 樣本,然後整理出 Cambrian-10M 的資料集。最後再透過一些 Data Curation 方法,得到 High-Quality 的 Instruction-Tuning Data — Cambrian-7M。

從上表 Table 7 可以看到 VLM 訓練在 Cambrian-7M 和 LLaVA-665K 在 Benchmark 上表現的差異。
10 分析 6:透過 System Prompt 控制 VLM 的輸出內容
作者發現當成功的透過兩階段(Two Stage)訓練把 LLM 訓練成 VLM 後,VLM 容易變成一個「Answer Machine」。如下圖 Figure 12(w/o system prompt)所示,輸入一個 Question 到 VLM 中,VLM 輸出一個簡短直接的答案:

會有這樣的狀況,主要是因為在 VLM 的 Fine-Tuning 階段中,我們所準備的 Instruction-Following Dataset(Cambrian-7M)中包含很多 Visual Question-Answer 樣本。
而很多樣本的 Answer 比較簡短,使得 VLM 也學習到了只透過簡短的方式來回答 Visual Question。 針對此問題,作者透過替 Instruction-Following Dataset(Cambrian-7M)中的每一個資料集加上「System Prompt」的方式來解決這個問題。
舉例來說,如果這個訓練樣本的 Answer 是很簡短的,那就會加上一個 System Prompt:“Answer the question using a single word or phrase.” 讓 VLM 學習根據 System Prompt 修改自己的輸出。
在下表 Table 16 中,呈現的是每一個資料集所對應的 System Prompt:

