[論文介紹] Steering Large Language Models Between Code Execution and Textual Reasoning

1 前言
本篇文章介紹 Steering Large Language Models Between Code Execution and Textual Reasoning 論文,由 MIT, Harvard, Microsoft, Google DeepMind 於 2024 年 10 月發表於 arXiv,並且被 ICLR 2025 會議所收錄!不管是作者們的來歷亦或是收錄的會議,都感覺這篇論文非常的高品質呀!
2 本篇論文想解決的問題
如同論文的名稱所示,本篇論文想解決/探討的問題是:
對於一個 Large Langugae Model 而言,究竟是以 Code Execution 方式進行 Reasoning 比較好,還是以 Textual Output 的方式來 Reasoning 比較好呢?
針對一些 NLP 任務,像是生成摘要或是對話等等,以 Textual Output 進行 Reasoning 明顯會比較自然比較好,但是在一些數學或是邏輯推理任務上,Code Execution 的 Reasoning 方式往往可以更有效率的方式得到正確答案。
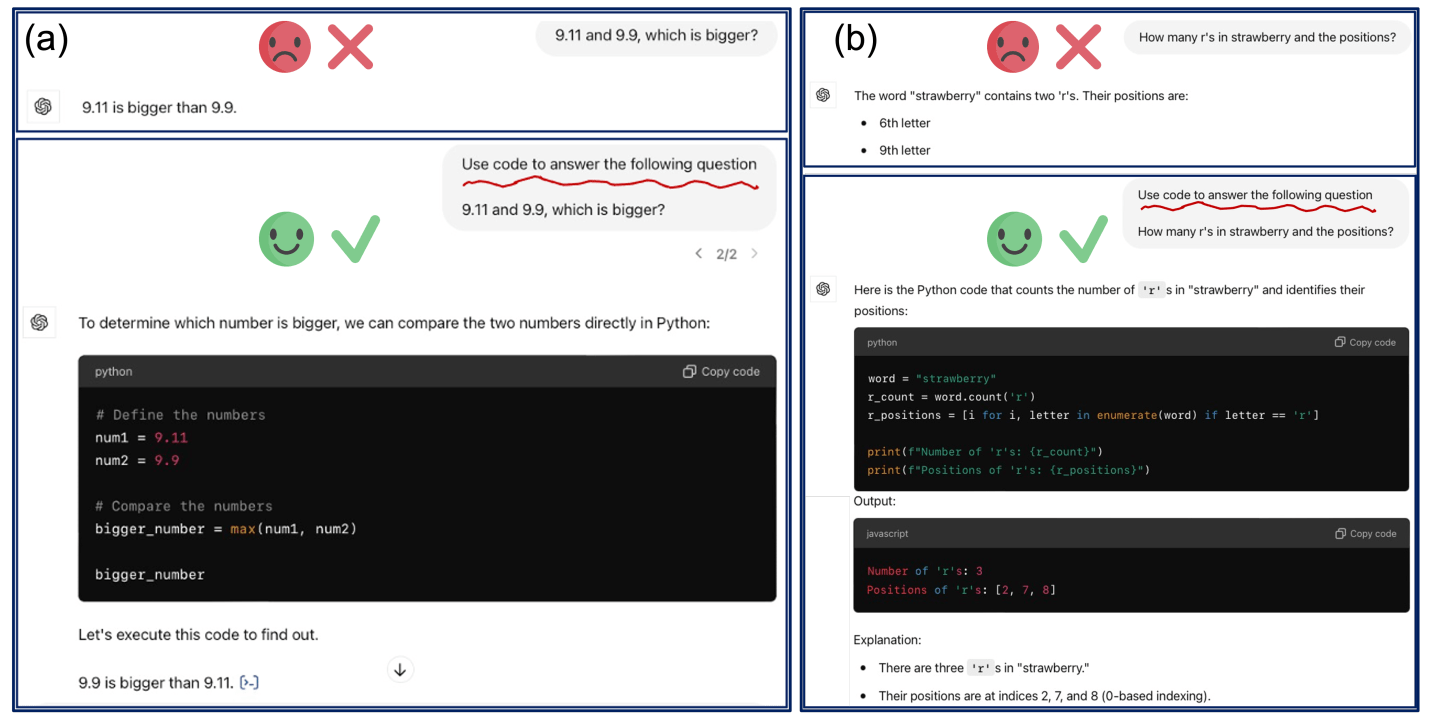
舉例來說,如上圖呈現的兩個任務:“9.11 和 9.9 誰比較大” 與 “‘strawberry’ 中有多少 ‘r’ 以及每一個的位置”,這兩個任務明顯相當簡單,但是對於 GPT-4o 而言如果以 Textual Output 進行 Reasoning 會得到錯誤的答案,而透過 Code Execution 很輕易的答對。
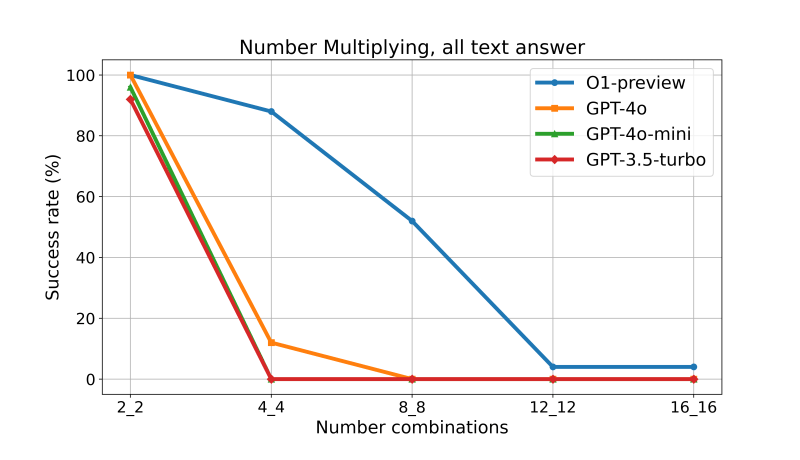
如上圖所示,又或者是進行兩個數字的乘法運算時,“2_3” 代表 2 位數數字乘以 3 位數數字,可以發現隨著位數增加,即使是 OpenAI O1 類型的模型,透過更多的 Textual Output 來進行 Reasoning,也沒有辦法回答正確。
很明顯的,對於 LLM 而言,無法用一種思考方式來解決天底下所有任務,有時候適合透過 Textual Output 有時候則適合利用 Code Execution 進行 Reasoning。因此本篇論文提到的另外一個問題:
如何引導 LLM 在適合的任務上使用正確的 Reasoning 方式 (Textual Output vs Code Execution) 呢?
本篇論文的重點除了回答上述兩個問題之外,也分析 6 種 LLM (O1-preview, GPT-4o, GPT-4o-mini, GPT-3.5, Claude-sonnet, Mixtral-8x7b) 在多種任務上,使用 Textual Output 以及 Code Execution 進行 Reasoning 所帶來的差異。
3 OpenAI GPT-4o: Code Execution vs Textual Output
