AI 如何邊工作邊學習?深入解析《Dynamic Cheatsheet》的自我提升之道

1 前言
本篇文章和大家分享 Dynamic Cheatsheet: Test-Time Learning with Adaptive Memory 論文,該論文於 2025 年 4 月上傳至 arXiv。之所以想分享這篇論文,是因為最近很熱門的一篇 Self-Improving Agent 類型的論文 - Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models 其方法就是基於此篇論文進行優化。本篇論文作者也有開源程式碼於 GitHub,有興趣的讀者可以再自行測試看看!
2 Dynamic Cheatsheet 想解決的問題
本篇論文 Dynamic Cheatsheet 想解決的問題非常直觀:
如何讓 LLM Agent 在 Inference 階段也能夠不斷學習,以致隨著 Inference 次數變多,Agent 的表現也提升
Dynamic Cheatsheet 方法定位在 Black-Box LLM 上,因此其方法並不是希望透過 Gradient Descent 來改變 LLM 的權重進行學習,而是希望透過改變 LLM 的 Input Context 使得 LLM 能夠在 Input Context 中塞入過去的經驗來產生正確的輸出。其實就是目前熱門的 Context Engineering 領域的技術。
3 Dynamic Cheatsheet (DC) 方法介紹
在本篇論文中,作者總共提出兩種方法:
- DC-Cumulative (DC-Cu)
- DC with Retrieval & Synthesis (DC-RS)
無論是哪一種方法,其核心的概念都是讓 LLM 自主操作一個 Non-Parametric Memory: 將 Inference 過程中值得注意的資訊記載到 Memory 中,使得 Memory 本身能夠不斷演化 (Adpative)。每次 Inference 也會參考 Memory 中的資訊來得到更好的輸出。
3.1 DC-Cumulative (DC-Cu)
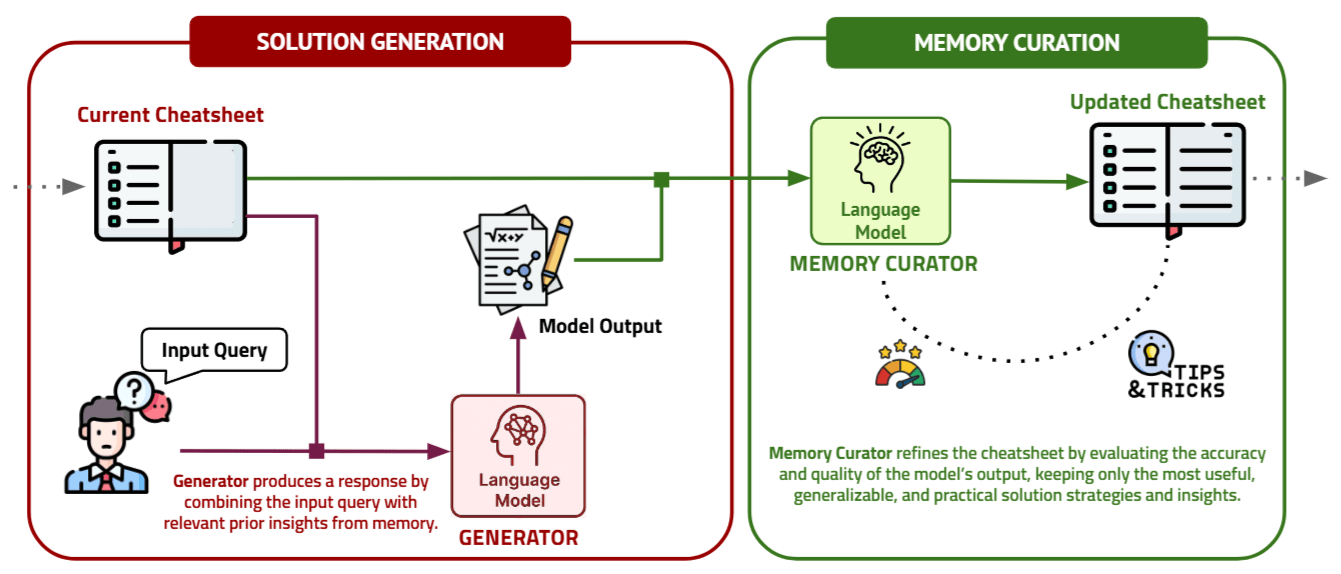
我們首先從 DC-Cumulative (DC-Cu) 方法開始介紹,上圖呈現的是其完整的 Workflow,主要分為 Solution Generation 與 Memory Curation 兩個階段:
- Solution Generation: 模型基於現在的 (1) Input Query (2) Memory 中的所有內容 → 來產生回答
- Memory Curation: 模型基於現在的 (1) Input Query (2) Memory 中的所有內容 (3) 剛剛產生的回答 → 來產生新的 Memory。Memory Curation 主要會針對 Memory 進行以下 3 種操作:
- 從剛剛所產生的回答中萃取出有意義的 Insight 存入 Memory
- 將 Memory 中錯誤或過時的資訊刪除或修改
- 將 Memory 變得更簡潔
從上述流程可以發現到,DC-Cumulative 方法能不能成功的關鍵其實在於 LLM 能不能在 Memory Curation 階段,判斷目前的回答是否是正確的,進而對 Memory 進行合理的更新。
3.2 DC with Retrieval & Synthesis (DC-RS)
DC with Retrieval & Synthesis (DC-RS) 顧名思義就是比 DC 多了 Retrieval & Synthesis 的步驟,DC-RS 主要想解決 DC-Cu 的兩個缺點:
- 在進行 Solution Generation 時,Memory 中的內容其實是過時的,而非完全適合目前的 Input Query
- 在進行 Memory Curation 時,只能參考前一個 Input-Output 而無法參考過去更多的 Input-Output Example