如上圖 Figure 12(w/ system prompt)的範例所示,透過具有正確的 System Prompt 的 Instruction-Following Dataset 來訓練 VLM,可以幫助 VLM 在 Inference 時根據 System Prompt 修改自己的輸出。從這邊的分析所得到的 Finding:
11 開源 3:Vision-Language Model — Cambrian-1
最後,作者透過前面的所有的分析,訓練一個全新的 VLM — Cambrian-1。Cambrian-1 基於不同的 LLM 有不同的規模(8B、13B、34B)。
Cambrian-1 透過其所設計的 Connector (SVA),將四種不同 Visual Encoder 整合在一起。在訓練上,Cambrian-1 採取兩階段(Two Stage)訓練,在 Pre-Training 階段中使用了 2.5M 的 Adapter Data;在 Fine-Tuning 階段中使用了自己建立的 Cambrian-7M。
在下表 Table 8 中可以看到 Cambrian-1 的表現相當厲害: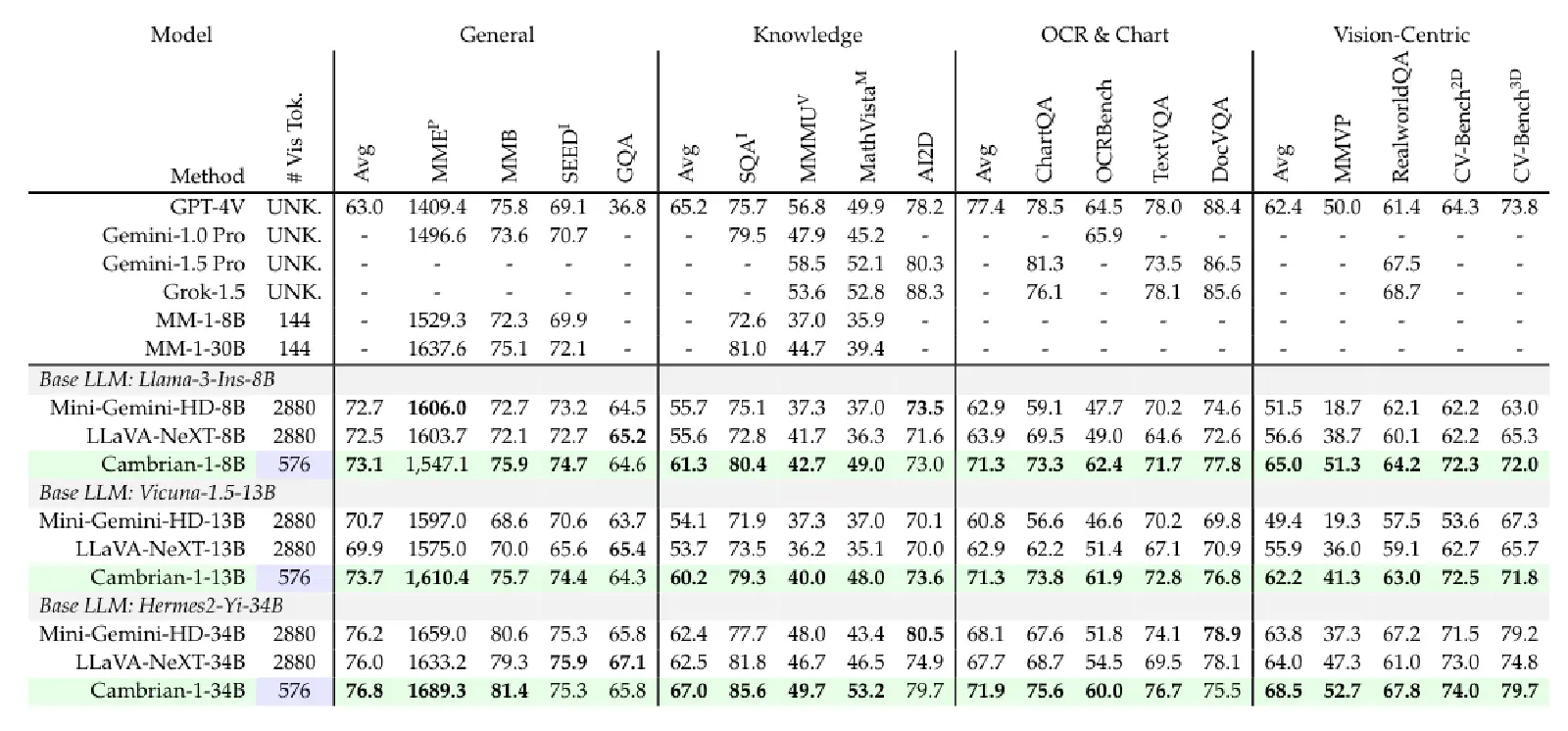
12 結語
在本篇文章中,我們分享了 Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs 這篇論文,作者以「視覺能力」的角度出發,分析 VLM 中各種面向的設計,包含 Benchmark、Visual Encoder、Connector、Training Recipe 以及 Instruction-Following Data,理解這些變因是如何影響 VLM 的視覺能力。相信讀完這篇文章的你,一定也相當佩服作者們可以將 VLM 的研究做得這麼徹底,也希望你也從中得到滿滿的收穫!
以下是這篇論文的 Key Takeaways:
- 目前多數的 VLM Benchmark 都沒有真的衡量 VLM 的「視覺能力」,而太大程度的在衡量「語言能力」。因此,本篇論文也製作並開源了以衡量 VLM 視覺能力的 Visual-Centric Benchmark(CV-Bench)
- Language-Supervised Model(ex. CLIP)更擅長理解圖像中的文字,因此在 OCR-Related 的問題上比 Self-Supervised Model(ex. DINO)表現得更好
- 無論哪一種 Visual Encoder,提高圖像解析度對 VLM 都有好的影響
- 在 Fine-Tune VLM 中的 Connector 與 LLM 之前,先 Pre-Train Connector 確實能夠提升 VLM 的表現
- 在 Pre-Training 階段中,訓練資料(Adapter Data)愈多,也可以提升 VLM 的表現
- 在 Pre-Training 階段中,除了訓練 Connector 之外,也將 Visual Encoder 一起加入訓練也能夠提升 VLM 的表現
- 在 VLM 中結合愈多不同類型的 Visual Encoder 能夠提升 VLM 的視覺能力進而在 Benchmark 上表現得更好
- 在設計 VLM 中的 Connector 時,考慮圖像特徵的空間資訊整合多個 Visual Encoder 的輸出,並將圖像資訊融入到 LLM 之中(而不只是在 LLM 之前)有助於提升 VLM 的視覺能力
- 根據 Instruction-Following Dataset 中 VQA 樣本的 Answer 長度給予適合的 System Prompt,可以幫助 VLM 學習透過 System Prompt 來調整輸出
- 作者開源了以下資料集與模型:
- CV-Bench:衡量 VLM 視覺能力的 Visual-Centric Benchmark
- Cambrian-7M:High-Quality Instruction-Tuning Data
- Cambrian-1:State-Of-The-Art Vision-Language Model