OpenAI GPT-4o 預設是以 Textual Output 進行 Reasoning,但是必要時 GPT-4o 仍然可以透過 Code Interpreter Tool 以 Code Execution 進行 Reasoning。作者以 GPT-4o, GPT-4o-mini 與 GPT-3.5-turbo 三個模型為例,分析這三個模型在處理 Number Multiplying (計算兩個數字相乘的結果) 與 Game 24 (給定一些數字,從中挑選並輸出可以得到 24 的算式) 兩種不同任務時,會選擇 Code Execution 或是 Textual Output 的方式進行 Reasoning。
從這個實驗中發現到:
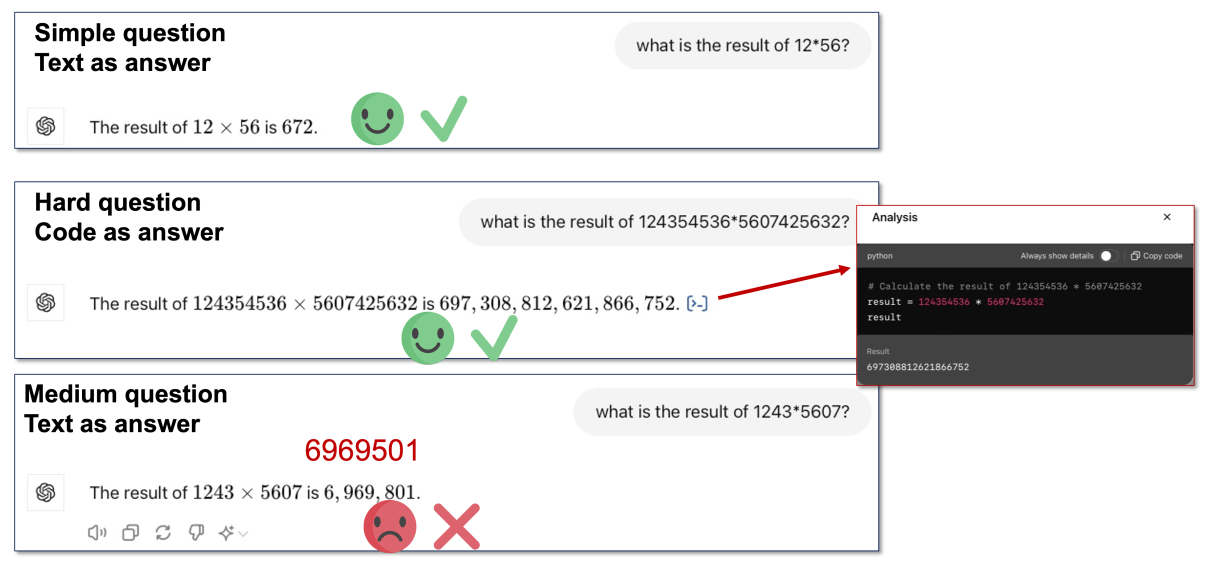
如上圖所示,GPT-4o 在簡單的 2 位數字的乘法很有自信的透過 Textual Output 進行 Reasoning 得到正確的答案;在第二個非常困難的多位數的數字乘法中,GPT-4o 知道要使用 Code Execution 進行 Reasoning。然而,在第三個例子中,面對難度中等的 4 位數字的乘法,GPT-4o 仍然很有自信的透過 Textual Output 進行 Reasoning 而得到錯誤的答案。
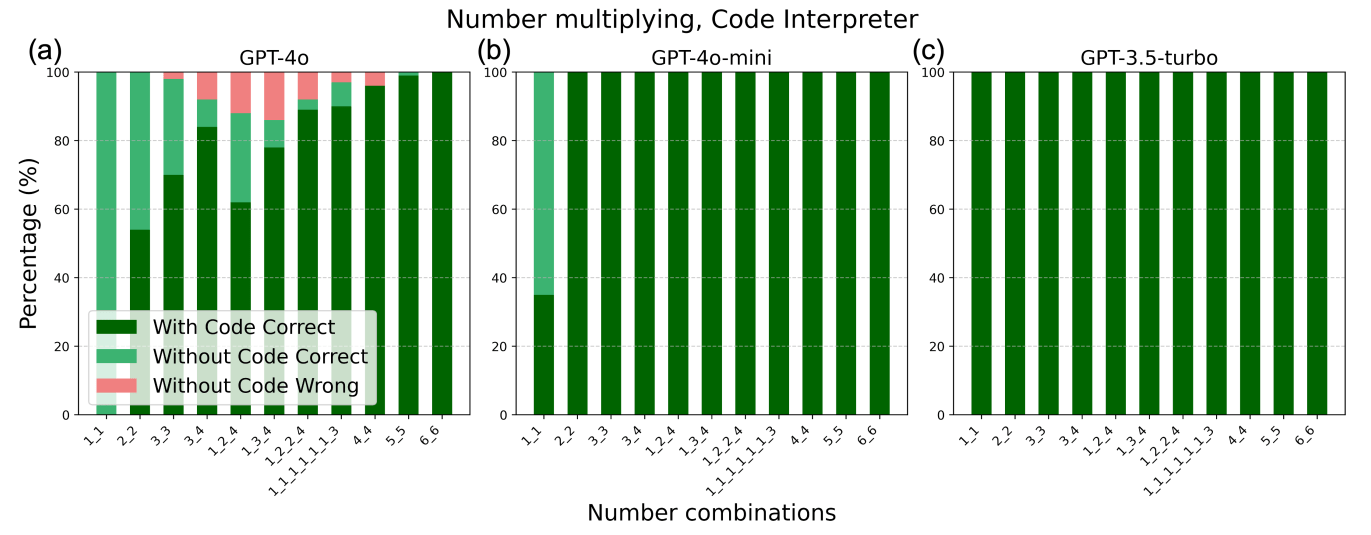
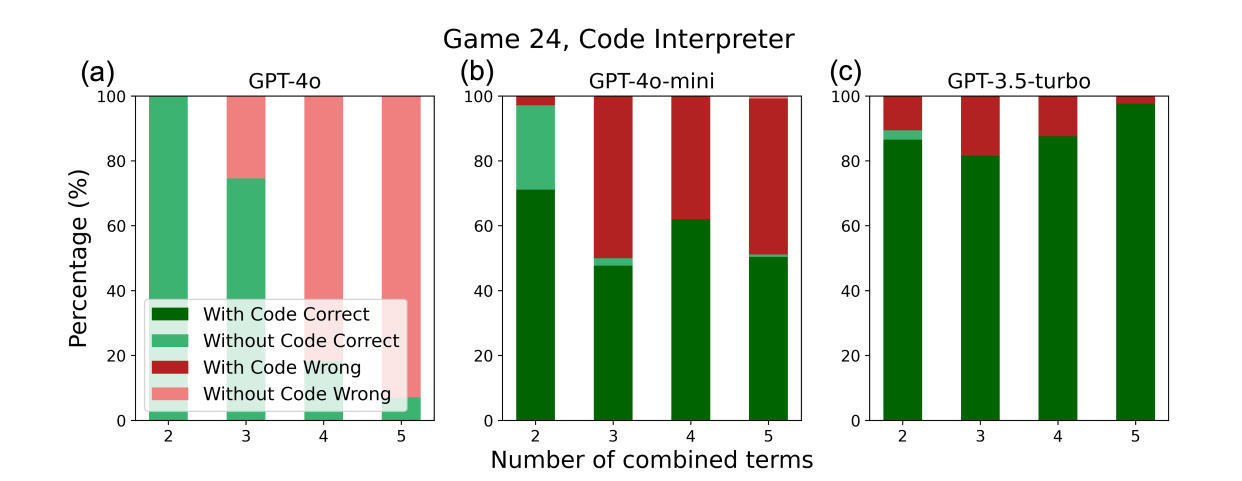
上方兩張圖片分別對應到論文中的 Figure 3 與 Figure 4,從量化分析的實驗結果,可以明顯觀察到 GPT-4o 在簡單的任務上傾向透過 Textual Output Reasoning,而在明顯困難的任務上則會透過 Code Execution Reasoning,但是在難度中等的任務上,仍然選擇 Textual Output Reasoning 而導致錯誤比例上升。在 GPT-3.5-turbo,則是不管任務的簡單到困難,一律都以 Code Execution Reasoning 進行。
由於 Number Multiplying 與 Game 24 剛好是適合透過 Code Execution Reasoning 的任務,使得小模型 (GPT-3.5-turbo) 的表現反而勝過大模型 (GPT-4o)。
如果我們直接在 Prompt 中告訴模型要透過 Code Execution Reasoning,那會不會大家的表現都一樣好了?作者一樣進行了這個實驗,但是卻發現:

如上圖所示,即使要求 GPT-4o 透過 Code Execution 進行 Reasoning,GPT-4o 可能打從心裡很有自信的覺得這個任務透過 Textual Output 進行 Reasoning 就可以解決,使得寫出來的 Code 仍然如同 Textual Output 一般,使得最後的結果仍然錯誤。
4 更大規模的實驗分析
為了更徹底的分析以及比較現有的 LLM 在 Code Execution 以及 Textual Output Reasoning 上的表現,作者使用了 7 種 Baseline 方法搭配 6 種 LLM 並測試在 14 種任務上。
4.1 任務種類
14 種任務如下表所示:
- Math
- Number Multiplying
- Game 24
- GSM-Hard,
- MATH-Geometry
- MATH-Count&Probability
- Logical Reasoning
- Date Understanding
- Web of Lies
- Logical Deduction
- Navigate