因此,DC-RS 的方法由以下步驟組成:
- Example Retrieval: 基於現在的 (1) Input Query → 透過 Embedding Model 抽取出 Top-K 個最相似的 Input-Output Example
- Memory Curation: 模型基於現在的 (1) Input Query (2) Memory 中的所有內容 (3) 剛剛抽取出的 Top-K Input-Output Example → 來產生新的 Memory
- Solution Generation: 模型基於現在的 (1) Input Query (2) Memory 中的所有內容 → 來產生回答
4 Dynamic Cheatsheet 實驗
4.1 Baseline
- Baseline prompting (BL).: 沒有任何 Memory Curation 或是 Example Retrieval 的幫助下,直接 Prompt LLM 來產生回答
- DC- (empty memory).: 基於 DC 方法但是在 Memory 中不保留任何內容
- Full-History Appending (FH).: 直接將所有 Iteration 過程不斷累積在 LLM 的 Input Context 中
- Dynamic Retrieval (DR).: 每次都先抽取出與現在 Input Query 最相似的 Input-Output Examples 放在 LLM 的 Input Context 中 (相當於有進行 Retrieval 但沒有 Curation: 直接把原始的 Input-Output Examples 放入 Input Context,而非先 Distill 出一些 Insight)
4.2 Benchmark
- AIME 2020–2025 Exam Questions
- GPQA-Diamond
- Game of 24
- Math Equation Balancer
- MMLU-Pro (Engineering and Physics)
4.3 Result
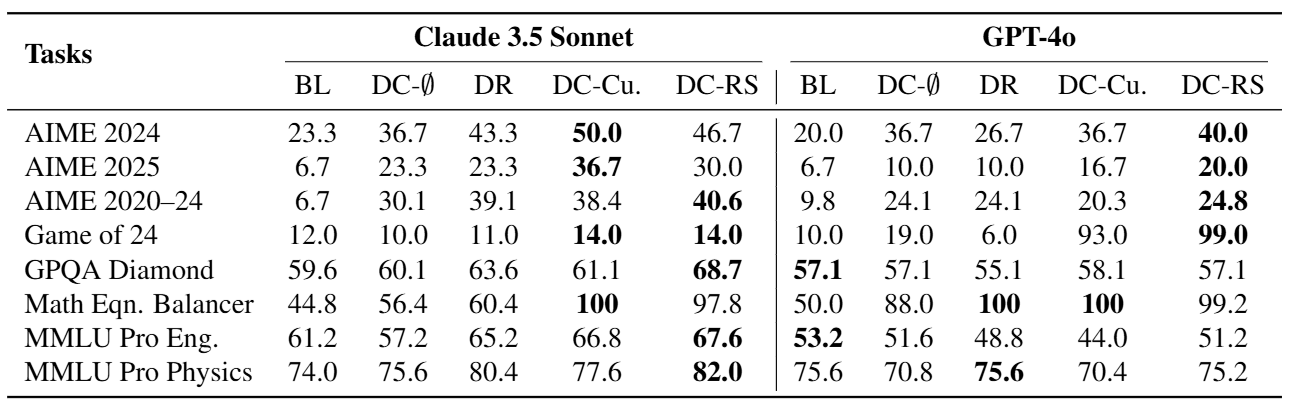
從上表 Table 1 中以 Game of 24 舉例,可以看到 DC-RS 方法基於 GPT-4o 表現是最好的,而 DC- 的表現相當差,說明了賦予 LLM 進行 Memory 的 Retrieval 與 Curation,確實能夠提升 LLM 的表現。
然而,若以 Claude 3.5 Sonnet 來看,DC-RS 相對於 Baseline 方法的改善卻不多。論文中解釋雖然 Dynamic Cheatsheet 賦予 LLM 進行 Test-Time Adaption 的可能,但是效果如何還是取決於 LLM 本身的能力。
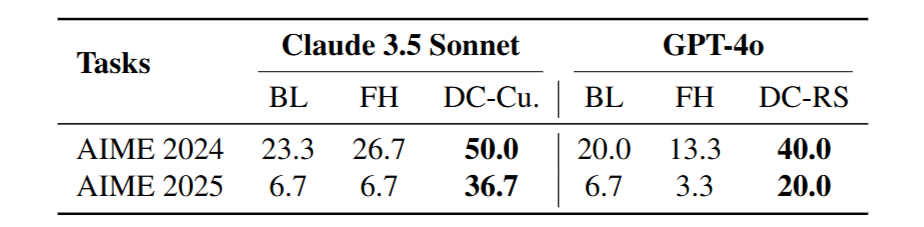
從上表 Table 2 可以發現到單純地將過去的經驗 (Input-Output Example) 保留於 LLM 的 Input Context 中的方法 (FH),不僅沒有辦法顯著提升表現,反而有時還可能比完全不放這些經驗、單純 Prompt LLM 的方法 (BL) 來得差。
這也說明了 DC-RS 方法中,透過 Retrieval 來取出真正相似的過去經驗 (Input-Output Example) 以及將這些過去經驗進行 Curation 得到更精簡更泛化的 Insight 的重要性。
5 結語
本篇文章介紹了 Dynamic Cheatsheet: Test-Time Learning with Adaptive Memory 論文,理解如何加入 Adaptive Memory 的技巧,實現一個簡單的 Self-Improving LLM。同時,透過實驗結果我們也可以了解到,單純地將所有資訊放入 Memory 或是從 Memory 中取出所有資訊,所帶來的表現提升是很有限制的,必須搭配 Memory Retrieval 與 Curation 才能夠有效率的提升整體表現。