- Robot Planning
- BoxNet
- Path Plan
- Symbolic Calculation
- Letters
- BoxLift
- Blocksworld
這些任務都可以透過 Code Execution Reasoning 來處理,但是難度有所不同。此外,每個任務都有超過 300 個測試樣本,因此 LLM 本身在輸出的隨機變異問題可以被忽略。最後,針對每一個任務的描述以及論文出處,可以參考原始論文的 Appendix D。
4.2 方法種類
7 種 Baseline 方法如下所示:
- Only Question: 只提供 Input Question
- All Text: 在 Prompt 中加上一些提示,讓 LLM 只以 Textual Output 進行 Reasoning
- All Code: 在 Prompt 中加上一些提示,讓 LLM 只以 Code Execution 進行 Reasoning
- All Code + CoT: 在 Prompt 中加上一些提示,讓 LLM 只以 Code Execution 進行 Chain-of-Thought Reasoning
- AutoGen Conca.: 將 Input Question 與 AutoGen 的 System Prompt Concatenate 在一起。AutoGen 的 System Prompt:
You are a helpful AI assistant. Solve tasks using your coding and language skills. In the following cases, suggest python code (in a python coding block) or shell script (in a sh coding block) for the user to execute. 1. When you need to collect info, use the code to output the info you need, for example, browse or search the web, download/read a file, print the content of a webpage or a file, get the current date/time, check the operating system. After sufficient info is printed and the task is ready to be solved based on your language skill, you can solve the task by yourself. 2. When you need to perform some task with code, use the code to perform the task and output the result. Finish the task smartly. Solve the task step by step if you need to. If a plan is not provided, explain your plan first. Be clear which step uses code, and which step uses your language skill. When using code, you must indicate the script type in the code block. The user cannot provide any other feedback or perform any other action beyond executing the code you suggest. The user can’t modify your code. So do not suggest incomplete code which requires users to modify. Don’t use a code block if it’s not intended to be executed by the user. If you want the user to save the code in a file before executing it, put # filename: filename inside the code block as the first line. Don’t include multiple code blocks in one response. Do not ask users to copy and paste the result. Instead, use ’print’ function for the output when relevant. Check the execution result returned by the user. If the result indicates there is an error, fix the error and output the code again. Suggest the full code instead of partial code or code changes. If the error can’t be fixed or if the task is not solved even after the code is executed successfully, analyze the problem, revisit your assumption, collect additional info you need, and think of a different approach to try. When you find an answer, verify the answer carefully. Include verifiable evidence in your response if possible. Reply ”TERMINATE” in the end when everything is done. - AutoGen System: 使用 AutoGen 的 system Prompt 作為 LLM 的 System Prompt (LLM 預設沒有使用 System Prompt)
- Code Interpreter: 讓 LLM 可以使用 Code Interpreter
4.3 LLM 模型種類
6 種 LLM 如下所示:
- O1-preview
- GPT-4o
- GPT-4o-mini
- GPT-3.5-turbo-16k-0613 (GPT-3.5)
- Claude-3-sonnet-20240229 (Claude-sonnet)
- Open-mixtral-8x7b (Mixtral-8x7b)
除了 GPT 系列的 LLM 有提供 Code Interpreter 功能外,其他的 LLM 都沒有提供,因此沒有測試在 Code Interpreter 方法;O1-preview 因為無法自己更改 System Prompt,AutoGen System 方法不適用在 O1-preview 上。
4.4 評估指標
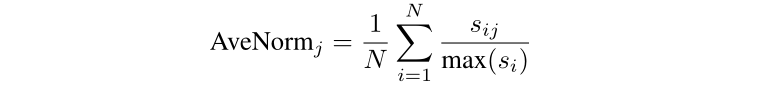
作者以 Average Normalized Score 作為每一種方法的分數。AveNorm 表示第 個方法的最終分數, 則是第 個方法在第 個任務上的分數,max() 則是第 個任務最多可以獲得的分數上限。
4.5 實驗結果
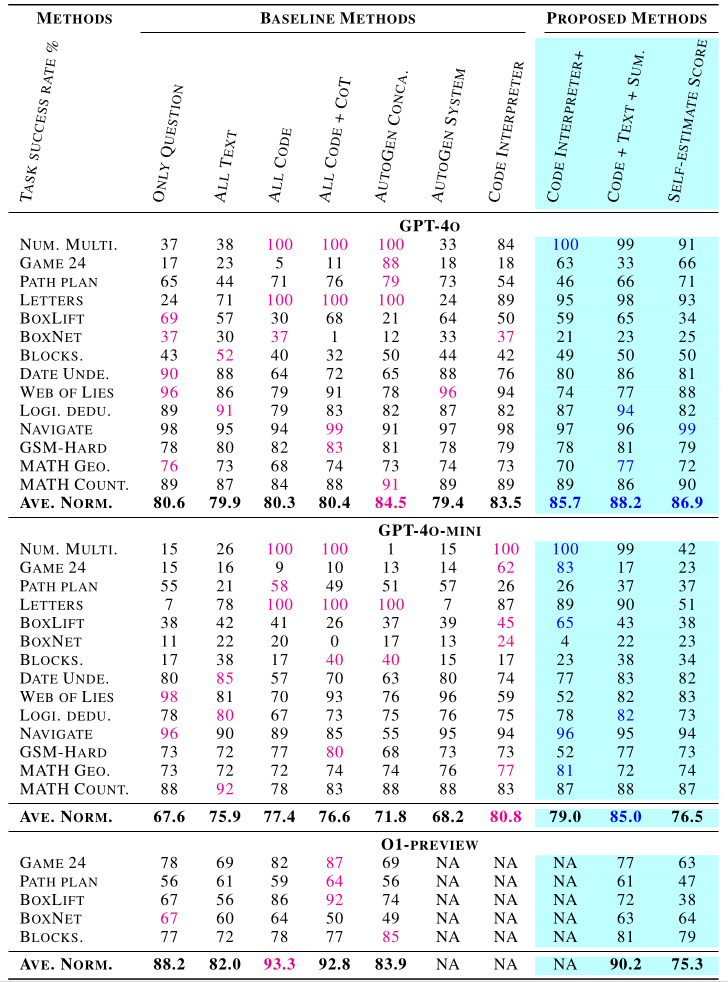
作者從上表的實驗結果得到 2 個 Insight:
- 7 種 Baseline 方法中,沒有絕對最好可以適用所有任務的方法,每種任務適合不同的 Reasoning 方法
- 不是每次透過 Code Execution 進行 Reasoning 都是最好的,有些任務上 Textual Output Reasoning 帶來更好的表現,主要原因來自於:
- 某些任務要考慮太多面向,LLM 寫出的 Code 沒有完全考慮
- Code 限制了 LLM 能夠輸出的 Token,而限制了 LLM 思考
5 本篇論文所提出的方法
作者提出 3 種方法來提昇 LLM 使用 Textual Output 或是 Code Execution 進行 Reasoning 的表現:
Code Interpreter+: 如同 Baseline 方法 “All Code”,鼓勵 LLM 透過 Code Execution 進行 Reasoning (論文中並沒有很清楚的說明這個方法和 “All Code” Baseline 方法的區別)
Code + Text + Sum.: 先透過 “All Code” 與 “All Text” 方法得到基於 Code Execution 和 Textual Output 進行 Reasoning 所得到的結果,再透過一個 LLM 基於兩種答案總結出最後的答案。Prompt 如下所示:
You are a helpful AI assistant. Solve tasks using your coding and language skills. In the following cases, there are two different agents respond to the same problem. In some cases, they output the direct answer, while sometimes they output the code to calculate the answer. I will display you the initial question and the answers from two agents. The code execution results will also be given if the code exists. Your task is to analyze this question based on the analysis and answers from above two agents and then output your final answer. If you want to generate code to acquire the answer, suggest python code (in a python coding block) for the user to execute. Don’t include multiple code blocks in one response, only include one in the response. Do not ask users to copy and paste the result. Instead, use ’print’ function for the output when relevant. I hope you can perform better than other two agents. Hence, try to choose the best answer and propose a new one if you think their methods and answers are wrong.Self-estimate Score: 先要求 LLM 基於目前的問題,給予 Textual Output 與 Code Execution 兩種 Reasoning 方法各一個分數,代表哪一種方法比較適合。再要求 LLM 依照分數高的方法進行 Reasoning。 Prompt 如下所示:
You will be presented with a task that can potentially be solved using either pure textual reasoning or coding (or a combination of both). Your goal is to determine which method will be most effective for solving the task and figure out the answer. Follow these steps: 1. **Estimate your confidence level** in solving the task using both approaches: - **Coding score (0-10)**: How confident are you that you can solve this task correctly by writing code? Provide reasoning. - **Text score (0-10)**: How confident are you that you can solve this task correctly by using textual reasoning? Provide reasoning. 2. **Choose the approach** that you believe has the highest chance of success: - If one score is significantly higher, start with that approach. - If both scores are close, start with textual reasoning first, then decide if coding is necessary after. 3. **Solve the task** using the chosen method: - If you chose coding, write the necessary code, explain the logic behind it, and run it. - If you chose textual reasoning, use detailed explanation and logical steps to reach the answer. 4. **Reflect** after attempting the task: - Did the chosen approach work well? If not, should you switch to the other method? Now, here is the task:
6 實驗結果
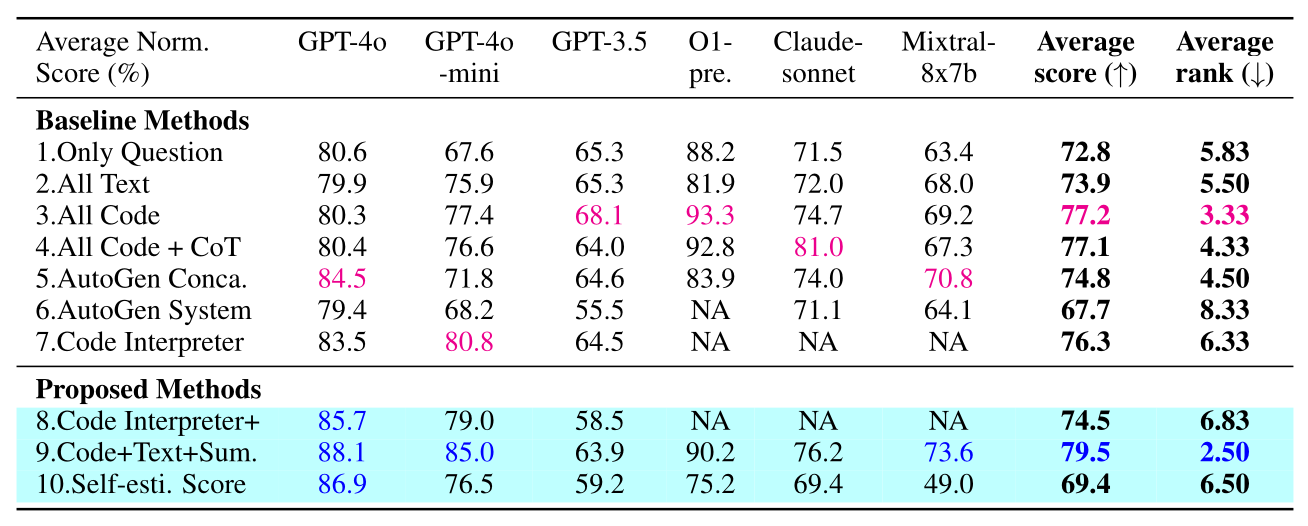
從 Table 1 以及 Table 2 都可以看到 Code + Text + Sum. 是所有方法中表現的最好的,說明了與其讓 LLM 只選擇 Textual Output 或 Code Execution 進行 Reasoning,倒不如讓 LLM 同時考慮兩種 Reasoning 方法的結果,能夠得到最好的表現。
7 結語
本篇文章介紹一篇 ICLR 2025 的論文 — Steering Large Language Models Between Code Execution and Textual Reasoning,主要在理解 LLM 在 Textual Output 以及 Code Execution 兩種 Reasoning 方式的選擇以及表現。
以下是本篇論文的 Takeaway:
- 較大的模型 (GPT-4o) 在一些難度中間 (不難也不簡單) 的任務上,傾向透過 Textual Output 進行 Reasoning,而導致在這些問題上得到錯誤的答案;相反的,較小的模型 (GPT-3.5-turbo) 則是在所有難度的任務上,都傾向透過 Code Execution 進行 Reasoning,使得正確率較高
- 在 Prompt 中要求模型一定要透過 Code 來 Reasoning 不能保證結果一定是好的,模型可能會產生沒有效率如同 Textual Output 的 Code,使得最後得到的答案仍然是錯誤的
- 有些任務適合 Textual Output 進行 Reasoning 而有些則適合 Code Execution,沒有絕對最好的
- LLM 以 Code Execution 進行 Reasoning 時,可能因為以下兩種情況而表現不好:
- 某些任務要考慮太多面向,LLM 寫出的 Code 沒有完全考慮
- Code 限制了 LLM 能夠輸出的 Token,而限制了 LLM 思考
- 讓 LLM 基於兩種 Reasoning 方法的結果再總結出最終答案,能夠得到最好的表現